
นกกระสา ตอนที่ 2: การสร้างตัวแยกวิเคราะห์นิพจน์
เผยแพร่แล้ว: 2022-03-11ในส่วนนี้ของซีรีส์ เราจะพูดถึงองค์ประกอบที่ซับซ้อนกว่า (อย่างน้อยในความคิดของฉัน) ของการเขียนสคริปต์เอ็นจิ้นภาษา ซึ่งเป็นองค์ประกอบพื้นฐานที่จำเป็นสำหรับภาษาการเขียนโปรแกรมทุกภาษา: ตัวแยกวิเคราะห์นิพจน์
คำถามที่ผู้อ่านสามารถถามได้—และถูกต้อง—คือ: ทำไมเราไม่ใช้เครื่องมือหรือไลบรารีที่ซับซ้อนบางอย่างซึ่งมีอยู่แล้วในการกำจัดของเรา
ทำไมเราไม่ใช้ Lex, YACC, Bison, Boost Spirit หรือนิพจน์ทั่วไปอย่างน้อย
ตลอดความสัมพันธ์ของเรา ภรรยาของฉันสังเกตเห็นคุณลักษณะของฉันที่ฉันไม่สามารถปฏิเสธได้: เมื่อใดก็ตามที่ต้องเผชิญกับคำถามยากๆ ฉันจะทำรายการ ถ้าคุณลองคิดดูแล้ว มันสมเหตุสมผลดี—ฉันกำลังใช้ปริมาณเพื่อชดเชยการขาดคุณภาพในคำตอบของฉัน
ฉันจะทำสิ่งเดียวกันตอนนี้
- ฉันต้องการใช้มาตรฐาน C++ ในกรณีนี้ จะเป็น C++17 ฉันคิดว่าภาษานั้นสมบูรณ์ด้วยตัวมันเอง และฉันกำลังต่อสู้กับความอยากที่จะเพิ่มสิ่งใดนอกจากไลบรารีมาตรฐานลงในมิกซ์
- เมื่อฉันพัฒนาภาษาสคริปต์แรกของฉัน ฉันไม่ได้ใช้เครื่องมือที่ซับซ้อนใดๆ ฉันอยู่ภายใต้แรงกดดันและกำหนดเวลาที่รัดกุม แต่ฉันไม่รู้วิธีใช้ Lex, YACC หรืออะไรที่คล้ายกัน ดังนั้นฉันจึงตัดสินใจพัฒนาทุกอย่างด้วยตนเอง
- ต่อมา ฉันพบบล็อกโดยนักพัฒนาภาษาโปรแกรมที่มีประสบการณ์ ซึ่งแนะนำไม่ให้ใช้เครื่องมือเหล่านี้ เขากล่าวว่าเครื่องมือเหล่านั้นช่วยแก้ไขส่วนที่ง่ายกว่าของการพัฒนาภาษา ดังนั้นไม่ว่าในกรณีใด คุณจะเหลือสิ่งที่ยาก หาบล็อกนั้นไม่เจอเลย เพราะมันนานมาแล้ว ตอนที่ทั้งอินเทอร์เน็ตและฉันยังเด็ก
- ในเวลาเดียวกัน มีมส์หนึ่งพูดว่า: “คุณมีปัญหาซึ่งคุณตัดสินใจแก้ไขโดยใช้นิพจน์ทั่วไป ตอนนี้คุณมีปัญหาสองประการ”
- ฉันไม่รู้จัก Lex, YACC, Bison หรืออะไรที่คล้ายกัน ฉันรู้จัก Boost Spirit และเป็นห้องสมุดที่มีประโยชน์และน่าทึ่ง แต่ฉันก็ยังชอบที่จะควบคุมตัวแยกวิเคราะห์ได้ดีขึ้น
- ฉันชอบที่จะทำส่วนประกอบเหล่านั้นด้วยตนเอง อันที่จริง ฉันสามารถให้คำตอบนี้และลบรายการนี้ทั้งหมดได้
รหัสเต็มมีอยู่ที่หน้า GitHub ของฉัน
Token Iterator
มีการเปลี่ยนแปลงโค้ดบางส่วนจากส่วนที่ 1
สิ่งเหล่านี้ส่วนใหญ่เป็นการแก้ไขง่ายๆ และการเปลี่ยนแปลงเล็กน้อย แต่การเพิ่มที่สำคัญอย่างหนึ่งในโค้ดการแยกวิเคราะห์ที่มีอยู่คือคลาส token_iterator ช่วยให้เราสามารถประเมินโทเค็นปัจจุบันโดยไม่ต้องลบออกจากสตรีม ซึ่งสะดวกมาก
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; มันถูกเริ่มต้นด้วย push_back_stream จากนั้นสามารถยกเลิกและเพิ่มขึ้นได้ สามารถตรวจสอบได้ด้วย bool cast ซึ่งจะประเมินเป็นเท็จเมื่อโทเค็นปัจจุบันเท่ากับ eof
ภาษาที่พิมพ์แบบคงที่หรือแบบไดนามิก?
