
Cicogna, parte 2: creazione di un parser di espressioni
Pubblicato: 2022-03-11In questa parte della nostra serie, tratteremo uno dei componenti più complicati (almeno secondo me) dello scripting di un motore di linguaggio, che è un elemento costitutivo essenziale per ogni linguaggio di programmazione: il parser di espressioni.
Una domanda che un lettore potrebbe porre - e giustamente - è: perché non utilizziamo semplicemente alcuni strumenti o librerie sofisticati, qualcosa che è già a nostra disposizione?
Perché non usiamo Lex, YACC, Bison, Boost Spirit o almeno le espressioni regolari?
Durante la nostra relazione, mia moglie ha notato una mia caratteristica che non posso negare: ogni volta che devo affrontare una domanda difficile, faccio una lista. Se ci pensi, ha perfettamente senso: sto usando la quantità per compensare la mancanza di qualità nella mia risposta.
Farò la stessa cosa adesso.
- Voglio usare il C++ standard. In questo caso, sarà C++17. Penso che il linguaggio sia abbastanza ricco di per sé e sto combattendo l'impulso di aggiungere qualsiasi cosa tranne la libreria standard nel mix.
- Quando ho sviluppato il mio primo linguaggio di scripting, non ho utilizzato strumenti sofisticati. Ero sotto pressione e avevo una scadenza ravvicinata, ma non sapevo come usare Lex, YACC o qualcosa di simile. Pertanto, ho deciso di sviluppare tutto manualmente.
- Più tardi, ho trovato un blog di uno sviluppatore esperto di linguaggi di programmazione, che sconsigliava l'uso di uno di questi strumenti. Ha detto che quegli strumenti risolvono la parte più facile dello sviluppo del linguaggio, quindi in ogni caso ti rimangono le cose difficili. Non riesco a trovare quel blog in questo momento, come lo era tanto tempo fa, quando Internet e io eravamo giovani.
- Allo stesso tempo, c'era un meme che diceva: “Hai un problema che decidi di risolvere usando espressioni regolari. Adesso hai due problemi".
- Non conosco Lex, YACC, Bison o qualcosa di simile. Conosco Boost Spirit ed è una libreria utile e sorprendente, ma preferisco comunque avere un controllo migliore sul parser.
- Mi piace fare quei componenti manualmente. In realtà, potrei semplicemente dare questa risposta e rimuovere completamente questo elenco.
Il codice completo è disponibile nella mia pagina GitHub.
Iteratore di token
Ci sono alcune modifiche al codice dalla parte 1.
Si tratta per lo più di semplici correzioni e piccole modifiche, ma un'importante aggiunta al codice di analisi esistente è la classe token_iterator . Ci consente di valutare il token corrente senza rimuoverlo dallo stream, il che è davvero utile.
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; Viene inizializzato con push_back_stream , quindi può essere dereferenziato e incrementato. Può essere verificato con un cast bool esplicito, che restituirà false quando il token corrente è uguale a eof.
Linguaggio tipizzato staticamente o dinamicamente?
C'è una decisione che devo prendere in questa parte: questa lingua sarà digitata staticamente o dinamicamente?
Un linguaggio tipizzato staticamente è un linguaggio che controlla i tipi delle sue variabili al momento della compilazione.
Un linguaggio tipizzato dinamicamente , invece, non lo verifica durante la compilazione (se c'è una compilazione, che non è obbligatoria per un linguaggio tipizzato dinamicamente) ma durante l'esecuzione. Pertanto, potenziali errori possono risiedere nel codice fino a quando non vengono colpiti.
Questo è un ovvio vantaggio dei linguaggi tipizzati staticamente. A tutti piace cogliere i propri errori il prima possibile. Mi sono sempre chiesto quale fosse il più grande vantaggio dei linguaggi digitati dinamicamente e la risposta mi ha colpito nelle ultime due settimane: è molto più facile da sviluppare!
Il linguaggio precedente che ho sviluppato è stato digitato dinamicamente. Sono rimasto più o meno soddisfatto del risultato e scrivere il parser di espressioni non è stato troppo difficile. Fondamentalmente non devi controllare i tipi di variabili e fai affidamento su errori di runtime, che codifichi quasi spontaneamente.
Ad esempio, se devi scrivere l'operatore binario + e vuoi farlo per i numeri, devi solo valutare entrambi i lati di quell'operatore come numeri nel runtime. Se una delle parti non è in grado di valutare il numero, genera semplicemente un'eccezione. Ho persino implementato l'overloading degli operatori controllando le informazioni sul tipo di runtime delle variabili in un'espressione e gli operatori facevano parte di tali informazioni di runtime.
