
جو ستورك ، الجزء 2: إنشاء محلل تعبير
نشرت: 2022-03-11في هذا الجزء من سلسلتنا ، سنغطي أحد المكونات الأكثر تعقيدًا (على الأقل في رأيي) في برمجة محرك لغة ، والذي يعد لبنة أساسية لكل لغة برمجة: محلل التعبير.
السؤال الذي يمكن للقارئ أن يطرحه - وهو محق في ذلك - هو: لماذا لا نستخدم ببساطة بعض الأدوات أو المكتبات المعقدة ، وهو شيء تحت تصرفنا بالفعل؟
لماذا لا نستخدم Lex أو YACC أو Bison أو Boost Spirit أو على الأقل التعبيرات العادية؟
طوال علاقتنا ، لاحظت زوجتي سمة خاصة بي لا يمكنني إنكارها: كلما واجهت سؤالًا صعبًا ، أقوم بإعداد قائمة. إذا فكرت في الأمر ، فمن المنطقي تمامًا - أنا أستخدم الكمية للتعويض عن نقص الجودة في إجابتي.
سأفعل نفس الشيء الآن.
- أريد استخدام معيار C ++. في هذه الحالة ، سيكون هذا هو C ++ 17. أعتقد أن اللغة غنية جدًا بمفردها ، وأنا أحارب الرغبة في إضافة أي شيء سوى المكتبة القياسية إلى هذا المزيج.
- عندما طورت لغتي الأولى في البرمجة النصية ، لم أستخدم أي أدوات معقدة. كنت تحت ضغط وفي موعد نهائي ضيق ، ومع ذلك لم أكن أعرف كيفية استخدام Lex أو YACC أو أي شيء مشابه. لذلك ، قررت تطوير كل شيء يدويًا.
- في وقت لاحق ، عثرت على مدونة لمطور لغة برمجة متمرس ، والذي نصح بعدم استخدام أي من هذه الأدوات. قال إن هذه الأدوات تحل الجزء الأسهل من تطوير اللغة ، لذلك على أي حال ، تبقى مع الأشياء الصعبة. لا يمكنني العثور على هذه المدونة الآن ، كما كانت منذ زمن بعيد ، عندما كنت أنا والإنترنت صغارًا.
- في الوقت نفسه ، كان هناك ميم يقول: "لديك مشكلة قررت حلها باستخدام التعبيرات النمطية. الآن لديك مشكلتان ".
- لا أعرف Lex أو YACC أو Bison أو أي شيء مشابه. أنا أعرف Boost Spirit ، وهي مكتبة مفيدة ومدهشة ، لكنني ما زلت أفضل أن يكون لدي سيطرة أفضل على المحلل اللغوي.
- أحب أن أفعل هذه المكونات يدويًا. في الواقع ، يمكنني فقط إعطاء هذه الإجابة وإزالة هذه القائمة تمامًا.
الكود الكامل متاح في صفحة GitHub الخاصة بي.
تكرار الرمز المميز
توجد بعض التغييرات على الكود من الجزء الأول.
هذه في الغالب إصلاحات بسيطة وتغييرات صغيرة ، ولكن إحدى الإضافات المهمة إلى كود التحليل الحالي هي فئة token_iterator . يسمح لنا بتقييم الرمز المميز الحالي دون إزالته من الدفق ، وهو أمر مفيد حقًا.
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; تتم تهيئته باستخدام push_back_stream ، ومن ثم يمكن إلغاء الإشارة إليه وزيادته. يمكن التحقق من ذلك باستخدام قالب منطقي صريح ، والذي سيتم تقييمه إلى خطأ عندما يكون الرمز المميز الحالي مساويًا لـ eof.
لغة مكتوبة بشكل ثابت أو ديناميكي؟
هناك قرار واحد يتعين علي اتخاذه في هذا الجزء: هل ستتم كتابة هذه اللغة بشكل ثابت أو ديناميكي؟
اللغة المكتوبة بشكل ثابت هي اللغة التي تتحقق من أنواع متغيراتها في وقت التجميع.
من ناحية أخرى ، لا تتحقق اللغة المكتوبة ديناميكيًا أثناء التجميع (إذا كان هناك تجميع ، وهو ليس إلزاميًا للغة المكتوبة ديناميكيًا) ولكن أثناء التنفيذ. لذلك ، يمكن أن تبقى الأخطاء المحتملة في التعليمات البرمجية حتى يتم الوصول إليها.
