
Stork,第 2 部分:創建表達式解析器
已發表: 2022-03-11在我們系列的這一部分中,我們將介紹編寫語言引擎腳本的一個更棘手的(至少在我看來)組件,它是每種編程語言的基本構建塊:表達式解析器。
讀者可能會問的一個問題——這是理所當然的——是:為什麼我們不簡單地使用一些已經可以使用的複雜工具或庫?
為什麼我們不使用 Lex、YACC、Bison、Boost Spirit,或者至少是正則表達式?
在我們的整個關係中,我的妻子注意到了我不能否認的一個特點:每當遇到困難的問題時,我都會列出一個清單。 如果您考慮一下,那是完全有道理的——我用數量來彌補我的回答中缺乏質量。
我現在會做同樣的事情。
- 我想使用標準 C++。 在這種情況下,這將是 C++17。 我認為該語言本身就非常豐富,我正在努力克服將標準庫以外的任何東西添加到混合中的衝動。
- 當我開發我的第一個腳本語言時,我沒有使用任何復雜的工具。 我承受著壓力並且時間緊迫,但我不知道如何使用 Lex、YACC 或類似的東西。 因此,我決定手動開發所有內容。
- 後來,我找到了一位經驗豐富的編程語言開發人員的博客,他建議不要使用任何這些工具。 他說這些工具解決了語言開發中較容易的部分,所以無論如何,你都會遇到困難的事情。 我現在找不到那個博客,因為那是很久以前,當互聯網和我都很年輕的時候。
- 同時,有一個表情包說: “你有一個問題,你決定使用正則表達式來解決。 現在你有兩個問題。”
- 我不知道 Lex、YACC、Bison 或類似的東西。 我知道 Boost Spirit,它是一個方便且令人驚嘆的庫,但我仍然更喜歡更好地控制解析器。
- 我喜歡手動完成這些組件。 實際上,我可以給出這個答案並完全刪除這個列表。
完整代碼可在我的 GitHub 頁面上找到。
令牌迭代器
第 1 部分中的代碼有一些更改。
這些大多是簡單的修復和小的更改,但現有解析代碼的一個重要補充是類token_iterator 。 它允許我們評估當前令牌而不將其從流中刪除,這非常方便。
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; 它使用push_back_stream初始化,然後可以取消引用和遞增。 可以使用顯式 bool 強制轉換來檢查它,噹噹前令牌等於 eof 時,它將評估為 false。
靜態或動態類型語言?
在這一部分我必須做出一個決定:這種語言是靜態類型的還是動態類型的?
靜態類型語言是一種在編譯時檢查其變量類型的語言。
另一方面,動態類型語言不會在編譯期間檢查它(如果有編譯,這對於動態類型語言不是必需的),而是在執行期間。 因此,潛在的錯誤可能會一直存在於代碼中,直到它們被命中。
這是靜態類型語言的一個明顯優勢。 每個人都喜歡盡快發現自己的錯誤。 我一直想知道動態類型語言的最大優勢是什麼,最近幾週我得到了答案:它更容易開發!
我之前開發的語言是動態類型的。 我或多或少對結果感到滿意,編寫表達式解析器並不太難。 您基本上不必檢查變量類型,並且您依賴於運行時錯誤,您幾乎可以自發地編寫代碼。
例如,如果您必須編寫二進制+運算符並且想要為數字執行此操作,則只需在運行時將該運算符的兩邊都計算為數字。 如果任何一方都無法評估該數字,則只需拋出異常即可。 我什至通過檢查表達式中變量的運行時類型信息來實現運算符重載,並且運算符是該運行時信息的一部分。
