
K- أقرب خوارزمية الجيران في التعلم الآلي [مع أمثلة]
نشرت: 2020-10-28جدول المحتويات
مقدمة
يعد التعلم الآلي بلا شك أحد أكثر التقنيات حدثًا وقوة في عالم اليوم المدفوع بالبيانات حيث نجمع قدرًا أكبر من البيانات في كل ثانية. هذه إحدى التقنيات سريعة النمو حيث لكل مجال وكل قطاع حالات ومشاريع استخدام خاصة به.
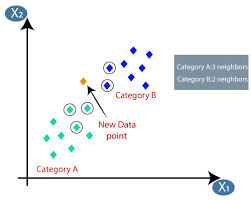
يعد التعلم الآلي أو تطوير النموذج إحدى المراحل في دورة حياة مشروع علوم البيانات والتي يبدو أنها واحدة من أكثر المراحل أهمية أيضًا. تم تصميم هذه المقالة كمقدمة لـ KNN (K-Nearest Neighbours) في التعلم الآلي.
K- أقرب الجيران
إذا كنت معتادًا على التعلم الآلي أو كنت جزءًا من فريق علوم البيانات أو الذكاء الاصطناعي ، فمن المحتمل أنك سمعت عن خوارزمية k-Nearest Neighbours ، أو بسيطة تسمى KNN. هذه الخوارزمية هي واحدة من الخوارزميات المستخدمة في التعلم الآلي لأنها سهلة التنفيذ وغير بارامترية وتعلم كسول ولديها وقت حساب منخفض.
ميزة أخرى لخوارزمية k-Nearest Neighbours هي أنه يمكن استخدامها لكل من تصنيف المشاكل ونوع الانحدار. إذا لم تكن على دراية بالفرق بين هذين النوعين ، فاسمحوا لي أن أوضح لك ، الفرق الرئيسي بين التصنيف والانحدار هو أن متغير الإخراج في الانحدار رقمي (مستمر) بينما هذا بالنسبة للتصنيف هو فئوي (منفصل).
قراءة: خوارزميات KNN في R.
كيف يعمل k-Nearest Neighbours؟
تستخدم خوارزمية K- الأقرب للجيران (KNN) تقنية "تشابه الميزات" أو "الجيران الأقرب" للتنبؤ بالمجموعة التي تقع فيها نقطة بيانات جديدة. فيما يلي بعض الخطوات التي يمكننا من خلالها فهم عمل هذه الخوارزمية بشكل أفضل

الخطوة 1 - لتنفيذ أي خوارزمية في التعلم الآلي ، نحتاج إلى مجموعة بيانات نظيفة وجاهزة للنمذجة. لنفترض أن لدينا بالفعل مجموعة بيانات نظيفة تم تقسيمها إلى مجموعة بيانات تدريب واختبار.
الخطوة 2 - نظرًا لأن لدينا مجموعات البيانات جاهزة بالفعل ، نحتاج إلى اختيار قيمة K (عدد صحيح) التي تخبرنا عن عدد نقاط البيانات الأقرب التي يجب أن نأخذها في الاعتبار لتنفيذ الخوارزمية. يمكننا التعرف على كيفية تحديد قيمة k في المراحل اللاحقة من المقالة.
الخطوة 3 - هذه الخطوة تكرارية ويجب تطبيقها على كل نقطة بيانات في مجموعة البيانات
1. احسب المسافة بين بيانات الاختبار وكل صف من بيانات التدريب باستخدام أي من قياس المسافة
أ. المسافة الإقليدية
ب. مسافة مانهاتن
ج. مسافة مينكوفسكي
د. مسافة المطرقة.
يميل العديد من علماء البيانات إلى استخدام المسافة الإقليدية ، لكن يمكننا التعرف على أهمية كل واحدة في المرحلة اللاحقة من هذه المقالة.
ثانيًا. نحتاج إلى فرز البيانات بناءً على مقياس المسافة الذي استخدمناه في الخطوة أعلاه.
ثالثا. اختر أعلى صفوف K في البيانات المحولة التي تم فرزها.
رابعا. ثم تقوم بتعيين فئة لنقطة الاختبار بناءً على فئة هذه الصفوف الأكثر شيوعًا.
الخطوة 4 - النهاية
كيفية تحديد قيمة K؟
نحتاج إلى تحديد قيمة K مناسبة لتحقيق أقصى دقة للنموذج ، ولكن لا توجد طرق إحصائية محددة مسبقًا للعثور على القيمة الأكثر ملاءمة لـ K. لكن معظمهم يستخدمون طريقة Elbow.