هذه ميزة واضحة للغات المكتوبة بشكل ثابت. يحب الجميع اكتشاف أخطائهم في أسرع وقت ممكن. لطالما تساءلت عن أكبر ميزة للغات المكتوبة ديناميكيًا ، وقد صدمتني الإجابة في الأسبوعين الماضيين: من الأسهل تطويرها!
اللغة السابقة التي طورتها تمت كتابتها ديناميكيًا. كنت راضيًا إلى حد ما عن النتيجة ، ولم تكن كتابة المحلل اللغوي للتعبير صعبة للغاية. لست مضطرًا بشكل أساسي إلى التحقق من الأنواع المتغيرة وأنت تعتمد على أخطاء وقت التشغيل ، والتي تقوم بتشفيرها تلقائيًا تقريبًا.
على سبيل المثال ، إذا كان عليك كتابة عامل التشغيل الثنائي + وتريد القيام بذلك للأرقام ، فأنت تحتاج فقط إلى تقييم كلا جانبي هذا العامل كأرقام في وقت التشغيل. إذا لم يتمكن أي من الجانبين من تقييم الرقم ، فكل ما عليك هو طرح استثناء. لقد قمت حتى بتنفيذ التحميل الزائد للمشغل عن طريق التحقق من معلومات نوع وقت التشغيل للمتغيرات في التعبير ، وكانت العوامل جزءًا من معلومات وقت التشغيل هذه.
في اللغة الأولى التي طورتها (هذه هي لغتي الثالثة) ، قمت بفحص الكتابة في وقت التجميع ، لكنني لم أستفد من ذلك بشكل كامل. كان تقييم التعبير لا يزال يعتمد على معلومات نوع وقت التشغيل.
الآن ، قررت تطوير لغة مكتوبة بشكل ثابت ، واتضح أنها مهمة أصعب بكثير مما كان متوقعًا. ومع ذلك ، نظرًا لأنني لا أخطط لترجمته إلى ثنائي ، أو أي نوع من رموز التجميع التي تمت مضاهاتها ، فإن بعض أنواع المعلومات ستكون موجودة ضمنيًا في الكود المترجم.
أنواع
كحد أدنى من الأنواع التي يتعين علينا دعمها ، سنبدأ بما يلي:
- أعداد
- سلاسل
- المهام
- المصفوفات
على الرغم من أننا قد نضيفها من الآن فصاعدًا ، إلا أننا لن ندعم الهياكل (أو الفئات ، والسجلات ، والمجموعات ، وما إلى ذلك) في البداية. ومع ذلك ، سوف نضع في اعتبارنا أننا قد نضيفها لاحقًا ، لذلك لن نختم مصيرنا بقرارات يصعب تغييرها.
أولاً ، أردت تحديد النوع كسلسلة ، والتي ستتبع بعض الاصطلاحات. سيحتفظ كل معرف بهذه السلسلة من حيث القيمة في وقت التجميع ، وسيتعين علينا تحليلها في بعض الأحيان. على سبيل المثال ، إذا قمنا بترميز نوع مصفوفة الأرقام كـ "[رقم]" ، فسنضطر إلى قطع الحرف الأول والأخير من أجل الحصول على نوع داخلي ، وهو "رقم" في هذه الحالة. إنها فكرة سيئة جدًا إذا فكرت في الأمر.
ثم حاولت تنفيذه كصف دراسي. هذا الفصل سيكون لديه كل المعلومات حول النوع. سيحتفظ كل معرف بمؤشر مشترك لتلك الفئة. في النهاية ، فكرت في الحصول على سجل لجميع الأنواع المستخدمة أثناء التجميع ، بحيث يكون لكل معرف المؤشر الأولي لنوعه.
أعجبتني هذه الفكرة ، وانتهى بنا الأمر بما يلي:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;الأنواع البسيطة هي أعضاء في التعداد:
enum struct simple_type { nothing, number, string, }; لا يوجد nothing لعضو التعداد هنا كعنصر نائب void ، والذي لا يمكنني استخدامه لأنه كلمة رئيسية في C ++.