มีการตัดสินใจอย่างหนึ่งที่ฉันต้องทำในส่วนนี้: ภาษานี้จะพิมพ์แบบสแตติกหรือไดนามิกหรือไม่
ภาษาที่ พิมพ์แบบสถิต คือภาษาที่ตรวจสอบประเภทของตัวแปรในขณะที่คอมไพล์
ในทางกลับกัน ภาษาที่ พิมพ์แบบไดนามิก จะไม่ตรวจสอบในระหว่างการคอมไพล์ (หากมีการคอมไพล์ ซึ่งไม่จำเป็นสำหรับภาษาที่พิมพ์แบบไดนามิก) แต่ระหว่างการดำเนินการ ดังนั้น ข้อผิดพลาดที่อาจเกิดขึ้นสามารถอยู่ในโค้ดได้จนกว่าจะถูกโจมตี
นี่เป็นข้อได้เปรียบที่ชัดเจนของภาษาที่พิมพ์แบบสแตติก ทุกคนชอบที่จะจับข้อผิดพลาดโดยเร็วที่สุด ฉันเคยสงสัยอยู่เสมอว่าข้อดีที่ใหญ่ที่สุดของภาษาที่พิมพ์แบบไดนามิกคืออะไร และคำตอบก็โดนใจฉันในสองสามสัปดาห์ที่ผ่านมา: การพัฒนาง่ายขึ้นมาก!
ภาษาก่อนหน้าที่ฉันพัฒนาเป็นแบบพิมพ์แบบไดนามิก ฉันพอใจกับผลลัพธ์ไม่มากก็น้อย และการเขียนนิพจน์ parser ก็ไม่ยากเกินไป โดยพื้นฐานแล้วคุณไม่จำเป็นต้องตรวจสอบประเภทตัวแปรและคุณต้องพึ่งพาข้อผิดพลาดรันไทม์ซึ่งคุณเขียนโค้ดได้เกือบจะเป็นธรรมชาติ
ตัวอย่างเช่น หากคุณต้องเขียนตัวดำเนินการไบนารี + และต้องการเขียนตัวเลข คุณเพียงแค่ประเมินทั้งสองด้านของตัวดำเนินการนั้นเป็นตัวเลขในรันไทม์ หากด้านใดด้านหนึ่งไม่สามารถประเมินตัวเลขได้ คุณก็แค่โยนข้อยกเว้น ฉันยังใช้โอเปอเรเตอร์โอเวอร์โหลดด้วยการตรวจสอบข้อมูลประเภทรันไทม์ของตัวแปรในนิพจน์ และโอเปอเรเตอร์ก็เป็นส่วนหนึ่งของข้อมูลรันไทม์นั้น
ในภาษาแรกที่ฉันพัฒนา (นี่คือภาษาที่สามของฉัน) ฉันตรวจสอบการพิมพ์ในขณะที่รวบรวม แต่ฉันไม่ได้ใช้ประโยชน์จากสิ่งนั้นอย่างเต็มที่ การประเมินนิพจน์ยังคงขึ้นอยู่กับข้อมูลประเภทรันไทม์
ตอนนี้ ฉันตัดสินใจพัฒนาภาษาที่พิมพ์แบบสแตติก และกลายเป็นงานที่ยากกว่าที่คาดไว้มาก อย่างไรก็ตาม เนื่องจากฉันไม่ได้วางแผนที่จะคอมไพล์เป็นไบนารี หรือรหัสแอสเซมบลีที่จำลองขึ้นใดๆ ข้อมูลบางประเภทจึงจะมีอยู่ในโค้ดที่คอมไพล์แล้วโดยปริยาย
ประเภท
สำหรับประเภทขั้นต่ำที่เราต้องรองรับ เราจะเริ่มต้นด้วยสิ่งต่อไปนี้:
- ตัวเลข
- เครื่องสาย
- ฟังก์ชั่น
- อาร์เรย์
แม้ว่าเราอาจเพิ่มมันเข้าไปในอนาคต แต่เราจะไม่รองรับโครงสร้าง (หรือคลาส เรคคอร์ด ทูเพิล ฯลฯ) ในตอนเริ่มต้น อย่างไรก็ตาม เราจะจำไว้ว่าเราอาจเพิ่มพวกเขาในภายหลัง ดังนั้นเราจะไม่ประทับตราชะตากรรมของเราด้วยการตัดสินใจที่ยากต่อการเปลี่ยนแปลง
