
Makine Öğreniminde K-En Yakın Komşular Algoritması [Örneklerle]
Yayınlanan: 2020-10-28İçindekiler
Tanıtım
Makine Öğrenimi, şüphesiz her saniye daha fazla miktarda veri topladığımız günümüzün veri odaklı dünyasında en gelişen ve güçlü teknolojilerden biridir. Bu, her alanın ve her sektörün kendi kullanım durumları ve projelerine sahip olduğu, hızla büyüyen teknolojilerden biridir.
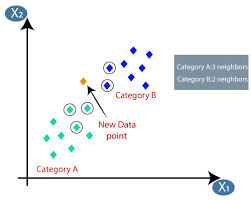
Makine Öğrenimi veya Model Geliştirme, aynı zamanda en önemlilerinden biri gibi görünen bir Veri Bilimi Projesi Yaşam Döngüsünün aşamalarından biridir. Bu makale, Makine Öğreniminde KNN'ye (K-En Yakın Komşular) bir giriş olarak tasarlanmıştır.
K-En Yakın Komşular
Makine öğrenimine aşinaysanız veya Veri Bilimi veya AI ekibinin bir parçasıysanız, muhtemelen k-En Yakın Komşular algoritmasını veya KNN olarak adlandırılan basit algoritmayı duymuşsunuzdur. Bu algoritma, uygulanması kolay, parametrik olmayan, tembel öğrenme ve hesaplama süresinin düşük olması nedeniyle makine öğrenmesinde kullanılan algoritmalardan biridir.
k-Nearest Neighbors algoritmasının bir diğer avantajı da Problemlerin hem Sınıflandırma hem de Regresyon tipinde kullanılabilmesidir. Bu ikisi arasındaki farkın farkında değilseniz, o zaman size açıklığa kavuşturmama izin verin, Sınıflandırma ve Regresyon arasındaki temel fark, regresyondaki çıktı değişkeninin sayısal (Sürekli), sınıflandırma için olanın ise kategorik (Ayrık) olmasıdır.
Okuyun: R'de KNN Algoritmaları
k-En Yakın Komşular nasıl çalışır?
K-en yakın komşular (KNN) algoritması, yeni bir veri noktasının içine düştüğü kümeyi tahmin etmek için 'özellik benzerliği' veya 'en yakın komşular' tekniğini kullanır. Aşağıda, bu algoritmanın çalışmasını daha iyi anlayabileceğimiz birkaç adım bulunmaktadır.

Adım 1 − Makine öğreniminde herhangi bir algoritmayı uygulamak için modellemeye hazır temizlenmiş bir veri setine ihtiyacımız var. Halihazırda eğitim ve test veri setine bölünmüş temizlenmiş bir veri setimiz olduğunu varsayalım.
Adım 2 − Veri setleri zaten hazır olduğundan, algoritmayı uygulamak için en yakın kaç veri noktasını dikkate almamız gerektiğini söyleyen K (tamsayı) değerini seçmemiz gerekiyor. k değerinin nasıl belirleneceğini yazının ilerleyen aşamalarında öğrenebiliriz.
Adım 3 - Bu adım yinelemeli bir adımdır ve veri kümesindeki her veri noktası için uygulanması gerekir.
I. Mesafe metriklerinden herhangi birini kullanarak test verileri ile her eğitim verisi satırı arasındaki mesafeyi hesaplayın
a. Öklid mesafesi
B. Manhattan mesafesi
C. Minkowski mesafesi
D. Hamming mesafesi.
Birçok veri bilimcisi Öklid mesafesini kullanma eğilimindedir, ancak bu makalenin sonraki aşamalarında her birinin önemini öğrenebiliriz.
II. Yukarıdaki adımda kullandığımız mesafe ölçümüne göre verileri sıralamamız gerekiyor.
III. Dönüştürülen sıralanmış verilerde en üstteki K satırını seçin.
IV. Ardından, bu satırların en sık görülen sınıfına dayalı olarak test noktasına bir sınıf atayacaktır.
Adım 4 – Bitir
K değeri nasıl belirlenir?
Modelin maksimum doğruluğunu elde etmek için uygun bir K değeri seçmemiz gerekiyor, ancak K'nin en uygun değerini bulmak için önceden tanımlanmış istatistiksel yöntemler yok. Ancak çoğu Dirsek Yöntemini kullanıyor.