يتم تمثيل أنواع المصفوفات مع الهيكل الذي يحتوي على العضو الوحيد من type_handle .
struct array_type { type_handle inner_type_id; }; من الواضح أن طول المصفوفة ليس جزءًا من array_type ، لذلك ستنمو المصفوفات ديناميكيًا. هذا يعني أننا سننتهي بـ std::deque أو شيء مشابه ، لكننا سنتعامل مع ذلك لاحقًا.
يتكون نوع الوظيفة من نوع الإرجاع الخاص به ، ونوع كل من معلماته ، وما إذا كان يتم تمرير كل من هذه المعلمات بواسطة القيمة أو المرجع أم لا.
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };الآن ، يمكننا تحديد الفئة التي ستحتفظ بهذه الأنواع.
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; يتم الاحتفاظ بالأنواع في std::set ، لأن هذه الحاوية مستقرة ، مما يعني أن المؤشرات إلى أعضائها صالحة حتى بعد إدراج أنواع جديدة. هناك وظيفة get_handle ، والتي تسجل النوع الذي تم تمريره وترجع المؤشر إليه. إذا كان النوع مسجلاً بالفعل ، فسيعيد المؤشر إلى النوع الحالي. هناك أيضًا وظائف ملائمة للحصول على الأنواع البدائية.
بالنسبة للتحويل الضمني بين الأنواع ، ستكون الأرقام قابلة للتحويل إلى سلاسل. لا ينبغي أن يكون الأمر خطيرًا ، لأن التحويل العكسي غير ممكن ، والمشغل الخاص بسلسلة السلسلة مميز عن عامل جمع الأرقام. حتى إذا تمت إزالة هذا التحويل في المراحل اللاحقة من تطور هذه اللغة ، فسيكون بمثابة تمرين جيد في هذه المرحلة. لهذا الغرض ، كان علي تعديل محلل الأرقام ، كما تم تحليله دائمًا . كنقطة عشرية. قد يكون الحرف الأول من عامل التشغيل التسلسلي ..
سياق المترجم
أثناء التجميع ، تحتاج وظائف المترجم المختلفة إلى الحصول على معلومات حول الشفرة التي تم تجميعها حتى الآن. سنحتفظ بهذه المعلومات في فئة compiler_context . نظرًا لأننا على وشك تنفيذ تحليل التعبير ، فسنحتاج إلى استرداد المعلومات حول المعرفات التي نواجهها.
أثناء وقت التشغيل ، سنحتفظ بالمتغيرات في حاويتين مختلفتين. سيكون أحدهما هو حاوية المتغير العام ، والآخر سيكون المكدس. ستنمو المكدس عندما نسمي الوظائف وندخل النطاقات. سوف يتقلص عندما نعود من الوظائف ونترك النطاقات. عندما نسمي بعض الوظائف ، سنقوم بدفع معاملات الوظيفة ، وبعد ذلك سيتم تنفيذ الوظيفة. سيتم دفع قيمة العودة الخاصة به إلى أعلى المكدس عند مغادرته. لذلك ، لكل دالة ، سيبدو المكدس كما يلي:
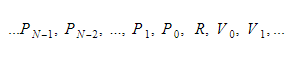
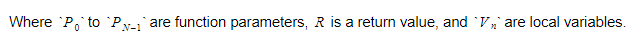
ستحتفظ الوظيفة بالفهرس المطلق لمتغير الإرجاع ، وسيتم العثور على كل متغير أو معلمة بالنسبة لهذا الفهرس.
في الوقت الحالي ، سنتعامل مع الدوال على أنها معرّفات عالمية ثابتة.
هذا هو الفصل الذي يعمل كمعلومات معرف:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; بالنسبة للمتغيرات المحلية ومعلمات الوظيفة ، يُرجع index الوظيفة الفهرس المتعلق بقيمة الإرجاع. تقوم بإرجاع الفهرس العالمي المطلق في حالة المعرفات العالمية.
سيكون لدينا ثلاث عمليات بحث مختلفة عن المعرفات في compile_context :
- البحث عن المعرف العام ، والذي سيحافظ على
compile_contextحسب القيمة ، لأنه هو نفسه في جميع أنحاء التجميع. - البحث عن المعرف المحلي ، باعتباره
unique_ptr، والذي سيكونnullptrفي النطاق العام وسيتم تهيئته في أي دالة. عندما ندخل إلى النطاق ، سيتم تهيئة السياق المحلي الجديد مع السياق القديم باعتباره الأصل. عندما نترك النطاق ، سيتم استبداله بالوالد. - البحث عن معرف الوظيفة ، والذي سيكون المؤشر الأولي. سيكون
nullptrفي النطاق العام ، ونفس قيمة النطاق المحلي الخارجي في أي دالة.
