
Algoritmul K-Nearest Neighbors în Machine Learning [cu exemple]
Publicat: 2020-10-28Cuprins
Introducere
Învățarea automată este, fără îndoială, una dintre cele mai actuale și puternice tehnologii din lumea actuală bazată pe date, unde colectăm mai multe cantități de date în fiecare secundă. Aceasta este una dintre tehnologiile cu creștere rapidă în care fiecare domeniu și fiecare sector are propriile cazuri de utilizare și proiecte.
Învățarea automată sau dezvoltarea modelelor este una dintre fazele ciclului de viață al unui proiect de știință a datelor, care pare să fie și una dintre cele mai importante. Acest articol este conceput ca o introducere în KNN (K-Nearest Neighbors) în Machine Learning.
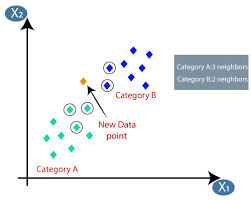
K-Cei mai apropiati vecini
Dacă sunteți familiarizat cu învățarea automată sau ați făcut parte din echipa Data Science sau AI, atunci probabil ați auzit de algoritmul k-Nearest Neighbors, sau simplu numit KNN. Acest algoritm este unul dintre algoritmii folosiți în învățarea automată, deoarece este ușor de implementat, neparametric, învățare leneșă și are un timp de calcul redus.
Un alt avantaj al algoritmului k-Nearest Neighbors este că poate fi folosit atât pentru probleme de tipul de clasificare, cât și de regresie. Dacă nu sunteți conștient de diferența dintre aceste două, atunci permiteți-mi să vă explic, principala diferență dintre clasificare și regresie este că variabila de ieșire în regresie este numerică (continuă), în timp ce cea pentru clasificare este categorică (discretă).
Citiți: Algoritmi KNN în R
Cum funcționează k-Nearest Neighbours?
Algoritmul K-nearest neighbors (KNN) folosește tehnica „asemănarea caracteristicilor” sau „cele mai apropiate vecini” pentru a prezice clusterul în care se încadrează un nou punct de date. Mai jos sunt câțiva pași pe baza cărora putem înțelege mai bine funcționarea acestui algoritm

Pasul 1 - Pentru implementarea oricărui algoritm în Machine Learning, avem nevoie de un set de date curățat gata pentru modelare. Să presupunem că avem deja un set de date curățat care a fost împărțit în set de date de antrenament și de testare.
Pasul 2 - Deoarece avem deja seturile de date pregătite, trebuie să alegem valoarea lui K (întreg) care ne spune câte puncte de date cele mai apropiate trebuie să luăm în considerare pentru a implementa algoritmul. Putem afla cum să determinăm valoarea k în etapele ulterioare ale articolului.
Pasul 3 - Acest pas este unul iterativ și trebuie aplicat pentru fiecare punct de date din setul de date
I. Calculați distanța dintre datele de testare și fiecare rând de date de antrenament utilizând oricare dintre metrica distanței
A. distanta euclidiana
b. Distanța de Manhattan
c. distanta Minkowski
d. Distanța Hamming.
Mulți cercetători tind să folosească distanța euclidiană, dar putem cunoaște semnificația fiecăruia în etapa ulterioară a acestui articol.
II. Trebuie să sortăm datele în funcție de metrica distanței pe care am folosit-o în pasul de mai sus.
III. Alegeți K rândurile de sus din datele sortate transformate.
IV. Apoi va atribui o clasă punctului de testare pe baza clasei cele mai frecvente din aceste rânduri.
Pasul 4 - Sfârșit
Cum se determină valoarea K?
Trebuie să selectăm o valoare K adecvată pentru a obține acuratețea maximă a modelului, dar nu există metode statistice predefinite pentru a găsi cea mai favorabilă valoare a lui K. Dar majoritatea folosesc metoda cotului.
