
황새, 파트 2: 표현식 파서 생성
게시 됨: 2022-03-11시리즈의 이 부분에서는 모든 프로그래밍 언어의 필수 구성 요소인 언어 엔진 스크립팅의 까다로운(적어도 제 생각에는) 구성 요소 중 하나인 표현식 파서를 다룰 것입니다.
독자가 던질 수 있는 질문은 정당합니다. 이미 사용할 수 있는 정교한 도구나 라이브러리를 사용하지 않는 이유는 무엇입니까?
Lex, YACC, Bison, Boost Spirit 또는 최소한 정규 표현식을 사용하지 않는 이유는 무엇입니까?
우리의 관계를 통해 아내는 내가 부인할 수 없는 나의 특성을 알아차렸습니다. 어려운 질문에 직면할 때마다 나는 목록을 작성합니다. 생각해보면 이해가 됩니다. 답변의 질적 부족을 보완하기 위해 양을 사용하고 있습니다.
나는 지금 같은 일을 할 것입니다.
- 표준 C++를 사용하고 싶습니다. 이 경우 C++17이 됩니다. 나는 언어 자체가 상당히 풍부하다고 생각하며 표준 라이브러리 외에 다른 것을 추가하려는 충동과 싸우고 있습니다.
- 첫 번째 스크립팅 언어를 개발할 때 정교한 도구를 사용하지 않았습니다. 나는 압박을 받고 촉박한 마감일을 맞았지만 Lex, YACC 또는 이와 유사한 것을 사용하는 방법을 몰랐습니다. 따라서 모든 것을 수동으로 개발하기로 결정했습니다.
- 나중에 이러한 도구를 사용하지 말라고 조언한 경험 많은 프로그래밍 언어 개발자의 블로그를 찾았습니다. 그는 이러한 도구가 언어 개발의 더 쉬운 부분을 해결하므로 어쨌든 어려운 부분이 남아 있다고 말했습니다. 지금은 그 블로그를 찾을 수 없습니다. 오래전 인터넷과 제가 젊었을 때였기 때문입니다.
- 동시에 "정규 표현식을 사용하여 해결하기로 결정한 문제가 있습니다. 이제 두 가지 문제가 있습니다.”
- 나는 Lex, YACC, Bison 또는 이와 유사한 것을 모릅니다. 나는 Boost Spirit을 알고 있고 그것은 편리하고 놀라운 라이브러리이지만 나는 여전히 파서를 더 잘 제어하는 것을 선호합니다.
- 저는 이러한 구성 요소를 수동으로 수행하는 것을 좋아합니다. 사실, 나는 이 대답을 하고 이 목록을 완전히 제거할 수 있습니다.
전체 코드는 내 GitHub 페이지에서 사용할 수 있습니다.
토큰 반복자
1부에서 코드가 약간 변경되었습니다.
이것들은 대부분 간단한 수정과 작은 변경이지만 기존 구문 분석 코드에 대한 중요한 추가 사항 중 하나는 token_iterator 클래스입니다. 스트림에서 제거하지 않고 현재 토큰을 평가할 수 있어 정말 편리합니다.
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; push_back_stream 으로 초기화된 다음 역참조 및 증가될 수 있습니다. 현재 토큰이 eof와 같을 때 false로 평가되는 명시적 bool 캐스트로 확인할 수 있습니다.
정적 또는 동적 형식 언어?
이 부분에서 결정해야 하는 한 가지가 있습니다. 이 언어를 정적으로 입력할까요 아니면 동적으로 입력할까요?
정적 형식 언어는 컴파일 시 해당 변수의 형식을 확인하는 언어입니다.
반면에 동적으로 유형 이 지정된 언어는 컴파일 중에(동적으로 유형이 지정된 언어에 필수가 아닌 컴파일이 있는 경우) 실행 중에 확인하지 않습니다. 따라서 잠재적인 오류는 적중될 때까지 코드에 존재할 수 있습니다.
이것은 정적으로 유형이 지정된 언어의 명백한 이점입니다. 누구나 가능한 한 빨리 자신의 오류를 파악하는 것을 좋아합니다. 저는 항상 동적으로 유형이 지정된 언어의 가장 큰 장점이 무엇인지 궁금했는데 지난 몇 주 동안 그 대답이 저를 놀라게 했습니다. 개발하기가 훨씬 쉽습니다!
