
Stork, Parte 2: Criando um analisador de expressão
Publicados: 2022-03-11Nesta parte de nossa série, abordaremos um dos componentes mais complicados (pelo menos na minha opinião) de criar scripts em um mecanismo de linguagem, que é um bloco de construção essencial para todas as linguagens de programação: o analisador de expressões.
Uma pergunta que um leitor poderia fazer – e com razão – é: por que simplesmente não usamos algumas ferramentas ou bibliotecas sofisticadas, algo já à nossa disposição?
Por que não usamos Lex, YACC, Bison, Boost Spirit ou pelo menos expressões regulares?
Ao longo de nosso relacionamento, minha esposa notou um traço meu que não posso negar: sempre que me deparo com uma pergunta difícil, faço uma lista. Se você pensar sobre isso, faz todo o sentido - estou usando a quantidade para compensar a falta de qualidade na minha resposta.
Vou fazer a mesma coisa agora.
- Eu quero usar C++ padrão. Nesse caso, será C++17. Acho que a linguagem é bastante rica por si só, e estou lutando contra o desejo de adicionar qualquer coisa, menos a biblioteca padrão à mistura.
- Quando desenvolvi minha primeira linguagem de script, não usei nenhuma ferramenta sofisticada. Eu estava sob pressão e com um prazo apertado, mas não sabia como usar Lex, YACC ou algo semelhante. Por isso, decidi desenvolver tudo manualmente.
- Mais tarde, encontrei um blog de um desenvolvedor de linguagem de programação experiente, que desaconselhou o uso de qualquer uma dessas ferramentas. Ele disse que essas ferramentas resolvem a parte mais fácil do desenvolvimento da linguagem, então, em qualquer caso, você fica com as coisas difíceis. Não consigo encontrar esse blog agora, como foi há muito tempo, quando a internet e eu éramos jovens.
- Ao mesmo tempo, havia um meme que dizia: “Você tem um problema que decide resolver usando expressões regulares. Agora você tem dois problemas.”
- Eu não conheço Lex, YACC, Bison ou algo parecido. Conheço o Boost Spirit, e é uma biblioteca útil e incrível, mas ainda prefiro ter um melhor controle sobre o analisador.
- Eu gosto de fazer esses componentes manualmente. Na verdade, eu poderia apenas dar esta resposta e remover esta lista completamente.
O código completo está disponível na minha página do GitHub.
Iterador de token
Existem algumas alterações no código da Parte 1.
Essas são principalmente correções simples e pequenas alterações, mas uma adição importante ao código de análise existente é a classe token_iterator . Ele nos permite avaliar o token atual sem removê-lo do fluxo, o que é muito útil.
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; Ele é inicializado com push_back_stream e, em seguida, pode ser desreferenciado e incrementado. Ele pode ser verificado com um bool cast explícito, que será avaliado como false quando o token atual for igual a eof.
Linguagem tipada estaticamente ou dinamicamente?
Há uma decisão que preciso tomar nesta parte: essa linguagem será digitada estaticamente ou dinamicamente?
Uma linguagem tipada estaticamente é uma linguagem que verifica os tipos de suas variáveis no momento da compilação.
Uma linguagem tipada dinamicamente , por outro lado, não a verifica durante a compilação (se houver uma compilação, o que não é obrigatório para uma linguagem tipada dinamicamente), mas durante a execução. Portanto, erros potenciais podem permanecer no código até serem atingidos.
Esta é uma vantagem óbvia de linguagens de tipagem estática. Todo mundo gosta de pegar seus erros o mais rápido possível. Sempre me perguntei qual é a maior vantagem das linguagens tipadas dinamicamente, e a resposta me surpreendeu nas últimas semanas: É muito mais fácil desenvolver!
A linguagem anterior que desenvolvi era tipada dinamicamente. Fiquei mais ou menos satisfeito com o resultado, e escrever o analisador de expressão não foi muito difícil. Você basicamente não precisa verificar os tipos de variáveis e depende de erros de tempo de execução, que você codifica quase espontaneamente.