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };شجرة التعبير
عندما يتم تحليل الرموز المميزة للتعبير ، يتم تحويلها إلى شجرة تعبير. على غرار جميع الأشجار ، يتكون هذا أيضًا من عقد.

هناك نوعان مختلفان من العقد:
- العقد الورقية ، والتي يمكن أن تكون:
أ) المعرفات
ب) الأعداد
ج) الخيوط - العقد الداخلية ، والتي تمثل عملية على العقد الفرعية الخاصة بهم. تحافظ على أطفالها مع
unique_ptr.
لكل عقدة ، توجد معلومات حول نوعها وما إذا كانت تُرجع قيمة lvalue أم لا (قيمة يمكن أن تظهر على الجانب الأيسر من عامل التشغيل = ).
عندما يتم إنشاء عقدة داخلية ، ستحاول تحويل أنواع الإرجاع من توابعها إلى الأنواع التي تتوقعها. يُسمح بالتحويلات الضمنية التالية:
- من lvalue إلى non-lvalue
- أي شيء
void -
numberstring
إذا لم يتم السماح بالتحويل ، فسيتم طرح خطأ دلالي.
فيما يلي تعريف الفئة ، بدون بعض الوظائف المساعدة وتفاصيل التنفيذ:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; وظائف الطرق تشرح نفسها بنفسها ، باستثناء وظيفة check_conversion . سيتحقق مما إذا كان النوع قابل للتحويل إلى type_id و lvalue المنطقي من خلال الامتثال لقواعد تحويل النوع وسيقوم بطرح استثناء إذا لم يكن كذلك.
إذا تمت تهيئة العقدة باستخدام std::string ، أو double ، فسيكون نوعه عبارة عن string أو number ، على التوالي ، ولن يكون lvalue. إذا تمت تهيئته بمعرف ، فسوف يفترض نوع هذا المعرف وسيكون قيمة lvalue إذا لم يكن المعرف ثابتًا.
ومع ذلك ، إذا تمت تهيئتها باستخدام عملية عقدة ، فسيعتمد نوعها على العملية ، وأحيانًا على نوع العناصر الفرعية الخاصة بها. لنكتب أنواع التعبير في الجدول. سأستخدم & لاحقة للإشارة إلى قيمة. في الحالات التي يكون فيها للعديد من التعبيرات نفس المعاملة ، سأكتب تعبيرات إضافية بين قوسين دائريين.
العمليات الأحادية
| عملية | نوع العملية | نوع x |
| ++ س (--x) | رقم& | رقم& |
| x ++ (س--) | رقم | رقم& |
| + س (-x ~ س! x) | رقم | رقم |
العمليات الثنائية
| عملية | نوع العملية | نوع x | نوع ص |
| x + y (xy x * yx / yx \ yx٪ y x & y x | yx ^ y x << y x >> y x && y x || y) | رقم | رقم | رقم |
| x == y (x! = y x <y x> y x <= y x> = y) | رقم | رقم أو سلسلة | مثل x |
| x..y | سلسلة | سلسلة | سلسلة |
| س = ص | مثل x | قيمة أي شيء | مثل x ، بدون lvalue |
| x + = y (x- = yx * = yx / = yx \ = yx٪ = y x & = yx | = yx ^ = y x << = y x >> = y) | رقم& | رقم& | رقم |
| س .. = ص | سلسلة& | سلسلة& | سلسلة |
| س ، ص | نفس y | فارغ | اي شى |
| س [ص] | نوع عنصر x | نوع المجموعة | رقم |
العمليات الثلاثية
| عملية | نوع العملية | نوع x | نوع ص | نوع z |
| x؟ y: z | نفس y | رقم | اي شى | نفس y |
استدعاء الوظيفة
عندما يتعلق الأمر باستدعاء الوظيفة ، تصبح الأمور أكثر تعقيدًا بعض الشيء. إذا كانت الوظيفة تحتوي على وسيطات N ، فإن عملية استدعاء الدالة لها N + 1 أبناء ، حيث يكون الطفل الأول هو الوظيفة نفسها ، ويتوافق باقي الأطفال مع وسيطات الوظيفة.
