
K-Nächste-Nachbarn-Algorithmus im maschinellen Lernen [mit Beispielen]
Veröffentlicht: 2020-10-28Inhaltsverzeichnis
Einführung
Maschinelles Lernen ist zweifellos eine der angesagtesten und leistungsstärksten Technologien in der heutigen datengesteuerten Welt, in der wir jede Sekunde mehr Datenmengen sammeln. Dies ist eine der schnell wachsenden Technologien, bei denen jede Domäne und jeder Sektor seine eigenen Anwendungsfälle und Projekte hat.
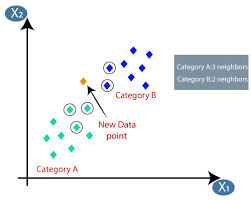
Maschinelles Lernen oder Modellentwicklung ist eine der Phasen im Lebenszyklus eines Data Science-Projekts, die auch eine der wichtigsten zu sein scheint. Dieser Artikel ist als Einführung in KNN (K-Nearest Neighbors) im maschinellen Lernen konzipiert.
K-Nächste Nachbarn
Wenn Sie mit maschinellem Lernen vertraut sind oder Teil eines Data Science- oder KI-Teams waren, haben Sie wahrscheinlich schon vom k-Nearest Neighbors-Algorithmus oder einfach KNN gehört. Dieser Algorithmus ist einer der wichtigsten Algorithmen, die beim maschinellen Lernen verwendet werden, da er einfach zu implementieren, nicht parametrisch ist, faul lernt und eine geringe Rechenzeit hat.
Ein weiterer Vorteil des k-Nearest-Neighbors-Algorithmus besteht darin, dass er sowohl für Klassifikations- als auch für Regressionsprobleme verwendet werden kann. Wenn Sie sich des Unterschieds zwischen diesen beiden nicht bewusst sind, lassen Sie mich Ihnen klarstellen, dass der Hauptunterschied zwischen Klassifizierung und Regression darin besteht, dass die Ausgabevariable bei der Regression numerisch (kontinuierlich) ist, während die für die Klassifizierung kategorisch (diskret) ist.
Lesen Sie: KNN-Algorithmen in R
Wie funktioniert k-nächste Nachbarn?
Der K-nächste-Nachbarn-Algorithmus (KNN) verwendet die Technik „Merkmalsähnlichkeit“ oder „nächste Nachbarn“, um den Cluster vorherzusagen, in den ein neuer Datenpunkt fällt. Nachfolgend sind die wenigen Schritte aufgeführt, anhand derer wir die Funktionsweise dieses Algorithmus besser verstehen können

Schritt 1 – Für die Implementierung eines beliebigen Algorithmus im maschinellen Lernen benötigen wir einen bereinigten Datensatz, der für die Modellierung bereit ist. Nehmen wir an, wir haben bereits einen bereinigten Datensatz, der in einen Trainings- und einen Testdatensatz aufgeteilt wurde.
Schritt 2 – Da wir die Datensätze bereits bereit haben, müssen wir den Wert von K (ganzzahlig) wählen, der uns sagt, wie viele nächste Datenpunkte wir berücksichtigen müssen, um den Algorithmus zu implementieren. Wie man den k-Wert bestimmt, erfahren wir im weiteren Verlauf des Artikels.
Schritt 3 – Dieser Schritt ist ein iterativer Schritt und muss für jeden Datenpunkt im Datensatz angewendet werden
I. Berechnen Sie den Abstand zwischen Testdaten und jeder Reihe von Trainingsdaten unter Verwendung einer beliebigen Abstandsmetrik
A. Euklidische Entfernung
B. Manhattan-Distanz
C. Minkowski-Distanz
D. Hamming-Distanz.
Viele Data Scientists neigen dazu, die euklidische Distanz zu verwenden, aber wir können die Bedeutung jeder einzelnen in der späteren Phase dieses Artikels kennenlernen.
II. Wir müssen die Daten basierend auf der Entfernungsmetrik sortieren, die wir im obigen Schritt verwendet haben.
III. Wählen Sie die obersten K Zeilen in den transformierten sortierten Daten aus.
IV. Dann weist es dem Testpunkt basierend auf der häufigsten Klasse dieser Zeilen eine Klasse zu.
Schritt 4 – Ende
Wie bestimmt man den K-Wert?
