
機械学習におけるK最近傍アルゴリズム[例付き]
公開: 2020-10-28目次
序章
機械学習は間違いなく、1秒ごとにより多くのデータを収集している今日のデータ駆動型の世界で最も起こっている強力なテクノロジーの1つです。 これは急速に成長しているテクノロジーの1つであり、すべてのドメインとすべてのセクターに独自のユースケースとプロジェクトがあります。
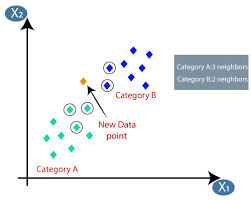
機械学習またはモデル開発は、データサイエンスプロジェクトのライフサイクルのフェーズの1つであり、これも最も重要なフェーズの1つと思われます。 この記事は、機械学習におけるKNN(K最近傍法)の紹介として作成されています。
K最近傍法
機械学習に精通している場合、またはデータサイエンスやAIチームの一員である場合は、おそらくk最近傍アルゴリズムまたは単純にKNNと呼ばれるアルゴリズムについて聞いたことがあるでしょう。 このアルゴリズムは、実装が簡単で、ノンパラメトリックで、怠惰な学習であり、計算時間が短いため、機械学習で使用されるアルゴリズムの1つです。
k最近傍アルゴリズムのもう1つの利点は、分類タイプと回帰タイプの両方の問題に使用できることです。 これら2つの違いに気付いていない場合は、はっきりさせておきます。分類と回帰の主な違いは、回帰の出力変数が数値(連続)であるのに対し、分類の出力変数はカテゴリ(離散)であるということです。
読む: RのKNNアルゴリズム
k最近傍法はどのように機能しますか?
K最近傍法(KNN)アルゴリズムは、「特徴類似性」または「最近傍法」の手法を使用して、新しいデータポイントが分類されるクラスターを予測します。 以下は、このアルゴリズムの動作をよりよく理解するためのいくつかのステップです。

ステップ1-機械学習でアルゴリズムを実装するには、モデリングの準備ができたクリーンなデータセットが必要です。 トレーニングとテストのデータセットに分割された、クリーンアップされたデータセットがすでにあると仮定します。
ステップ2-すでにデータセットの準備ができているので、アルゴリズムを実装するために考慮する必要がある最も近いデータポイントの数を示すK(整数)の値を選択する必要があります。 記事の後の段階でk値を決定する方法を知ることができます。
ステップ3-このステップは反復的なものであり、データセット内の各データポイントに適用する必要があります
I.距離メトリックのいずれかを使用して、テストデータとトレーニングデータの各行の間の距離を計算します
a。 ユークリッド距離
b。 マンハッタン距離
c。 ミンコフスキー距離
d。 ハミング距離。
多くのデータサイエンティストはユークリッド距離を使用する傾向がありますが、この記事の後の段階でそれぞれの重要性を知ることができます。
II。 上記の手順で使用した距離メトリックに基づいてデータを並べ替える必要があります。
III。 変換されたソート済みデータの上位K行を選択します。
IV。 次に、これらの行の最も頻繁なクラスに基づいて、テストポイントにクラスを割り当てます。
ステップ4-終了
K値を決定する方法は?
モデルの最大精度を達成するために適切なK値を選択する必要がありますが、Kの最も好ましい値を見つけるための事前定義された統計的方法はありません。しかし、それらのほとんどはエルボー法を使用します。
