
Bangau, Bagian 2: Membuat Pengurai Ekspresi
Diterbitkan: 2022-03-11Di bagian seri ini, kami akan membahas salah satu komponen yang lebih rumit (setidaknya menurut saya) dari skrip mesin bahasa, yang merupakan blok bangunan penting untuk setiap bahasa pemrograman: parser ekspresi.
Sebuah pertanyaan yang dapat diajukan pembaca—dan memang seharusnya demikian—adalah: Mengapa kita tidak menggunakan beberapa alat atau pustaka yang canggih saja, sesuatu yang sudah tersedia untuk kita?
Mengapa kita tidak menggunakan Lex, YACC, Bison, Boost Spirit, atau setidaknya ekspresi reguler?
Sepanjang hubungan kami, istri saya telah memperhatikan sifat saya yang tidak dapat saya sangkal: Setiap kali dihadapkan pada pertanyaan yang sulit, saya membuat daftar. Jika Anda memikirkannya, itu masuk akal—saya menggunakan kuantitas untuk mengimbangi kurangnya kualitas dalam jawaban saya.
Saya akan melakukan hal yang sama sekarang.
- Saya ingin menggunakan C++ standar. Dalam hal ini, itu akan menjadi C++17. Saya pikir bahasanya sendiri cukup kaya, dan saya melawan keinginan untuk menambahkan apa pun kecuali perpustakaan standar ke dalam campuran.
- Ketika saya mengembangkan bahasa scripting pertama saya, saya tidak menggunakan alat yang canggih. Saya berada di bawah tekanan dan tenggat waktu yang ketat, namun saya tidak tahu bagaimana menggunakan Lex, YACC, atau yang serupa. Karena itu, saya memutuskan untuk mengembangkan semuanya secara manual.
- Kemudian, saya menemukan sebuah blog oleh pengembang bahasa pemrograman yang berpengalaman, yang menyarankan untuk tidak menggunakan salah satu alat ini. Dia mengatakan alat-alat itu menyelesaikan bagian yang lebih mudah dari pengembangan bahasa, jadi bagaimanapun juga, Anda hanya memiliki hal-hal yang sulit. Saya tidak dapat menemukan blog itu sekarang, karena sudah lama sekali, ketika saya dan internet masih muda.
- Pada saat yang sama, ada meme yang mengatakan: “Anda memiliki masalah yang Anda putuskan untuk diselesaikan dengan menggunakan ekspresi reguler. Sekarang Anda memiliki dua masalah. ”
- Saya tidak tahu Lex, YACC, Bison, atau yang serupa. Saya tahu Boost Spirit, dan ini adalah perpustakaan yang berguna dan menakjubkan, tetapi saya masih lebih suka memiliki kontrol yang lebih baik atas parser.
- Saya suka melakukan komponen-komponen itu secara manual. Sebenarnya, saya hanya bisa memberikan jawaban ini dan menghapus daftar ini sepenuhnya.
Kode lengkapnya tersedia di halaman GitHub saya.
Token Iterator
Ada beberapa perubahan pada kode dari Bagian 1.
Ini sebagian besar adalah perbaikan sederhana dan perubahan kecil, tetapi satu tambahan penting untuk kode penguraian yang ada adalah kelas token_iterator . Ini memungkinkan kami untuk mengevaluasi token saat ini tanpa menghapusnya dari aliran, yang sangat berguna.
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; Ini diinisialisasi dengan push_back_stream , dan kemudian dapat diturunkan dan ditambah. Itu dapat diperiksa dengan bool cast eksplisit, yang akan dievaluasi menjadi false ketika token saat ini sama dengan eof.
Bahasa yang Diketik Secara Statis atau Dinamis?
Ada satu keputusan yang harus saya buat di bagian ini: Apakah bahasa ini akan diketik secara statis atau dinamis?
Bahasa yang diketik secara statis adalah bahasa yang memeriksa jenis variabelnya pada saat kompilasi.
