
Stork, Partea 2: Crearea unui analizator de expresii
Publicat: 2022-03-11În această parte a seriei noastre, vom acoperi una dintre componentele mai complicate (cel puțin în opinia mea) ale scriptării unui motor de limbaj, care este un element esențial pentru fiecare limbaj de programare: parserul de expresii.
O întrebare pe care un cititor ar putea să o pună – și pe bună dreptate – este: de ce nu folosim pur și simplu niște instrumente sau biblioteci sofisticate, ceva ce avem deja la dispoziție?
De ce nu folosim Lex, YACC, Bison, Boost Spirit sau cel puțin expresii regulate?
De-a lungul relației noastre, soția mea a observat o trăsătură a mea pe care nu o pot nega: de fiecare dată când mă confrunt cu o întrebare dificilă, fac o listă. Dacă vă gândiți bine, este perfect logic - folosesc cantitatea pentru a compensa lipsa de calitate a răspunsului meu.
O sa fac acelasi lucru si acum.
- Vreau să folosesc C++ standard. În acest caz, acesta va fi C++17. Cred că limbajul este destul de bogat în sine și mă lupt cu dorința de a adăuga în amestec altceva decât biblioteca standard.
- Când am dezvoltat primul meu limbaj de scripting, nu am folosit niciun instrument sofisticat. Eram sub presiune și într-un termen limită strâns, dar nu știam cum să folosesc Lex, YACC sau ceva similar. Prin urmare, am decis să dezvolt totul manual.
- Mai târziu, am găsit un blog al unui dezvoltator de limbaje de programare cu experiență, care a sfătuit să nu folosească oricare dintre aceste instrumente. El a spus că aceste instrumente rezolvă partea mai ușoară a dezvoltării limbajului, așa că, în orice caz, rămâi cu lucrurile dificile. Nu pot găsi acel blog acum, așa cum era cu mult timp în urmă, când atât internetul, cât și eu eram tineri.
- În același timp, a existat o meme care spunea: „Ai o problemă pe care decizi să o rezolvi folosind expresii regulate. Acum ai două probleme.”
- Nu cunosc Lex, YACC, Bison sau ceva asemănător. Cunosc Boost Spirit și este o bibliotecă la îndemână și uimitoare, dar încă prefer să am un control mai bun asupra parserului.
- Îmi place să fac acele componente manual. De fapt, aș putea doar să dau acest răspuns și să elimin complet această listă.
Codul complet este disponibil pe pagina mea GitHub.
Token Iterator
Există unele modificări ale codului din partea 1.
Acestea sunt în mare parte remedieri simple și modificări mici, dar o adăugare importantă la codul de analizare existent este clasa token_iterator . Ne permite să evaluăm jetonul curent fără a-l elimina din flux, ceea ce este foarte util.
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; Este inițializat cu push_back_stream și apoi poate fi dereferențiat și incrementat. Poate fi verificat cu bool cast explicit, care va fi evaluat ca fals atunci când jetonul curent este egal cu eof.
Limbaj tipizat static sau dinamic?
Există o decizie pe care trebuie să o iau în această parte: va fi acest limbaj tipizat static sau dinamic?
Un limbaj tipizat static este un limbaj care verifică tipurile variabilelor sale în momentul compilării.
Un limbaj tatat dinamic , pe de altă parte, nu îl verifică în timpul compilării (dacă există o compilare, ceea ce nu este obligatoriu pentru un limbaj tatat dinamic), ci în timpul execuției. Prin urmare, erorile potențiale pot rămâne în cod până când sunt lovite.
Acesta este un avantaj evident al limbajelor tipizate static. Tuturor le place să-și surprindă erorile cât mai curând posibil. Întotdeauna m-am întrebat care este cel mai mare avantaj al limbilor cu tastare dinamică, iar răspunsul m-a frapat în ultimele două săptămâni: este mult mai ușor de dezvoltat!
Limbajul anterior pe care l-am dezvoltat a fost tastat dinamic. Am fost mai mult sau mai puțin mulțumit de rezultat, iar scrierea analizei expresiei nu a fost prea dificilă. Practic, nu trebuie să verificați tipurile de variabile și vă bazați pe erori de rulare, pe care le codificați aproape spontan.