在我開發的第一種語言(這是我的第三種語言)中,我在編譯時進行了類型檢查,但我沒有充分利用這一點。 表達式評估仍然取決於運行時類型信息。
現在,我決定開發一種靜態類型語言,結果證明這是一項比預期困難得多的任務。 但是,由於我不打算將其編譯為二進製文件或任何類型的模擬彙編代碼,因此某些類型的信息將隱含在編譯後的代碼中。
類型
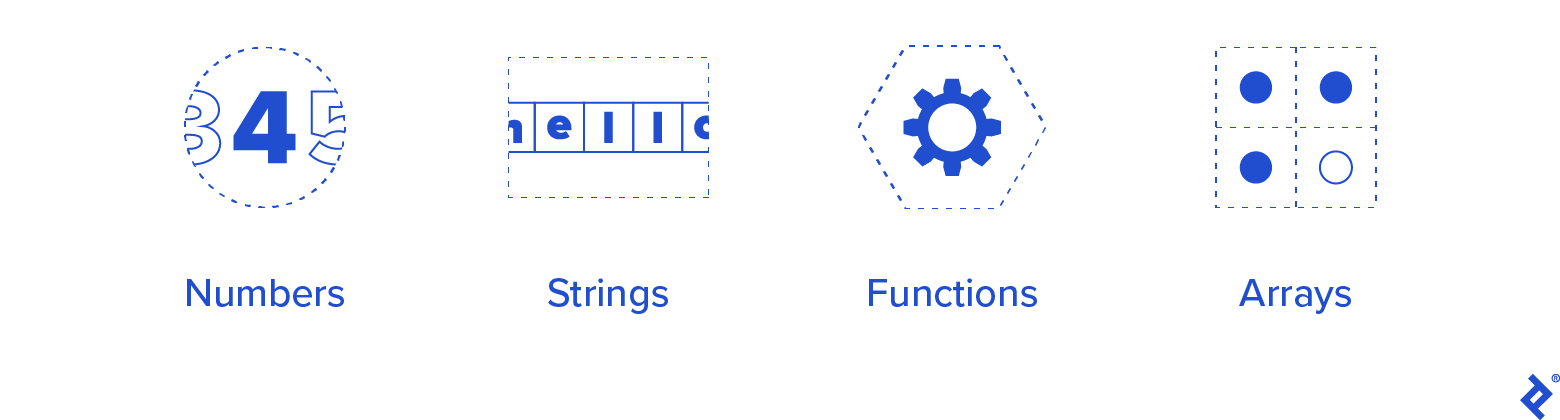
作為我們必須支持的最低限度的類型,我們將從以下內容開始:
- 數字
- 字符串
- 職能
- 數組
儘管我們可能會在未來添加它們,但我們不會在一開始就支持結構(或類、記錄、元組等)。 但是,我們會記住,我們可能會在以後添加它們,所以我們不會用難以改變的決定來密封我們的命運。
首先,我想將類型定義為字符串,這將遵循一些約定。 每個標識符都會在編譯時按值保留該字符串,有時我們必須對其進行解析。 例如,如果我們將數字數組的類型編碼為“[number]”,那麼我們必須修剪第一個和最後一個字符以獲得內部類型,在本例中為“number”。 如果您考慮一下,這是一個非常糟糕的主意。
然後,我嘗試將它作為一個類來實現。 該類將包含有關該類型的所有信息。 每個標識符都會保留一個指向該類的共享指針。 最後,我考慮在編譯期間使用所有類型的註冊表,因此每個標識符都有指向其類型的原始指針。
我喜歡這個主意,所以我們最終得到了以下結果:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;簡單類型是枚舉的成員:
enum struct simple_type { nothing, number, string, }; 枚舉成員nothing在這裡作為void的佔位符,我不能使用它,因為它是 C++ 中的關鍵字。
數組類型用具有type_handle唯一成員的結構表示。
struct array_type { type_handle inner_type_id; }; 顯然,數組長度不是array_type的一部分,所以數組會動態增長。 這意味著我們最終會得到std::deque或類似的東西,但我們稍後會處理。
函數類型由其返回類型、每個參數的類型以及每個參數是通過值傳遞還是通過引用傳遞。
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };現在,我們可以定義將保留這些類型的類。
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; 類型保存在std::set中,因為該容器是穩定的,這意味著即使在插入新類型之後,指向其成員的指針也是有效的。 有函數get_handle ,它註冊傳遞的類型並返回指向它的指針。 如果該類型已經註冊,它將返回指向現有類型的指針。 還有一些方便的函數可以獲取原始類型。
至於類型之間的隱式轉換,數字將可以轉換為字符串。 這不應該是危險的,因為不可能進行反向轉換,並且字符串連接的運算符與數字加法的運算符不同。 即使在這種語言開發的後期階段取消了這種轉換,它也可以作為一個很好的練習。 為此,我不得不修改數字解析器,因為它總是解析. 作為小數點。 它可能是連接運算符的第一個字符..