Bahasa yang diketik secara dinamis , di sisi lain, tidak memeriksanya selama kompilasi (jika ada kompilasi, yang tidak wajib untuk bahasa yang diketik secara dinamis) tetapi selama eksekusi. Oleh karena itu, kesalahan potensial dapat hidup dalam kode sampai mereka terkena.
Ini adalah keuntungan nyata dari bahasa yang diketik secara statis. Semua orang suka menangkap kesalahan mereka sesegera mungkin. Saya selalu bertanya-tanya apa keuntungan terbesar dari bahasa yang diketik secara dinamis, dan jawabannya mengejutkan saya dalam beberapa minggu terakhir: Jauh lebih mudah untuk dikembangkan!
Bahasa sebelumnya yang saya kembangkan diketik secara dinamis. Saya kurang lebih puas dengan hasilnya, dan menulis pengurai ekspresi tidak terlalu sulit. Anda pada dasarnya tidak perlu memeriksa jenis variabel dan Anda mengandalkan kesalahan runtime, yang Anda kode hampir secara spontan.
Misalnya, jika Anda harus menulis operator + biner dan Anda ingin melakukannya untuk angka, Anda hanya perlu mengevaluasi kedua sisi operator itu sebagai angka di runtime. Jika salah satu sisi tidak dapat mengevaluasi nomor, Anda hanya melemparkan pengecualian. Saya bahkan telah menerapkan kelebihan beban operator dengan memeriksa informasi jenis waktu proses dari variabel dalam ekspresi, dan operator adalah bagian dari informasi waktu proses itu.
Dalam bahasa pertama yang saya kembangkan (ini adalah bahasa ketiga saya), saya melakukan pengecekan ketik pada saat kompilasi, tetapi saya belum memanfaatkannya sepenuhnya. Evaluasi ekspresi masih tergantung pada informasi jenis runtime.
Sekarang, saya memutuskan untuk mengembangkan bahasa yang diketik secara statis, dan ternyata itu menjadi tugas yang jauh lebih sulit dari yang diharapkan. Namun, karena saya tidak berencana untuk mengompilasinya ke biner, atau segala jenis kode perakitan yang ditiru, beberapa jenis informasi secara implisit akan ada dalam kode yang dikompilasi.
Jenis
Sebagai minimal jenis yang harus kami dukung, kami akan mulai dengan yang berikut:
- angka
- string
- Fungsi
- Array
Meskipun kami dapat menambahkannya ke depan, kami tidak akan mendukung struktur (atau kelas, catatan, tupel, dll.) di awal. Namun, kami akan ingat bahwa kami dapat menambahkannya nanti, jadi kami tidak akan menutup nasib kami dengan keputusan yang sulit diubah.
Pertama, saya ingin mendefinisikan tipe sebagai string, yang akan mengikuti beberapa konvensi. Setiap pengenal akan menyimpan string itu berdasarkan nilai pada saat kompilasi, dan terkadang kita harus menguraikannya. Misalnya, jika kita mengkodekan tipe larik angka sebagai “[angka],” maka kita harus memangkas karakter pertama dan terakhir untuk mendapatkan tipe dalam, yaitu “angka” dalam kasus ini. Ini ide yang sangat buruk jika Anda memikirkannya.
Kemudian, saya mencoba mengimplementasikannya sebagai kelas. Kelas itu akan memiliki semua informasi tentang tipenya. Setiap pengenal akan menyimpan pointer bersama ke kelas itu. Pada akhirnya, saya berpikir untuk memiliki registri dari semua jenis yang digunakan selama kompilasi, sehingga setiap pengenal akan memiliki penunjuk mentah ke jenisnya.
Saya menyukai ide itu, jadi kami berakhir dengan yang berikut:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;Tipe sederhana adalah anggota enum:
enum struct simple_type { nothing, number, string, }; Anggota pencacahan nothing ada di sini sebagai pengganti untuk void , yang tidak dapat saya gunakan karena ini adalah kata kunci dalam C++.