Wir müssen einen geeigneten K-Wert auswählen, um die maximale Genauigkeit des Modells zu erreichen, aber es gibt keine vordefinierten statistischen Methoden, um den günstigsten Wert von K zu finden. Die meisten von ihnen verwenden jedoch die Elbow-Methode.
Die Elbow-Methode beginnt mit der Berechnung der Summe des quadrierten Fehlers (SSE) für einige Werte von k. Die SSE ist die Summe des quadrierten Abstands zwischen jedem Mitglied des Clusters und seinem Schwerpunkt.
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
Wenn Sie verschiedene Werte von k gegen die SSE auftragen, können wir sehen, dass der Fehler abnimmt, wenn der Wert von k größer wird. Dies liegt daran, dass die Cluster mit zunehmender Anzahl von Clustern tendenziell kleiner werden, sodass auch die Verzerrung kleiner wird . Die Idee der Ellbogenmethode besteht darin, das k zu wählen, bei dem die SSE plötzlich abnimmt, was die Form des Ellbogens anzeigt.
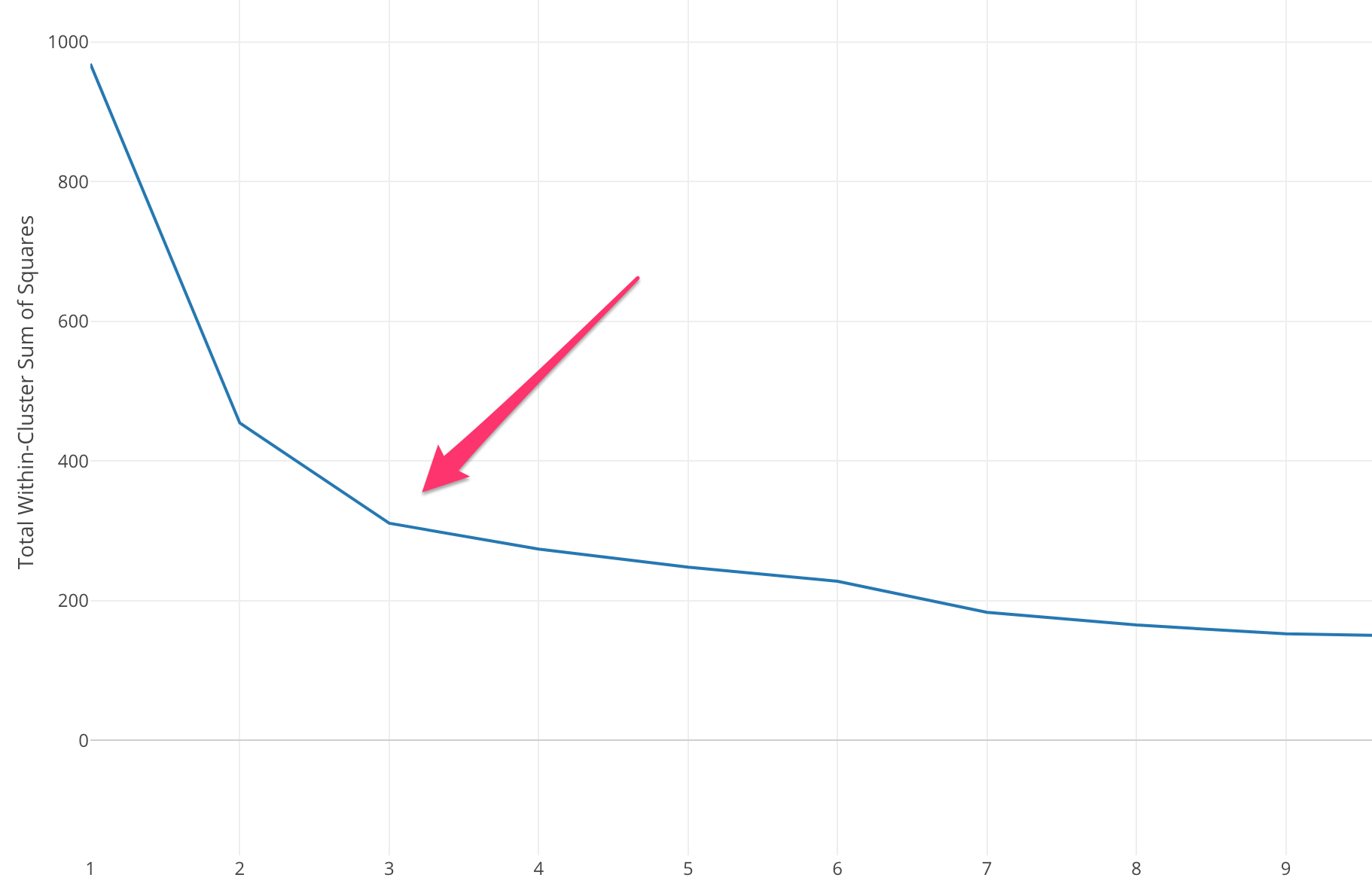
In einigen Fällen gibt es mehr als einen Ellbogen oder überhaupt keinen Ellbogen. In solchen Fällen berechnen wir normalerweise das beste k, indem wir bewerten, wie gut der k-means ML-Algorithmus im Kontext des Problems, das Sie zu lösen versuchen, abschneidet.
