
TensorFlow Kullanarak Derin Öğrenmede Model Doğrulama ve Düzenlemeye Uygulamalı Giriş
Yayınlanan: 2020-10-28İçindekiler
Tanıtım
Makinelerin denetimli öğrenme algoritmaları paradigması aracılığıyla bilgiyi özümseme pratiği, dizi oluşturma, doğal dil işleme ve hatta bilgisayar görüşü gibi çeşitli görevlerde devrim yarattı. Bu yaklaşım, bir dizi girdi özelliği ve buna karşılık gelen bir etiket kümesine sahip bir veri kümesinin kullanılmasına dayanmaktadır. Makine daha sonra, görünmeyen girdiler üzerinde istatistiksel tahminler yapmak için verilerin dağılımını ve modellerini öğrenmek için özellikler ve etiketler biçiminde bulunan bu bilgileri kullanır.
Derin öğrenme modelleri tasarlamanın en önemli adımı, özellikle yeni ve görünmeyen veri noktalarında model performansını değerlendirmektir. Temel amaç, eğitildikleri verilerin ötesinde genelleme yapan modeller geliştirmektir. Gerçek dünyada iyi ve güvenilir tahminler yapabilen modeller istiyoruz. Bu konuda bize yardımcı olan önemli bir kavram, bugün ele alacağımız model doğrulama ve düzenlemedir.
Model geçerliliği
Bir makine öğrenimi modeli oluşturmak, her zaman mevcut verileri üç gruba ayırmaya dayanır: eğitim, doğrulama ve test seti. Eğitim verileri, model tarafından dağılımın tuhaflıklarını ve özelliklerini öğrenmek için kullanılır.
Burada bilinmesi gereken bir odak noktası, modelin eğitim setindeki tatmin edici performansının, modelin benzer performansa sahip yeni veriler üzerinde genelleme yapacağı anlamına gelmediğidir, bunun nedeni modelin eğitim setine önyargılı hale gelmesidir. Bu nedenle doğrulama ve test seti kavramı, modelin yeni veri noktalarında ne kadar iyi genellediğini raporlamak için kullanılır.
Standart prosedür, eğitim verilerini modele uyacak şekilde kullanmak, doğrulama verilerini kullanarak model performansını değerlendirmek ve son olarak test verileri, modelin tamamen yeni örnekler üzerinde ne kadar iyi performans göstereceğini değerlendirmek için kullanılır.
Doğrulama seti, modelin iyi bir şekilde genelleştirilebilmesi için hiperparametreleri (gizli katman sayısı, öğrenme oranı, bırakma oranı vb.) ayarlamak için kullanılır. Makine öğrenimine yeni başlayanların karşılaştığı yaygın bir bilmece, ayrı doğrulama ve test setlerine duyulan ihtiyacı anlamaktır.