Nel primo linguaggio che ho sviluppato (questo è il mio terzo), ho eseguito il controllo del tipo al momento della compilazione, ma non ne avevo sfruttato appieno. La valutazione dell'espressione dipendeva ancora dalle informazioni sul tipo di runtime.
Ora, ho deciso di sviluppare un linguaggio tipizzato staticamente e si è rivelato un compito molto più difficile del previsto. Tuttavia, poiché non ho intenzione di compilarlo in un binario o in qualsiasi tipo di codice assembly emulato, nel codice compilato esisteranno implicitamente alcuni tipi di informazioni.
Tipi
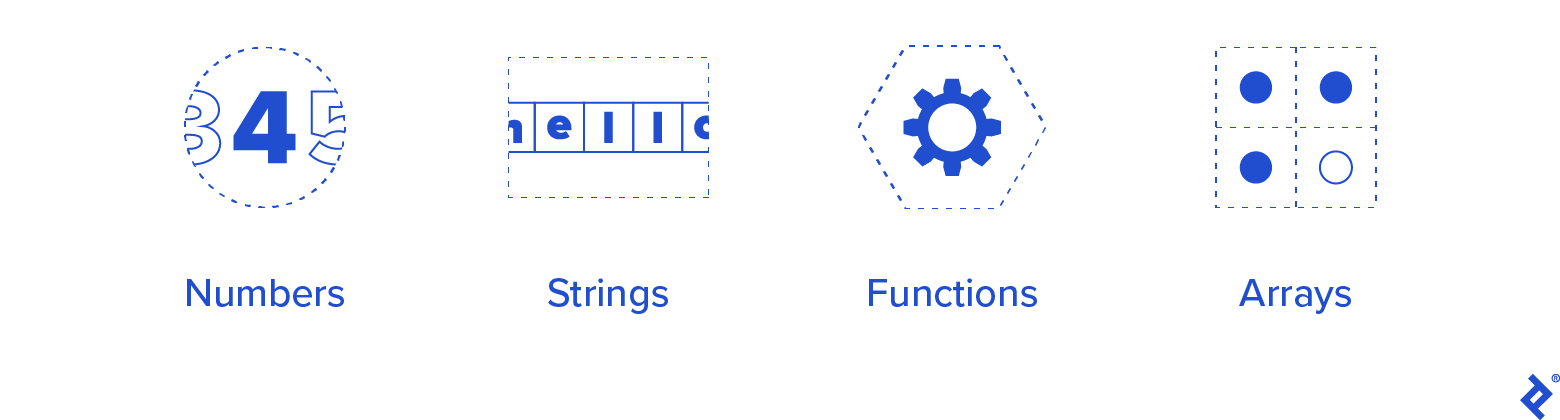
Come minimo dei tipi che dobbiamo supportare, inizieremo con quanto segue:
- Numeri
- stringhe
- Funzioni
- Matrici
Sebbene possiamo aggiungerli andando avanti, non supporteremo strutture (o classi, record, tuple, ecc.) all'inizio. Tuttavia, terremo presente che potremmo aggiungerli in seguito, quindi non sigilleremo il nostro destino con decisioni difficili da cambiare.
Innanzitutto, volevo definire il tipo come una stringa, che seguirà alcune convenzioni. Ogni identificatore manterrebbe quella stringa per valore al momento della compilazione e a volte dovremo analizzarla. Ad esempio, se codifichiamo il tipo di matrice di numeri come "[numero]", dovremo tagliare il primo e l'ultimo carattere per ottenere un tipo interno, che in questo caso è "numero". È una pessima idea se ci pensi.
Quindi, ho provato a implementarlo come una classe. Quella classe avrebbe tutte le informazioni sul tipo. Ogni identificatore manterrebbe un puntatore condiviso a quella classe. Alla fine, ho pensato di utilizzare il registro di tutti i tipi durante la compilazione, in modo che ogni identificatore avesse il puntatore grezzo al suo tipo.
Mi è piaciuta l'idea, quindi abbiamo finito con quanto segue:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;I tipi semplici sono membri dell'enumerazione:
enum struct simple_type { nothing, number, string, }; Il membro dell'enumerazione nothing è qui come segnaposto per void , che non posso usare in quanto è una parola chiave in C++.