Por exemplo, se você tiver que escrever o operador binário + e quiser fazê-lo para números, basta avaliar ambos os lados desse operador como números no tempo de execução. Se um dos lados não puder avaliar o número, você simplesmente lança uma exceção. Até implementei a sobrecarga de operadores verificando as informações de tipo de tempo de execução das variáveis em uma expressão, e os operadores faziam parte dessas informações de tempo de execução.
Na primeira linguagem que desenvolvi (essa é a minha terceira), fiz a verificação de tipos na hora da compilação, mas não tirei o máximo proveito disso. A avaliação da expressão ainda dependia das informações do tipo de tempo de execução.
Agora, decidi desenvolver uma linguagem estaticamente tipada, e acabou sendo uma tarefa muito mais difícil do que o esperado. No entanto, como não pretendo compilá-lo em um binário ou em qualquer tipo de código assembly emulado, algum tipo de informação existirá implicitamente no código compilado.
Tipos
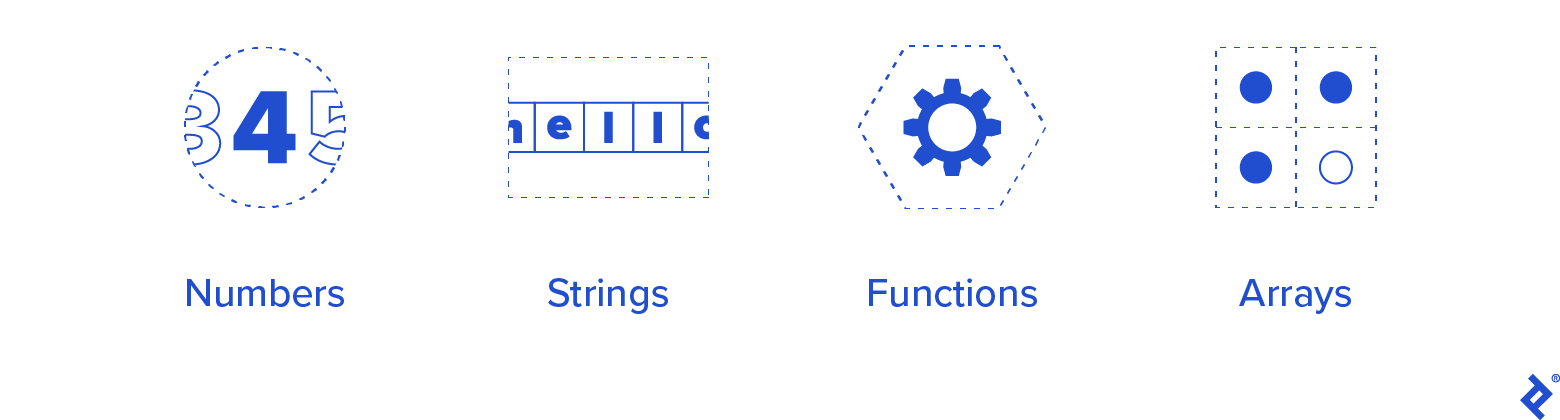
Como um mínimo de tipos que temos que suportar, começaremos com o seguinte:
- Números
- Cordas
- Funções
- Matrizes
Embora possamos adicioná-los daqui para frente, não suportaremos estruturas (ou classes, registros, tuplas, etc.) no início. No entanto, teremos em mente que podemos adicioná-los mais tarde, para não selar nosso destino com decisões difíceis de mudar.
Primeiro, eu queria definir o tipo como uma string, que seguirá alguma convenção. Cada identificador manteria essa string por valor no momento da compilação, e às vezes teremos que analisá-la. Por exemplo, se codificarmos o tipo de array de números como “[number]”, teremos que cortar o primeiro e o último caractere para obter um tipo interno, que é “number” neste caso. É uma ideia muito ruim se você pensar sobre isso.
Então, tentei implementá-lo como uma classe. Essa classe teria todas as informações sobre o tipo. Cada identificador manteria um ponteiro compartilhado para essa classe. No final, pensei em ter o registro de todos os tipos usados durante a compilação, assim cada identificador teria o ponteiro bruto para o seu tipo.
Eu gostei dessa ideia, então acabamos com o seguinte:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;Tipos simples são membros do enum:
enum struct simple_type { nothing, number, string, }; O membro de enumeração nothing está aqui como um espaço reservado para void , que não posso usar, pois é uma palavra-chave em C++.