تبدأ طريقة الكوع بحساب مجموع الخطأ التربيعي (SSE) لبعض قيم k. SSE هو مجموع المسافة المربعة بين كل عضو في الكتلة والنقطة الوسطى.
SSE = ∑Ki = 1∑x ∈ cidist (x، ci) 2SSE = ∑∑ x ∈ cidist (x، ci) 2
إذا قمت برسم قيم مختلفة لـ k مقابل SSE ، يمكننا أن نرى أن الخطأ يتناقص مع زيادة قيمة k ، وهذا يحدث لأنه عندما يزداد عدد المجموعات ، ستميل المجموعات إلى أن تصبح أصغر ، لذلك سيكون التشويه أيضًا أصغر . فكرة طريقة الكوع هي اختيار k حيث يتناقص SSE فجأة للدلالة على شكل الكوع.
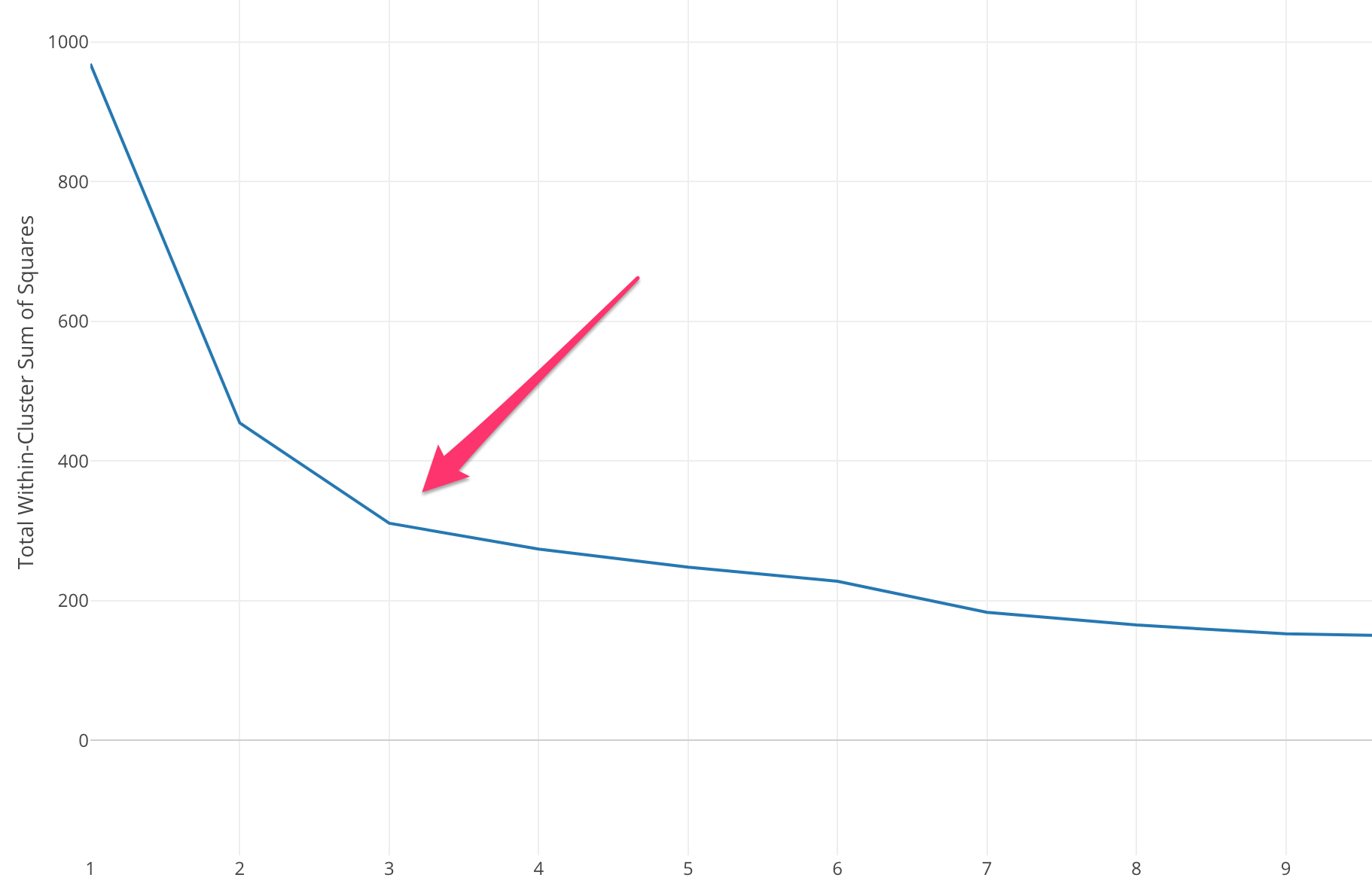
في بعض الحالات ، يوجد أكثر من مرفق ، أو لا يوجد كوع على الإطلاق. في مثل هذه الحالات ، ننتهي عادةً بحساب أفضل k من خلال تقييم مدى جودة أداء خوارزمية ML في سياق المشكلة التي تحاول حلها.