I tipi di array sono rappresentati con la struttura che ha l'unico membro di type_handle .
struct array_type { type_handle inner_type_id; }; Ovviamente, la lunghezza dell'array non fa parte di array_type , quindi gli array cresceranno dinamicamente. Ciò significa che finiremo con std::deque o qualcosa di simile, ma ci occuperemo di questo in seguito.
Un tipo di funzione è composto dal tipo restituito, dal tipo di ciascuno dei suoi parametri e dal fatto che ciascuno di questi parametri sia passato o meno per valore o per riferimento.
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };Ora possiamo definire la classe che manterrà quei tipi.
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; I tipi vengono mantenuti in std::set , poiché quel contenitore è stabile, il che significa che i puntatori ai suoi membri sono validi anche dopo l'inserimento di nuovi tipi. C'è la funzione get_handle , che registra il tipo passato e restituisce il puntatore ad esso. Se il tipo è già registrato, restituirà il puntatore al tipo esistente. Ci sono anche funzioni utili per ottenere tipi primitivi.
Per quanto riguarda la conversione implicita tra tipi, i numeri saranno convertibili in stringhe. Non dovrebbe essere pericoloso, poiché una conversione inversa non è possibile e l'operatore per la concatenazione di stringhe è distintivo di quello per l'addizione dei numeri. Anche se questa conversione viene rimossa nelle fasi successive dello sviluppo di questo linguaggio, servirà bene come esercizio a questo punto. A tale scopo, ho dovuto modificare il parser dei numeri, poiché analizzava sempre . come punto decimale. Potrebbe essere il primo carattere dell'operatore di concatenazione ..
Contesto del compilatore
Durante la compilazione, diverse funzioni del compilatore devono ottenere informazioni sul codice compilato finora. Conserveremo queste informazioni in una classe compiler_context . Poiché stiamo per implementare l'analisi delle espressioni, dovremo recuperare informazioni sugli identificatori che incontriamo.
Durante il runtime, manterremo le variabili in due contenitori diversi. Uno di questi sarà il contenitore della variabile globale e un altro sarà lo stack. Lo stack aumenterà man mano che chiamiamo funzioni e inseriamo ambiti. Si ridurrà quando torniamo dalle funzioni e lasciamo gli ambiti. Quando chiamiamo una funzione, spingeremo i parametri della funzione e quindi la funzione verrà eseguita. Il suo valore di ritorno verrà spostato in cima allo stack quando esce. Pertanto, per ogni funzione, lo stack sarà simile a questo:
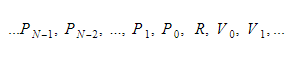
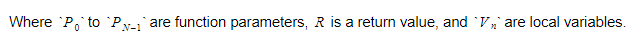
La funzione manterrà l'indice assoluto della variabile di ritorno e ogni variabile o parametro verrà trovato relativo a quell'indice.
Per ora, tratteremo le funzioni come identificatori globali costanti.
Questa è la classe che funge da informazioni identificative:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; Per variabili locali e parametri di funzione, index funzione restituisce l'indice relativo al valore restituito. Restituisce l'indice globale assoluto in caso di identificatori globali.
Avremo tre diverse ricerche di identificatori in compile_context :
- Ricerca dell'identificatore globale, che
compile_contextmanterrà per valore, poiché è lo stesso per l'intera compilazione. - Ricerca dell'identificatore locale, come
unique_ptr, che sarànullptrnell'ambito globale e verrà inizializzato in qualsiasi funzione. Ogni volta che entriamo nell'ambito, il nuovo contesto locale verrà inizializzato con quello vecchio come genitore. Quando usciamo dall'ambito, verrà sostituito dal suo genitore. - Ricerca dell'identificatore di funzione, che sarà il puntatore non elaborato. Sarà
nullptrnell'ambito globale e lo stesso valore dell'ambito locale più esterno in qualsiasi funzione.
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };Albero delle espressioni
Quando i token di espressione vengono analizzati, vengono convertiti in un albero delle espressioni. Simile a tutti gli alberi, anche questo è composto da nodi.

Esistono due diversi tipi di nodi:
- Nodi foglia, che possono essere:
a) Identificatori
b) Numeri
c) Stringhe - Nodi interni, che rappresentano un'operazione sui loro nodi figli. Mantiene i suoi figli con
unique_ptr.
Per ogni nodo, ci sono informazioni sul suo tipo e se restituisce o meno un lvalue (un valore che può apparire sul lato sinistro dell'operatore = ).
Quando viene creato un nodo interno, proverà a convertire i tipi restituiti dei suoi figli nei tipi che si aspetta. Sono consentite le seguenti conversioni implicite:
- lvalue a non lvalue
- Qualsiasi cosa da
void -
numberinstring
Se la conversione non è consentita, verrà generato un errore semantico.
