
Stork, Bölüm 2: Bir İfade Ayrıştırıcısı Oluşturma
Yayınlanan: 2022-03-11Serimizin bu bölümünde, her programlama dili için temel bir yapı taşı olan bir dil motorunu komut dosyası yazmanın (en azından benim görüşüme göre) daha zor bileşenlerinden birini ele alacağız: ifade ayrıştırıcı.
Okuyucunun sorabileceği ve haklı olarak sorabileceği bir soru şudur: Neden halihazırda elimizde olan bazı karmaşık araçlar veya kitaplıklar kullanmıyoruz?
Neden Lex, YACC, Bison, Boost Spirit veya en azından düzenli ifadeler kullanmıyoruz?
İlişkimiz boyunca eşim inkar edemeyeceğim bir özelliğimi fark etti: Ne zaman zor bir soruyla karşılaşsam liste yaparım. Bunu düşünürseniz, kesinlikle mantıklı - Cevabımdaki kalite eksikliğini telafi etmek için niceliği kullanıyorum.
Şimdi aynı şeyi yapacağım.
- Standart C++ kullanmak istiyorum. Bu durumda, bu C++17 olacaktır. Dilin kendi başına oldukça zengin olduğunu düşünüyorum ve standart kitaplıktan başka bir şeyi karışıma ekleme dürtüsüyle mücadele ediyorum.
- İlk betik dilimi geliştirdiğimde, karmaşık araçlar kullanmadım. Baskı altındaydım ve son teslim tarihim kısıtlıydı, ancak Lex, YACC veya benzeri bir şeyi nasıl kullanacağımı bilmiyordum. Bu nedenle, her şeyi manuel olarak geliştirmeye karar verdim.
- Daha sonra, bu araçlardan herhangi birinin kullanılmasına karşı tavsiyede bulunan deneyimli bir programlama dili geliştiricisine ait bir blog buldum. Bu araçların dil geliştirmenin daha kolay kısmını çözdüğünü söyledi, yani her durumda, zor şeylerle baş başa kaldınız. O blogu şu anda bulamıyorum, çok eskiden, hem internetin hem de benim gençliğimde.
- Aynı zamanda şöyle bir meme vardı: “Normal ifadeler kullanarak çözmeye karar verdiğiniz bir sorununuz var. Şimdi iki sorununuz var.”
- Lex, YACC, Bison veya benzeri bir şey bilmiyorum. Boost Spirit'i biliyorum ve bu kullanışlı ve harika bir kitaplık ama yine de ayrıştırıcı üzerinde daha iyi kontrol sahibi olmayı tercih ediyorum.
- Bu bileşenleri manuel olarak yapmayı seviyorum. Aslında sadece bu cevabı verebilir ve bu listeyi tamamen kaldırabilirim.
Kodun tamamı GitHub sayfamda mevcuttur.
Belirteç Yineleyici
Bölüm 1'deki kodda bazı değişiklikler var.
Bunlar çoğunlukla basit düzeltmeler ve küçük değişikliklerdir, ancak mevcut ayrıştırma koduna önemli bir ekleme token_iterator . Mevcut jetonu akıştan çıkarmadan değerlendirmemizi sağlar, bu gerçekten kullanışlıdır.
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; push_back_stream ile başlatılır ve ardından başvurudan çıkarılabilir ve artırılabilir. Geçerli belirteç eof'a eşit olduğunda yanlış olarak değerlendirilecek olan açık bool dökümü ile kontrol edilebilir.
Statik veya Dinamik Olarak Yazılan Dil?
Bu kısımda vermem gereken bir karar var: Bu dil statik mi yoksa dinamik olarak mı yazılacak?
Statik olarak yazılmış bir dil, derleme sırasında değişkenlerinin türlerini kontrol eden bir dildir.
