
Algoritmo K-Nearest Neighbors in Machine Learning [con esempi]
Pubblicato: 2020-10-28Sommario
introduzione
L'apprendimento automatico è senza dubbio una delle tecnologie più potenti e all'avanguardia nell'odierno mondo basato sui dati, in cui raccogliamo più quantità di dati ogni singolo secondo. Questa è una delle tecnologie in rapida crescita in cui ogni dominio e ogni settore ha i propri casi d'uso e progetti.
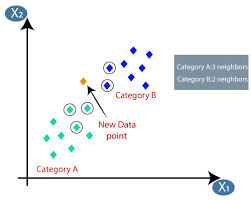
L'apprendimento automatico o lo sviluppo di modelli è una delle fasi del ciclo di vita di un progetto di scienza dei dati che sembra essere anche una delle più importanti. Questo articolo è concepito come un'introduzione a KNN (K-Nearest Neighbors) in Machine Learning.
K-vicini più vicini
Se hai familiarità con l'apprendimento automatico o hai fatto parte del team di Data Science o AI, probabilmente hai sentito parlare dell'algoritmo k-Nearest Neighbors, o semplicemente chiamato KNN. Questo algoritmo è uno degli algoritmi più utilizzati nell'apprendimento automatico perché è facile da implementare, non parametrico, apprendimento pigro e ha tempi di calcolo ridotti.
Un altro vantaggio dell'algoritmo k-Nearest Neighbors è che può essere utilizzato sia per problemi di tipo Classificazione che Regressione. Se non sei a conoscenza della differenza tra questi due, lascia che te lo chiarisca, la differenza principale tra Classificazione e Regressione è che la variabile di output nella regressione è numerica (Continua) mentre quella per la classificazione è categoriale (Discreta).
Leggi: Algoritmi KNN in R
Come funziona k-Nearest Neighbors?
L'algoritmo K-nearest neighbors (KNN) utilizza la tecnica "feature similarity" o "neest neighbors" per prevedere il cluster in cui cade un nuovo punto dati. Di seguito sono riportati i pochi passaggi in base ai quali possiamo comprendere meglio il funzionamento di questo algoritmo

Passaggio 1 : per implementare qualsiasi algoritmo in Machine learning, abbiamo bisogno di un set di dati pulito pronto per la modellazione. Supponiamo di avere già un set di dati pulito che è stato suddiviso in set di dati di addestramento e test.
Passaggio 2 − Poiché abbiamo già i set di dati pronti, dobbiamo scegliere il valore di K (intero) che ci dice quanti punti dati più vicini dobbiamo prendere in considerazione per implementare l'algoritmo. Possiamo imparare a determinare il valore k nelle fasi successive dell'articolo.
Passaggio 3 : questo passaggio è iterativo e deve essere applicato per ciascun punto dati nel set di dati
I. Calcolare la distanza tra i dati del test e ciascuna riga di dati di allenamento utilizzando una qualsiasi delle metriche di distanza
un. Distanza euclidea
B. Distanza di Manhattan
C. Distanza Minkowski
D. Distanza di Hamming.
Molti data scientist tendono a utilizzare la distanza euclidea, ma possiamo conoscere il significato di ciascuna nella fase successiva di questo articolo.
II. Dobbiamo ordinare i dati in base alla metrica della distanza che abbiamo utilizzato nel passaggio precedente.
III. Scegli le prime K righe nei dati ordinati trasformati.
IV. Quindi assegnerà una classe al punto di test in base alla classe più frequente di queste righe.
Passaggio 4 - Fine
Come determinare il valore K?
Dobbiamo selezionare un valore K appropriato per ottenere la massima accuratezza del modello, ma non ci sono metodi statistici predefiniti per trovare il valore più favorevole di K. Ma la maggior parte di essi usa il metodo del gomito.
Il metodo del gomito inizia con il calcolo della somma degli errori quadrati (SSE) per alcuni valori di k. L'SSE è la somma della distanza al quadrato tra ciascun membro del cluster e il suo baricentro.
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
Se si tracciano diversi valori di k rispetto a SSE, possiamo vedere che l'errore diminuisce all'aumentare del valore di k, questo accade perché quando il numero di cluster aumenta, i cluster tenderanno a diventare più piccoli, quindi anche la distorsione sarà minore . L'idea del metodo del gomito è di scegliere la k alla quale il SSE diminuisce improvvisamente a significare la forma del gomito.
