
Algorytm K-Nearest Neighbors w uczeniu maszynowym [z przykładami]
Opublikowany: 2020-10-28Spis treści
Wstęp
Uczenie maszynowe to bez wątpienia jedna z najpopularniejszych i najpotężniejszych technologii w dzisiejszym świecie opartym na danych, w którym co sekundę gromadzimy coraz więcej danych. Jest to jedna z szybko rozwijających się technologii, w której każda domena i każdy sektor ma swoje własne przypadki użycia i projekty.
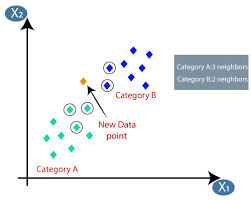
Uczenie maszynowe lub opracowywanie modeli to jedna z faz cyklu życia projektu Data Science, która wydaje się być również jedną z najważniejszych. Ten artykuł został zaprojektowany jako wprowadzenie do KNN (K-Nearest Neighbors) w uczeniu maszynowym.
K-Najbliżsi sąsiedzi
Jeśli jesteś zaznajomiony z uczeniem maszynowym lub byłeś częścią zespołu Data Science lub AI, prawdopodobnie słyszałeś o algorytmie k-Nearest Neighbors lub po prostu o nazwie KNN. Algorytm ten jest jednym z algorytmów stosowanych w uczeniu maszynowym, ponieważ jest łatwy do wdrożenia, nieparametryczny, leniwy i ma krótki czas obliczeń.
Kolejną zaletą algorytmu k-Nearest Neighbors jest to, że można go używać zarówno do problemów typu Klasyfikacja, jak i Regresja. Jeśli nie jesteś świadomy różnicy między tymi dwoma, pozwól, że wyjaśnię ci, główna różnica między klasyfikacją a regresją polega na tym, że zmienna wyjściowa w regresji jest liczbowa (ciągła), podczas gdy zmienna dla klasyfikacji jest kategoryczna (dyskretna).
Przeczytaj: Algorytmy KNN w R
Jak działa k-Nearest Neighbors?
Algorytm K-najbliższych sąsiadów (KNN) wykorzystuje technikę „podobieństwa cech” lub „najbliżsi sąsiedzi” do przewidywania klastra, do którego należy nowy punkt danych. Poniżej kilka kroków, na podstawie których możemy lepiej zrozumieć działanie tego algorytmu

Krok 1 – Do implementacji dowolnego algorytmu w uczeniu maszynowym potrzebujemy oczyszczonego zestawu danych gotowych do modelowania. Załóżmy, że mamy już wyczyszczony zbiór danych, który został podzielony na zbiór danych uczących i testowych.
Krok 2 − Ponieważ mamy już gotowe zestawy danych, musimy wybrać wartość K (liczba całkowita), która mówi nam, ile najbliższych punktów danych musimy wziąć pod uwagę, aby zaimplementować algorytm. Jak określić wartość k, możemy dowiedzieć się w dalszych etapach artykułu.
Krok 3 – Ten krok jest etapem iteracyjnym i należy go zastosować dla każdego punktu danych w zbiorze danych
I. Oblicz odległość między danymi testowymi a każdym rzędem danych treningowych za pomocą dowolnego miernika odległości
a. Odległość euklidesowa
b. Odległość Manhattanu
C. Odległość Minkowskiego
D. Odległość Hamminga.
Wielu naukowców zajmujących się danymi ma tendencję do używania odległości euklidesowych, ale możemy poznać znaczenie każdego z nich w dalszej części tego artykułu.
II. Musimy posortować dane na podstawie miernika odległości, którego użyliśmy w powyższym kroku.
III. Wybierz górne K wierszy w przekształconych posortowanych danych.
IV. Następnie przypisze klasę do punktu testowego na podstawie najczęściej występującej klasy tych wierszy.
Krok 4 – Koniec
Jak określić wartość K?
Musimy wybrać odpowiednią wartość K, aby osiągnąć maksymalną dokładność modelu, ale nie ma z góry zdefiniowanych metod statystycznych, aby znaleźć najkorzystniejszą wartość K. Jednak większość z nich wykorzystuje metodę Elbow.