내가 개발한 이전 언어는 동적으로 입력되었습니다. 나는 그 결과에 다소 만족했고 표현식 파서를 작성하는 것은 그리 어렵지 않았다. 기본적으로 변수 유형을 확인할 필요가 없으며 거의 자발적으로 코딩하는 런타임 오류에 의존합니다.
예를 들어 이진 + 연산자를 작성해야 하고 숫자에 대해 수행하려는 경우 런타임에서 해당 연산자의 양쪽을 숫자로 평가하기만 하면 됩니다. 양쪽 중 하나가 숫자를 평가할 수 없으면 예외를 throw합니다. 표현식에서 변수의 런타임 유형 정보를 확인하여 연산자 오버로딩을 구현하기도 했으며 연산자도 해당 런타임 정보의 일부였습니다.
내가 개발한 첫 번째 언어(이것이 세 번째 언어임)에서 컴파일할 때 유형 검사를 수행했지만 이를 충분히 활용하지 못했습니다. 표현식 평가는 여전히 런타임 유형 정보에 의존했습니다.
이제 정적 형식 언어를 개발하기로 결정했는데 예상보다 훨씬 어려운 작업이었습니다. 그러나 바이너리 또는 모든 종류의 에뮬레이트된 어셈블리 코드로 컴파일할 계획이 없기 때문에 일부 유형의 정보는 컴파일된 코드에 암시적으로 존재합니다.
유형
지원해야 하는 최소한의 유형으로 다음부터 시작합니다.
- 숫자
- 문자열
- 기능
- 배열
앞으로 추가할 수 있지만 처음에는 구조(또는 클래스, 레코드, 튜플 등)를 지원하지 않습니다. 다만 추후 추가될 수 있음을 유념하여 변경하기 어려운 결정으로 운명을 봉인하지는 않겠습니다.
먼저 유형을 문자열로 정의하고 싶었습니다. 이는 일부 규칙을 따를 것입니다. 모든 식별자는 컴파일 시 해당 문자열을 값으로 유지하며 때때로 구문 분석해야 합니다. 예를 들어 숫자 배열 유형을 "[숫자]"로 인코딩하면 내부 유형(이 경우 "숫자")을 얻기 위해 첫 번째 문자와 마지막 문자를 잘라야 합니다. 생각해보면 참 안 좋은 생각입니다.
그런 다음 클래스로 구현하려고했습니다. 해당 클래스에는 유형에 대한 모든 정보가 있습니다. 각 식별자는 해당 클래스에 대한 공유 포인터를 유지합니다. 결국 컴파일하는 동안 모든 유형의 레지스트리를 사용하여 각 식별자에 해당 유형에 대한 원시 포인터가 있어야 한다고 생각했습니다.
나는 그 아이디어가 마음에 들어서 다음과 같이 결론을 내렸습니다.
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;단순 유형은 열거형의 구성원입니다.
enum struct simple_type { nothing, number, string, }; 열거형 멤버 nothing 은 C++의 키워드이므로 사용할 수 없는 void 에 대한 자리 표시자로 여기에 없습니다.
배열 유형은 type_handle 의 유일한 멤버가 있는 구조로 표시됩니다.
struct array_type { type_handle inner_type_id; }; 분명히 배열 길이는 array_type 의 일부가 아니므로 배열은 동적으로 커집니다. 이것은 우리가 std::deque 또는 이와 유사한 것으로 끝날 것이라는 것을 의미하지만 나중에 다룰 것입니다.
함수 유형은 반환 유형, 각 매개변수의 유형, 각 매개변수가 값으로 또는 참조로 전달되는지 여부로 구성됩니다.
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };이제 이러한 유형을 유지할 클래스를 정의할 수 있습니다.
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; 컨테이너가 안정적이므로 std::set 에 유형이 유지됩니다. 즉, 새 유형이 삽입된 후에도 해당 멤버에 대한 포인터가 유효합니다. 전달된 유형을 등록하고 해당 유형에 대한 포인터를 반환하는 get_handle 함수가 있습니다. 유형이 이미 등록된 경우 기존 유형에 대한 포인터를 반환합니다. 기본 유형을 가져오는 편리한 함수도 있습니다.