İki farklı kümeye duyulan ihtiyaç aşağıdaki sezgiyle anlaşılabilir: Tasarlanması gereken her derin sinir ağı için, tatmin edici performans için ayarlanması gereken çok sayıda hiperparametre vardır.
Birden fazla model, hiperparametrelerden herhangi biri kullanılarak eğitilebilir ve ardından en iyi performans metriğine sahip model, o modelin doğrulama setindeki performansına dayalı olarak seçilebilir. Şimdi, doğrulama setinde daha iyi performans için hiperparametreler her değiştirildiğinde, modele bazı bilgiler sızdırılır/beslenir , bu nedenle, sinir ağının son ağırlıkları doğrulama setine karşı önyargılı olabilir.
Hiperparametrenin her ayarlanmasından sonra modelimiz doğrulama setinde iyi performans göstermeye devam ediyor çünkü onu bunun için optimize ettik. Geçerlilik testinin modelin genelleme yeteneğini doğru bir şekilde gösterememesinin nedeni budur. Bu dezavantajın üstesinden gelmek için test seti devreye giriyor.
Bir modelin genelleme yeteneğinin en doğru temsili, modeli bu kümede daha iyi performans için optimize etmediğimiz için test kümesindeki performans tarafından verilir ve bu nedenle bu, modelin yeteneğinin en pragmatik tahminini gösterecektir.
Mutlaka Okuyun: Bilmeniz Gereken En İyi Derin Öğrenme Teknikleri
TensorFlow 2.0 Kullanarak Doğrulama Stratejilerini Uygulama
TensorFlow 2.0, modelimizin performansını ayrı bir uzatılmış doğrulama testinde izlemek için son derece kolay bir çözüm sunar. validation_split anahtar kelime argümanını model.fit() yönteminde iletebiliriz .
validation_split anahtar sözcüğü , doğrulama verileri olarak kullanılacak eğitim verilerinin kesirini temsil eden 0 ve 1 arasında kayan bir sayı olarak girdi alır . Bu nedenle, anahtar kelimede 0.1 değerini geçmek, doğrulama için eğitim verilerinin %10'unu ayırmak anlamına gelir.
Doğrulama bölmesinin pratik uygulaması, sklearn'den Diyabet Veri Kümesi kullanılarak kolayca gösterilebilir . Veri kümesinde, eğitim özellikleri olarak 10 temel değişken (yaş, cinsiyet, BMI, vb.) ve etiket olarak bir yıl sonra hastalık ilerlemesinin ölçüsü olan 442 örnek bulunur.
Veri setini TensorFlow ve sklearn kullanarak içe aktarıyoruz:

Veri ön işlemeden sonraki temel adım, yoğun katmanlarla sıralı bir ileri beslemeli sinir ağı oluşturmaktır:

Burada, relu aktivasyonlu altı gizli katmana ve lineer aktivasyonlu bir çıkış katmanına sahip bir sinir ağımız var .
Daha sonra modeli Adam optimizer ve ortalama kare hata kaybı fonksiyonu ile derleriz.


Model.fit () yöntemi daha sonra, modeli %15 validation_split ile 100 dönem için eğitmek için kullanılır .

Hem eğitim verileri hem de doğrulama verileri için gözlemlenen model kaybını da çizebiliriz:
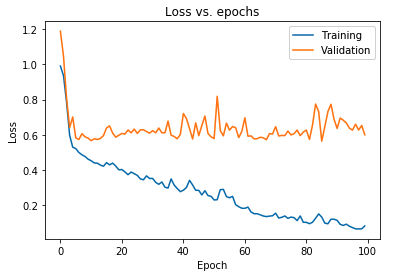
Yukarıda görüntülenen grafik, eğitim kaybı azalmaya devam ederken doğrulama kaybının 10 dönem sonra sürekli olarak arttığını göstermektedir. Bu eğilim, aşırı uydurma olarak adlandırılan, makine öğreniminde inanılmaz derecede önemli bir sorunun ders kitabı örneğidir .
Bu sorunun üstesinden gelmek için birçok ufuk açıcı araştırma yapılmıştır ve toplu olarak bu çözümlere düzenlileştirme teknikleri denir . Aşağıdaki bölüm, düzenlileştirme yönünü ve herhangi bir derin öğrenme modelini düzenleme prosedürünü kapsayacaktır.
Modelimizin Düzenlenmesi
Önceki bölümde, eğitim ve doğrulama setlerinin kayıp grafiklerinde, ikinci setin maliyet fonksiyonu grafiğinin yükseldiği ve önceki setin azalmaya devam ettiği ve dolayısıyla bir boşluk ( genelleme boşluğu ) oluşturduğunda ters bir eğilim gözlemledik . Makine öğreniminde düzenlileştirme hakkında daha fazla bilgi edinin.
İki kayıp grafiği arasında böyle bir boşluk olması, modelin doğrulama setinde ( görünmeyen veriler) iyi genelleme yapamayacağını ve dolayısıyla o veri setinde katlanılan maliyet/kayıp değerinin de kaçınılmaz olarak yüksek olacağını sembolize eder.
Bu tuhaflık, eğitilmiş modelin ağırlıkları ve yanlılıkları, eğitim verilerinin dağılımını o kadar iyi öğrenmek için birlikte uyarlanır ki, artan bir doğrulama kaybına yol açan yeni ve görünmeyen özelliklerin etiketlerini tahmin edemediğinden ortaya çıkar.
Bunun mantığı, model parametreleri eğitim verileri için oldukça sağlam hale gelmek üzere büyüdüğünden, karmaşık bir modelin yapılandırılmasının bu tür anormallikler üreteceğidir. Bu nedenle, model kapasitesini/karmaşıklığını basitleştirmek veya azaltmak, fazla uydurma etkisini azaltacaktır. Bunu başarmanın bir yolu, bir sonraki bölümde ele alacağımız derin öğrenme modelimizde terkleri kullanmaktır.
TensorFlow'da Eksikleri Anlama ve Uygulama
Bırakma kullanmanın arkasındaki temel algı, model parametrelerinin artmasını kısıtlayan ve dolayısıyla modeli genelleştirilmiş bir veri kümesinde performans için daha sağlam hale getiren daha az karmaşık bir model elde etmek için gizli ve görünür birimleri rastgele bırakmaktır.
Yakın zamanda kabul edilen bu uygulama, herhangi bir derin öğrenme modelinde düzenlileştirici bir etki yaratmak için makine öğrenimi uygulayıcıları tarafından kullanılan güçlü bir yaklaşımdır. Bırakma katmanını içe aktararak ve bırakılacak birimlerin kesirini belirtmek için oran argümanını geçirerek TensorFlow üzerinden Keras API'sini kullanarak kesintiler zahmetsizce uygulanabilir .
Bu bırakma katmanları, genellikle bir yoğun bırakma katmanı mimarisinin alternatif bir gelgitini üretmek için her yoğun katmandan hemen sonra istiflenir.
Önceden tanımlanmış ileri beslemeli sinir ağımızı, her bir gizli katman için bir tane olmak üzere altı bırakma katmanı içerecek şekilde değiştirebiliriz:


Burada, bırakma _ oranı 0,2'ye ayarlanmıştır; bu, model eğitilirken düğümlerin %20'sinin bırakılacağını belirtir. Adil bir karşılaştırma yapmak için modeli aynı optimize edici, kayıp fonksiyonu, metrikler ve dönem sayısı ile derliyor ve eğitiyoruz.
Modeli bırakmaları kullanarak düzenlemenin birincil etkisi, eğitim ve doğrulama setlerinde elde edilen modelin kayıp eğrisinin yeniden çizilmesiyle yorumlanabilir:
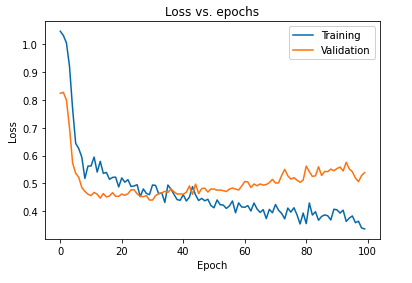
Modeli düzenli hale getirdikten sonra elde edilen genelleme boşluğunun çok daha az olduğu ve bu da modeli eğitim verilerine fazla uydurmaya daha az duyarlı hale getirdiği yukarıdaki grafikten açıkça görülmektedir.
Ayrıca Okuyun: Derin Öğrenme Projesi Fikirleri
Çözüm
Model doğrulama ve düzenleme yönü, herhangi bir makine öğrenimi çözümü oluşturma iş akışını tasarlamanın önemli bir parçasıdır. Denetimli öğrenmeyi doğaçlama yapmak için pek çok araştırma yürütülüyor ve bu uygulamalı eğitim, herhangi bir öğrenme algoritmasını kurarken en çok kabul edilen uygulama ve tekniklerin bazıları hakkında kısa bir fikir veriyor.
Derin öğrenme teknikleri , makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, IIIT-B & upGrad'ın çalışan profesyoneller için tasarlanmış ve 240+ saatlik zorlu eğitim, 5+ vaka çalışması sunan Makine Öğrenimi ve Derin Öğrenmede PG Sertifikasına göz atın & atamalar, IIIT-B Mezunları durumu ve en iyi firmalarla iş yardımı.