Tipe array direpresentasikan dengan struktur yang memiliki satu-satunya anggota type_handle .
struct array_type { type_handle inner_type_id; }; Jelas, panjang array bukan bagian dari array_type , jadi array akan tumbuh secara dinamis. Itu berarti bahwa kita akan berakhir dengan std::deque atau yang serupa, tetapi kita akan menanganinya nanti.
Tipe fungsi terdiri dari tipe kembaliannya, tipe setiap parameternya, dan apakah masing-masing parameter tersebut dilewatkan dengan nilai atau referensi.
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };Sekarang, kita dapat mendefinisikan kelas yang akan menyimpan tipe-tipe tersebut.
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; Tipe disimpan di std::set , karena wadah itu stabil, artinya pointer ke anggotanya valid bahkan setelah tipe baru dimasukkan. Ada fungsi get_handle , yang mendaftarkan tipe yang diteruskan dan mengembalikan pointer ke sana. Jika tipe sudah terdaftar, maka pointer akan kembali ke tipe yang ada. Ada juga fungsi kemudahan untuk mendapatkan tipe primitif.
Adapun konversi implisit antar tipe, angka akan dapat dikonversi menjadi string. Seharusnya tidak berbahaya, karena konversi terbalik tidak dimungkinkan, dan operator untuk penggabungan string berbeda dengan operator untuk penambahan angka. Bahkan jika konversi itu dihilangkan pada tahap akhir perkembangan bahasa ini, itu akan berfungsi dengan baik sebagai latihan pada saat ini. Untuk tujuan itu, saya harus memodifikasi pengurai angka, seperti yang selalu diuraikan . sebagai titik desimal. Ini mungkin karakter pertama dari operator rangkaian .. .
Konteks Kompilator
Selama kompilasi, fungsi kompiler yang berbeda perlu mendapatkan informasi tentang kode yang dikompilasi sejauh ini. Kami akan menyimpan informasi itu dalam class compiler_context . Karena kita akan mengimplementasikan penguraian ekspresi, kita perlu mengambil informasi tentang pengidentifikasi yang kita temui.
Selama runtime, kami akan menyimpan variabel dalam dua wadah yang berbeda. Salah satunya akan menjadi wadah variabel global, dan yang lain akan menjadi tumpukan. Tumpukan akan bertambah saat kita memanggil fungsi dan memasukkan cakupan. Itu akan menyusut saat kami kembali dari fungsi dan meninggalkan cakupan. Ketika kita memanggil beberapa fungsi, kita akan menekan parameter fungsi, dan kemudian fungsi tersebut akan dieksekusi. Nilai pengembaliannya akan didorong ke atas tumpukan saat ia keluar. Oleh karena itu, untuk setiap fungsi, tumpukan akan terlihat seperti ini:
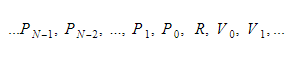
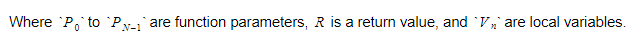
Fungsi akan menjaga indeks absolut dari variabel kembali, dan setiap variabel atau parameter akan ditemukan relatif terhadap indeks itu.
Untuk saat ini, kami akan memperlakukan fungsi sebagai pengidentifikasi global konstan.
Ini adalah kelas yang berfungsi sebagai informasi pengenal:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; Untuk variabel lokal dan parameter fungsi, index fungsi mengembalikan indeks relatif terhadap nilai kembalian. Ini mengembalikan indeks global absolut dalam kasus pengidentifikasi global.