อันดับแรก ฉันต้องการกำหนดประเภทเป็นสตริง ซึ่งจะเป็นไปตามหลักการบางอย่าง ตัวระบุทุกตัวจะเก็บสตริงนั้นตามค่าในขณะที่คอมไพล์ และบางครั้งเราจะต้องแยกวิเคราะห์ ตัวอย่างเช่น หากเราเข้ารหัสประเภทของอาร์เรย์ของตัวเลขเป็น "[number]" เราจะต้องตัดอักขระตัวแรกและตัวสุดท้ายเพื่อให้ได้ประเภทภายใน ซึ่งในกรณีนี้คือ "number" มันเป็นความคิดที่แย่มากถ้าคุณคิดเกี่ยวกับมัน
จากนั้นฉันก็ลองนำไปใช้เป็นคลาส ชั้นเรียนนั้นจะมีข้อมูลทั้งหมดเกี่ยวกับประเภทนั้น ตัวระบุแต่ละตัวจะเก็บตัวชี้ที่ใช้ร่วมกันไปยังคลาสนั้น ในท้ายที่สุด ฉันคิดว่าจะมีรีจิสทรีทุกประเภทที่ใช้ในระหว่างการคอมไพล์ ดังนั้นตัวระบุแต่ละตัวจะมีตัวชี้แบบดิบเป็นประเภทของมัน
ฉันชอบความคิดนั้น ดังนั้นเราจึงลงเอยด้วยสิ่งต่อไปนี้:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;ประเภทง่าย ๆ เป็นสมาชิกของ enum:
enum struct simple_type { nothing, number, string, }; สมาชิกการแจงนับ nothing อยู่ที่นี่ในฐานะตัวแทนสำหรับ void ซึ่งฉันไม่สามารถใช้ได้เนื่องจากเป็นคำหลักใน C ++
ประเภทอาร์เรย์จะแสดงด้วยโครงสร้างที่มีสมาชิกเพียงคนเดียวของ type_handle
struct array_type { type_handle inner_type_id; }; เห็นได้ชัดว่าความยาวอาร์เรย์ไม่ได้เป็นส่วนหนึ่งของ array_type ดังนั้นอาร์เรย์จะเติบโตแบบไดนามิก นั่นหมายความว่าเราจะลงเอยด้วย std::deque หรือสิ่งที่คล้ายกัน แต่เราจะจัดการกับมันในภายหลัง
ประเภทฟังก์ชันประกอบด้วยประเภทการส่งคืน ประเภทของพารามิเตอร์แต่ละตัว และไม่ว่าพารามิเตอร์เหล่านั้นจะถูกส่งผ่านด้วยค่าหรือโดยการอ้างอิงหรือไม่
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };ตอนนี้ เราสามารถกำหนดคลาสที่จะเก็บประเภทเหล่านั้นไว้
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; ประเภทจะถูกเก็บไว้ใน std::set เนื่องจากคอนเทนเนอร์นั้นมีความเสถียร ซึ่งหมายความว่าพอยน์เตอร์ที่ชี้ไปยังสมาชิกนั้นใช้ได้แม้หลังจากใส่ประเภทใหม่แล้ว มีฟังก์ชัน get_handle ซึ่งลงทะเบียนประเภทที่ส่งผ่านและส่งคืนตัวชี้ไปที่มัน หากลงทะเบียนประเภทแล้ว ตัวชี้จะคืนตัวชี้เป็นประเภทที่มีอยู่ นอกจากนี้ยังมีฟังก์ชันอำนวยความสะดวกในการรับประเภทดั้งเดิม
สำหรับการแปลงโดยนัยระหว่างประเภท ตัวเลขจะเปลี่ยนเป็นสตริงได้ ไม่ควรเป็นอันตราย เนื่องจากไม่สามารถแปลงย้อนกลับได้ และตัวดำเนินการสำหรับการต่อสายอักขระจะมีลักษณะเฉพาะสำหรับการเพิ่มจำนวน แม้ว่าการเปลี่ยนใจเลื่อมใสนั้นจะถูกลบออกในระยะหลังของการพัฒนาภาษานี้ มันจะเป็นแบบฝึกหัดที่ดี ณ จุดนี้ เพื่อจุดประสงค์นั้น ฉันต้องแก้ไข number parser เนื่องจากมัน parsed . เป็นจุดทศนิยม อาจเป็นอักขระตัวแรกของตัวดำเนินการเรียงต่อกัน .. .