エルボー法は、kのいくつかの値の二乗誤差の合計(SSE)を計算することから始まります。 SSEは、クラスターの各メンバーとその重心の間の距離の2乗の合計です。
SSE = ∑Ki = 1∑x∈cidist ( x 、ci)2SSE = ∑∑x∈cidist ( x 、ci)2
SSEに対して異なるkの値をプロットすると、kの値が大きくなるにつれて誤差が減少することがわかります。これは、クラスターの数が増えるとクラスターが小さくなる傾向があるため、歪みも小さくなるためです。 。 エルボー法の考え方は、SSEが急激に減少してエルボーの形状を表すkを選択することです。
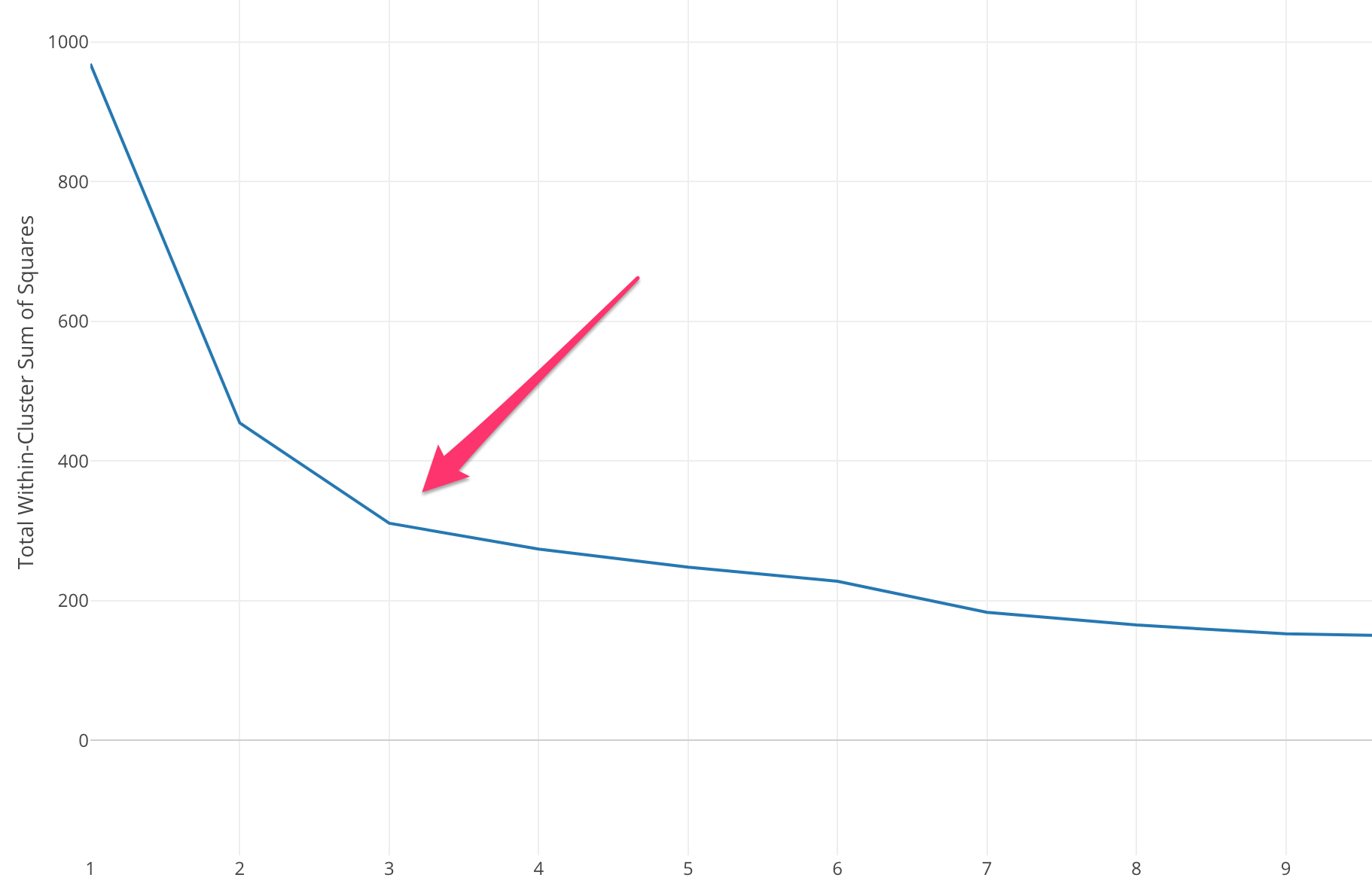
場合によっては、複数のエルボがあるか、まったくエルボがないことがあります。 このような場合、通常、解決しようとしている問題のコンテキストでk-means MLアルゴリズムがどの程度うまく機能するかを評価することにより、最良のkを計算することになります。
また読む:機械学習モデル

距離メトリックのタイプ
2つのデータポイント間の距離を1つずつ計算するために使用されるさまざまな距離メトリックについて理解しましょう。
1.ユークリッド距離–ユークリッド距離は、2点間の距離の2乗の合計の平方根です。
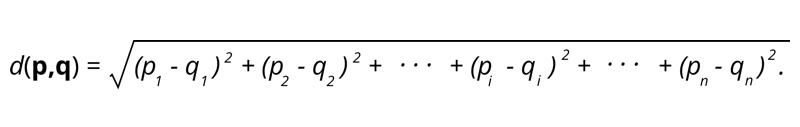 2.マンハッタン距離–マンハッタン距離は、2点間の差の絶対値の合計です。
2.マンハッタン距離–マンハッタン距離は、2点間の差の絶対値の合計です。
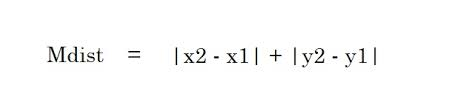 3.ミンコフスキー距離–ミンコフスキー距離は、2点間の距離の類似性を見つけるために使用されます。 以下の式に基づいて、マンハッタン距離(p = 1の場合)とユークリッド距離(p = 2の場合)のいずれかに変更されます。
3.ミンコフスキー距離–ミンコフスキー距離は、2点間の距離の類似性を見つけるために使用されます。 以下の式に基づいて、マンハッタン距離(p = 1の場合)とユークリッド距離(p = 2の場合)のいずれかに変更されます。
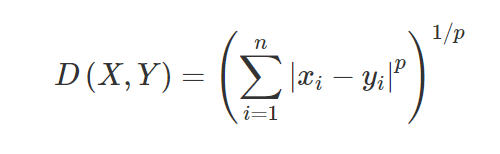 4.ハミング距離–ハミング距離はカテゴリ変数に使用されます。 このメトリックは、2つのカテゴリ変数が同じであるかどうかを示します。
4.ハミング距離–ハミング距離はカテゴリ変数に使用されます。 このメトリックは、2つのカテゴリ変数が同じであるかどうかを示します。
KNNのアプリケーション
すでに利用可能な顧客のクレジットの使用状況と評価に基づいて、新しい顧客のクレジット評価を予測します。
- ローンを制裁するかどうか? 候補者に。
- 特定のトランザクションを分類することは不正であるかどうかです。
- レコメンデーションシステム(YouTube、Netflix)
- 手書き検出(OCRなど)。
- 画像認識。
- ビデオ認識。
KNNの長所と短所
機械学習は多くのアルゴリズムで構成されているため、それぞれに長所と短所があります。 業界、ドメイン、データの種類、および各アルゴリズムのさまざまな評価指標に応じて、データサイエンティストは、ビジネスの問題に適合し、それに答える最適なアルゴリズムを選択する必要があります。 K最近傍法の長所と短所をいくつか見てみましょう。
長所
- 使いやすく、理解し、解釈しやすい。
- 迅速な計算時間。