Dinamik olarak yazılan bir dil ise, derleme sırasında (dinamik olarak yazılan bir dil için zorunlu olmayan bir derleme varsa) kontrol etmez, ancak yürütme sırasında kontrol eder. Bu nedenle, olası hatalar, vuruluncaya kadar kodda yaşayabilir.
Bu, statik olarak yazılan dillerin bariz bir avantajıdır. Herkes hatalarını bir an önce yakalamayı sever. Dinamik olarak yazılan dillerin en büyük avantajının ne olduğunu hep merak etmişimdir ve cevap son birkaç haftadır beni çok etkiledi: Geliştirmesi çok daha kolay!
Geliştirdiğim önceki dil dinamik olarak yazılmıştı. Sonuçtan az çok memnun kaldım ve ifade ayrıştırıcısını yazmak çok zor değildi. Temel olarak değişken türlerini kontrol etmeniz gerekmez ve neredeyse kendiliğinden kodladığınız çalışma zamanı hatalarına güvenirsiniz.
Örneğin, ikili + operatörünü yazmanız gerekiyorsa ve bunu sayılar için yapmak istiyorsanız, çalışma zamanında o operatörün her iki tarafını da sayı olarak değerlendirmeniz yeterlidir. Taraflardan biri sayıyı değerlendiremezse, sadece bir istisna atarsınız. Bir ifadedeki değişkenlerin çalışma zamanı türü bilgilerini kontrol ederek operatör aşırı yüklemesini bile uyguladım ve operatörler bu çalışma zamanı bilgilerinin bir parçasıydı.
Geliştirdiğim ilk dilde (bu benim üçüncü dilim), derleme sırasında tip denetimi yaptım, ancak bundan tam olarak yararlanmamıştım. İfade değerlendirmesi hala çalışma zamanı türü bilgisine bağlıydı.
Şimdi, statik olarak yazılmış bir dil geliştirmeye karar verdim ve bunun beklenenden çok daha zor bir iş olduğu ortaya çıktı. Ancak, onu bir ikili dosyaya veya herhangi bir türde öykünülmüş derleme koduna derlemeyi planlamadığım için, derlenmiş kodda dolaylı olarak bir tür bilgi bulunacaktır.
Türler
Desteklememiz gereken minimum tür olarak, aşağıdakilerle başlayacağız:
- sayılar
- Teller
- Fonksiyonlar
- diziler
Bunları ileriye dönük olarak ekleyebilsek de, başlangıçta yapıları (veya sınıfları, kayıtları, demetleri vb.) desteklemeyeceğiz. Ancak daha sonra ekleyebileceğimizi aklımızda tutacağız, bu yüzden kaderimizi değiştirmesi zor kararlarla mühürlemeyeceğiz.
İlk olarak, türü, bazı kuralları takip edecek bir dize olarak tanımlamak istedim. Her tanımlayıcı, derleme sırasında bu dizeyi değerine göre tutar ve bazen onu ayrıştırmamız gerekir. Örneğin, sayı dizisinin türünü “[sayı]” olarak kodlarsak, bu durumda “sayı” olan bir iç tür elde etmek için ilk ve son karakteri kırpmamız gerekir. Eğer düşünürsen bu oldukça kötü bir fikir.
Daha sonra sınıf olarak uygulamaya çalıştım. Bu sınıf, tür hakkında tüm bilgilere sahip olacaktır. Her tanımlayıcı, o sınıf için paylaşılan bir işaretçi tutacaktır. Sonunda, derleme sırasında kullanılan tüm türlerin kayıt defterine sahip olmayı düşündüm, böylece her tanımlayıcı kendi türüne yönelik ham işaretçiye sahip olacaktı.
Bu fikri beğendim, bu yüzden aşağıdakilerle sonuçlandık:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;Basit türler, numaralandırmanın üyeleridir:
enum struct simple_type { nothing, number, string, }; Numaralandırma üyesi nothing şey burada, C++ 'da bir anahtar kelime olduğu için kullanamadığım void için yer tutucu olarak yok.