Ecco la definizione della classe, senza alcune funzioni di supporto e dettagli di implementazione:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; La funzionalità dei metodi è autoesplicativa, ad eccezione della funzione check_conversion . Verificherà se il tipo è convertibile nel type_id passato e nel valore booleano lvalue obbedendo alle regole di conversione del tipo e genererà un'eccezione in caso contrario.
Se un nodo viene inizializzato con std::string , o double , il suo tipo sarà rispettivamente string o number , e non sarà un lvalue. Se viene inizializzato con un identificatore, assumerà il tipo di tale identificatore e sarà un lvalue se l'identificatore non è costante.
Se viene inizializzato, tuttavia, con un'operazione di nodo, il suo tipo dipenderà dall'operazione e talvolta dal tipo dei suoi figli. Scriviamo i tipi di espressione nella tabella. Userò & suffix per denotare un lvalue. Nei casi in cui più espressioni hanno lo stesso trattamento, scriverò espressioni aggiuntive tra parentesi tonde.
Operazioni unarie
| Operazione | Tipo di operazione | tipo x |
| ++x (--x) | numero& | numero& |
| x++ (x--) | numero | numero& |
| +x (-x ~x !x) | numero | numero |
Operazioni binarie
| Operazione | Tipo di operazione | tipo x | y digita |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | numero | numero | numero |
| x==y (x!=y x<y x>y x<=y x>=y) | numero | numero o stringa | uguale a x |
| x..y | corda | corda | corda |
| x=y | uguale a x | valore di qualsiasi cosa | come x, senza lvalue |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | numero& | numero& | numero |
| x..=y | corda& | corda& | corda |
| x,y | come y | vuoto | nulla |
| x[y] | tipo di elemento di x | tipo di matrice | numero |
Operazioni ternarie
| Operazione | Tipo di operazione | tipo x | y digita | tipo z |
| x?y:z | come y | numero | nulla | come y |
Chiamata di funzione
Quando si tratta della chiamata di funzione, le cose si complicano un po'. Se la funzione ha N argomenti, l'operazione di chiamata di funzione ha N+1 figli, dove il primo figlio è la funzione stessa e il resto dei figli corrisponde agli argomenti della funzione.
Tuttavia, non consentiremo il passaggio implicito di argomenti per riferimento. Richiederemo al chiamante di anteporre loro il segno & . Per ora, quello non sarà un operatore aggiuntivo ma il modo in cui viene analizzata la chiamata di funzione. Se non analizziamo la e commerciale, quando l'argomento è previsto, rimuoveremo lvalue-ness da quell'argomento aggiungendo un'operazione unaria falsa che chiamiamo node_operation::param . Quell'operazione ha lo stesso tipo del suo figlio, ma non è un lvalue.
Quindi, quando costruiamo il nodo con quell'operazione di chiamata, se abbiamo un argomento che è lvalue ma non è previsto dalla funzione, genereremo un errore, poiché significa che il chiamante ha digitato accidentalmente la e commerciale. In qualche modo sorprendentemente, che & , se trattato come un operatore, avrebbe la precedenza minore, poiché non ha il significato semanticamente se analizzato all'interno dell'espressione. Potremmo cambiarlo in seguito.
Analizzatore di espressioni
In una delle sue affermazioni sul potenziale dei programmatori, il famoso filosofo dell'informatica Edsger Dijkstra una volta disse:
“È praticamente impossibile insegnare una buona programmazione a studenti che hanno avuto una precedente esposizione al BASIC. In quanto potenziali programmatori, sono mentalmente mutilati oltre ogni speranza di rigenerazione”.
Quindi, per tutti voi che non siete stati esposti al BASIC, siate grati perché siete sfuggiti alla "mutilazione mentale".
Il resto di noi, programmatori mutilati, ricordiamoci dei giorni in cui codificavamo in BASIC. C'era un operatore \ , che è stato utilizzato per la divisione integrale. In una lingua in cui non hai tipi separati per numeri interi e in virgola mobile, è abbastanza utile, quindi ho aggiunto lo stesso operatore a Stork. Ho anche aggiunto l'operatore \= , che, come hai intuito, eseguirà la divisione integrale e quindi assegnerà.
Penso che tali operatori sarebbero apprezzati dai programmatori JavaScript, ad esempio. Non voglio nemmeno immaginare cosa direbbe Dijkstra di loro se vivesse abbastanza a lungo per vedere la crescente popolarità di JS.