- データに関する仮定はありません。
- 予測の高精度。
- 用途が広い–分類と回帰の両方のビジネス問題に使用できます。
- マルチクラス問題にも使用できます。
- ハイパーパラメータ調整ステップで調整するハイパーパラメータは1つだけです。
短所
- アルゴリズムはすべてのトレーニングデータを保存するため、計算コストが高く、高いメモリが必要です。
- 変数が増えると、アルゴリズムは遅くなります。
- 無関係な機能には非常に敏感です。
- 次元の呪い。
- Kの最適値を選択します。
- クラスの不均衡なデータセットは問題を引き起こします。
- データに値がない場合も問題が発生します。
必読:機械学習プロジェクトのアイデア
結論
これは、使いやすさと計算時間の短縮で広く知られている基本的な機械学習アルゴリズムです。 これは、機械学習の世界に非常に慣れておらず、面倒なことなく特定のタスクを完了したい場合に選択する適切なアルゴリズムになります。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIIT-を提供します。 B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。
K最近傍アルゴリズムは高価ですか?
巨大なデータセットの場合、K最近傍アルゴリズムは計算時間とストレージの両方の点でコストがかかる可能性があります。 これは、このKNNアルゴリズムが機能するために、すべてのトレーニングデータセットを保存および保存する必要があるためです。 KNNは、距離の計算に依存するため、トレーニングデータのスケールに非常に敏感です。 このアルゴリズムは、トレーニングデータに関する仮定に基づいて結果をフェッチしません。 他の教師あり学習アルゴリズムを検討する場合、これは一般的なケースではないかもしれませんが、KNNアルゴリズムは、非線形データポイントに伴う問題を解決するのに非常に効果的であると考えられます。
K-NNアルゴリズムの実用的なアプリケーションにはどのようなものがありますか?
KNNアルゴリズムは、共通の関心を持つ個人に製品を推奨するために企業でよく使用されます。 たとえば、企業は、視聴者の選択に基づいてテレビ番組を提案したり、以前の購入に基づいてアパレルデザインを提案したり、予約履歴に基づいてツアー中にホテルや宿泊施設のオプションを提案したりできます。 また、金融機関が同様の財務機能に基づいて顧客に信用格付けを割り当てるために使用することもできます。 銀行は、債務不履行者と同様の特徴を共有しているように見える特定のアプリケーションに基づいて、ローンの支払いを決定します。 このアルゴリズムの高度なアプリケーションには、画像認識、OCRを使用した手書き検出、およびビデオ認識が含まれます。
機械学習エンジニアの将来はどのようになりますか?
AIと機械学習のさらなる進歩により、機械学習エンジニアの市場または需要は非常に有望に見えます。 2021年の後半までに、LinkedInには機械学習エンジニア向けに約23,000件の求人が掲載されました。 アマゾンやグーグルからPayPal、オートデスク、モルガンスタンレー、アクセンチュアなどに至るまで、世界的な巨大組織は常にトップの才能を探し求めています。 プログラミング、統計、機械学習などの分野で強力なファンダメンタルズを備えているため、エンジニアはデータ分析、自動化、AI統合、その他の分野で指導的役割を担うこともできます。