De exemplu, dacă trebuie să scrieți operatorul binar + și doriți să o faceți pentru numere, trebuie doar să evaluați ambele părți ale acelui operator ca numere în timpul de execuție. Dacă oricare dintre părți nu poate evalua numărul, trebuie doar să aruncați o excepție. Am implementat chiar și supraîncărcarea operatorilor verificând informațiile de tipul de rulare ale variabilelor dintr-o expresie, iar operatorii au făcut parte din acele informații de rulare.
În primul limbaj pe care l-am dezvoltat (acesta este al treilea al meu), am făcut verificarea tipului în momentul compilării, dar nu profitasem la maximum de asta. Evaluarea expresiei depindea încă de informațiile despre tipul de rulare.
Acum, am decis să dezvolt un limbaj tipizat static și sa dovedit a fi o sarcină mult mai grea decât mă așteptam. Cu toate acestea, din moment ce nu intenționez să-l compilez într-un cod binar sau orice fel de cod de asamblare emulat, un anumit tip de informații vor exista implicit în codul compilat.
Tipuri
Ca un minim strict de tipuri pe care trebuie să le sprijinim, vom începe cu următoarele:
- Numerele
- Siruri de caractere
- Funcții
- Matrice
Deși le putem adăuga în continuare, nu vom suporta structuri (sau clase, înregistrări, tupluri etc.) la început. Totuși, vom ține cont de faptul că le putem adăuga ulterior, așa că nu ne vom pecetlui soarta cu decizii greu de schimbat.
În primul rând, am vrut să definesc tipul ca șir, care va urma anumite convenții. Fiecare identificator ar păstra acel șir după valoare în momentul compilării și va trebui să-l analizăm uneori. De exemplu, dacă codificăm tipul de matrice de numere ca „[număr]”, atunci va trebui să tăiem primul și ultimul caracter pentru a obține un tip interior, care este „număr” în acest caz. Este o idee destul de proastă dacă te gândești la asta.
Apoi, am încercat să-l implementez ca o clasă. Acea clasă ar avea toate informațiile despre tip. Fiecare identificator ar păstra un pointer partajat către acea clasă. În cele din urmă, m-am gândit să am registrul de toate tipurile folosit în timpul compilării, astfel încât fiecare identificator să aibă indicatorul brut către tipul său.
Mi-a plăcut ideea asta, așa că am ajuns la următoarele:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;Tipurile simple sunt membri ai enumerarii:
enum struct simple_type { nothing, number, string, }; Membrul de enumerare nothing este aici ca substituent pentru void , pe care nu îl pot folosi deoarece este un cuvânt cheie în C++.
Tipurile de matrice sunt reprezentate cu structura având singurul membru al type_handle .
struct array_type { type_handle inner_type_id; }; Evident, lungimea matricei nu face parte din array_type , așa că matricele vor crește dinamic. Asta înseamnă că vom ajunge cu std::deque sau ceva asemănător, dar ne vom ocupa de asta mai târziu.
Un tip de funcție este compus din tipul său returnat, tipul fiecăruia dintre parametrii săi și dacă fiecare dintre acești parametri este sau nu transmis prin valoare sau prin referință.
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };Acum, putem defini clasa care va păstra aceste tipuri.
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; Tipurile sunt păstrate în std::set , deoarece acel container este stabil, ceea ce înseamnă că pointerii către membrii săi sunt validi chiar și după ce sunt introduse noi tipuri. Există funcția get_handle , care înregistrează tipul trecut și returnează pointerul la acesta. Dacă tipul este deja înregistrat, va returna indicatorul la tipul existent. Există, de asemenea, funcții de confort pentru a obține tipuri primitive.
În ceea ce privește conversia implicită între tipuri, numerele vor fi convertibile în șiruri. Nu ar trebui să fie periculos, deoarece o conversie inversă nu este posibilă, iar operatorul pentru concatenarea șirurilor este distinct de cel pentru adăugarea numerelor. Chiar dacă această conversie este eliminată în etapele ulterioare ale dezvoltării acestui limbaj, va servi bine ca exercițiu în acest moment. În acest scop, a trebuit să modific analizatorul de numere, deoarece a analizat întotdeauna . ca punct zecimal. Poate fi primul caracter al operatorului de concatenare .. .