บริบทของคอมไพเลอร์
ในระหว่างการคอมไพล์ ฟังก์ชันคอมไพเลอร์ที่แตกต่างกันจำเป็นต้องได้รับข้อมูลเกี่ยวกับโค้ดที่คอมไพล์แล้ว เราจะเก็บข้อมูลนั้นไว้ในคลาส compiler_context เนื่องจากเรากำลังจะใช้การแยกวิเคราะห์นิพจน์ เราจะต้องดึงข้อมูลเกี่ยวกับตัวระบุที่เราพบ
ระหว่างรันไทม์ เราจะเก็บตัวแปรไว้ในคอนเทนเนอร์สองคอนเทนเนอร์ที่ต่างกัน หนึ่งในนั้นจะเป็นคอนเทนเนอร์ตัวแปรโกลบอล และอีกอันจะเป็นสแต็ก สแต็กจะเพิ่มขึ้นเมื่อเราเรียกใช้ฟังก์ชันและเข้าสู่ขอบเขต มันจะหดตัวเมื่อเรากลับจากฟังก์ชันและออกจากขอบเขต เมื่อเราเรียกใช้ฟังก์ชันบางอย่าง เราจะกดพารามิเตอร์ของฟังก์ชัน จากนั้นฟังก์ชันจะทำงาน ค่าที่ส่งคืนจะถูกผลักไปที่ด้านบนของสแต็กเมื่อออก ดังนั้น สำหรับแต่ละฟังก์ชัน สแต็กจะมีลักษณะดังนี้:
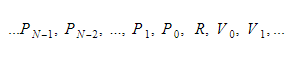
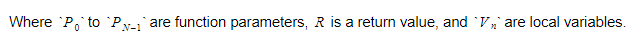
ฟังก์ชันจะเก็บดัชนีสัมบูรณ์ของตัวแปรส่งคืน และแต่ละตัวแปรหรือพารามิเตอร์จะสัมพันธ์กับดัชนีนั้น
สำหรับตอนนี้ เราจะถือว่าฟังก์ชันเป็นตัวระบุส่วนกลางคงที่
นี่คือคลาสที่ทำหน้าที่เป็นข้อมูลตัวระบุ:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; สำหรับตัวแปรภายในเครื่องและพารามิเตอร์ของฟังก์ชัน index ฟังก์ชันจะส่งกลับดัชนีที่สัมพันธ์กับค่าที่ส่งกลับ ส่งคืนดัชนีโกลบอลแบบสัมบูรณ์ในกรณีของตัวระบุส่วนกลาง
เราจะมีการค้นหาตัวระบุที่แตกต่างกันสามแบบใน compile_context :
- การค้นหาตัวระบุส่วนกลาง ซึ่งจะ
compile_contextยึดตามค่า เนื่องจากจะเหมือนกันตลอดการคอมไพล์ทั้งหมด - การค้นหาตัวระบุท้องถิ่นเป็น
unique_ptrซึ่งจะเป็นnullptrในขอบเขตส่วนกลางและจะเริ่มต้นในฟังก์ชันใดก็ได้ เมื่อใดก็ตามที่เราเข้าสู่ขอบเขต บริบทในเครื่องใหม่จะถูกเริ่มต้นโดยบริบทเก่าเป็นพาเรนต์ เมื่อเราออกจากขอบเขต ขอบเขตนั้นจะถูกแทนที่ด้วยระดับบนสุด - การค้นหาตัวระบุฟังก์ชัน ซึ่งจะเป็นตัวชี้แบบดิบ มันจะเป็น
nullptrในขอบเขตสากล และค่าเดียวกับขอบเขตภายในสุดในฟังก์ชันใดๆ
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };ต้นไม้นิพจน์
เมื่อโทเค็นนิพจน์ถูกแยกวิเคราะห์ โทเค็นจะถูกแปลงเป็นทรีนิพจน์ คล้ายกับต้นไม้ทั้งหมด ต้นไม้นี้ประกอบด้วยโหนดด้วย

โหนดมีสองประเภทที่แตกต่างกัน:
- โหนดใบซึ่งสามารถ:
ก) ตัวระบุ
b) ตัวเลข
c) เครื่องสาย - โหนดภายใน ซึ่งแสดงถึงการดำเนินการบนโหนดย่อย มันทำให้ลูก ๆ ของตนมี