Lesen Sie auch: Modelle für maschinelles Lernen
Arten von Entfernungsmetriken
Lassen Sie uns etwas über die verschiedenen Entfernungsmetriken erfahren, die verwendet werden, um die Entfernung zwischen zwei Datenpunkten nacheinander zu berechnen.

1. Euklidische Distanz – Die euklidische Distanz ist die Quadratwurzel der Summe der quadrierten Distanz zwischen zwei Punkten.
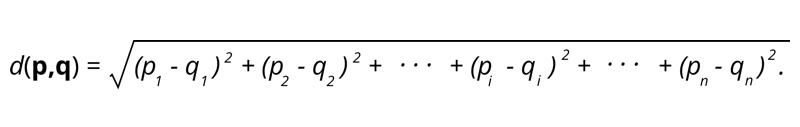 2. Manhattan-Distanz – Die Manhattan-Distanz ist die Summe der Absolutwerte der Differenzen zwischen zwei Punkten.
2. Manhattan-Distanz – Die Manhattan-Distanz ist die Summe der Absolutwerte der Differenzen zwischen zwei Punkten.
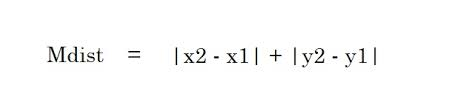 3. Minkowski-Distanz – Die Minkowski-Distanz wird verwendet, um die Distanzähnlichkeit zwischen zwei Punkten zu finden. Basierend auf der folgenden Formel ändert sich entweder die Manhattan-Distanz (wenn p = 1) oder die euklidische Distanz (wenn p = 2).
3. Minkowski-Distanz – Die Minkowski-Distanz wird verwendet, um die Distanzähnlichkeit zwischen zwei Punkten zu finden. Basierend auf der folgenden Formel ändert sich entweder die Manhattan-Distanz (wenn p = 1) oder die euklidische Distanz (wenn p = 2).
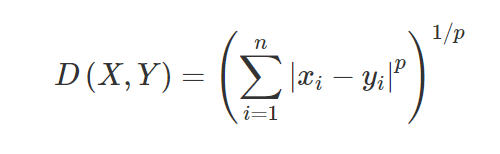 4. Hamming-Distanz – Hamming-Distanz wird für kategoriale Variablen verwendet. Diese Metrik sagt aus, ob zwei kategoriale Variablen gleich sind oder nicht.
4. Hamming-Distanz – Hamming-Distanz wird für kategoriale Variablen verwendet. Diese Metrik sagt aus, ob zwei kategoriale Variablen gleich sind oder nicht.
Anwendungen von KNN
Vorhersage der Kreditwürdigkeit eines neuen Kunden auf der Grundlage bereits verfügbarer Kreditnutzungen und Bewertungen von Kunden.
- Soll ein Kredit genehmigt werden oder nicht? zu einem Kandidaten.
- Die Klassifizierung einer bestimmten Transaktion ist betrügerisch oder nicht.
- Empfehlungssystem (YouTube, Netflix)
- Handschrifterkennung (wie OCR).
- Bilderkennung.
- Videoerkennung.
Vor- und Nachteile von KNN
Maschinelles Lernen besteht aus vielen Algorithmen, sodass jeder seine eigenen Vor- und Nachteile hat. Je nach Branche, Domäne und Art der Daten sowie unterschiedlichen Bewertungsmetriken für jeden Algorithmus sollte ein Data Scientist den besten Algorithmus auswählen, der zum Geschäftsproblem passt und ihn beantwortet. Lassen Sie uns einige Vor- und Nachteile von K-Nearest Neighbors sehen.