유형 간의 암시적 변환의 경우 숫자를 문자열로 변환할 수 있습니다. 역변환이 불가능하고 문자열 연결 연산자가 숫자 덧셈 연산자와 구별되므로 위험하지 않아야 합니다. 이 변환이 이 언어 개발의 후반 단계에서 제거되더라도 이 시점에서 연습으로 잘 사용될 것입니다. 이를 위해 항상 parsed 하는 숫자 파서를 수정해야 했습니다 . 소수점으로. 연결 연산자의 첫 번째 문자일 수 있습니다 ..
컴파일러 컨텍스트
컴파일하는 동안 다른 컴파일러 함수는 지금까지 컴파일된 코드에 대한 정보를 가져와야 합니다. 우리는 해당 정보를 compiler_context 클래스에 보관할 것입니다. 표현식 구문 분석을 구현하려고 하기 때문에 마주치는 식별자에 대한 정보를 검색해야 합니다.
런타임 동안 변수를 두 개의 다른 컨테이너에 보관합니다. 그 중 하나는 전역 변수 컨테이너이고 다른 하나는 스택입니다. 함수를 호출하고 범위를 입력하면 스택이 커집니다. 함수에서 돌아와 범위를 벗어나면 축소됩니다. 어떤 함수를 호출할 때 함수 매개변수를 푸시하면 함수가 실행됩니다. 반환 값은 떠날 때 스택의 맨 위로 푸시됩니다. 따라서 각 함수에 대해 스택은 다음과 같습니다.
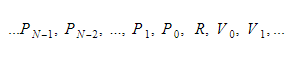
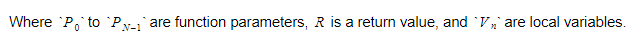
함수는 반환 변수의 절대 인덱스를 유지하고 각 변수 또는 매개변수는 해당 인덱스를 기준으로 찾습니다.
지금은 함수를 상수 전역 식별자로 취급합니다.
다음은 식별자 정보 역할을 하는 클래스입니다.
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; 지역 변수 및 함수 매개변수의 경우 함수 index 는 반환 값에 상대적인 인덱스를 반환합니다. 전역 식별자의 경우 절대 전역 인덱스를 반환합니다.
compile_context 에 세 가지 다른 식별자 조회가 있습니다.
- 전체 컴파일에서 동일하므로
compile_context가 값으로 유지되는 전역 식별자 조회입니다. -
unique_ptr로 로컬 식별자 조회는 전역 범위에서nullptr이 되고 모든 함수에서 초기화됩니다. 범위에 들어갈 때마다 새 로컬 컨텍스트는 이전 컨텍스트를 상위 컨텍스트로 사용하여 초기화됩니다. 범위를 벗어나면 상위 항목으로 대체됩니다. - 원시 포인터가 될 함수 식별자 조회. 전역 범위에서는
nullptr이고 모든 함수에서 가장 바깥쪽 지역 범위와 동일한 값입니다.
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };표현식 트리
표현식 토큰이 구문 분석되면 표현식 트리로 변환됩니다. 모든 트리와 마찬가지로 이 트리도 노드로 구성됩니다.

두 가지 다른 종류의 노드가 있습니다.
- 다음과 같은 리프 노드:
a) 식별자
b) 숫자
c) 문자열 - 자식 노드에 대한 작업을 나타내는 내부 노드. 자식을
unique_ptr로 유지합니다.
각 노드에 대해 해당 유형 및 lvalue( = 연산자의 왼쪽에 나타날 수 있는 값)를 반환하는지 여부에 대한 정보가 있습니다.
내부 노드가 생성되면 자식의 반환 유형을 예상하는 유형으로 변환하려고 시도합니다. 다음과 같은 암시적 변환이 허용됩니다.
- lvalue에서 non-lvalue로
-
void할 것은 무엇이든 -
number를string로
변환이 허용되지 않으면 의미 오류가 발생합니다.
다음은 일부 도우미 함수 및 구현 세부 정보가 없는 클래스 정의입니다.