Kami akan memiliki tiga pencarian pengenal yang berbeda di compile_context :
- Pencarian pengenal global, yang akan
compile_contextdisimpan berdasarkan nilai, karena nilainya sama di seluruh kompilasi. - Pencarian pengenal lokal, sebagai
unique_ptr, yang akan menjadinullptrdalam lingkup global dan akan diinisialisasi dalam fungsi apa pun. Setiap kali kita memasuki ruang lingkup, konteks lokal baru akan diinisialisasi dengan yang lama sebagai induknya. Ketika kita meninggalkan ruang lingkup, itu akan digantikan oleh induknya. - Pencarian pengidentifikasi fungsi, yang akan menjadi penunjuk mentah. Ini akan menjadi
nullptrdalam lingkup global, dan nilai yang sama dengan lingkup lokal terluar dalam fungsi apa pun.
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };Pohon Ekspresi
Saat token ekspresi diurai, mereka dikonversi menjadi pohon ekspresi. Mirip dengan semua pohon, yang satu ini juga terdiri dari node.

Ada dua jenis node yang berbeda:
- Node daun, yang dapat berupa:
a) Pengidentifikasi
b) Angka
c) Senar - Node dalam, yang mewakili operasi pada node anak mereka. Itu membuat anak-anaknya dengan
unique_ptr.
Untuk setiap node, ada informasi tentang jenisnya dan apakah itu mengembalikan nilai atau tidak (nilai yang dapat muncul di sisi kiri = operator).
Ketika simpul dalam dibuat, ia akan mencoba mengonversi tipe kembalian turunannya ke tipe yang diharapkannya. Konversi implisit berikut diizinkan:
- lnilai ke non-nilai
- Apa pun untuk
void -
numberkestring
Jika konversi tidak diizinkan, kesalahan semantik akan terjadi.
Berikut adalah definisi kelas, tanpa beberapa fungsi pembantu dan detail implementasi:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; Fungsionalitas metode cukup jelas, kecuali untuk fungsi check_conversion . Ini akan memeriksa apakah tipe tersebut dapat dikonversi ke type_id dan lvalue boolean yang diteruskan dengan mematuhi aturan konversi tipe dan akan mengeluarkan pengecualian jika tidak.
Jika sebuah node diinisialisasi dengan std::string , atau double , tipenya akan menjadi string atau number , masing-masing, dan itu tidak akan menjadi lvalue. Jika diinisialisasi dengan pengidentifikasi, itu akan mengasumsikan jenis pengidentifikasi itu dan akan menjadi nilai jika pengidentifikasi tidak konstan.
Namun, jika diinisialisasi, dengan operasi simpul, jenisnya akan bergantung pada operasi, dan terkadang pada jenis anak-anaknya. Mari kita tulis tipe ekspresi dalam tabel. Saya akan menggunakan & akhiran untuk menunjukkan nilai. Dalam kasus ketika beberapa ekspresi memiliki perlakuan yang sama, saya akan menulis ekspresi tambahan dalam tanda kurung bulat.
Operasi Unary
| Operasi | Jenis operasi | tipe x |
| ++x (--x) | nomor& | nomor& |
| x++ (x--) | nomor | nomor& |
| +x (-x ~x !x) | nomor | nomor |
Operasi Biner
| Operasi | Jenis operasi | tipe x | tipe y |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | nomor | nomor | nomor |
| x==y (x!=y x<y x>y x<=y x>=y) | nomor | nomor atau string | sama dengan x |
| x..y | rangkaian | rangkaian | rangkaian |
| x=y | sama dengan x | nilai apapun | sama dengan x, tanpa nilai |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | nomor& | nomor& | nomor |
| x..=y | rangkaian& | rangkaian& | rangkaian |
| x,y | sama seperti kamu | kosong | apa pun |
| x[y] | tipe elemen x | tipe larik | nomor |
Operasi Terner
| Operasi | Jenis operasi | tipe x | tipe y | tipe z |
| x?y:z | sama seperti kamu | nomor | apa pun | sama seperti kamu |
Panggilan Fungsi
Ketika datang ke panggilan fungsi, segalanya menjadi sedikit lebih rumit. Jika fungsi memiliki N argumen, operasi pemanggilan fungsi memiliki N+1 anak, di mana anak pertama adalah fungsi itu sendiri, dan anak-anak lainnya sesuai dengan argumen fungsi.
