
K-Nearest Neighbors Algorithm ในการเรียนรู้ของเครื่อง [พร้อมตัวอย่าง]
เผยแพร่แล้ว: 2020-10-28สารบัญ
บทนำ
การเรียนรู้ด้วยเครื่องเป็นหนึ่งในเทคโนโลยีที่มีประสิทธิภาพและเกิดขึ้นมากที่สุดอย่างไม่ต้องสงสัยในโลกที่ขับเคลื่อนด้วยข้อมูลในปัจจุบัน ซึ่งเรากำลังรวบรวมข้อมูลจำนวนมากขึ้นทุกวินาที นี่เป็นหนึ่งในเทคโนโลยีที่เติบโตอย่างรวดเร็วซึ่งทุกโดเมนและทุกภาคส่วนมีกรณีการใช้งานและโครงการของตนเอง
การเรียนรู้ด้วยเครื่องหรือการพัฒนาแบบจำลองเป็นหนึ่งในขั้นตอนในวัฏจักรชีวิตของโครงการวิทยาศาสตร์ข้อมูล ซึ่งดูเหมือนจะเป็นหนึ่งในขั้นตอนที่สำคัญที่สุดเช่นกัน บทความนี้จัดทำขึ้นเพื่อเป็นการแนะนำ KNN (K-Nearest Neighbors) ในการเรียนรู้ของเครื่อง
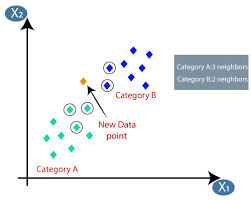
K-เพื่อนบ้านที่ใกล้ที่สุด
หากคุณคุ้นเคยกับแมชชีนเลิร์นนิงหรือเคยเป็นส่วนหนึ่งของ Data Science หรือทีม AI คุณอาจเคยได้ยินอัลกอริทึม k-Nearest Neighbors หรือเรียกง่ายๆ ว่า KNN อัลกอริธึมนี้เป็นหนึ่งในอัลกอริธึมที่ใช้ในแมชชีนเลิร์นนิงเพราะง่ายต่อการใช้งาน ไม่ใช้พารามิเตอร์ ขี้เกียจเรียนรู้ และมีเวลาคำนวณต่ำ
ข้อดีอีกประการของอัลกอริธึม k-Nearest Neighbors คือ สามารถใช้ได้กับปัญหาทั้งประเภทการจำแนกประเภทและการถดถอย หากคุณไม่ทราบถึงความแตกต่างระหว่างสองสิ่งนี้ ให้ฉันอธิบายให้คุณทราบ ความแตกต่างที่สำคัญระหว่างการจำแนกและการถดถอยคือ ตัวแปรผลลัพธ์ในการถดถอยเป็น ตัวเลข (ต่อเนื่อง) ในขณะที่สำหรับการจัดประเภทนั้นเป็น หมวดหมู่ (ไม่ต่อเนื่อง)
อ่าน: อัลกอริทึม KNN ใน R
k-Nearest Neighbors ทำงานอย่างไร?
อัลกอริธึม K-Nearest Neighbors (KNN) ใช้เทคนิค 'คุณลักษณะที่คล้ายคลึงกัน' หรือ 'เพื่อนบ้านที่ใกล้ที่สุด' เพื่อทำนายคลัสเตอร์ที่มีจุดข้อมูลใหม่ ด้านล่างนี้คือขั้นตอนที่เราเข้าใจการทำงานของอัลกอริธึมนี้ได้ดีขึ้น