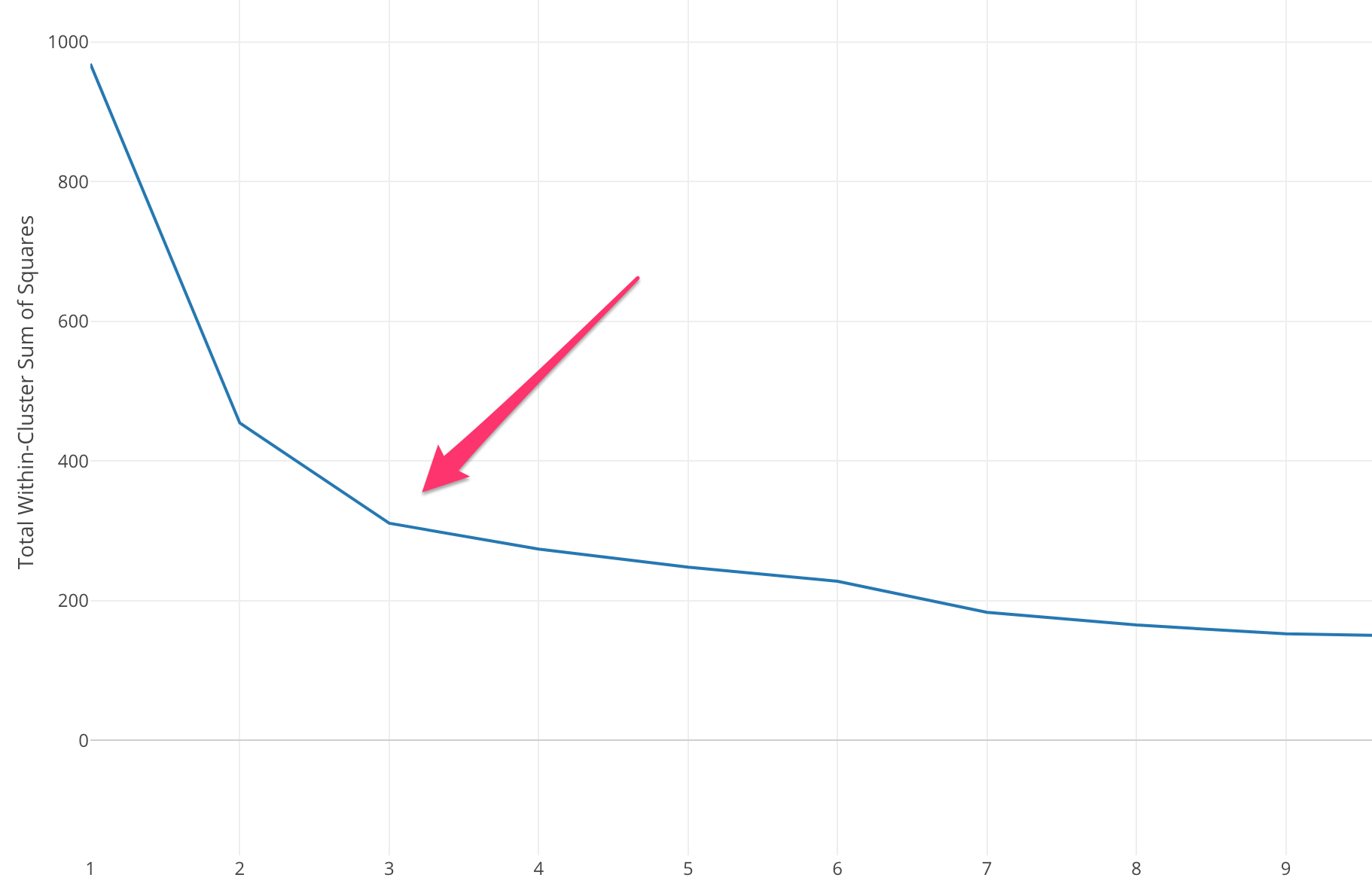
In alcuni casi, ci sono più di un gomito o nessun gomito. In questi casi di solito finiamo per calcolare il miglior k valutando quanto bene k-mean Algoritmo ML si comporta nel contesto del problema che stai cercando di risolvere.
Leggi anche: Modelli di Machine Learning
Tipi di distanza metrica
Conosciamo le diverse metriche di distanza utilizzate per calcolare la distanza tra due punti dati uno per uno.
1. Distanza euclidea – La distanza euclidea è la radice quadrata della somma della distanza al quadrato tra due punti.

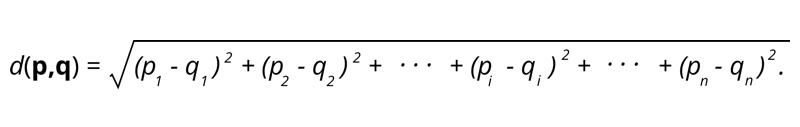 2. Distanza di Manhattan – La distanza di Manhattan è la somma dei valori assoluti delle differenze tra due punti.
2. Distanza di Manhattan – La distanza di Manhattan è la somma dei valori assoluti delle differenze tra due punti.
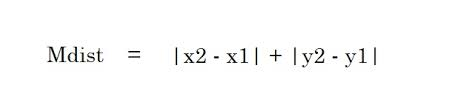 3. Distanza di Minkowski – La distanza di Minkowski viene utilizzata per trovare la somiglianza della distanza tra due punti. In base alla formula seguente cambia in distanza Manhattan (quando p=1) e distanza euclidea (quando p=2).
3. Distanza di Minkowski – La distanza di Minkowski viene utilizzata per trovare la somiglianza della distanza tra due punti. In base alla formula seguente cambia in distanza Manhattan (quando p=1) e distanza euclidea (quando p=2).