Metoda Elbow rozpoczyna się od obliczenia sumy błędu kwadratowego (SSE) dla niektórych wartości k. SSE jest sumą kwadratu odległości między każdym elementem klastra a jego środkiem ciężkości.
SSE=∑Ki=1∑x ∈ cidist(x,ci)2SSE= ∑∑ x ∈ cidist(x,ci)2
Jeśli wykreślisz różne wartości k w stosunku do SSE, zobaczymy, że błąd zmniejsza się wraz ze wzrostem wartości k, dzieje się tak, ponieważ gdy liczba klastrów wzrasta, klastry będą miały tendencję do zmniejszania się, więc zniekształcenie również będzie mniejsze . Ideą metody łokcia jest wybranie k, przy którym SSE nagle maleje, wskazując na kształt łokcia.
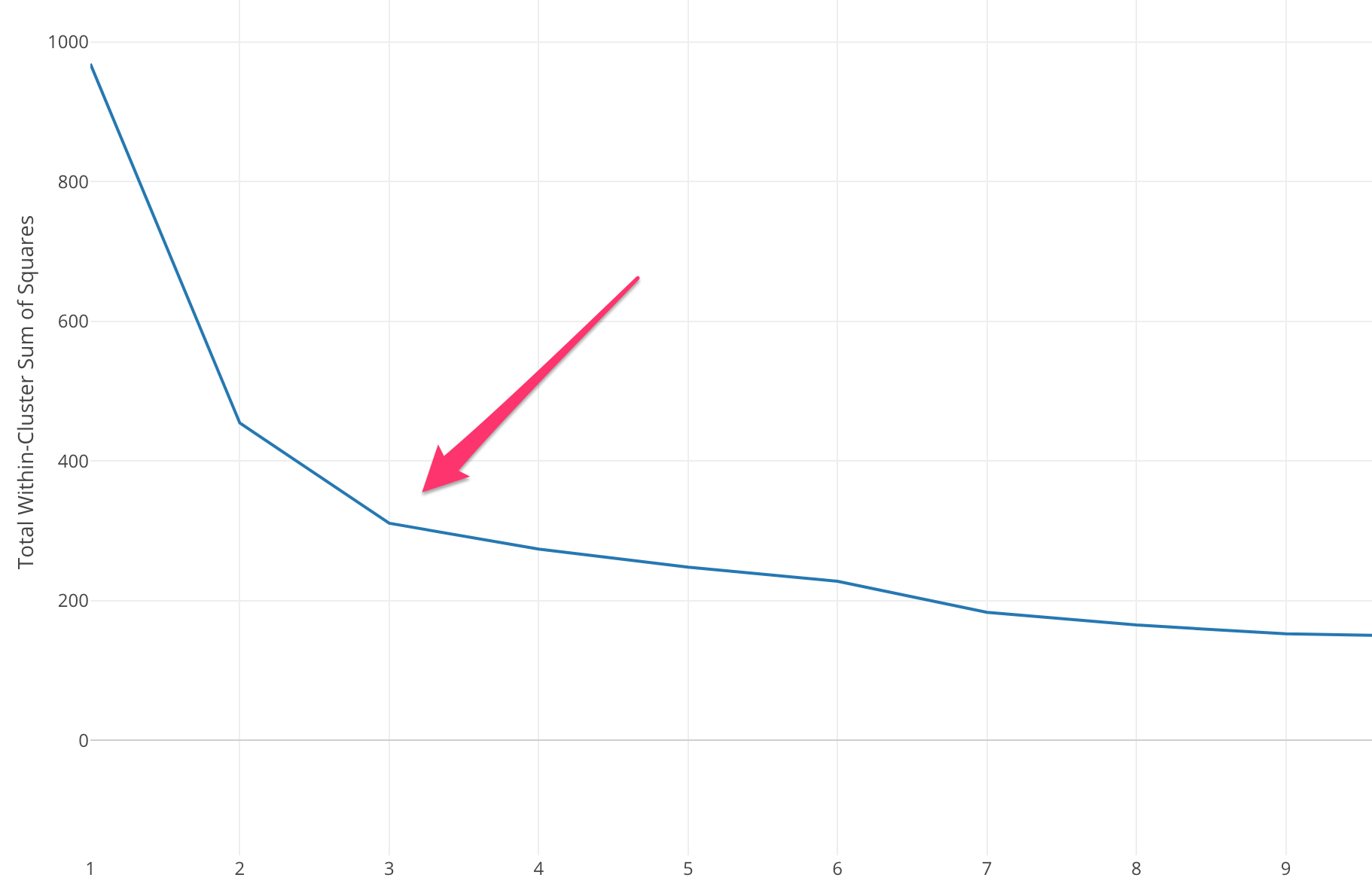
W niektórych przypadkach istnieje więcej niż jeden łokieć lub w ogóle nie ma łokcia. W takich przypadkach zwykle kończymy obliczenie najlepszego k, oceniając, jak dobrze algorytm k-średnich działa w kontekście problemu, który próbujesz rozwiązać.