Dizi türleri, type_handle tek üyesine sahip yapıyla temsil edilir.
struct array_type { type_handle inner_type_id; }; Açıkçası, dizi uzunluğu array_type bir parçası değildir, bu nedenle diziler dinamik olarak büyüyecektir. Bu, std::deque veya benzeri bir şeyle sonuçlanacağımız anlamına gelir, ancak bununla daha sonra ilgileneceğiz.
Bir işlev türü, dönüş türünden, parametrelerinin her birinin türünden ve bu parametrelerin her birinin değere veya başvuruya göre geçirilip geçirilmediğinden oluşur.
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };Şimdi bu tipleri tutacak sınıfı tanımlayabiliriz.
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; Türler std::set içinde tutulur, çünkü kapsayıcı sabittir, yani yeni türler eklendikten sonra bile üyelerine yönelik işaretçiler geçerlidir. Geçilen türü kaydeden ve işaretçiyi ona döndüren get_handle işlevi vardır. Tür zaten kayıtlıysa, işaretçiyi mevcut türe döndürür. İlkel türleri elde etmek için kolaylık işlevleri de vardır.
Türler arasındaki örtük dönüştürmeye gelince, sayılar dizelere dönüştürülebilir. Tehlikeli olmamalıdır, çünkü ters dönüştürme mümkün değildir ve dizi birleştirme operatörü, sayı ekleme operatöründen farklıdır. Bu çeviri, bu dilin gelişiminin sonraki aşamalarında kaldırılsa bile, bu noktada bir alıştırma olarak iyi hizmet edecektir. Bu amaçla, her zaman ayrıştırıldığı gibi sayı ayrıştırıcısını değiştirmek zorunda kaldım . ondalık nokta olarak. Birleştirme operatörünün ilk karakteri olabilir .. .
Derleyici Bağlamı
Derleme sırasında, farklı derleyici işlevlerinin o ana kadar derlenen kod hakkında bilgi alması gerekir. Bu bilgiyi compiler_context sınıfında tutacağız. İfade ayrıştırmayı uygulamak üzere olduğumuz için, karşılaştığımız tanımlayıcılar hakkında bilgi almamız gerekecek.
Çalışma zamanı boyunca değişkenleri iki farklı kapsayıcıda tutacağız. Bunlardan biri global değişken kapsayıcı, diğeri ise yığın olacaktır. Fonksiyonları çağırdıkça ve kapsamları girdikçe yığın büyüyecektir. Fonksiyonlardan döndüğümüzde ve kapsamlardan çıktığımızda küçülecek. Bir işlevi çağırdığımızda, işlev parametrelerine basacağız ve ardından işlev yürütülecektir. Dönüş değeri, ayrıldığında yığının en üstüne itilecektir. Bu nedenle, her işlev için yığın şöyle görünecektir:
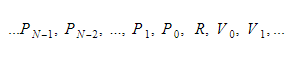
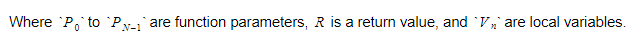
İşlev, dönüş değişkeninin mutlak indeksini tutacak ve her bir değişken veya parametre bu indekse göre bulunacaktır.
Şimdilik, fonksiyonları sabit global tanımlayıcılar olarak ele alacağız.
Bu, tanımlayıcı bilgi olarak hizmet veren sınıftır:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; Yerel değişkenler ve işlev parametreleri için işlev dizini, dönüş değerine göre index döndürür. Genel tanımlayıcılar olması durumunda mutlak küresel dizini döndürür.
compile_context içinde üç farklı tanımlayıcı aramamız olacak:
-
compile_context, tüm derleme boyunca aynı olduğu için değere göre tutulacak genel tanımlayıcı araması. - Global kapsamda
unique_ptrolacak ve herhangi bir işlevde başlatılacak olannullptrolarak yerel tanımlayıcı araması. Kapsama her girdiğimizde, yeni yerel bağlam, eskisi ebeveyni olarak başlatılacaktır. Kapsamdan ayrıldığımızda, üst öğesi tarafından değiştirilecektir. - Ham işaretçi olacak işlev tanımlayıcı araması. Global kapsamda
nullptrolacak ve herhangi bir fonksiyondaki en dıştaki yerel kapsamla aynı değerde olacaktır.