Metoda cotului începe cu calcularea Sumei Erorii Pătrate (SSE) pentru unele valori ale lui k. SSE este suma distanței pătrate dintre fiecare membru al clusterului și centroidul acestuia.
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
Dacă trasați diferite valori ale lui k în raport cu SSE, putem vedea că eroarea scade pe măsură ce valoarea lui k devine mai mare, acest lucru se întâmplă deoarece atunci când numărul de clustere crește, clusterele vor tinde să devină mai mici, astfel încât distorsiunea va fi, de asemenea, mai mică. . Ideea metodei cotului este de a alege k la care SSE scade brusc semnificând forma cotului.
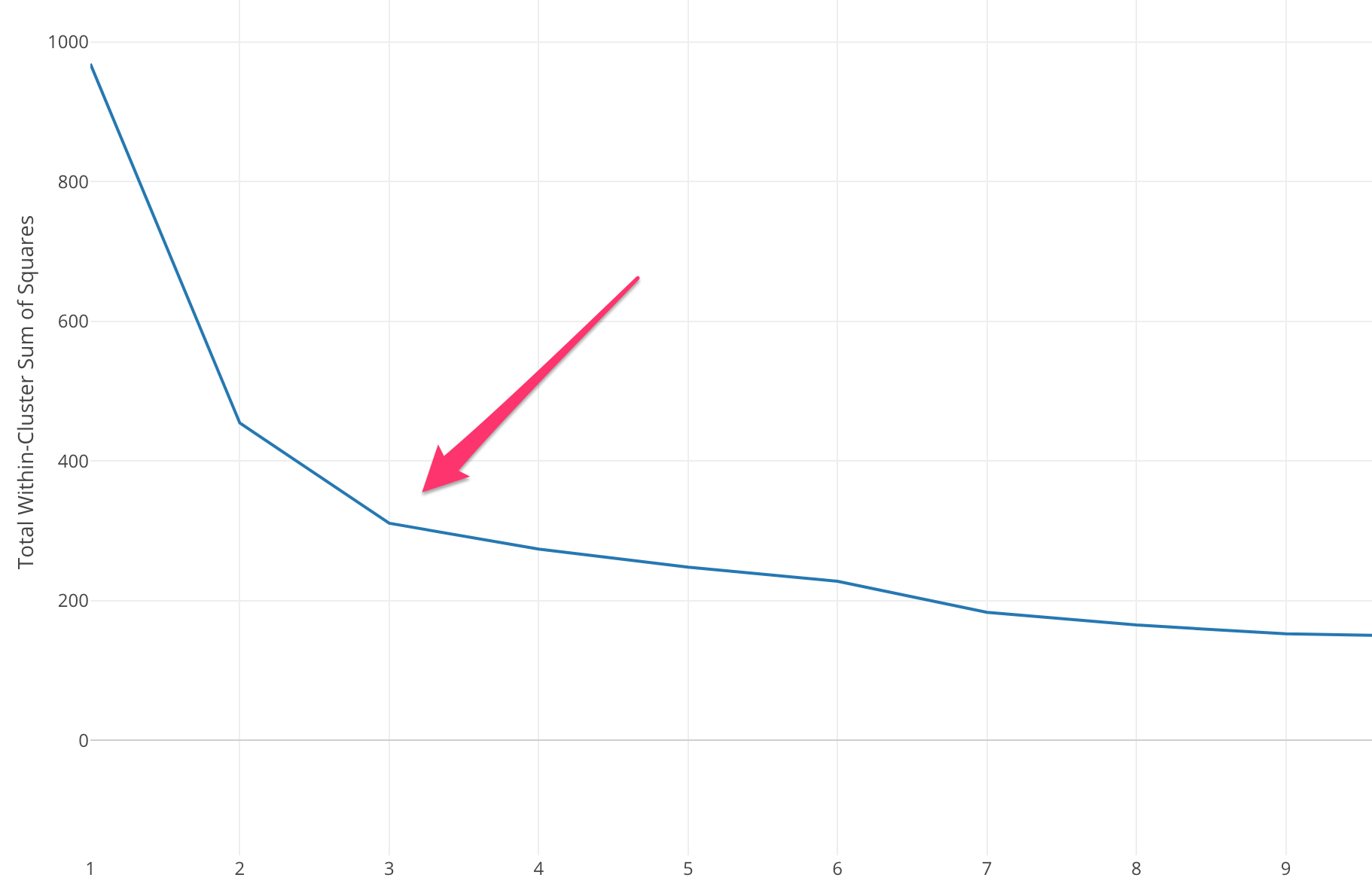
În unele cazuri, există mai mult de un cot sau nu există deloc. În astfel de cazuri ajungem, de obicei, să calculăm cel mai bun k evaluând cât de bine funcționează algoritmul k-means ML în contextul problemei pe care încercați să o rezolvați.