Contextul compilatorului
În timpul compilării, diferite funcții ale compilatorului trebuie să obțină informații despre codul compilat până acum. Vom păstra acele informații într-o clasă compiler_context . Deoarece suntem pe cale să implementăm analiza expresiei, va trebui să recuperăm informații despre identificatorii pe care îi întâlnim.
În timpul rulării, vom păstra variabilele în două containere diferite. Unul dintre ele va fi containerul de variabile globale, iar altul va fi stiva. Stiva va crește pe măsură ce apelăm funcții și intrăm în domenii. Se va micșora pe măsură ce ne întoarcem de la funcții și părăsim domeniile. Când apelăm o funcție, vom împinge parametrii funcției, iar apoi funcția se va executa. Valoarea sa de returnare va fi împinsă în partea de sus a stivei când pleacă. Prin urmare, pentru fiecare funcție, stiva va arăta astfel:
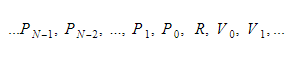
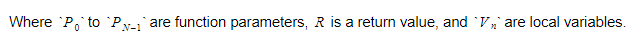
Funcția va păstra indicele absolut al variabilei returnate, iar fiecare variabilă sau parametru va fi găsit relativ la acel indice.
Pentru moment, vom trata funcțiile ca identificatori globali constanți.
Aceasta este clasa care servește ca informații de identificare:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; Pentru variabilele locale și parametrii funcției, funcția index returnează indicele relativ la valoarea returnată. Returnează indexul global absolut în cazul identificatorilor globali.
Vom avea trei căutări diferite de identificare în compile_context :
- Căutare globală a identificatorului, care va păstra
compile_contextdupă valoare, deoarece este aceeași pe toată durata compilației. - Căutarea identificatorului local, ca
unique_ptr, care va finullptrîn domeniul global și va fi inițializat în orice funcție. Ori de câte ori intrăm în domeniu, noul context local va fi inițializat cu cel vechi ca părinte. Când părăsim domeniul de aplicare, acesta va fi înlocuit de părintele său. - Căutare identificator de funcție, care va fi indicatorul brut. Va fi
nullptrîn domeniul global și aceeași valoare ca domeniul local cel mai exterior în orice funcție.
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };Arborele de expresie
Când simbolurile de expresie sunt analizate, acestea sunt convertite într-un arbore de expresie. Similar tuturor copacilor, acesta este format din noduri.

Există două tipuri diferite de noduri:
- Nodurile frunzelor, care pot fi:
a) Identificatori
b) Numerele
c) Coarde - Nodurile interne, care reprezintă o operație asupra nodurilor lor fii. Își păstrează copiii cu
unique_ptr.
Pentru fiecare nod, există informații despre tipul său și dacă returnează sau nu o valoare l (o valoare care poate apărea în partea stângă a operatorului = ).
Când este creat un nod interior, acesta va încerca să convertească tipurile returnate ale copiilor săi în tipurile pe care le așteaptă. Sunt permise următoarele conversii implicite:
- lvalue la non-lvalue
- Orice de
void -
numberînstring
Dacă conversia nu este permisă, va fi generată o eroare semantică.
Iată definiția clasei, fără câteva funcții de ajutor și detalii de implementare:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; Funcționalitatea metodelor se explică de la sine, cu excepția funcției check_conversion . Acesta va verifica dacă tipul este convertibil la type_id și boolean lvalue transmis, respectând regulile de conversie a tipului și va arunca o excepție dacă nu este.
Dacă un nod este inițializat cu std::string sau double , tipul său va fi string sau, respectiv, number și nu va fi o valoare l. Dacă este inițializat cu un identificator, va presupune tipul acelui identificator și va fi o valoare l dacă identificatorul nu este constant.