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };İfade Ağacı
İfade belirteçleri ayrıştırıldığında, bir ifade ağacına dönüştürülürler. Tüm ağaçlar gibi bu da düğümlerden oluşur.

İki farklı düğüm türü vardır:
- Olabilecek yaprak düğümleri:
a) Tanımlayıcılar
b) Sayılar
c) Dizeler - Alt düğümlerinde bir işlemi temsil eden iç düğümler. Çocuklarını
unique_ptrile tutar.
Her düğüm için, türü ve bir değer ( = operatörünün sol tarafında görünebilen bir değer) döndürüp döndürmediği hakkında bilgi vardır.
Bir iç düğüm oluşturulduğunda, çocuklarının dönüş türlerini beklediği türlere dönüştürmeye çalışacaktır. Aşağıdaki örtük dönüşümlere izin verilir:
- değerden değersize
-
voidiçin herhangi bir şey -
stringnumber
Dönüştürmeye izin verilmezse, anlamsal bir hata atılacaktır.
Bazı yardımcı işlevler ve uygulama ayrıntıları olmadan sınıf tanımı:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; yöntemlerin işlevselliği, check_conversion işlevi dışında kendiliğinden açıklayıcıdır. Tür dönüştürme kurallarına uyarak türün geçirilen type_id ve boolean lvalue dönüştürülebilir olup olmadığını kontrol edecek ve değilse bir istisna atacaktır.
Bir düğüm std::string veya double ile başlatılırsa, türü sırasıyla string veya number olur ve bir değer olmaz. Bir tanımlayıcı ile başlatılırsa, o tanımlayıcının türünü üstlenir ve tanımlayıcı sabit değilse bir değer olur.
Ancak bir düğüm işlemiyle başlatılırsa, türü işleme ve bazen de alt öğelerinin türüne bağlı olacaktır. Tablodaki ifade türlerini yazalım. Bir değeri belirtmek için & son ekini kullanacağım. Birden fazla ifadenin aynı muameleye sahip olduğu durumlarda, ek ifadeleri köşeli parantez içinde yazacağım.
Tekli İşlemler
| Operasyon | Operasyon türü | x tipi |
| ++x (--x) | numara& | numara& |
| x++ (x--) | numara | numara& |
| +x (-x ~x !x) | numara | numara |
İkili İşlemler
| Operasyon | Operasyon türü | x tipi | y tipi |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | numara | numara | numara |
| x==y (x!=y x<y x>y x<=y x>=y) | numara | sayı veya dize | x ile aynı |
| x..y | sicim | sicim | sicim |
| x=y | x ile aynı | hiçbir şeyin değeri | x ile aynı, değersiz |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | numara& | numara& | numara |
| x..=y | sicim& | sicim& | sicim |
| x,y | y ile aynı | geçersiz | herhangi bir şey |
| x[y] | eleman tipi x | dizi türü | numara |
Üçlü Operasyonlar
| Operasyon | Operasyon türü | x tipi | y tipi | z tipi |
| x?y:z | y ile aynı | numara | herhangi bir şey | y ile aynı |
İşlev Çağrısı
İşlev çağrısına gelince, işler biraz daha karmaşıklaşıyor. İşlevin N bağımsız değişkeni varsa, işlev çağrısı işleminin N+1 çocuğu vardır; burada ilk alt öğe işlevin kendisidir ve geri kalan alt öğeler işlev bağımsız değişkenlerine karşılık gelir.