unique_ptr
สำหรับแต่ละโหนด จะมีข้อมูลเกี่ยวกับประเภทของโหนด และจะส่งคืนค่า lvalue หรือไม่ (ค่าที่สามารถปรากฏทางด้านซ้ายของตัวดำเนินการ = )
เมื่อมีการสร้างโหนดภายใน โหนดจะพยายามแปลงประเภทการส่งคืนของโหนดย่อยเป็นประเภทที่คาดหวัง อนุญาตให้ทำการแปลงโดยนัยต่อไปนี้:
- lvalue เป็น non-lvalue
- อะไรก็ตามที่
void -
numberต่อstring
หากไม่อนุญาตให้แปลง จะเกิดข้อผิดพลาดทางความหมาย
นี่คือคำจำกัดความของคลาส โดยไม่มีฟังก์ชันตัวช่วยและรายละเอียดการใช้งาน:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; ฟังก์ชันการทำงานของเมธอดสามารถอธิบายได้ด้วยตนเอง ยกเว้นฟังก์ชัน check_conversion มันจะตรวจสอบว่าประเภทนั้นแปลงเป็น type_id และ boolean lvalue ที่ส่งผ่านได้หรือไม่โดยปฏิบัติตามกฎการแปลงประเภทและจะส่งข้อยกเว้นหากไม่ใช่
หากโหนดเริ่มต้นด้วย std::string หรือ double ประเภทของโหนดจะเป็น string หรือ number ตามลำดับ และจะไม่ใช่ lvalue หากเริ่มต้นด้วยตัวระบุ จะถือว่าประเภทของตัวระบุนั้นและจะเป็น lvalue หากตัวระบุไม่คงที่
อย่างไรก็ตาม หากเริ่มต้นด้วยการทำงานของโหนด ประเภทของโหนดจะขึ้นอยู่กับการดำเนินการ และบางครั้งขึ้นอยู่กับประเภทของโหนดย่อย มาเขียนประเภทนิพจน์ในตารางกัน ฉันจะใช้ & ต่อท้ายเพื่อแสดงค่า lvalue ในกรณีที่นิพจน์หลายนิพจน์มีการปฏิบัติเหมือนกัน ฉันจะเขียนนิพจน์เพิ่มเติมในวงเล็บกลม
Unary Operations
| การดำเนินการ | ประเภทการดำเนินงาน | ประเภท x |
| ++x (--x) | ตัวเลข& | ตัวเลข& |
| x++ (x--) | ตัวเลข | ตัวเลข& |
| +x (-x ~x !x) | ตัวเลข | ตัวเลข |
ปฏิบัติการไบนารี
| การดำเนินการ | ประเภทการดำเนินงาน | ประเภท x | y ประเภท |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | ตัวเลข | ตัวเลข | ตัวเลข |
| x==y (x!=y x<y x>y x<=y x>=y) | ตัวเลข | ตัวเลขหรือสตริง | เช่นเดียวกับ x |
| x..y | สตริง | สตริง | สตริง |
| x=y | เช่นเดียวกับ x | คุณค่าของทุกสิ่ง | เหมือนกับ x โดยไม่มีค่า lvalue |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | ตัวเลข& | ตัวเลข& | ตัวเลข |
| x..=y | สตริง& | สตริง& | สตริง |
| x,y | เช่นเดียวกับ y | โมฆะ | อะไรก็ตาม |
| x[y] | ประเภทองค์ประกอบของ x | ประเภทอาร์เรย์ | ตัวเลข |
Ternary Operations
| การดำเนินการ | ประเภทการดำเนินงาน | ประเภท x | y ประเภท | z type |