Vorteile
- Einfach zu bedienen, zu verstehen und zu interpretieren.
- Schnelle Berechnungszeit.
- Keine Annahmen über Daten.
- Hohe Genauigkeit der Vorhersagen.
- Vielseitig – Kann sowohl für Klassifikations- als auch für Regressionsgeschäftsprobleme verwendet werden.
- Kann auch für Mehrklassenprobleme verwendet werden.
- Wir haben nur einen Hyper-Parameter, den wir im Hyperparameter-Tuning-Schritt anpassen müssen.
Nachteile
- Rechenintensiv und erfordert viel Speicher, da der Algorithmus alle Trainingsdaten speichert.
- Der Algorithmus wird langsamer, wenn die Variablen zunehmen.
- Es ist sehr empfindlich gegenüber irrelevanten Merkmalen.
- Fluch der Dimensionalität.
- Wählen Sie den optimalen Wert von K.
- Ein Datensatz mit unausgeglichener Klasse verursacht Probleme.
- Fehlende Werte in den Daten verursachen ebenfalls Probleme.
Muss gelesen werden: Projektideen für maschinelles Lernen
Fazit
Dies ist ein grundlegender Algorithmus für maschinelles Lernen, der allgemein für seine Benutzerfreundlichkeit und schnelle Berechnungszeit bekannt ist. Dies wäre ein anständiger Algorithmus, den Sie auswählen sollten, wenn Sie neu in der Welt des maschinellen Lernens sind und die gegebene Aufgabe ohne großen Aufwand erledigen möchten.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.
Ist der K-Nearest Neighbors-Algorithmus teuer?
Bei riesigen Datensätzen kann der K-Nearest-Neighbors-Algorithmus sowohl rechenzeit- als auch speicherintensiv werden. Dies liegt daran, dass dieser KNN-Algorithmus alle Trainingsdatensätze speichern und speichern muss, um zu funktionieren. KNN reagiert sehr sensibel auf die Skala der Trainingsdaten, da es auf die Berechnung der Distanzen ankommt. Dieser Algorithmus ruft keine Ergebnisse basierend auf Annahmen über die Trainingsdaten ab. Auch wenn dies bei anderen überwachten Lernalgorithmen möglicherweise nicht der allgemeine Fall ist, gilt der KNN-Algorithmus als äußerst effektiv bei der Lösung von Problemen, die mit nichtlinearen Datenpunkten einhergehen.
Was sind einige der praktischen Anwendungen des K-NN-Algorithmus?
Der KNN-Algorithmus wird häufig von Unternehmen verwendet, um Personen mit gemeinsamen Interessen Produkte zu empfehlen. Unternehmen können beispielsweise Fernsehsendungen basierend auf der Auswahl der Zuschauer, Bekleidungsdesigns basierend auf früheren Einkäufen sowie Hotel- und Unterkunftsoptionen während der Touren basierend auf dem Buchungsverlauf vorschlagen. Es kann auch von Finanzinstituten verwendet werden, um Kunden Kreditratings auf der Grundlage ähnlicher finanzieller Merkmale zuzuweisen. Banken stützen ihre Entscheidungen über die Kreditauszahlung auf spezifische Anträge, die ähnliche Merkmale wie säumige Personen zu haben scheinen. Fortgeschrittene Anwendungen dieses Algorithmus umfassen Bilderkennung, Handschriftenerkennung mittels OCR sowie Videoerkennung.
Wie sieht die Zukunft für Machine-Learning-Ingenieure aus?
Mit weiteren Fortschritten in KI und maschinellem Lernen sieht der Markt oder die Nachfrage nach Ingenieuren für maschinelles Lernen sehr vielversprechend aus. In der zweiten Hälfte des Jahres 2021 waren auf LinkedIn rund 23.000 Jobs für Ingenieure für maschinelles Lernen gelistet. Globale Riesenunternehmen, angefangen bei Amazon und Google bis hin zu PayPal, Autodesk, Morgan Stanley, Accenture und anderen, sind immer auf der Suche nach den besten Talenten. Mit starken Grundlagen in Fächern wie Programmierung, Statistik, maschinellem Lernen können Ingenieure auch Führungsrollen in Datenanalyse, Automatisierung, KI-Integration und anderen Bereichen übernehmen.