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; 메서드의 기능은 check_conversion 기능을 제외하고는 자명합니다. 유형 변환 규칙을 준수하여 유형이 전달된 type_id 및 부울 lvalue 로 변환 가능한지 확인하고 그렇지 않은 경우 예외를 throw합니다.
노드가 std::string 또는 double 로 초기화되면 해당 유형은 각각 string 또는 number 이고 lvalue가 아닙니다. 식별자로 초기화되면 해당 식별자의 유형을 가정하고 식별자가 일정하지 않으면 lvalue가 됩니다.
그러나 노드 작업으로 초기화되는 경우 해당 유형은 작업에 따라 달라지며 때로는 자식 유형에 따라 달라집니다. 표에 표현식 유형을 작성해 보겠습니다. 나는 lvalue를 나타내기 위해 & 접미사를 사용할 것입니다. 여러 표현식이 같은 처리를 하는 경우에는 추가 표현식을 대괄호로 묶습니다.
단항 연산
| 작업 | 작업 유형 | x 유형 |
| ++x(--x) | 숫자& | 숫자& |
| x++(x--) | 숫자 | 숫자& |
| +x (-x ~x !x) | 숫자 | 숫자 |
이진 연산
| 작업 | 작업 유형 | x 유형 | Y형 |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | 숫자 | 숫자 | 숫자 |
| x==y (x!=y x<y x>y x<=y x>=y) | 숫자 | 숫자 또는 문자열 | x와 동일 |
| x..y | 끈 | 끈 | 끈 |
| x=y | x와 동일 | 모든 것의 가치 | lvalue가 없는 x와 동일 |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | 숫자& | 숫자& | 숫자 |
| x..=y | 끈& | 끈& | 끈 |
| x,y | y와 동일 | 무효의 | 아무것 |
| x[y] | x의 요소 유형 | 배열 유형 | 숫자 |
삼항 연산
| 작업 | 작업 유형 | x 유형 | Y형 | Z 유형 |
| x?y:z | y와 동일 | 숫자 | 아무것 | y와 동일 |
함수 호출
함수 호출에 관해서는 상황이 조금 더 복잡해집니다. 함수에 N개의 인수가 있는 경우 함수 호출 작업에는 N+1개의 하위가 있습니다. 여기서 첫 번째 하위는 함수 자체이고 나머지 하위는 함수 인수에 해당합니다.
그러나 암시적으로 참조로 인수를 전달하는 것은 허용하지 않습니다. 호출자에게 & 기호를 접두어로 붙이도록 요구할 것입니다. 현재로서는 추가 연산자가 아니라 함수 호출이 구문 분석되는 방식입니다. 앰퍼샌드를 구문 분석하지 않으면 인수가 예상될 때 node_operation::param 이라고 하는 가짜 단항 연산을 추가하여 해당 인수에서 lvalue-ness를 제거합니다. 해당 작업은 자식과 동일한 유형을 갖지만 lvalue가 아닙니다.
그런 다음 해당 호출 작업으로 노드를 빌드할 때 lvalue인 인수가 있지만 함수에서 예상하지 않은 경우 호출자가 실수로 앰퍼샌드를 입력했음을 의미하므로 오류가 생성됩니다. 다소 놀랍게도, 그 & 는 연산자로 취급될 경우 가장 우선 순위가 낮습니다. 표현식 내부에서 구문 분석하면 의미상 의미가 없기 때문입니다. 나중에 변경할 수 있습니다.
표현식 파서
프로그래머의 잠재력에 대한 그의 주장 중 하나에서 유명한 컴퓨터 과학 철학자 Edsger Dijkstra는 다음과 같이 말했습니다.
“BASIC에 대한 사전 경험이 있는 학생들에게 좋은 프로그래밍을 가르치는 것은 사실상 불가능합니다. 잠재적인 프로그래머로서 그들은 재생의 희망을 넘어서 정신적으로 훼손되었습니다.”
따라서 BASIC에 노출되지 않은 여러분 모두에게 감사합니다. "정신적 절단"에서 벗어났기 때문입니다.
절단된 프로그래머인 나머지 우리는 BASIC으로 코딩하던 시절을 상기해 봅시다. 적분 나눗셈에 사용되는 연산자 \ 가 있었습니다. 정수 및 부동 소수점 숫자에 대해 별도의 유형이 없는 언어에서는 매우 편리하므로 동일한 연산자를 Stork에 추가했습니다. 나는 또한 연산자 \= 를 추가했는데, 이 연산자는 추측한 대로 적분 나누기를 수행한 다음 할당합니다.