ومع ذلك ، فإننا لن نسمح بتمرير الحجج ضمنيًا بالإشارة. سنطلب من المتصل أن يسبقها بعلامة & . في الوقت الحالي ، لن يكون هذا عاملًا إضافيًا ولكن الطريقة التي يتم بها تحليل استدعاء الوظيفة. إذا لم نقم بتحليل علامة العطف ، فعند توقع الوسيطة ، سنزيل lvalue-ness من تلك الحجة بإضافة عملية أحادية زائفة نسميها node_operation::param . هذه العملية لها نفس نوع العملية التابعة لها ، لكنها ليست قيمة.
بعد ذلك ، عندما نبني العقدة من خلال عملية الاستدعاء هذه ، إذا كانت لدينا وسيطة هي lvalue ولكن لا تتوقعها الوظيفة ، فسننشئ خطأً ، حيث يعني ذلك أن المتصل كتب علامة العطف بطريق الخطأ. من المستغرب إلى حد ما ، أن & ، إذا تم التعامل معها كعامل ، سيكون لها أقل الأسبقية ، لأنها لا تحمل المعنى المعنوي إذا تم تحليلها داخل التعبير. قد نقوم بتغييره لاحقًا.
محلل التعبير
في أحد ادعاءاته حول إمكانات المبرمجين ، قال فيلسوف علوم الكمبيوتر الشهير Edsger Dijkstra ذات مرة:
"من المستحيل عمليًا تعليم البرمجة الجيدة للطلاب الذين سبق لهم التعرض لـ BASIC. بصفتهم مبرمجين محتملين ، فإنهم مشوهون عقليًا بشكل يفوق الأمل في التجديد ".
لذا ، فبالنسبة لكم جميعًا الذين لم تتعرضوا لـ BASIC - كونوا ممتنًا ، لأنكم هربتم من "التشويه العقلي".
البقية منا ، المبرمجين المشوهين ، دعونا نذكر أنفسنا بالأيام التي قمنا فيها بالتشفير في BASIC. كان هناك عامل تشغيل \ ، والذي تم استخدامه للتقسيم المتكامل. في لغة ليس لديك فيها أنواع منفصلة لأرقام الفاصلة المتكاملة والعائمة ، يكون هذا مفيدًا جدًا ، لذلك أضفت نفس المعامل إلى Stork. أضفت أيضًا عامل التشغيل \= ، والذي سيقوم ، كما خمنت ، بإجراء تقسيم متكامل ثم التعيين.
أعتقد أن مثل هؤلاء المشغلين محل تقدير من قبل مبرمجي جافا سكريبت ، على سبيل المثال. لا أريد حتى أن أتخيل ما سيقوله Dijkstra عنهم إذا عاش طويلاً بما يكفي لرؤية تزايد شعبية JS.
بالحديث عن ذلك ، فإن إحدى أكبر المشكلات التي أواجهها مع JavaScript هي تناقض التعبيرات التالية:
- يتم تقييم
"1" - “1”بـ0 - يتم تقييم
"1" * “1”بـ1 - يتم تقييم
"1" / “1”بـ1 - يتم تقييم
"1" + “1”بـ“11”
ثنائي الهيب هوب الكرواتي "ترام 11" ، الذي سمي على اسم ترام يربط بين أحياء زغرب النائية ، كان لهما أغنية تُترجم تقريبًا على النحو التالي: "واحد وواحد ليسا اثنين ، ولكن 11." ظهرت في أواخر التسعينيات ، لذلك لم تكن إشارة إلى JavaScript ، لكنها توضح التناقض جيدًا.
لتجنب هذه التناقضات ، حظرت التحويل الضمني من سلسلة إلى رقم ، وأضفت .. عامل التشغيل للتسلسل (و ..= للتسلسل مع التخصيص). لا أتذكر من أين خطرت لي فكرة هذا العامل. إنه ليس من BASIC أو PHP ، ولن أبحث عن عبارة "Python concatenation" لأن البحث على Google عن أي شيء عن Python يرسل قشعريرة أسفل العمود الفقري. لدي رهاب من الثعابين ، وأدمج ذلك مع "التسلسل" - لا ، شكرًا! ربما لاحقًا ، مع بعض المستعرضات القديمة القائمة على النصوص ، بدون فن ASCII.