編譯器上下文
在編譯過程中,不同的編譯器函數需要獲取到目前為止編譯的代碼的信息。 我們將把這些信息保存在類compiler_context中。 由於我們即將實現表達式解析,我們將需要檢索有關我們遇到的標識符的信息。
在運行時,我們會將變量保存在兩個不同的容器中。 其中一個是全局變量容器,另一個是堆棧。 當我們調用函數並進入作用域時,堆棧會增長。 當我們從函數返回並離開作用域時,它會縮小。 當我們調用某個函數時,我們會推送函數參數,然後函數就會執行。 當它離開時,它的返回值將被壓入棧頂。 因此,對於每個函數,堆棧將如下所示:
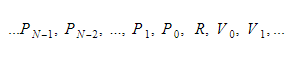
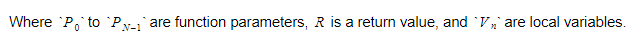
該函數將保留返回變量的絕對索引,並且每個變量或參數都將相對於該索引找到。
現在,我們將函數視為常量全局標識符。
這是用作標識符信息的類:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; 對於局部變量和函數參數,函數index返回相對於返回值的索引。 如果是全局標識符,它會返回絕對全局索引。
我們將在compile_context中進行三種不同的標識符查找:
- 全局標識符查找,它將按值保存
compile_context,因為它在整個編譯過程中都是相同的。 - 本地標識符查找,作為一個
unique_ptr,它將在全局範圍內為nullptr並將在任何函數中初始化。 每當我們進入作用域時,新的本地上下文將被初始化為舊的作為其父上下文。 當我們離開作用域時,它會被它的父代取代。 - 函數標識符查找,它將是原始指針。 它將在全局範圍內為
nullptr,並且與任何函數中最外層的本地範圍具有相同的值。
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };表達式樹
解析表達式標記時,它們將轉換為表達式樹。 與所有樹類似,這棵樹也由節點組成。

有兩種不同類型的節點:
- 葉節點,可以是:
a) 標識符
b) 數字
c) 字符串 - 內部節點,表示對其子節點的操作。 它用
unique_ptr保留它的孩子。
對於每個節點,都有關於其類型以及它是否返回左值(可以出現在=運算符左側的值)的信息。
創建內部節點時,它將嘗試將其子節點的返回類型轉換為它期望的類型。 允許以下隱式轉換:
- 左值到非左值
- 什麼都可以
void -
number到string
如果不允許轉換,則會拋出語義錯誤。
這是類定義,沒有一些輔助函數和實現細節:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; 方法的功能是不言自明的,除了函數check_conversion 。 它將通過遵守類型轉換規則檢查類型是否可轉換為傳遞的type_id和 boolean lvalue ,如果不是則拋出異常。
如果一個節點是用std::string或double初始化的,它的類型將分別是string或number ,而不是左值。 如果它是用標識符初始化的,它將假定該標識符的類型,如果標識符不是常量,它將是一個左值。
但是,如果使用節點操作對其進行初始化,則其類型將取決於操作,有時還取決於其子項的類型。 讓我們在表中編寫表達式類型。 我將使用&後綴來表示左值。 如果多個表達式具有相同的處理方式,我將在圓括號中寫出額外的表達式。
一元運算
| 手術 | 操作類型 | x型 |
| ++x (--x) | 數字& | 數字& |
| x++ (x--) | 數字 | 數字& |
| +x (-x ~x !x) | 數字 | 數字 |
二元運算
| 手術 | 操作類型 | x型 | y型 |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | 數字 | 數字 | 數字 |
| x==y (x!=y x<y x>y x<=y x>=y) | 數字 | 數字或字符串 | 與 x 相同 |
| x..y | 細繩 | 細繩 | 細繩 |
| x=y | 與 x 相同 | 任何事物的左值 | 與 x 相同,沒有左值 |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | 數字& | 數字& | 數字 |
| x..=y | 細繩& | 細繩& | 細繩 |
| x,y | 和 y 一樣 | 空白 | 任何事物 |
| x[y] | x的元素類型 | 數組類型 | 數字 |
三元運算
| 手術 | 操作類型 | x型 | y型 | z型 |
| x?y:z | 和 y 一樣 | 數字 | 任何事物 | 和 y 一樣 |
函數調用
當涉及到函數調用時,事情變得有點複雜。 如果函數有 N 個參數,則函數調用操作有 N+1 個子級,其中第一個子級是函數本身,其餘子級對應於函數參數。