Ancak, referans yoluyla dolaylı olarak argümanların iletilmesine izin vermeyeceğiz. Arayanın önüne & işareti koymasını isteyeceğiz. Şimdilik, bu ek bir operatör değil, işlev çağrısının ayrıştırılma şekli olacak. Ampersand'ı ayrıştırmazsak, argüman beklendiği zaman, node_operation::param dediğimiz sahte bir tekli işlem ekleyerek bu argümandan değeri kaldıracağız. Bu işlem, alt öğesiyle aynı türe sahiptir, ancak bir değer değildir.
Ardından, bu çağrı işlemi ile düğümü oluşturduğumuzda, değerli olan ancak işlev tarafından beklenmeyen bir argümanımız varsa, arayan kişinin yanlışlıkla ve işareti yazdığı anlamına geldiğinden bir hata üreteceğiz. Biraz şaşırtıcı bir şekilde, & , bir operatör olarak ele alınırsa, ifadenin içinde ayrıştırılırsa anlamsal olarak anlamı olmadığı için en az önceliğe sahip olur. Daha sonra değiştirebiliriz.
İfade Ayrıştırıcı
Ünlü bilgisayar bilimi filozofu Edsger Dijkstra, programcıların potansiyeli hakkındaki iddialarından birinde şöyle demişti:
“Önceden BASIC'e maruz kalmış öğrencilere iyi programlama öğretmek neredeyse imkansız. Potansiyel programcılar olarak, yenilenme umudunun ötesinde zihinsel olarak sakatlanmışlardır.”
Bu nedenle, BASIC'e maruz kalmayan hepiniz için - “zihinsel sakatlıktan” kurtulduğunuz için minnettar olun.
Geri kalanımız, sakatlanmış programcılar, BASIC'te kod yazdığımız günleri kendimize hatırlatmamıza izin verin. İntegral bölme için kullanılan bir \ operatörü vardı. İntegral ve kayan nokta sayıları için ayrı türlerin olmadığı bir dilde bu oldukça kullanışlı, bu yüzden aynı operatörü Stork'a ekledim. Ayrıca, tahmin ettiğiniz gibi, integral bölme işlemini gerçekleştirecek ve ardından atayacak olan \= operatörünü de ekledim.
Örneğin, bu tür operatörlerin JavaScript programcıları tarafından takdir edileceğini düşünüyorum. JS'nin artan popülaritesini görecek kadar uzun yaşasaydı Dijkstra'nın onlar hakkında ne söyleyeceğini hayal bile etmek istemiyorum.
Bununla ilgili olarak, JavaScript ile ilgili en büyük sorunlardan biri aşağıdaki ifadelerin tutarsızlığıdır:
-
"1" - “1”0olarak değerlendirilir -
"1" * “1”1değerlendirilir -
"1" / “1”1değerlendirilir -
"1" + “1”,“11”olarak değerlendirilir
Adını Zagreb'in ücra ilçelerini birbirine bağlayan bir tramvaydan alan Hırvat hip-hop ikilisi "Tram 11", kabaca "Bir ve bir iki değil, 11'dir" anlamına gelen bir şarkıya sahipti. 90'ların sonlarında ortaya çıktı, bu yüzden JavaScript'e bir referans değildi, ancak tutarsızlığı oldukça iyi gösteriyor.
Bu tutarsızlıklardan kaçınmak için, dizgeden sayıya örtük dönüştürmeyi yasakladım ve birleştirme için .. operatörünü ekledim (ve atama ile birleştirme için ..= ). Bu operatör fikrini nereden aldığımı hatırlamıyorum. BASIC veya PHP'den değil ve “Python birleştirme” ifadesini aramayacağım çünkü Python hakkında herhangi bir şeyi araştırmak omurgamı titretiyor. Yılan fobim var ve bunu "birleştirme" ile birleştirmek - hayır, teşekkürler! Belki daha sonra, bazı arkaik metin tabanlı tarayıcılarla, ASCII sanatı olmadan.