Namun, kami tidak akan mengizinkan argumen yang lewat secara implisit dengan referensi. Kami akan meminta penelepon untuk mengawalinya dengan tanda & . Untuk saat ini, itu tidak akan menjadi operator tambahan tetapi cara panggilan fungsi diuraikan. Jika kita tidak mengurai ampersand, ketika argumen diharapkan, kita akan menghapus nilai-nilai dari argumen itu dengan menambahkan operasi unary palsu yang kita sebut node_operation::param . Operasi itu memiliki tipe yang sama dengan anaknya, tetapi itu bukan nilai.
Kemudian, ketika kita membangun node dengan operasi panggilan itu, jika kita memiliki argumen yang bernilai tetapi tidak diharapkan oleh fungsi, kita akan menghasilkan kesalahan, karena itu berarti pemanggil mengetik ampersand secara tidak sengaja. Agak mengejutkan, bahwa & , jika diperlakukan sebagai operator, akan memiliki prioritas paling rendah, karena tidak memiliki arti secara semantik jika diuraikan di dalam ekspresi. Kami dapat mengubahnya nanti.
Pengurai Ekspresi
Dalam salah satu klaimnya tentang potensi programmer, filsuf ilmu komputer terkenal Edsger Dijkstra pernah berkata:
“Praktis tidak mungkin mengajarkan pemrograman yang baik kepada siswa yang telah memiliki pengalaman sebelumnya dengan BASIC. Sebagai pemrogram potensial, mereka secara mental dimutilasi di luar harapan regenerasi. ”
Jadi, bagi Anda semua yang belum terpapar BASIC - bersyukurlah, karena Anda lolos dari “mutilasi mental.”
Kita semua, programmer yang dimutilasi, mari kita ingatkan diri kita sendiri pada hari-hari ketika kita membuat kode dalam BASIC. Ada operator \ , yang digunakan untuk pembagian integral. Dalam bahasa di mana Anda tidak memiliki tipe terpisah untuk integral dan bilangan floating point, itu cukup berguna, jadi saya menambahkan operator yang sama ke Stork. Saya juga menambahkan operator \= , yang akan, seperti yang Anda tebak, melakukan pembagian integral dan kemudian menetapkan.
Saya pikir operator seperti itu akan dihargai oleh programmer JavaScript, misalnya. Saya bahkan tidak ingin membayangkan apa yang akan dikatakan Dijkstra tentang mereka jika dia hidup cukup lama untuk melihat popularitas JS yang meningkat.
Omong-omong, salah satu masalah terbesar yang saya miliki dengan JavaScript adalah perbedaan ekspresi berikut:
-
"1" - “1”bernilai0 -
"1" * “1”dievaluasi menjadi1 -
"1" / “1”dievaluasi menjadi1 -
"1" + “1”dievaluasi menjadi“11”
Duo hip-hop Kroasia “Tram 11,” dinamai dari sebuah trem yang menghubungkan daerah-daerah terpencil di Zagreb, memiliki sebuah lagu yang secara kasar diterjemahkan sebagai: “Satu dan satu bukan dua, tetapi 11.” Itu keluar di akhir 90-an, jadi itu bukan referensi ke JavaScript, tetapi menggambarkan perbedaan dengan cukup baik.
Untuk menghindari perbedaan tersebut, saya melarang konversi implisit dari string ke angka, dan saya menambahkan .. operator untuk rangkaian (dan ..= untuk rangkaian dengan tugas). Saya tidak ingat dari mana saya mendapatkan ide untuk operator itu. Ini bukan dari BASIC atau PHP, dan saya tidak akan mencari frasa "Python concatenation" karena googling apa pun tentang Python membuat saya merinding. Saya memiliki fobia ular, dan menggabungkannya dengan "gabungan" - tidak, terima kasih! Mungkin nanti, dengan beberapa browser berbasis teks kuno, tanpa seni ASCII.