Citiți și: Modele de învățare automată
Tipuri de metrică de distanță
Să facem cunoștință despre diferitele valori ale distanței utilizate pentru a calcula distanța dintre două puncte de date unul câte unul.

1. Distanța euclidiană – Distanța euclidiană este rădăcina pătrată a sumei pătratelor distanței dintre două puncte.
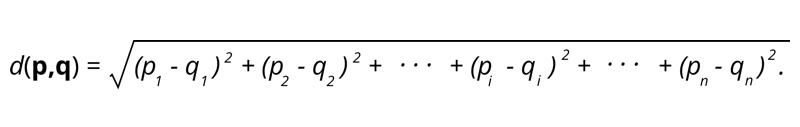 2. Distanța Manhattan – Distanța Manhattan este suma valorilor absolute ale diferențelor dintre două puncte.
2. Distanța Manhattan – Distanța Manhattan este suma valorilor absolute ale diferențelor dintre două puncte.
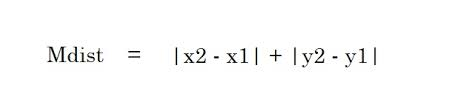 3. Distanța Minkowski – Distanța Minkowski este folosită pentru a găsi asemănarea distanței între două puncte. Pe baza formulei de mai jos, se schimbă fie distanța Manhattan (când p=1) și distanța euclidiană (când p=2).
3. Distanța Minkowski – Distanța Minkowski este folosită pentru a găsi asemănarea distanței între două puncte. Pe baza formulei de mai jos, se schimbă fie distanța Manhattan (când p=1) și distanța euclidiană (când p=2).
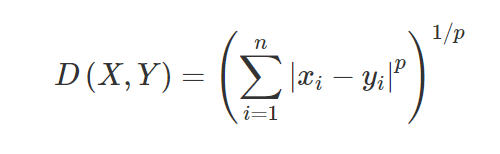 4. Distanța de hamming – Distanța de hamming este utilizată pentru variabilele categoriale. Această măsurătoare va spune dacă două variabile categorice sunt identice sau nu.
4. Distanța de hamming – Distanța de hamming este utilizată pentru variabilele categoriale. Această măsurătoare va spune dacă două variabile categorice sunt identice sau nu.
Aplicații ale KNN
Prezicerea ratingului de credit al unui nou client pe baza utilizărilor și evaluărilor creditului clienților deja disponibili.
- Dacă să sancționăm sau nu un împrumut? unui candidat.
- Clasificarea unei anumite tranzacții este sau nu frauduloasă.
- Sistem de recomandare (YouTube, Netflix)
- Detectarea scrisului de mână (cum ar fi OCR).
- Recunoașterea imaginilor.
- Recunoaștere video.
Avantaje și dezavantaje ale KNN
Machine Learning constă din mulți algoritmi, astfel încât fiecare are propriile sale avantaje și dezavantaje. În funcție de industrie, domeniu și tipul de date și diferitele valori de evaluare pentru fiecare algoritm, un Data Scientist ar trebui să aleagă cel mai bun algoritm care se potrivește și răspunde problemei de afaceri. Să vedem câteva avantaje și dezavantaje ale vecinilor K-Nearest.