Ancak bu bölümün konusuna geri dönelim - ifade ayrıştırıcımız. “Shunting-yard Algoritması”nın bir uyarlamasını kullanacağız.
Ortalama bir programcının bile problemi 10 dakika kadar düşündükten sonra aklına gelen algoritma budur. Bir infix ifadesini değerlendirmek veya yapmayacağımız ters Lehçe notasyonuna dönüştürmek için kullanılabilir.
Algoritmanın fikri, işlenenleri ve operatörleri soldan sağa okumaktır. Bir işleneni okuduğumuzda, onu işlenen yığınına iteriz. Bir operatörü okuduğumuzda, aşağıdaki operatörün ondan daha iyi önceliğe sahip olup olmayacağını bilmediğimiz için hemen değerlendiremeyiz. Bu nedenle, onu operatör yığınına itiyoruz.
Ancak, önce yığının en üstündeki operatörün az önce okuduğumuzdan daha iyi önceliğe sahip olup olmadığını kontrol ederiz. Bu durumda, işlenen yığınındaki işlenenlerle birlikte operatörü yığının tepesinden değerlendiririz. Sonucu işlenen yığınına itiyoruz. Her şeyi okuyana kadar saklarız ve sonra operatör yığınının solundaki tüm operatörleri, işlenen yığınındaki işlenenlerle değerlendiririz, sonuçları işlenen yığınına geri iterek, hiçbir operatör ve yalnızca bir işlenen kalmayıncaya kadar çalışırız. sonuç.
İki operatör aynı önceliğe sahip olduğunda, bu operatörlerin sol ilişkisel olması durumunda soldakini alacağız; yoksa doğru olanı alırız. Aynı önceliğe sahip iki operatörün farklı çağrışımları olamaz.
Orijinal algoritma ayrıca yuvarlak parantezleri de ele alır, ancak algoritma bu şekilde daha temiz olacağından bunun yerine özyinelemeli olarak yapacağız.
Edsger Dijkstra, bir demiryolu manevra sahasının işleyişine benzediği için algoritmaya “Sunting-yard” adını verdi.
Bununla birlikte, orijinal manevra alanı algoritması neredeyse hiç hata denetimi yapmaz, bu nedenle geçersiz bir ifadenin doğru bir ifade olarak ayrıştırılması oldukça olasıdır. Bu nedenle, bir operatör mü yoksa işlenen mi beklediğimizi kontrol eden boole değişkenini ekledim. İşlenenler bekliyorsak, tekli önek operatörlerini de ayrıştırabiliriz. Bu şekilde, hiçbir geçersiz ifade radarın altından geçemez ve ifade sözdizimi kontrolü tamamlanır.
Toplama
Serinin bu kısmı için kodlamaya başladığımda, ifade oluşturucu hakkında yazmayı planlamıştım. Değerlendirilebilecek bir ifade oluşturmak istedim. Ancak, bir blog yazısı için çok karmaşık olduğu ortaya çıktı, bu yüzden ikiye bölmeye karar verdim. Bu bölümde ifadeleri ayrıştırmayı tamamladık ve bir sonraki makalede ifade nesneleri oluşturma hakkında yazacağım.
Doğru hatırlıyorsam, yaklaşık 15 yıl önce, ana dilimin ilk versiyonunu yazmam bir hafta sonunu aldı, bu da bu sefer neyin yanlış gittiğini merak etmeme neden oldu.
Yaşlandığımı ve daha az esprili olduğumu inkar etmek için iki yaşındaki oğlumu boş zamanlarımda çok talepkar olduğu için suçlayacağım.
Bölüm 1'de olduğu gibi, GitHub sayfamdan kodu okuyabilir, indirebilir ve hatta derleyebilirsiniz.