Os tipos de matriz são representados com a estrutura tendo o único membro de type_handle .
struct array_type { type_handle inner_type_id; }; Obviamente, o tamanho do array não faz parte do array_type , então os arrays crescerão dinamicamente. Isso significa que terminaremos com std::deque ou algo semelhante, mas lidaremos com isso mais tarde.
Um tipo de função é composto de seu tipo de retorno, tipo de cada um de seus parâmetros e se cada um desses parâmetros é ou não passado por valor ou por referência.
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };Agora, podemos definir a classe que manterá esses tipos.
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; Os tipos são mantidos em std::set , pois esse contêiner é estável, o que significa que os ponteiros para seus membros são válidos mesmo após a inserção de novos tipos. Existe a função get_handle , que registra o tipo passado e retorna o ponteiro para ele. Se o tipo já estiver registrado, ele retornará o ponteiro para o tipo existente. Existem também funções de conveniência para obter tipos primitivos.
Quanto à conversão implícita entre tipos, os números serão conversíveis em strings. Não deve ser perigoso, pois uma conversão reversa não é possível, e o operador para concatenação de strings é distinto daquele para adição de números. Mesmo que essa conversão seja removida nos estágios posteriores do desenvolvimento dessa linguagem, ela servirá bem como um exercício neste momento. Para isso, tive que modificar o analisador de números, pois ele sempre analisava . como ponto decimal. Pode ser o primeiro caractere do operador de concatenação .. .
Contexto do compilador
Durante a compilação, diferentes funções do compilador precisam obter informações sobre o código compilado até o momento. Manteremos essas informações em uma classe compiler_context . Como estamos prestes a implementar a análise de expressão, precisaremos recuperar informações sobre os identificadores que encontrarmos.
Durante o tempo de execução, manteremos as variáveis em dois contêineres diferentes. Um deles será o contêiner da variável global e outro será a pilha. A pilha crescerá à medida que chamamos funções e inserimos escopos. Ele encolherá à medida que retornarmos das funções e deixarmos os escopos. Quando chamamos alguma função, enviamos os parâmetros da função e, em seguida, a função será executada. Seu valor de retorno será empurrado para o topo da pilha quando sair. Portanto, para cada função, a pilha ficará assim:
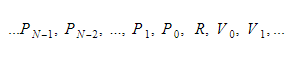
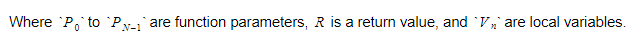
A função manterá o índice absoluto da variável de retorno e cada variável ou parâmetro será encontrado em relação a esse índice.
Por enquanto, trataremos as funções como identificadores globais constantes.
Esta é a classe que serve como informação identificadora:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; Para variáveis locais e parâmetros de função, o index da função retorna o índice relativo ao valor de retorno. Retorna o índice global absoluto no caso de identificadores globais.
Teremos três pesquisas de identificadores diferentes em compile_context :
- Pesquisa de identificador global, que irá
compile_contextmanter por valor, pois é o mesmo em toda a compilação. - Pesquisa de identificador local, como um
unique_ptr, que seránullptrno escopo global e será inicializado em qualquer função. Sempre que entrarmos no escopo, o novo contexto local será inicializado com o antigo como pai. Quando sairmos do escopo, ele será substituído por seu pai. - Pesquisa de identificador de função, que será o ponteiro bruto. Será
nullptrno escopo global e o mesmo valor que o escopo local mais externo em qualquer função.
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };Árvore de Expressão
Quando os tokens de expressão são analisados, eles são convertidos em uma árvore de expressão. Semelhante a todas as árvores, esta também consiste em nós.

Existem dois tipos diferentes de nós:
- Nós folha, que podem ser:
a) Identificadores
b) Números
c) Cordas - Nós internos, que representam uma operação em seus nós filhos. Ele mantém seus filhos com
unique_ptr.
Para cada nó, há informações sobre seu tipo e se ele retorna ou não um lvalue (um valor que pode aparecer no lado esquerdo do operador = ).