Dirsek yöntemi, bazı k değerleri için Kare Hatalarının Toplamının (SSE) hesaplanmasıyla başlar. SSE, kümenin her bir üyesi ile merkezi arasındaki uzaklığın karesinin toplamıdır.
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
SSE'ye karşı farklı k değerleri çizerseniz, k'nin değeri büyüdükçe hatanın azaldığını görebiliriz, bunun nedeni küme sayısı arttıkça kümelerin küçülme eğiliminde olması, dolayısıyla bozulmanın da daha küçük olması . Dirsek yönteminin fikri, dirsek şeklini belirten SSE'nin aniden azaldığı k'yi seçmektir.
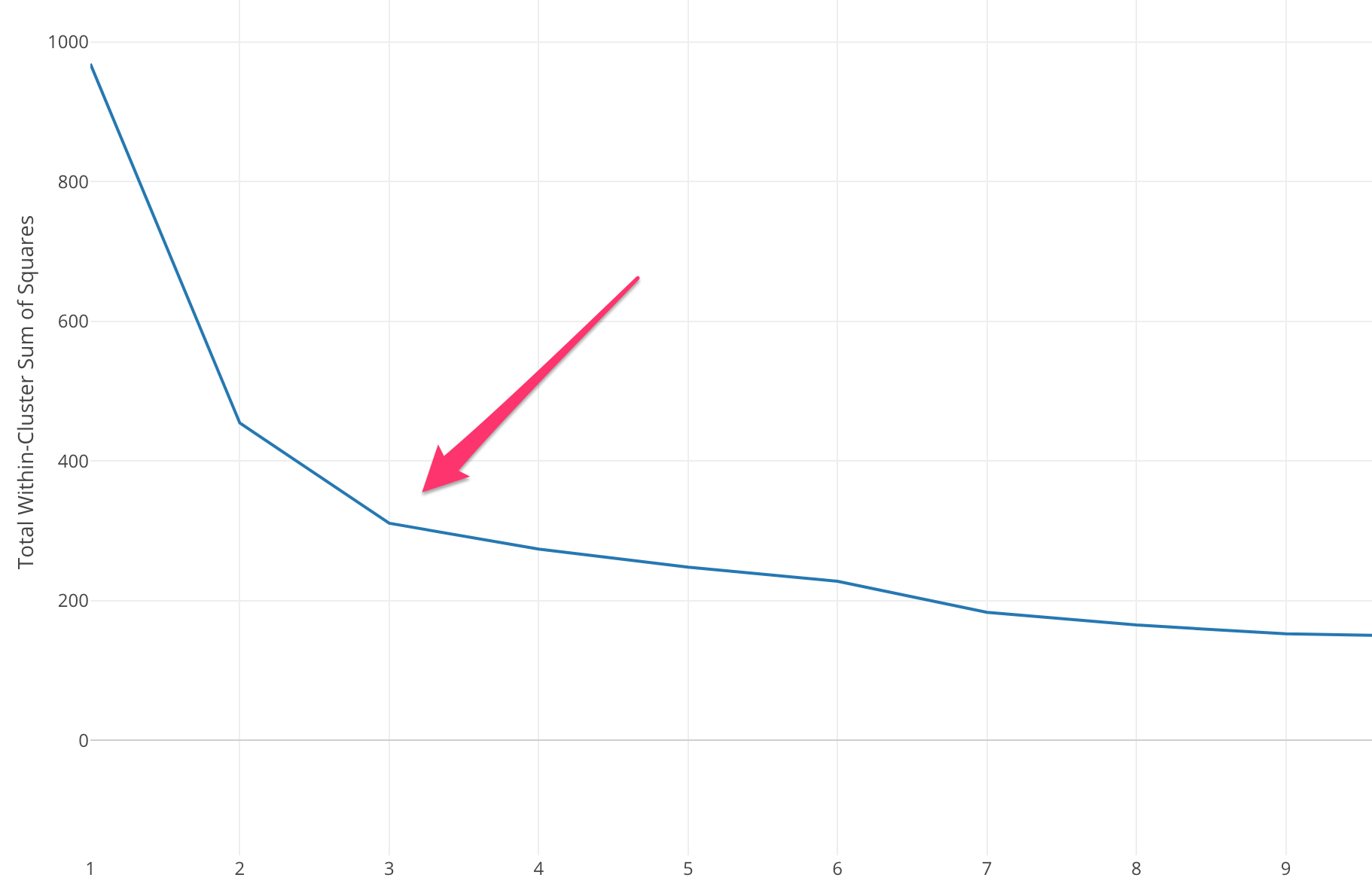
Bazı durumlarda, birden fazla dirsek vardır veya hiç dirsek yoktur. Bu gibi durumlarda, genellikle k-means ML Algoritmasının çözmeye çalıştığınız problem bağlamında ne kadar iyi performans gösterdiğini değerlendirerek en iyi k'yi hesaplıyoruz.