Dacă este inițializat, totuși, cu o operație de nod, tipul său va depinde de operație și, uneori, de tipul copiilor săi. Să scriem tipurile de expresii în tabel. Voi folosi & sufix pentru a desemna o valoare l. În cazurile în care mai multe expresii au același tratament, voi scrie expresii suplimentare între paranteze rotunde.
Operații unare
| Operațiune | Tipul operațiunii | tip x |
| ++x (--x) | număr& | număr& |
| x++ (x--) | număr | număr& |
| +x (-x ~x !x) | număr | număr |
Operații binare
| Operațiune | Tipul operațiunii | tip x | tipul y |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | număr | număr | număr |
| x==y (x!=y x<y x>y x<=y x>=y) | număr | număr sau șir | la fel ca x |
| X y | şir | şir | şir |
| x=y | la fel ca x | valoarea a orice | la fel ca x, fără lvalue |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | număr& | număr& | număr |
| x..=y | şir& | şir& | şir |
| X y | la fel ca si y | gol | orice |
| X y] | tipul de element x | tip de matrice | număr |
Operațiuni ternare
| Operațiune | Tipul operațiunii | tip x | tipul y | tipul z |
| x?y:z | la fel ca si y | număr | orice | la fel ca si y |
Apel de funcție
Când vine vorba de apelul de funcție, lucrurile devin puțin mai complicate. Dacă funcția are N argumente, operația de apelare a funcției are N+1 copii, unde primul copil este funcția însăși, iar restul copiilor corespund argumentelor funcției.
Cu toate acestea, nu vom permite trecerea implicită a argumentelor prin referință. Vom solicita apelantului să le prefixeze semnul & . Deocamdată, acesta nu va fi un operator suplimentar, ci modul în care este analizat apelul de funcție. Dacă nu analizăm ampersand, atunci când argumentul este așteptat, vom elimina lvalue-ness din acel argument adăugând o operație unară falsă pe care o numim node_operation::param . Operația respectivă are același tip ca și copilul său, dar nu este o valoare l.
Apoi, când construim nodul cu acea operație de apel, dacă avem un argument care este lvalue, dar care nu este așteptat de funcție, vom genera o eroare, deoarece înseamnă că apelantul a tastat accidental și ampersand. Oarecum surprinzător, că & , dacă este tratat ca un operator, ar avea cea mai mică prioritate, deoarece nu are sensul semantic dacă este analizat în interiorul expresiei. S-ar putea să o schimbăm mai târziu.
Analizator de expresii
Într-una dintre afirmațiile sale despre potențialul programatorilor, celebrul filozof al informaticii Edsger Dijkstra a spus odată:
„Este practic imposibil să predați programare bună studenților care au avut o expunere anterioară la BASIC. Ca potențiali programatori, ei sunt mutilați mental dincolo de speranța de regenerare.”
Așadar, pentru toți cei care nu au fost expuși la BASIC - fiți recunoscători, deoarece ați scăpat de „mutilarea mentală”.
Noi ceilalți, programatori mutilați, să ne amintim de vremurile când codificam în BASIC. A existat un operator \ , care a fost folosit pentru împărțirea integrală. Într-o limbă în care nu aveți tipuri separate pentru numere integrale și în virgulă mobilă, este destul de util, așa că am adăugat același operator la Stork. Am adăugat și operatorul \= , care, după cum ați ghicit, va efectua diviziunea integrală și apoi va atribui.
Cred că astfel de operatori ar fi apreciați de programatorii JavaScript, de exemplu. Nici nu vreau să-mi imaginez ce ar spune Dijkstra despre ei dacă ar trăi suficient pentru a vedea popularitatea în creștere a lui JS.
Apropo de asta, una dintre cele mai mari probleme pe care le am cu JavaScript este discrepanța următoarelor expresii:
-
"1" - “1”se evaluează la0 -
"1" * “1”se evaluează la1 -
"1" / “1”se evaluează la1 -
"1" + “1”se evaluează la“11”
Duo-ul croat de hip-hop „Tram 11”, numit după un tramvai care face legătura între cartierele din periferia Zagrebului, a avut un cântec care se traduce aproximativ prin: „Unu și unu nu sunt doi, ci 11”. A apărut la sfârșitul anilor 90, deci nu era o referire la JavaScript, dar ilustrează destul de bine discrepanța.