Quando um nó interno é criado, ele tentará converter os tipos de retorno de seus filhos em tipos esperados. As seguintes conversões implícitas são permitidas:
- lvalor para não-lvalor
- Qualquer coisa para
void -
numberparastring
Se a conversão não for permitida, um erro semântico será lançado.
Aqui está a definição da classe, sem algumas funções auxiliares e detalhes de implementação:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; A funcionalidade dos métodos é autoexplicativa, exceto pela função check_conversion . Ele verificará se o tipo é conversível para o type_id e boolean lvalue passados obedecendo às regras de conversão de tipo e lançará uma exceção se não for.
Se um nó for inicializado com std::string , ou double , seu tipo será string ou number , respectivamente, e não será um lvalue. Se for inicializado com um identificador, assumirá o tipo desse identificador e será um lvalue se o identificador não for constante.
Se for inicializado, no entanto, com uma operação de nó, seu tipo dependerá da operação e, às vezes, do tipo de seus filhos. Vamos escrever os tipos de expressão na tabela. Vou usar & sufixo para denotar um lvalue. Nos casos em que várias expressões têm o mesmo tratamento, escreverei expressões adicionais entre colchetes.
Operações Unárias
| Operação | Tipo de operação | x tipo |
| ++x (--x) | número& | número& |
| x++ (x--) | número | número& |
| +x (-x ~x !x) | número | número |
Operações Binárias
| Operação | Tipo de operação | x tipo | tipo y |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | número | número | número |
| x==y (x!=y x<y x>y x<=y x>=y) | número | número ou string | igual a x |
| x..y | corda | corda | corda |
| x=y | igual a x | lvalor de qualquer coisa | igual a x, sem lvalue |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | número& | número& | número |
| x..=y | corda& | corda& | corda |
| x,y | igual a você | vazio | nada |
| x[y] | tipo de elemento de x | tipo de matriz | número |
Operações ternárias
| Operação | Tipo de operação | x tipo | tipo y | tipo z |
| x?y:z | igual a você | número | nada | igual a você |
Chamada de Função
Quando se trata da chamada de função, as coisas ficam um pouco mais complicadas. Se a função tiver N argumentos, a operação de chamada de função terá N+1 filhos, onde o primeiro filho é a própria função e o restante dos filhos corresponde aos argumentos da função.
No entanto, não permitiremos a passagem de argumentos implicitamente por referência. Exigiremos que o chamador o prefixe com o sinal & . Por enquanto, isso não será um operador adicional, mas a forma como a chamada de função é analisada. Se não analisarmos o e comercial, quando o argumento for esperado, removeremos o lvalue-ness desse argumento adicionando uma operação unária falsa que chamamos de node_operation::param . Essa operação tem o mesmo tipo que seu filho, mas não é um lvalue.
Então, quando construirmos o nó com essa operação de chamada, se tivermos um argumento que é lvalue mas não é esperado pela função, geraremos um erro, pois significa que o chamador digitou o e comercial acidentalmente. Surpreendentemente, que & , se tratado como um operador, teria a menor precedência, pois não tem o significado semanticamente se analisado dentro da expressão. Podemos alterá-lo mais tarde.
Analisador de expressão
Em uma de suas afirmações sobre o potencial dos programadores, o famoso filósofo da ciência da computação Edsger Dijkstra disse uma vez:
“É praticamente impossível ensinar boa programação para alunos que tiveram uma exposição prévia ao BASIC. Como programadores em potencial, eles estão mentalmente mutilados além da esperança de regeneração.”
Então, para todos vocês que não foram expostos ao BASIC - sejam gratos, pois escaparam da “mutilação mental”.
O resto de nós, programadores mutilados, vamos nos lembrar dos dias em que codificávamos em BASIC. Havia um operador \ , que era usado para divisão integral. Em uma linguagem em que você não tem tipos separados para números inteiros e de ponto flutuante, isso é bastante útil, então adicionei o mesmo operador ao Stork. Também adicionei o operador \= , que, como você adivinhou, executará a divisão integral e depois atribuirá.
Acho que esses operadores seriam apreciados por programadores JavaScript, por exemplo. Não quero nem imaginar o que Dijkstra diria sobre eles se vivesse o suficiente para ver a crescente popularidade do JS.