| x?y:z | เช่นเดียวกับ y | ตัวเลข | อะไรก็ตาม | เช่นเดียวกับ y |
เรียกฟังก์ชัน
เมื่อพูดถึงการเรียกใช้ฟังก์ชัน สิ่งต่างๆ จะซับซ้อนขึ้นเล็กน้อย หากฟังก์ชันมีอาร์กิวเมนต์ N การเรียกใช้ฟังก์ชันจะมี N+1 ลูก โดยที่ชายด์คนแรกคือฟังก์ชัน และส่วนที่เหลือของเด็กจะสอดคล้องกับอาร์กิวเมนต์ของฟังก์ชัน
อย่างไรก็ตาม เราจะไม่อนุญาตให้มีการส่งต่ออาร์กิวเมนต์โดยนัยโดยการอ้างอิง เราจะกำหนดให้ผู้โทรนำหน้าด้วยเครื่องหมาย & สำหรับตอนนี้ นั่นจะไม่ใช่โอเปอเรเตอร์เพิ่มเติม แต่วิธีแยกวิเคราะห์การเรียกใช้ฟังก์ชัน หากเราไม่แยกวิเคราะห์เครื่องหมายและ เมื่อคาดว่าจะมีอาร์กิวเมนต์ เราจะลบ lvalue-ness ออกจากอาร์กิวเมนต์นั้นโดยเพิ่มการดำเนินการ unary ปลอมที่เราเรียกว่า node_operation::param การดำเนินการนั้นมีประเภทเดียวกับการดำเนินการย่อย แต่ไม่ใช่ค่า lvalue
จากนั้น เมื่อเราสร้างโหนดด้วยการดำเนินการเรียกนั้น หากเรามีอาร์กิวเมนต์ที่เป็น lvalue แต่ฟังก์ชันไม่คาดหวัง เราจะสร้างข้อผิดพลาด เนื่องจากหมายความว่าผู้โทรพิมพ์เครื่องหมายและโดยไม่ได้ตั้งใจ ค่อนข้างน่าประหลาดใจที่ & หากถือเป็นโอเปอเรเตอร์ จะมีความสำคัญน้อยที่สุด เนื่องจากไม่มีความหมายเชิงความหมายหากแยกวิเคราะห์ภายในนิพจน์ เราอาจเปลี่ยนแปลงได้ในภายหลัง
Parser นิพจน์
หนึ่งในข้อกล่าวอ้างของเขาเกี่ยวกับศักยภาพของโปรแกรมเมอร์ Edsger Dijkstra นักปรัชญาวิทยาการคอมพิวเตอร์ชื่อดังเคยกล่าวไว้ว่า:
“แทบจะเป็นไปไม่ได้เลยที่จะสอนการเขียนโปรแกรมที่ดีให้กับนักเรียนที่เคยเรียนขั้นพื้นฐานมาก่อน ในฐานะที่เป็นโปรแกรมเมอร์ที่มีศักยภาพ พวกเขาจะถูกทำร้ายจิตใจเกินกว่าจะฟื้นฟูได้”
ดังนั้น สำหรับพวกคุณทุกคนที่ไม่เคยสัมผัสกับเบสิก - จงขอบคุณเมื่อคุณรอดพ้นจาก "การทำร้ายจิตใจ"
พวกเราที่เหลือ ซึ่งเป็นโปรแกรมเมอร์ผู้พิการ ขอให้เราเตือนตัวเองถึงวันที่เราเขียนโค้ดในขั้นพื้นฐาน มีโอเปอเรเตอร์ \ ซึ่งใช้สำหรับการแบ่งอินทิกรัล ในภาษาที่คุณไม่มีประเภทแยกกันสำหรับจำนวนอินทิกรัลและจำนวนทศนิยม มันสะดวกมาก ดังนั้นฉันจึงเพิ่มโอเปอเรเตอร์เดียวกันใน Stork ฉันยังเพิ่มโอเปอเรเตอร์ \= ซึ่งตามที่คุณเดาจะทำการแบ่งอินทิกรัลแล้วมอบหมาย
ฉันคิดว่าตัวดำเนินการดังกล่าวจะได้รับการชื่นชมจากโปรแกรมเมอร์ JavaScript ฉันไม่ต้องการที่จะจินตนาการว่า Dijkstra จะพูดอะไรเกี่ยวกับพวกเขา ถ้าเขามีชีวิตอยู่นานพอที่จะเห็นความนิยมที่เพิ่มขึ้นของ JS