ขั้นตอนที่ 1 - สำหรับการนำอัลกอริธึมไปใช้ในการเรียนรู้ของเครื่อง เราจำเป็นต้องมีชุดข้อมูลที่สะอาดพร้อมสำหรับการสร้างแบบจำลอง สมมติว่าเรามีชุดข้อมูลที่ล้างแล้วซึ่งแบ่งออกเป็นชุดข้อมูลการฝึกอบรมและการทดสอบ
ขั้นตอนที่ 2 - เนื่องจากเรามีชุดข้อมูลพร้อมแล้ว เราจำเป็นต้องเลือกค่าของ K (จำนวนเต็ม) ซึ่งจะบอกเราว่าเราต้องคำนึงถึงจุดข้อมูลที่ใกล้ที่สุดกี่จุดเพื่อนำอัลกอริทึมไปใช้ เราจะได้ทราบวิธีการกำหนดค่า k ในขั้นตอนหลังของบทความ
ขั้นตอนที่ 3 - ขั้นตอนนี้เป็นการวนซ้ำและจำเป็นต้องใช้กับจุดข้อมูลแต่ละจุดในชุดข้อมูล
I. คำนวณระยะห่างระหว่างข้อมูลการทดสอบกับข้อมูลการฝึกแต่ละแถวโดยใช้ตัววัดระยะทางใดๆ
ก. ระยะทางแบบยุคลิด
ข. ระยะทางแมนฮัตตัน
ค. Minkowski ระยะทาง
ง. ระยะทางแฮมมิ่ง
นักวิทยาศาสตร์ด้านข้อมูลหลายคนมักจะใช้ระยะทางแบบยุคลิด แต่เราสามารถทราบถึงความสำคัญของแต่ละระยะได้ในระยะหลังของบทความนี้
ครั้งที่สอง เราจำเป็นต้องจัดเรียงข้อมูลตามการวัดระยะทางที่เราใช้ในขั้นตอนข้างต้น
สาม. เลือกแถว K บนสุดในข้อมูลที่จัดเรียงที่แปลงแล้ว
IV. จากนั้นจะกำหนดคลาสให้กับจุดทดสอบตามคลาสที่บ่อยที่สุดของแถวเหล่านี้
ขั้นตอนที่ 4 - สิ้นสุด
จะกำหนดค่า K ได้อย่างไร?
เราจำเป็นต้องเลือกค่า K ที่เหมาะสมเพื่อให้ได้ค่าความแม่นยำสูงสุดของแบบจำลอง แต่ไม่มีวิธีทางสถิติที่กำหนดไว้ล่วงหน้าในการค้นหาค่า K ที่เหมาะสมที่สุด แต่ส่วนใหญ่ใช้วิธีข้อศอก
วิธีข้อศอกเริ่มต้นด้วยการคำนวณผลรวมของข้อผิดพลาดกำลังสอง (SSE) สำหรับค่า k บางค่า SSE คือผลรวมของระยะห่างกำลังสองระหว่างสมาชิกของคลัสเตอร์แต่ละตัวกับเซนทรอยด์
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
หากคุณพลอตค่า k ที่ต่างกันกับ SSE เราจะเห็นว่าข้อผิดพลาดลดลงเมื่อค่า k มากขึ้น สิ่งนี้เกิดขึ้นเพราะเมื่อจำนวนคลัสเตอร์เพิ่มขึ้น คลัสเตอร์จะมีแนวโน้มน้อยลง ดังนั้นการบิดเบือนก็จะน้อยลงด้วย . แนวคิดของวิธีข้อศอกคือการเลือก k โดยที่ SSE ลดลงอย่างกะทันหันซึ่งหมายถึงรูปร่างของข้อศอก
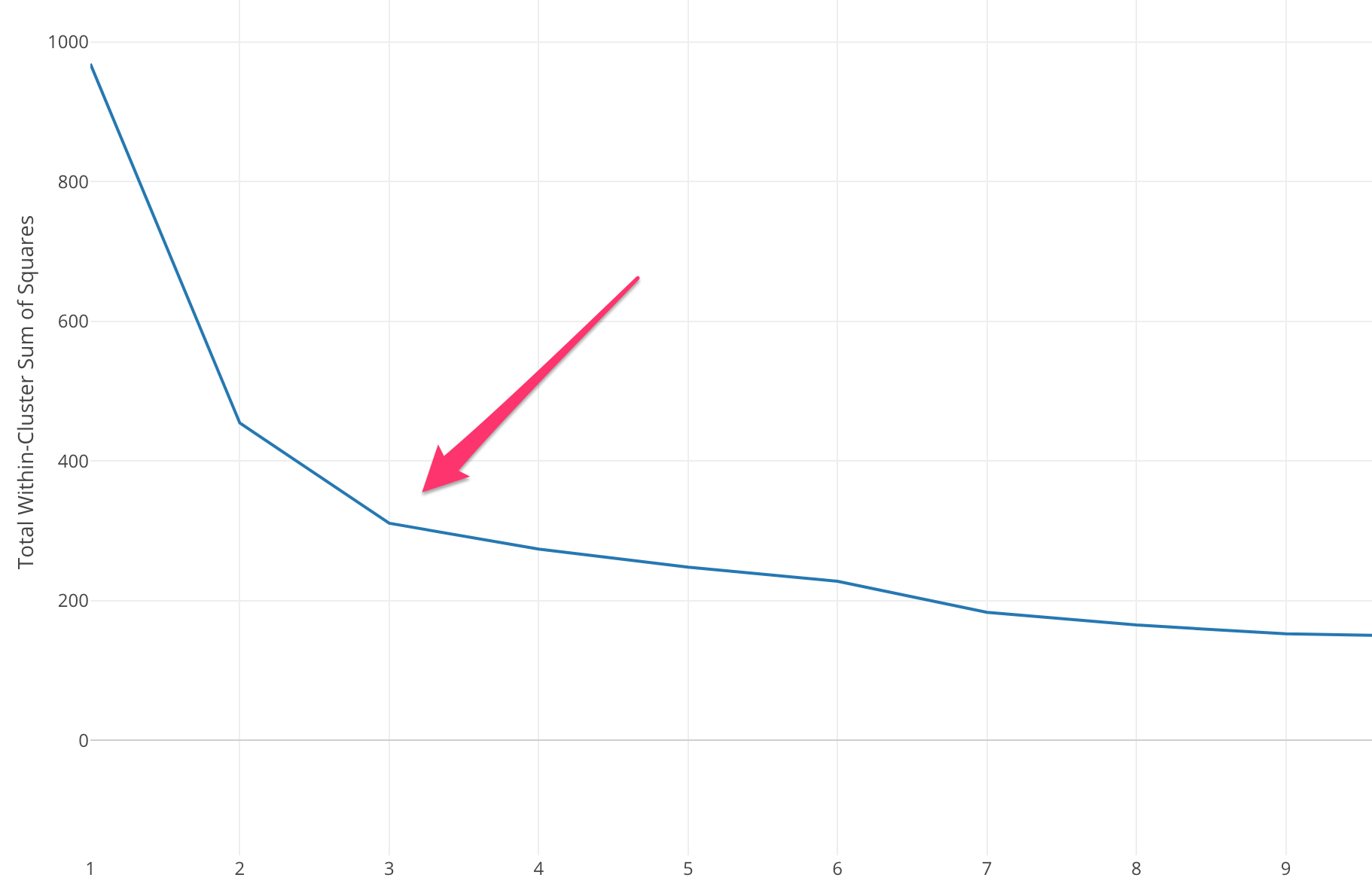