Pro
- Ușor de utilizat, înțeles și interpretat.
- Timp de calcul rapid.
- Fără presupuneri despre date.
- Precizie ridicată a predicțiilor.
- Versatil – Poate fi folosit atât pentru probleme de afaceri de clasificare, cât și de regresie.
- Poate fi folosit și pentru probleme cu mai multe clase.
- Avem un singur parametru Hyper de modificat la pasul de ajustare a hiperparametrului.
Contra
- Costos din punct de vedere informatic și necesită memorie mare, deoarece algoritmul stochează toate datele de antrenament.
- Algoritmul devine mai lent pe măsură ce variabilele cresc.
- Este foarte sensibil la caracteristicile irelevante.
- Blestemul dimensionalității.
- Alegerea valorii optime a lui K.
- Setul de date dezechilibrat de clasă va cauza probleme.
- Valorile lipsă din date cauzează, de asemenea, probleme.
Trebuie citit: Idei de proiecte de învățare automată
Concluzie
Acesta este un algoritm fundamental de învățare automată, cunoscut în mod popular pentru ușurința în utilizare și timpul de calcul rapid. Acesta ar fi un algoritm decent de ales dacă sunteți foarte nou în Machine Learning World și doriți să finalizați sarcina dată fără prea multe bătăi de cap.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Este algoritmul K-Nearest Neighbours scump?
În cazul unor seturi de date enorme, algoritmul K-Nearest Neighbors poate fi costisitor atât din punct de vedere al timpului de calcul, cât și al stocării. Acest lucru se datorează faptului că acest algoritm KNN trebuie să salveze și să stocheze toate seturile de date de antrenament pentru a funcționa. KNN este foarte sensibil la scara datelor de antrenament, deoarece depinde de calcularea distanțelor. Acest algoritm nu preia rezultate bazate pe ipoteze despre datele de antrenament. Chiar dacă acesta ar putea să nu fie cazul general atunci când luați în considerare alți algoritmi de învățare supravegheată, algoritmul KNN este considerat extrem de eficient în rezolvarea problemelor care vin cu puncte de date neliniare.
Care sunt unele dintre aplicațiile practice ale algoritmului K-NN?
Algoritmul KNN este adesea folosit de companii pentru a recomanda produse persoanelor care împărtășesc interese comune. De exemplu, companiile pot sugera emisiuni TV pe baza opțiunilor spectatorilor, modele de îmbrăcăminte bazate pe achiziții anterioare și opțiuni de cazare și hotel în timpul tururilor pe baza istoricului rezervărilor. De asemenea, poate fi folosit de instituțiile financiare pentru a atribui ratinguri de credit clienților pe baza unor caracteristici financiare similare. Băncile își bazează deciziile de acordare a împrumutului pe aplicații specifice care par să împărtășească caracteristici similare celor care ne plătesc plăți. Aplicațiile avansate ale acestui algoritm includ recunoașterea imaginilor, detectarea scrisului de mână folosind OCR, precum și recunoașterea video.
Cum arată viitorul pentru inginerii de învățare automată?
Odată cu progresele ulterioare în AI și învățarea automată, piața sau cererea de ingineri de învățare automată arată foarte promițătoare. Până în a doua jumătate a anului 2021, erau în jur de 23.000 de locuri de muncă listate pe LinkedIn pentru inginerii de învățare automată. Organizațiile gigantice globale, de la Amazon și Google până la PayPal, Autodesk, Morgan Stanley, Accenture și altele, caută mereu talentele de top. Având baze solide în subiecte precum programarea, statistica, învățarea automată, inginerii își pot asuma și roluri de conducere în analiza datelor, automatizare, integrarea AI și alte domenii.