Ayrıca Okuyun: Makine Öğrenimi Modelleri
Mesafe Metrik Türleri
İki veri noktası arasındaki mesafeyi tek tek hesaplamak için kullanılan farklı mesafe metriklerini öğrenelim.

1. Öklid mesafesi – Öklid mesafesi, iki nokta arasındaki uzaklığın karesinin toplamının kareköküdür.
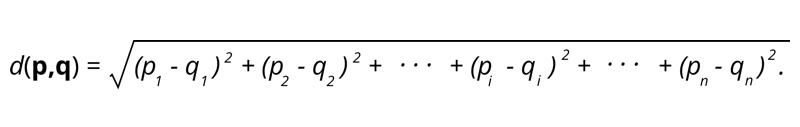 2. Manhattan mesafesi – Manhattan mesafesi, iki nokta arasındaki farkların mutlak değerlerinin toplamıdır.
2. Manhattan mesafesi – Manhattan mesafesi, iki nokta arasındaki farkların mutlak değerlerinin toplamıdır.
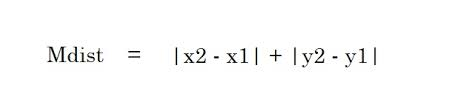 3. Minkowski mesafesi – Minkowski mesafesi, iki nokta arasındaki mesafe benzerliğini bulmak için kullanılır. Aşağıdaki formüle göre Manhattan mesafesi (p=1 olduğunda) ve Öklid mesafesi (p=2 olduğunda) olarak değişir.
3. Minkowski mesafesi – Minkowski mesafesi, iki nokta arasındaki mesafe benzerliğini bulmak için kullanılır. Aşağıdaki formüle göre Manhattan mesafesi (p=1 olduğunda) ve Öklid mesafesi (p=2 olduğunda) olarak değişir.
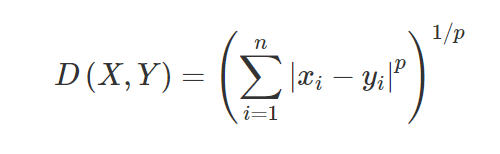 4. Hamming mesafesi – Kategorik değişkenler için Hamming mesafesi kullanılır. Bu metrik, iki kategorik değişkenin aynı olup olmadığını söyleyecektir.
4. Hamming mesafesi – Kategorik değişkenler için Hamming mesafesi kullanılır. Bu metrik, iki kategorik değişkenin aynı olup olmadığını söyleyecektir.
KNN Uygulamaları
Halihazırda mevcut müşterilerin kredi kullanımlarına ve derecelendirmelerine dayalı olarak yeni bir müşterinin Kredi notunu tahmin etme.
- Krediye onay verilip verilmeyeceği? bir adaya.
- Verilen işlemin sınıflandırılması hileli olup olmadığıdır.
- Öneri Sistemi (YouTube, Netflix)
- El yazısı algılama (OCR gibi).
- Görüntü tanıma.
- Video tanıma.
KNN'nin Artıları ve Eksileri
Makine Öğrenimi birçok algoritmadan oluşur, bu nedenle her birinin kendine göre avantajları ve dezavantajları vardır. Sektöre, etki alanına ve veri türüne ve her algoritma için farklı değerlendirme ölçütlerine bağlı olarak, bir Veri Bilimcisi İş sorununa uyan ve yanıtlayan en iyi algoritmayı seçmelidir. K-En Yakın Komşuların birkaç Artılarını ve Eksilerini görelim.
Artıları
- Kullanımı, anlaşılması ve yorumlanması kolaydır.