Przeczytaj także: Modele uczenia maszynowego
Rodzaje metryki odległości
Poznajmy różne metryki odległości używane do obliczania odległości między dwoma punktami danych jeden po drugim.

1. Odległość euklidesowa – odległość euklidesowa to pierwiastek kwadratowy z sumy kwadratów odległości między dwoma punktami.
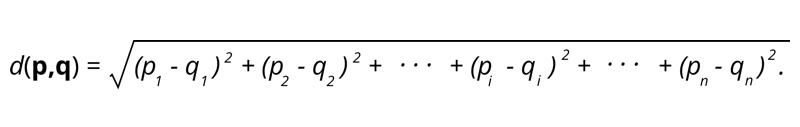 2. Odległość Manhattanu – Odległość Manhattanu to suma wartości bezwzględnych różnic między dwoma punktami.
2. Odległość Manhattanu – Odległość Manhattanu to suma wartości bezwzględnych różnic między dwoma punktami.
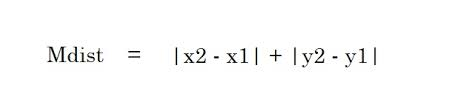 3. Odległość Minkowskiego – Odległość Minkowskiego służy do określenia podobieństwa odległości między dwoma punktami. W oparciu o poniższy wzór zmienia się na odległość Manhattanu (gdy p=1) i odległość euklidesową (gdy p=2).
3. Odległość Minkowskiego – Odległość Minkowskiego służy do określenia podobieństwa odległości między dwoma punktami. W oparciu o poniższy wzór zmienia się na odległość Manhattanu (gdy p=1) i odległość euklidesową (gdy p=2).
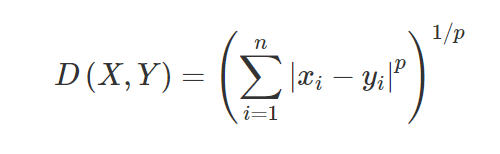 4. Odległość Hamminga – Odległość Hamminga jest używana dla zmiennych kategorycznych. Ta metryka pokaże, czy dwie zmienne kategorialne są takie same, czy nie.
4. Odległość Hamminga – Odległość Hamminga jest używana dla zmiennych kategorycznych. Ta metryka pokaże, czy dwie zmienne kategorialne są takie same, czy nie.
Zastosowania KNN
Przewidywanie ratingu kredytowego nowego klienta na podstawie już dostępnych zastosowań kredytowych i ratingów klientów.
- Czy sankcjonować pożyczkę, czy nie? do kandydata.
- Klasyfikowanie danej transakcji jest fałszywe lub nie.
- System rekomendacji (YouTube, Netflix)
- Wykrywanie pisma ręcznego (jak OCR).
- Rozpoznawanie obrazu.
- Rozpoznawanie wideo.
Plusy i minusy KNN
Machine Learning składa się z wielu algorytmów, więc każdy z nich ma swoje wady i zalety. W zależności od branży, domeny i rodzaju danych oraz różnych metryk oceny dla każdego algorytmu, Data Scientist powinien wybrać najlepszy algorytm, który pasuje i odpowiada na problem biznesowy. Zobaczmy kilka zalet i wad K-Nearest Neighbors.
Plusy
- Łatwy w użyciu, zrozumieniu i interpretacji.
- Szybki czas obliczeń.
- Brak założeń dotyczących danych.
- Wysoka dokładność prognoz.