ในบางกรณี มีมากกว่าหนึ่งข้อศอก หรือไม่มีเลย ในกรณีเช่นนี้ เรามักจะจบลงด้วยการคำนวณ k ที่ดีที่สุดโดยการประเมินว่า k-mean ML Algorithm ทำงานได้ดีเพียงใดในบริบทของปัญหาที่คุณพยายามแก้ไข
อ่านเพิ่มเติม: โมเดลการเรียนรู้ของเครื่อง
ประเภทของเมตริกระยะทาง
มาทำความรู้จักกับตัววัดระยะทางต่างๆ ที่ใช้ในการคำนวณระยะห่างระหว่างจุดข้อมูลสองจุดกันทีละจุด

1. ระยะทางแบบยุคลิด – ระยะทางแบบยุคลิดคือรากที่สองของผลรวมของระยะห่างกำลังสองระหว่างจุดสองจุด
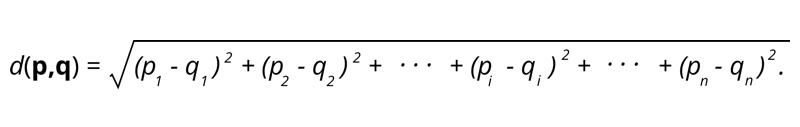 2. ระยะทางแมนฮัตตัน – ระยะทางแมนฮัตตันเป็นผลรวมของค่าสัมบูรณ์ของความแตกต่างระหว่างจุดสองจุด
2. ระยะทางแมนฮัตตัน – ระยะทางแมนฮัตตันเป็นผลรวมของค่าสัมบูรณ์ของความแตกต่างระหว่างจุดสองจุด
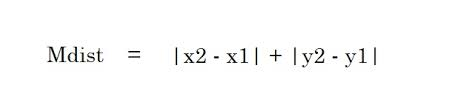 3. ระยะทาง Minkowski – ระยะทาง Minkowski ใช้เพื่อค้นหาความคล้ายคลึงกันของระยะทางระหว่างจุดสองจุด ตามสูตรด้านล่างจะเปลี่ยนเป็นระยะทางแมนฮัตตัน (เมื่อ p=1) และระยะทางแบบยุคลิด (เมื่อ p=2)
3. ระยะทาง Minkowski – ระยะทาง Minkowski ใช้เพื่อค้นหาความคล้ายคลึงกันของระยะทางระหว่างจุดสองจุด ตามสูตรด้านล่างจะเปลี่ยนเป็นระยะทางแมนฮัตตัน (เมื่อ p=1) และระยะทางแบบยุคลิด (เมื่อ p=2)
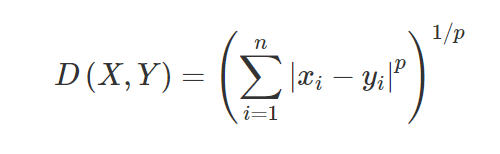 4. ระยะ Hamming – ระยะ Hamming ใช้สำหรับตัวแปรหมวดหมู่ ตัวชี้วัดนี้จะบอกได้ว่าตัวแปรตามหมวดหมู่สองตัวแปรเหมือนกันหรือไม่
4. ระยะ Hamming – ระยะ Hamming ใช้สำหรับตัวแปรหมวดหมู่ ตัวชี้วัดนี้จะบอกได้ว่าตัวแปรตามหมวดหมู่สองตัวแปรเหมือนกันหรือไม่
แอพพลิเคชั่นของ KNN
การคาดคะเนอันดับเครดิตของลูกค้าใหม่โดยพิจารณาจากการใช้และการให้คะแนนเครดิตของลูกค้าที่มีอยู่แล้ว
- จะคว่ำบาตรเงินกู้หรือไม่? ให้กับผู้สมัคร
- การจัดประเภทธุรกรรมที่กำหนดให้เป็นการฉ้อโกงหรือไม่
- ระบบคำแนะนำ (YouTube, Netflix)
- การตรวจจับการเขียนด้วยลายมือ (เช่น OCR)