- Hızlı hesaplama süresi.
- Veriler hakkında varsayım yok.
- Tahminlerin yüksek doğruluğu.
- Çok Yönlü – Hem Sınıflandırma hem de Regresyon İş Problemleri için kullanılabilir.
- Çok Sınıflı Problemler için de kullanılabilir.
- Hiperparametre Ayarlama adımında ince ayar yapmak için yalnızca bir Hiper parametremiz var.
Eksileri
- Algoritma tüm eğitim verilerini sakladığından hesaplama açısından pahalıdır ve yüksek bellek gerektirir.
- Değişkenler arttıkça algoritma yavaşlar.
- Alakasız özelliklere karşı çok hassastır.
- Boyutluluğun Laneti.
- K'nin optimal değerini seçme.
- Sınıf Dengesiz veri kümesi soruna neden olur.
- Verilerde eksik değerler de sorun yaratır.
Mutlaka Okuyun: Makine Öğrenimi Proje Fikirleri
Çözüm
Bu, yaygın olarak kullanım kolaylığı ve hızlı hesaplama süresi ile bilinen temel bir makine öğrenimi algoritmasıdır. Bu, Makine Öğrenimi Dünyasında çok yeniyseniz ve verilen görevi fazla güçlük çekmeden tamamlamak istiyorsanız, seçmek için iyi bir algoritma olacaktır.
Makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 450+ saat zorlu eğitim, 30'dan fazla vaka çalışması ve ödev, IIIT- sunan IIIT-B & upGrad'ın Makine Öğrenimi ve Yapay Zeka PG Diplomasına göz atın. B Mezun statüsü, 5+ pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.
K-En Yakın Komşular algoritması pahalı mı?
Muazzam veri kümeleri söz konusu olduğunda, K-Nearest Neighbors algoritması hem hesaplama süresi hem de depolama açısından pahalı olabilir. Bunun nedeni, bu KNN algoritmasının çalışması için tüm eğitim veri kümelerini kaydetmesi ve saklaması gerektiğidir. KNN, mesafelerin hesaplanmasına bağlı olduğu için eğitim verilerinin ölçeğine oldukça duyarlıdır. Bu algoritma, eğitim verileriyle ilgili varsayımlara dayalı sonuçları getirmez. Diğer denetimli öğrenme algoritmalarını düşündüğünüzde bu genel bir durum olmasa da, KNN algoritmasının doğrusal olmayan veri noktalarıyla gelen sorunları çözmede oldukça etkili olduğu düşünülmektedir.
K-NN algoritmasının pratik uygulamalarından bazıları nelerdir?
KNN algoritması genellikle işletmeler tarafından ortak ilgi alanlarını paylaşan bireylere ürün önermek için kullanılır. Örneğin şirketler, izleyici tercihlerine göre TV şovları, önceki satın almalara göre giyim tasarımları ve rezervasyon geçmişine göre turlar sırasında otel ve konaklama seçenekleri önerebilir. Benzer finansal özelliklere dayalı olarak müşterilere kredi notu atamak için finansal kuruluşlar tarafından da kullanılabilir. Bankalar, kredi ödeme kararlarını, temerrüde düşenlere benzer özellikleri paylaştığı görülen belirli uygulamalara dayandırır. Bu algoritmanın gelişmiş uygulamaları, görüntü tanıma, OCR kullanarak el yazısı algılama ve video tanımayı içerir.
Makine öğrenimi mühendisleri için gelecek nasıl görünüyor?
Yapay zeka ve makine öğrenimindeki diğer gelişmelerle birlikte, makine öğrenimi mühendisleri için pazar veya talep çok umut verici görünüyor. 2021'in ikinci yarısında, makine öğrenimi mühendisleri için LinkedIn'de listelenen yaklaşık 23.000 iş vardı. Amazon ve Google gibi şirketlerden PayPal, Autodesk, Morgan Stanley, Accenture ve diğerlerine kadar küresel dev kuruluşlar her zaman en iyi yeteneklerin peşindedir. Programlama, istatistik, makine öğrenimi gibi konularda güçlü temellere sahip mühendisler, veri analitiği, otomasyon, yapay zeka entegrasyonu ve diğer alanlarda da liderlik rolleri üstlenebilirler.