Tapi kembali ke topik bagian ini - pengurai ekspresi kita. Kami akan menggunakan adaptasi dari “Algoritma Shunting-yard.”
Itulah algoritme yang muncul di benak setiap programmer rata-rata setelah memikirkan masalah selama 10 menit atau lebih. Ini dapat digunakan untuk mengevaluasi ekspresi infiks atau mengubahnya ke notasi Polandia terbalik, yang tidak akan kita lakukan.
Ide dari algoritma ini adalah untuk membaca operan dan operator dari kiri ke kanan. Saat kami membaca sebuah operan, kami mendorongnya ke tumpukan operan. Ketika kita membaca sebuah operator, kita tidak dapat langsung mengevaluasinya, karena kita tidak tahu apakah operator berikut akan memiliki prioritas yang lebih baik dari yang itu. Oleh karena itu, kami mendorongnya ke tumpukan operator.
Namun, pertama-tama kami memeriksa apakah operator di bagian atas tumpukan memiliki prioritas yang lebih baik daripada yang baru saja kami baca. Dalam hal ini, kami mengevaluasi operator dari atas tumpukan dengan operan pada tumpukan operan. Kami mendorong hasilnya ke tumpukan operan. Kami menyimpannya sampai kami membaca semuanya dan kemudian mengevaluasi semua operator di sebelah kiri tumpukan operator dengan operan pada tumpukan operan, mendorong hasil kembali pada tumpukan operan sampai kami dibiarkan tanpa operator dan hanya dengan satu operan, yaitu hasil.
Ketika dua operator memiliki prioritas yang sama, kami akan mengambil operator kiri jika operator tersebut asosiatif kiri; jika tidak, kami mengambil yang benar. Dua operator dengan prioritas yang sama tidak dapat memiliki asosiatifitas yang berbeda.
Algoritme asli juga menangani tanda kurung bulat, tetapi kami akan melakukannya secara rekursif, karena algoritme akan lebih bersih dengan cara itu.
Edsger Dijkstra menamakan algoritma “Shunting-yard” karena menyerupai pengoperasian shunting yard rel kereta api.
Namun, algoritme shunting-yard asli hampir tidak melakukan pemeriksaan kesalahan, jadi sangat mungkin bahwa ekspresi yang tidak valid diuraikan sebagai ekspresi yang benar. Oleh karena itu, saya menambahkan variabel boolean yang memeriksa apakah kita mengharapkan operator atau operan. Jika kita mengharapkan operan, kita juga dapat mengurai operator prefiks unary. Dengan begitu, tidak ada ekspresi yang tidak valid yang dapat lolos dari radar, dan pemeriksaan sintaks ekspresi selesai.
Membungkus
Ketika saya mulai membuat kode untuk bagian seri ini, saya berencana untuk menulis tentang pembuat ekspresi. Saya ingin membangun ekspresi yang dapat dievaluasi. Namun, ternyata terlalu rumit untuk satu posting blog, jadi saya memutuskan untuk membaginya menjadi dua. Di bagian ini, kami menyimpulkan ekspresi parsing, dan saya akan menulis tentang membangun objek ekspresi di artikel berikutnya.
Jika saya mengingatnya dengan benar, sekitar 15 tahun yang lalu, saya membutuhkan satu akhir pekan untuk menulis versi pertama dari bahasa pertama saya, yang membuat saya bertanya-tanya apa yang salah kali ini.
Dalam upaya untuk menyangkal bahwa saya semakin tua dan kurang cerdas, saya akan menyalahkan putra saya yang berusia dua tahun karena terlalu menuntut waktu luang saya.
Seperti pada Bagian 1, Anda dipersilakan untuk membaca, mengunduh, atau bahkan mengkompilasi kode dari halaman GitHub saya.