A proposito, uno dei maggiori problemi che ho con JavaScript è la discrepanza delle seguenti espressioni:
-
"1" - “1”restituisce0 -
"1" * “1”restituisce1 -
"1" / “1”restituisce1 -
"1" + “1”restituisce“11”
Il duo hip-hop croato "Tram 11", dal nome di un tram che collega i quartieri periferici di Zagabria, aveva una canzone che si traduce approssimativamente come: "Uno e uno non sono due, ma 11". È uscito alla fine degli anni '90, quindi non era un riferimento a JavaScript, ma illustra abbastanza bene la discrepanza.
Per evitare queste discrepanze, ho proibito la conversione implicita da stringa a numero e ho aggiunto .. operatore per la concatenazione (e ..= per la concatenazione con assegnazione). Non ricordo da dove ho preso l'idea per quell'operatore. Non proviene da BASIC o PHP e non cercherò la frase "Python concatenation" perché cercare su Google qualsiasi cosa su Python mi fa venire i brividi lungo la schiena. Ho una fobia per i serpenti e combinandola con la "concatenazione" - no, grazie! Magari in seguito, con qualche browser testuale arcaico, senza ASCII art.
Ma torniamo all'argomento di questa sezione: il nostro parser di espressioni. Useremo un adattamento di "Shunting-yard Algorithm".
Questo è l'algoritmo che viene in mente a qualsiasi programmatore anche medio dopo aver pensato al problema per circa 10 minuti. Può essere utilizzato per valutare un'espressione infissa o trasformarla nella notazione polacca inversa, cosa che non faremo.
L'idea dell'algoritmo è di leggere operandi e operatori da sinistra a destra. Quando leggiamo un operando, lo inseriamo nello stack degli operandi. Quando leggiamo un operatore, non possiamo valutarlo immediatamente, poiché non sappiamo se l'operatore successivo avrà una precedenza migliore di quello. Pertanto, lo spingiamo nello stack dell'operatore.
Tuttavia, controlliamo prima se l'operatore in cima allo stack ha una precedenza migliore rispetto a quello che abbiamo appena letto. In tal caso, valutiamo l'operatore dalla cima dello stack con gli operandi nello stack degli operandi. Inseriamo il risultato nello stack degli operandi. Lo conserviamo finché non leggiamo tutto e quindi valutiamo tutti gli operatori a sinistra dello stack degli operatori con gli operandi sullo stack degli operandi, riportando i risultati sullo stack degli operandi finché non rimaniamo senza operatori e con un solo operando, che è il risultato.
Quando due operatori hanno la stessa precedenza, prenderemo quello di sinistra nel caso in cui quegli operatori siano associativi a sinistra; altrimenti prendiamo quello giusto. Due operatori con la stessa precedenza non possono avere associatività diversa.
L'algoritmo originale tratta anche le parentesi tonde, ma lo faremo invece in modo ricorsivo, poiché l'algoritmo sarà più pulito in questo modo.
Edsger Dijkstra ha chiamato l'algoritmo "cantiere di smistamento" perché ricorda il funzionamento di uno scalo ferroviario.
Tuttavia, l'algoritmo di smistamento originale non esegue quasi alcun controllo degli errori, quindi è del tutto possibile che un'espressione non valida venga analizzata come corretta. Pertanto, ho aggiunto la variabile booleana che controlla se ci aspettiamo un operatore o un operando. Se ci aspettiamo operandi, possiamo anche analizzare gli operatori di prefissi unari. In questo modo, nessuna espressione non valida può passare sotto il radar e il controllo della sintassi dell'espressione è completo.
Avvolgendo
Quando ho iniziato a programmare per questa parte della serie, avevo programmato di scrivere del costruttore di espressioni. Volevo costruire un'espressione che può essere valutata. Tuttavia, si è rivelato troppo complicato per un post sul blog, quindi ho deciso di dividerlo a metà. In questa parte, abbiamo concluso l'analisi delle espressioni e scriverò sulla creazione di oggetti espressione nel prossimo articolo.
Se ricordo bene, circa 15 anni fa, mi ci è voluto un fine settimana per scrivere la prima versione della mia prima lingua, il che mi fa chiedere cosa sia andato storto questa volta.
Nel tentativo di negare che sto invecchiando e diventando meno spiritoso, darò la colpa a mio figlio di due anni per essere stato troppo esigente nel mio tempo libero.
Come nella Parte 1, puoi leggere, scaricare o persino compilare il codice dalla mia pagina GitHub.