اقرأ أيضًا: نماذج التعلم الآلي
أنواع قياس المسافة
دعنا نتعرف على مقاييس المسافة المختلفة المستخدمة لحساب المسافة بين نقطتي بيانات واحدة تلو الأخرى.

1. المسافة الإقليدية - المسافة الإقليدية هي الجذر التربيعي لمجموع تربيع المسافة بين نقطتين.
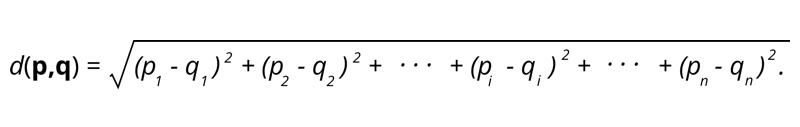 2. مسافة مانهاتن - مسافة مانهاتن هي مجموع القيم المطلقة للاختلافات بين نقطتين.
2. مسافة مانهاتن - مسافة مانهاتن هي مجموع القيم المطلقة للاختلافات بين نقطتين.
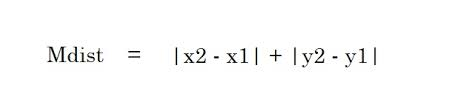 3. مسافة Minkowski - تستخدم مسافة Minkowski لإيجاد تشابه المسافة بين نقطتين. بناءً على الصيغة أدناه ، تتغير إما مسافة مانهاتن (عندما تكون ع = 1) والمسافة الإقليدية (عندما ع = 2).
3. مسافة Minkowski - تستخدم مسافة Minkowski لإيجاد تشابه المسافة بين نقطتين. بناءً على الصيغة أدناه ، تتغير إما مسافة مانهاتن (عندما تكون ع = 1) والمسافة الإقليدية (عندما ع = 2).
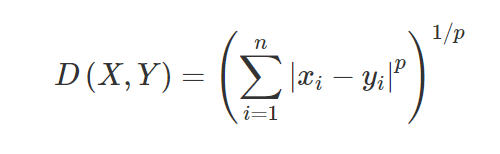 4. مسافة المطرقة - تستخدم مسافة المطرقة للمتغيرات الفئوية. سيحدد هذا المقياس ما إذا كان متغيرين فئتين متماثلان أم لا.
4. مسافة المطرقة - تستخدم مسافة المطرقة للمتغيرات الفئوية. سيحدد هذا المقياس ما إذا كان متغيرين فئتين متماثلان أم لا.
تطبيقات KNN
توقع التصنيف الائتماني للعميل الجديد بناءً على استخدامات ائتمان العملاء المتوفرة بالفعل وتقييماتهم.
- سواء كان للعقوبة على قرض أم لا؟ لمرشح.
- تصنيف معاملة معينة هو احتيالي أم لا.
- نظام التوصيات (يوتيوب ، نتفليكس)
- كشف خط اليد (مثل OCR).
- التعرف على الصور.
- التعرف على الفيديو.
إيجابيات وسلبيات KNN
يتكون التعلم الآلي من العديد من الخوارزميات ، لذلك لكل واحدة مزاياها وعيوبها. اعتمادًا على الصناعة والمجال ونوع البيانات ومقاييس التقييم المختلفة لكل خوارزمية ، يجب على عالم البيانات اختيار أفضل خوارزمية تناسب مشكلة الأعمال وتجيب عليها. دعونا نرى بعض إيجابيات وسلبيات K-Nearest Neighbours.
الايجابيات
- سهل الاستخدام والفهم والتفسير.
- وقت الحساب السريع.
- لا توجد افتراضات حول البيانات.
- دقة عالية في التنبؤات.