但是,我們不允許通過引用隱式傳遞參數。 我們將要求調用者在它們前面加上&符號。 目前,這不是一個額外的運算符,而是函數調用的解析方式。 如果我們不解析 & 符號,那麼當需要參數時,我們將通過添加一個我們稱為node_operation::param的假一元操作來從該參數中刪除左值。 該操作與其子操作具有相同的類型,但它不是左值。
然後,當我們使用該調用操作構建節點時,如果我們有一個左值但函數不期望的參數,我們將產生錯誤,因為這意味著調用者不小心輸入了 & 符號。 有點令人驚訝的是,如果將&視為運算符,則其優先級最低,因為如果在表達式內部進行解析,它在語義上沒有意義。 我們稍後可能會更改它。
表達式解析器
著名的計算機科學哲學家 Edsger Dijkstra 在他關於程序員潛力的一項聲明中曾經說過:
“向之前接觸過 BASIC 的學生教授好的編程實際上是不可能的。 作為潛在的程序員,他們在精神上被殘缺不全,沒有再生的希望。”
所以,對於所有沒有接觸過 BASIC 的人 - 感激不盡,因為你逃脫了“精神傷害”。
我們這些殘缺不全的程序員,讓我們提醒自己使用 BASIC 編碼的日子。 有一個運算符\ ,用於整數除法。 在你沒有單獨的整數和浮點數類型的語言中,這非常方便,所以我在 Stork 中添加了相同的運算符。 我還添加了運算符\= ,正如您所猜測的那樣,它將執行整數除法然後分配。
例如,我認為 JavaScript 程序員會喜歡這樣的運算符。 我什至不想想像如果 Dijkstra 活得足夠長,看到 JS 越來越受歡迎,他會對他們說些什麼。
說到這,我在 JavaScript 中遇到的最大問題之一是以下表達式的差異:
-
"1" - “1”計算為0 -
"1" * “1”計算結果為1 -
"1" / “1”計算為1 -
"1" + “1”計算為“11”
克羅地亞嘻哈二人組“Tram 11”以連接薩格勒布外圍行政區的電車命名,有一首歌大致翻譯為: “一加一不是二,而是 11”。 它出現在 90 年代後期,因此它不是對 JavaScript 的引用,但它很好地說明了這種差異。
為了避免這些差異,我禁止從字符串到數字的隱式轉換,並添加了..運算符用於連接(以及..=用於與賦值的連接)。 我不記得我從哪裡得到那個操作員的想法。 它不是來自 BASIC 或 PHP,我不會搜索短語“Python concatenation”,因為在谷歌上搜索任何關於 Python 的內容都會讓我脊背發涼。 我對蛇有恐懼症,並將其與“串聯”結合起來——不,謝謝! 也許稍後,使用一些古老的基於文本的瀏覽器,沒有 ASCII 藝術。
但回到本節的主題——我們的表達式解析器。 我們將使用“調車場算法”的改編版。
這是任何一個普通程序員在考慮這個問題 10 分鐘左右後都會想到的算法。 它可用於計算中綴表達式或將其轉換為反向波蘭表示法,我們不會這樣做。
該算法的思想是從左到右讀取操作數和運算符。 當我們讀取一個操作數時,我們將它壓入操作數堆棧。 當我們讀取一個運算符時,我們不能立即評估它,因為我們不知道後面的運算符是否會比那個有更好的優先級。 因此,我們將其推送到操作員堆棧。
但是,我們首先檢查堆棧頂部的運算符是否比我們剛剛讀取的運算符具有更好的優先級。 在這種情況下,我們使用操作數堆棧上的操作數從堆棧頂部評估運算符。 我們將結果推送到操作數堆棧。 我們一直保留它,直到我們讀取所有內容,然後使用操作數堆棧上的操作數評估操作數堆棧左側的所有運算符,將結果推回操作數堆棧,直到我們沒有運算符且只有一個操作數,即結果。
當兩個運算符具有相同的優先級時,我們將取左一個,以防這些運算符是左結合的; 否則,我們選擇正確的。 相同優先級的兩個運算符不能具有不同的關聯性。
原始算法也處理圓括號,但我們將改為遞歸處理,因為這樣算法會更乾淨。
Edsger Dijkstra 將該算法命名為“調車場”,因為它類似於鐵路調車場的操作。
然而,原來的調車場算法幾乎不做錯誤檢查,所以很有可能一個無效的表達式被解析為一個正確的表達式。 因此,我添加了布爾變量來檢查我們是否需要一個運算符或一個操作數。 如果我們期望操作數,我們也可以解析一元前綴運算符。 這樣一來,任何無效表達式都不會被忽視,表達式語法檢查就完成了。
包起來
當我開始編寫本系列的這一部分時,我計劃寫關於表達式構建器的文章。 我想構建一個可以評估的表達式。 然而,對於一篇博客文章來說,它太複雜了,所以我決定把它分成兩半。 在這一部分,我們總結了解析表達式,我將在下一篇文章中寫關於構建表達式對象的內容。
如果我沒記錯的話,大約 15 年前,我花了一個週末來寫我的第一語言的第一個版本,這讓我想知道這次出了什麼問題。
為了否認自己年紀大了,不那麼機智了,我會責怪我兩歲的兒子在業餘時間要求太高。
與第 1 部分一樣,歡迎您從我的 GitHub 頁面閱讀、下載甚至編譯代碼。