Pentru a evita aceste discrepanțe, am interzis conversia implicită din șir în număr și am adăugat operator .. pentru concatenare (și ..= pentru concatenarea cu atribuire). Nu-mi amintesc de unde mi-a venit ideea pentru acel operator. Nu este de la BASIC sau PHP și nu voi căuta expresia „concatenare Python”, deoarece căutarea pe Google despre Python îmi dă fiori pe coloana vertebrală. Am o fobie de șerpi și combinând asta cu „concatenarea” - nu, mulțumesc! Poate mai târziu, cu un browser arhaic bazat pe text, fără artă ASCII.
Dar să revenim la subiectul acestei secțiuni - analizatorul nostru de expresii. Vom folosi o adaptare a „Algoritmului de manevră”.
Acesta este algoritmul care vine în minte oricărui programator obișnuit după ce s-a gândit la problemă timp de 10 minute sau cam asa ceva. Poate fi folosit pentru a evalua o expresie infixă sau pentru a o transforma în notația poloneză inversă, ceea ce nu vom face.
Ideea algoritmului este de a citi operanzi și operatori de la stânga la dreapta. Când citim un operand, îl împingem în stiva de operanzi. Când citim un operator, nu îl putem evalua imediat, deoarece nu știm dacă următorul operator va avea o prioritate mai bună decât acela. Prin urmare, îl împingem la stiva de operator.
Cu toate acestea, verificăm mai întâi dacă operatorul din partea de sus a stivei are o prioritate mai bună decât cel pe care tocmai l-am citit. În acest caz, evaluăm operatorul din partea de sus a stivei cu operanzi pe stiva de operanzi. Împingem rezultatul în stiva de operanzi. Îl păstrăm până când citim totul și apoi evaluăm toți operatorii din stânga stivei de operatori cu operanzii din stiva de operanzi, împingând rezultatele înapoi pe stiva de operanzi până când rămânem fără operatori și cu un singur operand, care este Rezultatul.
Când doi operatori au aceeași prioritate, îl vom lua pe cel din stânga în cazul în care acești operatori sunt asociativi stângi; altfel, o luăm pe cea potrivită. Doi operatori cu aceeași precedență nu pot avea asociativitate diferită.
Algoritmul original tratează și parantezele rotunde, dar o vom face recursiv în schimb, deoarece algoritmul va fi mai curat în acest fel.
Edsger Dijkstra a numit algoritmul „Shunting-yard” deoarece seamănă cu funcționarea unei șantiere de manevră feroviară.
Cu toate acestea, algoritmul inițial de manevră-yard nu face aproape nicio verificare a erorilor, așa că este foarte posibil ca o expresie invalidă să fie analizată ca una corectă. Prin urmare, am adăugat variabila booleană care verifică dacă ne așteptăm la un operator sau un operand. Dacă ne așteptăm la operanzi, putem analiza și operatorii de prefix unari. În acest fel, nicio expresie nevalidă nu poate trece sub radar, iar verificarea sintaxei expresiei este completă.
Încheierea
Când am început să codific pentru această parte a seriei, am plănuit să scriu despre constructorul de expresii. Am vrut să construiesc o expresie care să poată fi evaluată. Cu toate acestea, sa dovedit a fi mult prea complicat pentru o postare pe blog, așa că am decis să o împart în jumătate. În această parte, am încheiat analiza expresiilor și voi scrie despre construirea obiectelor expresii în articolul următor.
Dacă îmi amintesc bine, acum vreo 15 ani, mi-a luat un weekend să scriu prima versiune a primei mele limbi, ceea ce mă face să mă întreb ce a mers prost de data aceasta.
În efortul de a nega că îmbătrânesc și sunt mai puțin spiritual, îi voi învinovăți pe fiul meu de doi ani pentru că este prea exigent în timpul meu liber.
Ca și în partea 1, sunteți binevenit să citiți, să descărcați sau chiar să compilați codul de pe pagina mea GitHub.