- การจดจำภาพ
- การจดจำวิดีโอ
ข้อดีและข้อเสียของ KNN
การเรียนรู้ของเครื่องประกอบด้วยอัลกอริธึมมากมาย ดังนั้นแต่ละอัลกอริทึมจึงมีข้อดีและข้อเสียต่างกันไป นักวิทยาศาสตร์ข้อมูลควรเลือกอัลกอริธึมที่ดีที่สุดที่เหมาะกับปัญหาทางธุรกิจ ทั้งนี้ขึ้นอยู่กับอุตสาหกรรม โดเมน และประเภทของข้อมูลและเมตริกการประเมินที่แตกต่างกันสำหรับแต่ละอัลกอริทึม ให้เราดูข้อดีและข้อเสียของ K-Nearest Neighbors
ข้อดี
- ใช้งานง่าย เข้าใจและตีความ
- เวลาคำนวณอย่างรวดเร็ว
- ไม่มีสมมติฐานเกี่ยวกับข้อมูล
- การทำนายที่แม่นยำสูง
- อเนกประสงค์ – ใช้ได้กับทั้งปัญหาธุรกิจการจำแนกประเภทและการถดถอย
- สามารถใช้กับปัญหาหลายชั้นได้เช่นกัน
- เรามีพารามิเตอร์ Hyper เพียงตัวเดียวที่จะปรับแต่งที่ขั้นตอนการปรับแต่ง Hyperparameter
ข้อเสีย
- การคำนวณมีราคาแพงและต้องใช้หน่วยความจำสูงเนื่องจากอัลกอริธึมเก็บข้อมูลการฝึกอบรมทั้งหมด
- อัลกอริทึมจะช้าลงเมื่อตัวแปรเพิ่มขึ้น
- มีความละเอียดอ่อนมากต่อคุณลักษณะที่ไม่เกี่ยวข้อง
- คำสาปแห่งมิติ
- การเลือกค่าที่เหมาะสมที่สุดของ K
- ชุดข้อมูลคลาสไม่สมดุลจะทำให้เกิดปัญหา
- ค่าที่หายไปในข้อมูลยังทำให้เกิดปัญหา
ต้องอ่าน: แนวคิดโครงการการเรียนรู้ของเครื่อง
บทสรุป
นี่คืออัลกอริธึมการเรียนรู้ของเครื่องพื้นฐานที่เป็นที่รู้จักในด้านความง่ายในการใช้งานและเวลาในการคำนวณที่รวดเร็ว นี่อาจเป็นอัลกอริธึมที่เหมาะสมในการเลือก หากคุณยังใหม่ต่อ Machine Learning World และต้องการทำงานให้เสร็จโดยไม่ยุ่งยากมากนัก
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับแมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมที่เข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษาและการมอบหมายมากกว่า 30 รายการ IIIT- สถานะศิษย์เก่า B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
อัลกอริทึม K-Nearest Neighbors มีราคาแพงหรือไม่