เมื่อพูดถึงปัญหาที่ใหญ่ที่สุดอย่างหนึ่งที่ฉันมีกับ JavaScript คือความคลาดเคลื่อนของนิพจน์ต่อไปนี้:
-
"1" - “1”ประเมินเป็น0 -
"1" * “1”มีค่าเป็น1 -
"1" / “1”มีค่าเป็น1 -
"1" + “1”ประเมินเป็น“11”
ดูโอฮิปฮอปชาวโครเอเชีย “Tram 11” ซึ่งตั้งชื่อตามรถรางที่เชื่อมเขตเมืองรอบนอกของซาเกร็บ มีเพลงที่แปลคร่าวๆ ว่า “หนึ่งกับหนึ่งไม่ใช่สอง แต่ 11” มันออกมาในช่วงปลายยุค 90 ดังนั้นจึงไม่ได้อ้างอิงถึง JavaScript แต่แสดงให้เห็นถึงความคลาดเคลื่อนได้ค่อนข้างดี
เพื่อหลีกเลี่ยงความคลาดเคลื่อนเหล่านั้น ฉันห้ามการแปลงโดยนัยจากสตริงเป็นตัวเลข และฉันเพิ่มตัวดำเนินการ .. สำหรับการต่อข้อมูล (และ ..= สำหรับการต่อกับการกำหนด) ฉันจำไม่ได้ว่าฉันได้ไอเดียสำหรับโอเปอเรเตอร์นั้นมาจากไหน มันไม่ได้มาจาก BASIC หรือ PHP และฉันจะไม่ค้นหาวลี "Python concatenation" เพราะ googling อะไรเกี่ยวกับ Python ทำให้ฉันหนาวสั่น ฉันเป็นโรคกลัวงู และรวมเข้ากับ "การเรียงต่อกัน" - ไม่ ขอบคุณ! อาจจะในภายหลังด้วยเบราว์เซอร์ที่ใช้ข้อความแบบโบราณบางตัวที่ไม่มี ASCII art
แต่กลับไปที่หัวข้อของส่วนนี้ - parser นิพจน์ของเรา เราจะใช้การดัดแปลงของ “Shunting-yard Algorithm”
นั่นคืออัลกอริธึมที่อยู่ในใจของโปรแกรมเมอร์ทั่วไปแม้กระทั่งหลังจากคิดเกี่ยวกับปัญหาเป็นเวลา 10 นาทีหรือมากกว่านั้น สามารถใช้เพื่อประเมินนิพจน์ infix หรือแปลงเป็นสัญกรณ์โปแลนด์ย้อนกลับ ซึ่งเราจะไม่ทำ
แนวคิดของอัลกอริทึมคือการอ่านตัวถูกดำเนินการและตัวดำเนินการจากซ้ายไปขวา เมื่อเราอ่านตัวถูกดำเนินการ เราพุชไปที่ตัวถูกดำเนินการ เมื่อเราอ่านโอเปอเรเตอร์ เราไม่สามารถประเมินได้ทันที เนื่องจากเราไม่รู้ว่าโอเปอเรเตอร์ต่อไปนี้จะมีลำดับความสำคัญดีกว่าตัวนั้นหรือไม่ ดังนั้นเราจึงผลักมันไปที่โอเปอเรเตอร์สแต็ก
อย่างไรก็ตาม ก่อนอื่นเราจะตรวจสอบว่าตัวดำเนินการที่ด้านบนสุดของสแต็กมีความสำคัญมากกว่าตัวที่เราเพิ่งอ่านหรือไม่ ในกรณีนั้น เราประเมินโอเปอเรเตอร์จากด้านบนของสแต็กด้วยตัวถูกดำเนินการบนสแต็กตัวถูกดำเนินการ เราผลักผลลัพธ์ไปที่ตัวถูกดำเนินการ เราเก็บไว้จนกว่าเราจะอ่านทุกอย่างแล้วประเมินโอเปอเรเตอร์ทั้งหมดทางด้านซ้ายของโอเปอเรเตอร์สแต็กด้วยโอเปอเรเตอร์บนสแต็กตัวถูกดำเนินการ ผลักผลลัพธ์กลับไปที่สแต็กตัวถูกดำเนินการ จนกว่าเราจะไม่มีโอเปอเรเตอร์ใดๆ และมีตัวถูกดำเนินการเพียงตัวเดียว ซึ่งก็คือ ผลลัพธ์.