- متعدد الاستخدامات - يمكن استخدامه لكل من مشاكل الأعمال المتعلقة بالتصنيف والانحدار.
- يمكن استخدامها أيضًا في حل المشكلات متعددة الفئات.
- لدينا معلمة Hyper واحدة فقط للتعديل في خطوة Hyperparameter Tuning.
سلبيات
- مكلفة من الناحية الحسابية وتتطلب ذاكرة عالية حيث تقوم الخوارزمية بتخزين جميع بيانات التدريب.
- تصبح الخوارزمية أبطأ مع زيادة المتغيرات.
- إنه حساس جدًا للميزات غير ذات الصلة.
- لعنة الأبعاد.
- اختيار القيمة المثلى لـ K.
- فئة مجموعة البيانات غير المتوازنة سوف تسبب مشكلة.
- القيم المفقودة في البيانات تسبب أيضًا مشكلة.
يجب أن تقرأ: أفكار مشروع التعلم الآلي
خاتمة
هذه خوارزمية أساسية للتعلم الآلي تشتهر بسهولة الاستخدام ووقت الحساب السريع. ستكون هذه خوارزمية جيدة لاختيار ما إذا كنت جديدًا جدًا في Machine Learning World وترغب في إكمال المهمة المحددة دون الكثير من المتاعب.
إذا كنت مهتمًا بمعرفة المزيد حول التعلم الآلي ، فراجع دبلوم PG في IIIT-B & upGrad في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة ومهمة ، IIIT- حالة الخريجين B ، أكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع أفضل الشركات.
هل خوارزمية K-Nearest Neighbours باهظة الثمن؟
في حالة مجموعات البيانات الهائلة ، يمكن أن تكون خوارزمية K-Nearest Neighbours مكلفة من حيث وقت الحوسبة والتخزين. هذا لأن خوارزمية KNN هذه يجب أن تحفظ وتخزن جميع مجموعات بيانات التدريب لتعمل. KNN حساسة للغاية لمقياس بيانات التدريب لأنها تعتمد على حساب المسافات. لا تجلب هذه الخوارزمية النتائج بناءً على افتراضات حول بيانات التدريب. على الرغم من أن هذا قد لا يكون الحالة العامة عندما تفكر في خوارزميات التعلم الأخرى الخاضعة للإشراف ، فإن خوارزمية KNN تعتبر فعالة للغاية في حل المشكلات التي تأتي مع نقاط البيانات غير الخطية.
ما هي بعض التطبيقات العملية لخوارزمية K-NN؟
غالبًا ما تستخدم الشركات خوارزمية KNN للتوصية بمنتجات للأفراد الذين يشاركونهم اهتمامات مشتركة. على سبيل المثال ، يمكن للشركات اقتراح عروض تلفزيونية بناءً على اختيارات المشاهدين وتصميمات الملابس بناءً على عمليات الشراء السابقة وخيارات الفنادق والإقامة أثناء الجولات بناءً على سجل الحجوزات. يمكن أيضًا استخدامه من قبل المؤسسات المالية لتخصيص التصنيفات الائتمانية للعملاء بناءً على ميزات مالية مماثلة. تبني البنوك قراراتها المتعلقة بصرف القروض على تطبيقات محددة يبدو أنها تشترك في خصائص مماثلة للمتخلفين عن السداد. تشمل التطبيقات المتقدمة لهذه الخوارزمية التعرف على الصور واكتشاف خط اليد باستخدام التعرف الضوئي على الحروف وكذلك التعرف على الفيديو.
كيف يبدو المستقبل لمهندسي التعلم الآلي؟
مع المزيد من التطورات في الذكاء الاصطناعي والتعلم الآلي ، يبدو السوق أو الطلب على مهندسي التعلم الآلي واعدًا للغاية. بحلول النصف الأخير من عام 2021 ، كان هناك حوالي 23000 وظيفة مدرجة على LinkedIn لمهندسي التعلم الآلي. المنظمات العالمية العملاقة بدءًا من أمثال Amazon و Google إلى PayPal و Autodesk و Morgan Stanley و Accenture وغيرها ، دائمًا ما تبحث عن أفضل المواهب. من خلال الأساسيات القوية في مواضيع مثل البرمجة والإحصاءات والتعلم الآلي ، يمكن للمهندسين أيضًا تولي أدوار قيادية في تحليلات البيانات والأتمتة وتكامل الذكاء الاصطناعي ومجالات أخرى.