Falando nisso, um dos maiores problemas que tenho com JavaScript é a discrepância das seguintes expressões:
-
"1" - “1”avalia como0 -
"1" * “1”é avaliado como1 -
"1" / “1”é avaliado como1 -
"1" + “1”é avaliado como“11”
A dupla croata de hip-hop “Tram 11”, batizada com o nome de um bonde que liga os bairros periféricos de Zagreb, tinha uma música que se traduz aproximadamente como: “Um e um não são dois, mas 11”. Ele foi lançado no final dos anos 90, então não era uma referência ao JavaScript, mas ilustra muito bem a discrepância.
Para evitar essas discrepâncias, proibi a conversão implícita de string para número e adicionei o operador .. para a concatenação (e ..= para a concatenação com atribuição). Não me lembro de onde tirei a ideia para esse operador. Não é do BASIC ou PHP, e não vou pesquisar a frase “Concatenação Python” porque pesquisar qualquer coisa sobre Python no Google me dá calafrios na espinha. Eu tenho fobia de cobras e combinando isso com “concatenação” - não, obrigado! Talvez mais tarde, com algum navegador arcaico baseado em texto, sem arte ASCII.
Mas voltando ao tópico desta seção - nosso analisador de expressão. Usaremos uma adaptação do “Shunting-yard Algorithm”.
Esse é o algoritmo que vem à mente de qualquer programador mediano depois de pensar no problema por 10 minutos ou mais. Ele pode ser usado para avaliar uma expressão infixa ou transformá-la para a notação polonesa reversa, o que não faremos.
A ideia do algoritmo é ler operandos e operadores da esquerda para a direita. Quando lemos um operando, nós o colocamos na pilha de operandos. Quando lemos um operador, não podemos avaliá-lo imediatamente, pois não sabemos se o operador a seguir terá precedência melhor do que aquele. Portanto, nós o empurramos para a pilha do operador.
No entanto, primeiro verificamos se o operador no topo da pilha tem precedência melhor do que aquele que acabamos de ler. Nesse caso, avaliamos o operador do topo da pilha com operandos na pilha de operandos. Colocamos o resultado na pilha de operandos. Nós o mantemos até lermos tudo e então avaliamos todos os operadores à esquerda da pilha de operadores com os operandos na pilha de operandos, empurrando os resultados de volta na pilha de operandos até ficarmos sem operadores e com apenas um operando, que é o resultado.
Quando dois operadores têm a mesma precedência, tomaremos o da esquerda caso esses operadores sejam associativos à esquerda; caso contrário, tomamos o caminho certo. Dois operadores de mesma precedência não podem ter associatividade diferente.
O algoritmo original também trata colchetes, mas faremos isso recursivamente, pois o algoritmo ficará mais limpo dessa maneira.
Edsger Dijkstra chamou o algoritmo de “Pátio de manobras” porque se assemelha à operação de um pátio de manobras de ferrovia.
No entanto, o algoritmo de desvio original quase não faz verificação de erros, portanto, é bem possível que uma expressão inválida seja analisada como correta. Portanto, adicionei a variável booleana que verifica se esperamos um operador ou um operando. Se esperamos operandos, também podemos analisar operadores de prefixo unário. Dessa forma, nenhuma expressão inválida pode passar despercebida e a verificação da sintaxe da expressão é concluída.
Empacotando
Quando comecei a codificar para esta parte da série, planejei escrever sobre o construtor de expressões. Eu queria construir uma expressão que pudesse ser avaliada. No entanto, acabou sendo muito complicado para um post de blog, então decidi dividi-lo ao meio. Nesta parte, concluímos a análise de expressões e escreverei sobre a construção de objetos de expressão no próximo artigo.
Se bem me lembro, cerca de 15 anos atrás, levei um fim de semana para escrever a primeira versão da minha primeira língua, o que me faz pensar o que deu errado desta vez.
Em um esforço para negar que estou ficando mais velho e menos espirituoso, vou culpar meu filho de dois anos por ser muito exigente no meu tempo livre.
Como na Parte 1, você pode ler, baixar ou até mesmo compilar o código da minha página do GitHub.