เมื่อตัวดำเนินการสองตัวมีลำดับความสำคัญเท่ากัน เราจะเลือกตัวดำเนินการทางซ้ายในกรณีที่ตัวดำเนินการเหล่านั้นสัมพันธ์กันทางซ้าย มิฉะนั้นเราจะใช้อันที่ถูกต้อง โอเปอเรเตอร์สองตัวที่มีลำดับความสำคัญเท่ากันไม่สามารถมีการเชื่อมโยงที่แตกต่างกันได้
อัลกอริธึมดั้งเดิมยังใช้กับวงเล็บเหลี่ยม แต่เราจะทำแบบเรียกซ้ำแทน เนื่องจากอัลกอริธึมจะสะอาดกว่านี้
Edsger Dijkstra ตั้งชื่ออัลกอริทึมนี้ว่า "Shunting-yard" เพราะมันคล้ายกับการทำงานของลานแบ่งทางรถไฟ
อย่างไรก็ตาม อัลกอริธึม shunting-yard ดั้งเดิมแทบไม่มีการตรวจสอบข้อผิดพลาด ดังนั้นจึงค่อนข้างเป็นไปได้ที่นิพจน์ที่ไม่ถูกต้องจะถูกแยกวิเคราะห์ว่าเป็นนิพจน์ที่ถูกต้อง ดังนั้นฉันจึงเพิ่มตัวแปรบูลีนซึ่งตรวจสอบว่าเราคาดหวังโอเปอเรเตอร์หรือตัวถูกดำเนินการหรือไม่ ถ้าเราคาดหวังตัวถูกดำเนินการ เราสามารถแยกวิเคราะห์ตัวดำเนินการ unary prefix ได้เช่นกัน ด้วยวิธีนี้ นิพจน์ที่ไม่ถูกต้องจะไม่สามารถผ่านเข้าไปได้ และการตรวจสอบไวยากรณ์ของนิพจน์จะเสร็จสมบูรณ์
ห่อ
เมื่อฉันเริ่มเขียนโค้ดสำหรับส่วนนี้ของซีรีส์นี้ ฉันวางแผนที่จะเขียนเกี่ยวกับตัวสร้างนิพจน์ ฉันต้องการสร้างนิพจน์ที่สามารถประเมินได้ อย่างไรก็ตาม มันกลับกลายเป็นว่าซับซ้อนเกินไปสำหรับโพสต์บล็อกเดียว ดังนั้นฉันจึงตัดสินใจแบ่งครึ่ง ในส่วนนี้ เราได้สรุปการแยกวิเคราะห์นิพจน์ และผมจะเขียนเกี่ยวกับการสร้างวัตถุนิพจน์ในบทความถัดไป
ถ้าฉันจำไม่ผิด เมื่อประมาณ 15 ปีที่แล้ว ฉันต้องใช้เวลาหนึ่งสัปดาห์ในการเขียนเวอร์ชันแรกของภาษาแรก ซึ่งทำให้ฉันสงสัยว่าครั้งนี้เกิดอะไรขึ้น
ในความพยายามที่จะปฏิเสธว่าฉันอายุมากขึ้นและมีไหวพริบน้อยลง ฉันจะตำหนิลูกชายวัย 2 ขวบของฉันที่มีความต้องการมากเกินไปในเวลาว่าง
เช่นเดียวกับในตอนที่ 1 คุณสามารถอ่าน ดาวน์โหลด หรือแม้แต่คอมไพล์โค้ดจากหน้า GitHub ของฉันได้