ในกรณีของชุดข้อมูลขนาดใหญ่ อัลกอริธึม K-Nearest Neighbors อาจมีราคาแพงทั้งในแง่ของเวลาประมวลผลและการจัดเก็บ เนื่องจากอัลกอริธึม KNN นี้ต้องบันทึกและจัดเก็บชุดข้อมูลการฝึกอบรมทั้งหมดจึงจะสามารถทำงานได้ KNN มีความไวสูงต่อขนาดของข้อมูลการฝึก เนื่องจากขึ้นอยู่กับการคำนวณระยะทาง อัลกอริธึมนี้ไม่ดึงผลลัพธ์ตามสมมติฐานเกี่ยวกับข้อมูลการฝึก แม้ว่าสิ่งนี้อาจไม่ใช่กรณีทั่วไปเมื่อคุณพิจารณาอัลกอริธึมการเรียนรู้ภายใต้การดูแลอื่น ๆ แต่อัลกอริธึม KNN ถือว่ามีประสิทธิภาพสูงในการแก้ปัญหาที่มาพร้อมกับจุดข้อมูลที่ไม่ใช่เชิงเส้น
การใช้งานจริงของอัลกอริทึม K-NN มีอะไรบ้าง
ธุรกิจมักใช้อัลกอริทึม KNN เพื่อแนะนำผลิตภัณฑ์ให้กับบุคคลที่มีความสนใจร่วมกัน ตัวอย่างเช่น บริษัทต่างๆ สามารถแนะนำรายการทีวีตามตัวเลือกของผู้ดู การออกแบบเครื่องแต่งกายตามการซื้อครั้งก่อน และตัวเลือกโรงแรมและที่พักระหว่างทัวร์ตามประวัติการจอง นอกจากนี้ยังสามารถใช้โดยสถาบันการเงินเพื่อกำหนดอันดับความน่าเชื่อถือให้กับลูกค้าตามคุณสมบัติทางการเงินที่คล้ายคลึงกัน ธนาคารตัดสินใจเบิกเงินกู้ตามใบสมัครเฉพาะที่มีลักษณะคล้ายคลึงกับผู้ผิดนัดชำระหนี้ แอปพลิเคชันขั้นสูงของอัลกอริธึมนี้รวมถึงการจดจำภาพ การตรวจจับการเขียนด้วยลายมือโดยใช้ OCR และการจดจำวิดีโอ
อนาคตของวิศวกรแมชชีนเลิร์นนิงจะเป็นอย่างไร
ด้วยความก้าวหน้าเพิ่มเติมใน AI และการเรียนรู้ของเครื่อง ตลาดหรือความต้องการของวิศวกรการเรียนรู้ของเครื่องจึงมีแนวโน้มที่ดี ภายในครึ่งหลังของปี 2564 มีตำแหน่งงานประมาณ 23,000 ตำแหน่งบน LinkedIn สำหรับวิศวกรการเรียนรู้ของเครื่อง องค์กรยักษ์ใหญ่ระดับโลกที่เริ่มจาก Amazon และ Google ไปจนถึง PayPal, Autodesk, Morgan Stanley, Accenture และอื่นๆ ต่างก็มองหาผู้มีความสามารถระดับสูงอยู่เสมอ ด้วยพื้นฐานที่แข็งแกร่งในวิชาต่างๆ เช่น การเขียนโปรแกรม สถิติ แมชชีนเลิร์นนิง วิศวกรยังสามารถมีบทบาทเป็นผู้นำในการวิเคราะห์ข้อมูล ระบบอัตโนมัติ การบูรณาการ AI และด้านอื่นๆ