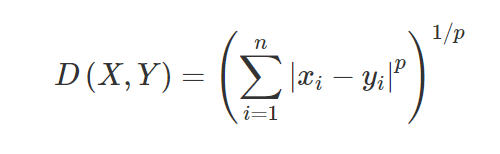 4. Distanza di Hamming – La distanza di Hamming viene utilizzata per le variabili categoriali. Questa metrica dirà se due variabili categoriali sono uguali o meno.
4. Distanza di Hamming – La distanza di Hamming viene utilizzata per le variabili categoriali. Questa metrica dirà se due variabili categoriali sono uguali o meno.
Applicazioni di KNN
Previsione del rating di credito di un nuovo cliente in base agli utilizzi e alle valutazioni del credito già disponibili dei clienti.
- Se sanzionare o meno un prestito? a un candidato.
- Classificare una determinata transazione è fraudolenta o meno.
- Sistema di raccomandazione (YouTube, Netflix)
- Rilevamento della grafia (come l'OCR).
- Riconoscimento delle immagini.
- Riconoscimento video.
Pro e contro di KNN
L'apprendimento automatico è costituito da molti algoritmi, quindi ognuno ha i suoi vantaggi e svantaggi. A seconda del settore, del dominio e del tipo di dati e delle diverse metriche di valutazione per ciascun algoritmo, un Data Scientist dovrebbe scegliere l'algoritmo migliore che si adatta e risponde al problema aziendale. Vediamo alcuni pro e contro di K-Nearest Neighbors.
Professionisti
- Facile da usare, capire e interpretare.
- Tempo di calcolo rapido.
- Nessuna ipotesi sui dati.
- Elevata precisione delle previsioni.
- Versatile: può essere utilizzato sia per problemi di classificazione che di regressione.
- Può essere utilizzato anche per problemi multiclasse.
- Abbiamo solo un parametro Hyper da modificare nella fase di ottimizzazione di Hyperparameter.
contro
- Computazionalmente costoso e richiede memoria elevata poiché l'algoritmo memorizza tutti i dati di addestramento.
- L'algoritmo diventa più lento all'aumentare delle variabili.
- È molto sensibile a caratteristiche irrilevanti.
- Maledizione della dimensionalità.
- Scegliere il valore ottimale di K.
- Il set di dati di classe sbilanciato causerà problemi.
- Anche i valori mancanti nei dati causano problemi.
Da leggere: idee per progetti di apprendimento automatico
Conclusione
Questo è un algoritmo di apprendimento automatico fondamentale che è popolarmente noto per facilità d'uso e tempi di calcolo rapidi. Questo sarebbe un algoritmo decente da scegliere se sei molto nuovo in Machine Learning World e desideri completare l'attività assegnata senza troppi problemi.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
L'algoritmo K-Nearest Neighbors è costoso?
Nel caso di enormi set di dati, l'algoritmo K-Nearest Neighbors può essere costoso sia in termini di tempo di calcolo che di archiviazione. Questo perché questo algoritmo KNN deve salvare e archiviare tutti i set di dati di addestramento per funzionare. KNN è altamente sensibile alla scala dei dati di allenamento poiché dipende dal calcolo delle distanze. Questo algoritmo non recupera i risultati sulla base di ipotesi sui dati di addestramento. Anche se questo potrebbe non essere il caso generale quando si considerano altri algoritmi di apprendimento supervisionato, l'algoritmo KNN è considerato altamente efficace nella risoluzione dei problemi che derivano da punti dati non lineari.
Quali sono alcune delle applicazioni pratiche dell'algoritmo K-NN?
L'algoritmo KNN viene spesso utilizzato dalle aziende per consigliare prodotti a persone che condividono interessi comuni. Ad esempio, le aziende possono suggerire programmi TV in base alle scelte degli spettatori, modelli di abbigliamento basati su acquisti precedenti e opzioni di hotel e alloggio durante i tour in base alla cronologia delle prenotazioni. Può anche essere impiegato dalle istituzioni finanziarie per assegnare rating di credito ai clienti sulla base di caratteristiche finanziarie simili. Le banche basano le loro decisioni di erogazione del prestito su richieste specifiche che sembrano condividere caratteristiche simili agli inadempienti. Le applicazioni avanzate di questo algoritmo includono il riconoscimento delle immagini, il rilevamento della grafia tramite OCR e il riconoscimento video.
Come sarà il futuro per gli ingegneri dell'apprendimento automatico?
Con ulteriori progressi nell'intelligenza artificiale e nell'apprendimento automatico, il mercato o la domanda di ingegneri dell'apprendimento automatico sembra molto promettente. Entro la seconda metà del 2021, c'erano circa 23.000 posti di lavoro elencati su LinkedIn per ingegneri dell'apprendimento automatico. Le organizzazioni giganti globali, a partire da Amazon e Google, fino a PayPal, Autodesk, Morgan Stanley, Accenture e altri, sono sempre alla ricerca dei migliori talenti. Con solide basi in materie come programmazione, statistica, apprendimento automatico, gli ingegneri possono anche assumere ruoli di leadership nell'analisi dei dati, nell'automazione, nell'integrazione dell'IA e in altre aree.