- Wszechstronny — może być używany zarówno w przypadku problemów biznesowych z klasyfikacją, jak i regresją.
- Może być również używany do problemów z wieloma klasami.
- Mamy tylko jeden parametr Hyper do dostrojenia w kroku Hyperparameter Tuning.
Cons
- Kosztowne obliczeniowo i wymaga dużej ilości pamięci, ponieważ algorytm przechowuje wszystkie dane treningowe.
- Algorytm staje się wolniejszy wraz ze wzrostem zmiennych.
- Jest bardzo wrażliwy na nieistotne cechy.
- Przekleństwo wymiarowości.
- Wybór optymalnej wartości K.
- Niezrównoważony zestaw danych klas spowoduje problem.
- Brakujące wartości w danych również powodują problem.
Musisz przeczytać: Pomysły na projekty uczenia maszynowego
Wniosek
Jest to podstawowy algorytm uczenia maszynowego, który jest powszechnie znany z łatwości użycia i szybkiego czasu obliczeń. Byłby to przyzwoity algorytm do wyboru, jeśli jesteś nowy w świecie uczenia maszynowego i chciałbyś wykonać dane zadanie bez większych problemów.
Jeśli chcesz dowiedzieć się więcej o uczeniu maszynowym, sprawdź dyplom PG IIIT-B i upGrad w uczeniu maszynowym i sztucznej inteligencji, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 450 godzin rygorystycznego szkolenia, ponad 30 studiów przypadków i zadań, IIIT- Status absolwenta B, ponad 5 praktycznych, praktycznych projektów zwieńczenia i pomoc w pracy z najlepszymi firmami.
Czy algorytm K-Nearest Neighbors jest drogi?
W przypadku ogromnych zbiorów danych algorytm K-Nearest Neighbors może być kosztowny zarówno pod względem czasu obliczeniowego, jak i przechowywania. Dzieje się tak, ponieważ algorytm KNN musi zapisywać i przechowywać wszystkie treningowe zestawy danych, aby działały. KNN jest bardzo wrażliwy na skalę danych treningowych, ponieważ zależy od obliczania odległości. Algorytm ten nie pobiera wyników na podstawie założeń dotyczących danych uczących. Chociaż może to nie być ogólny przypadek, gdy weźmiesz pod uwagę inne nadzorowane algorytmy uczenia się, algorytm KNN jest uważany za wysoce skuteczny w rozwiązywaniu problemów związanych z nieliniowymi punktami danych.
Jakie są praktyczne zastosowania algorytmu K-NN?
Algorytm KNN jest często wykorzystywany przez firmy do polecania produktów osobom o wspólnych zainteresowaniach. Na przykład firmy mogą proponować programy telewizyjne na podstawie wyborów widzów, projekty odzieży oparte na wcześniejszych zakupach oraz opcje hoteli i zakwaterowania podczas wycieczek na podstawie historii rezerwacji. Może być również wykorzystywany przez instytucje finansowe do przyznawania klientom ratingów kredytowych na podstawie podobnych cech finansowych. Banki opierają swoje decyzje o wypłacie kredytu na konkretnych aplikacjach, które wydają się mieć cechy podobne do defaulters. Zaawansowane zastosowania tego algorytmu obejmują rozpoznawanie obrazu, wykrywanie pisma ręcznego za pomocą OCR oraz rozpoznawanie wideo.
Jak wygląda przyszłość inżynierów zajmujących się uczeniem maszynowym?
Wraz z dalszym rozwojem sztucznej inteligencji i uczenia maszynowego rynek lub zapotrzebowanie na inżynierów uczenia maszynowego wygląda bardzo obiecująco. Do drugiej połowy 2021 r. na LinkedIn notowano około 23 000 miejsc pracy dla inżynierów zajmujących się uczeniem maszynowym. Globalne gigantyczne organizacje, od Amazon i Google po PayPal, Autodesk, Morgan Stanley, Accenture i inne, zawsze poszukują najlepszych talentów. Dzięki solidnym podstawom w takich dziedzinach, jak programowanie, statystyka, uczenie maszynowe, inżynierowie mogą również pełnić wiodące role w analityce danych, automatyzacji, integracji AI i innych obszarach.