لكن عد إلى موضوع هذا القسم - محلل تعبيرنا. سنستخدم تكيفًا لـ "خوارزمية Shunting-yard."
هذه هي الخوارزمية التي تتبادر إلى ذهن أي مبرمج متوسط بعد التفكير في المشكلة لمدة 10 دقائق أو نحو ذلك. يمكن استخدامه لتقييم تعبير infix أو تحويله إلى التدوين البولندي العكسي ، وهو ما لن نفعله.
فكرة الخوارزمية هي قراءة المعاملات والمشغلين من اليسار إلى اليمين. عندما نقرأ المعامل ، ندفعه إلى مكدس المعامل. عندما نقرأ عامل التشغيل ، لا يمكننا تقييمه على الفور ، لأننا لا نعرف ما إذا كان العامل التالي سيكون له أسبقية أفضل من ذلك. لذلك ، نقوم بدفعها إلى كومة المشغل.
ومع ذلك ، نتحقق أولاً مما إذا كان العامل الموجود أعلى المكدس له أسبقية أفضل من العامل الذي قرأناه للتو. في هذه الحالة ، نقوم بتقييم المشغل من أعلى المكدس باستخدام المعاملات في مكدس المعامل. ندفع النتيجة إلى مكدس المعامل. نحتفظ بها حتى نقرأ كل شيء ثم نقوم بتقييم جميع العوامل الموجودة على يسار مكدس المشغل مع المعاملات الموجودة في مكدس المعامل ، مع إعادة النتائج إلى مكدس المعامل حتى نترك بدون عوامل ومعامل واحد فقط ، وهو النتائج.
عندما يكون هناك عاملان لهما نفس الأسبقية ، فسنأخذ العامل الأيسر في حالة كون هذين العاملين مترابطين ؛ وإلا فإننا نأخذ الحق. لا يمكن أن يكون لمشغلين لهما نفس الأولوية ارتباط مختلف.
تتعامل الخوارزمية الأصلية أيضًا مع الأقواس المستديرة ، لكننا سنفعل ذلك بشكل متكرر بدلاً من ذلك ، لأن الخوارزمية ستكون أنظف بهذه الطريقة.
أطلق Edsger Dijkstra على الخوارزمية اسم "Shunting-yard" لأنها تشبه تشغيل ساحة تحويل السكك الحديدية.
ومع ذلك ، فإن خوارزمية ساحة التحويل الأصلية لا تتحقق من الأخطاء تقريبًا ، لذا فمن المحتمل تمامًا أن يتم تحليل تعبير غير صالح كتعبير صحيح. لذلك ، أضفت المتغير المنطقي الذي يتحقق مما إذا كنا نتوقع عاملًا أو معاملًا. إذا كنا نتوقع معاملات ، فيمكننا أيضًا تحليل عوامل البادئة الأحادية. بهذه الطريقة ، لا يمكن أن يمر أي تعبير غير صالح تحت الرادار ، ويكتمل التحقق من بناء جملة التعبير.
تغليف
عندما بدأت في الترميز لهذا الجزء من السلسلة ، خططت للكتابة عن منشئ التعبير. كنت أرغب في بناء تعبير يمكن تقييمه. ومع ذلك ، فقد تبين أن الأمر معقد للغاية بالنسبة إلى منشور مدونة واحد ، لذلك قررت تقسيمه إلى النصف. في هذا الجزء ، انتهينا من تحليل التعبيرات ، وسأكتب عن بناء كائنات التعبيرات في المقالة التالية.
إذا كنت أتذكر بشكل صحيح ، منذ حوالي 15 عامًا ، فقد استغرق الأمر عطلة نهاية أسبوع واحدة لكتابة النسخة الأولى من لغتي الأولى ، مما يجعلني أتساءل ما الخطأ الذي حدث هذه المرة.
في محاولة لإنكار تقدمي في السن وأقل ذكاءً ، سألقي باللوم على ابني البالغ من العمر عامين لأنه متطلب للغاية في أوقات فراغي.
كما هو الحال في الجزء 1 ، فنحن نرحب بك لقراءة الكود أو تنزيله أو حتى تجميعه من صفحة GitHub الخاصة بي.