예를 들어 JavaScript 프로그래머는 그러한 연산자를 높이 평가할 것이라고 생각합니다. Dijkstra가 JS의 인기 상승을 볼 수 있을 만큼 오래 살았다면 그들에 대해 뭐라고 말할지 상상조차 하고 싶지 않습니다.
말하자면 JavaScript에 대한 가장 큰 문제 중 하나는 다음 표현식의 불일치입니다.
-
"1" - “1”은0으로 평가됩니다. -
"1" * “1”은1로 평가됩니다. -
"1" / “1”은1로 평가됩니다. -
"1" + “1”은“11”로 평가됩니다.
크로아티아의 힙합 듀오 "Tram 11"은 자그레브의 외곽 자치구를 연결하는 트램의 이름을 따서 명명되었으며 대략 "하나와 하나는 둘이 아니라 11입니다" 로 번역되는 노래가 있습니다. 90년대 후반에 나왔기 때문에 자바스크립트에 대한 언급은 아니었지만 그 차이를 잘 보여주고 있습니다.
이러한 불일치를 피하기 위해 문자열에서 숫자로의 암시적 변환을 금지하고 연결에 .. 연산자를 추가했습니다(할당을 포함하는 연결에 ..= ). 그 운영자에 대한 아이디어를 어디서 얻었는지 기억이 나지 않습니다. 그것은 BASIC이나 PHP에서 가져온 것이 아니며 "파이썬 연결(Python concatenation)"이라는 문구는 검색하지 않을 것입니다. 왜냐하면 파이썬에 대한 어떤 것이든 인터넷 검색을 하면 등골이 오싹해질 것이기 때문입니다. 나는 뱀에 대한 공포증이 있고 그것을 "연결"과 결합합니다. 아니요, 감사합니다! 나중에 ASCII 아트가 없는 오래된 텍스트 기반 브라우저를 사용하게 될 수도 있습니다.
그러나 이 섹션의 주제로 돌아가서 표현 파서입니다. 우리는 "Shunting-yard Algorithm"의 적응을 사용할 것입니다.
평범한 프로그래머라도 10분 정도 문제에 대해 생각하면 떠오르는 알고리즘입니다. 중위 표현을 평가하거나 역 폴란드 표기법으로 변환하는 데 사용할 수 있습니다.
알고리즘의 아이디어는 왼쪽에서 오른쪽으로 피연산자와 연산자를 읽는 것입니다. 피연산자를 읽을 때 피연산자 스택으로 푸시합니다. 연산자를 읽을 때 다음 연산자가 그 연산자보다 더 나은 우선 순위를 가질지 모르기 때문에 즉시 평가할 수 없습니다. 따라서 연산자 스택에 푸시합니다.
그러나 먼저 스택의 맨 위에 있는 연산자가 방금 읽은 연산자보다 우선 순위가 더 높은지 확인합니다. 이 경우 피연산자 스택의 피연산자가 있는 스택의 맨 위에서 연산자를 평가합니다. 결과를 피연산자 스택에 푸시합니다. 모든 것을 읽을 때까지 유지한 다음 피연산자 스택의 피연산자를 사용하여 연산자 스택 왼쪽에 있는 모든 연산자를 평가하고 연산자가 없고 하나의 피연산자만 남을 때까지 결과를 피연산자 스택에 다시 푸시합니다. 결과.
두 연산자의 우선 순위가 같을 때 왼쪽 연결 연산자인 경우 왼쪽 연산자를 사용합니다. 그렇지 않으면 올바른 것을 선택합니다. 동일한 우선 순위의 두 연산자는 다른 연관성을 가질 수 없습니다.
원래 알고리즘은 대괄호도 처리하지만 알고리즘이 그렇게 하면 더 깔끔해지기 때문에 대신 재귀적으로 처리합니다.
Edsger Dijkstra는 이 알고리즘을 "Shunting-yard"라고 명명했는데, 이는 철도 분기점의 운영과 유사하기 때문입니다.
그러나 원래 shunting-yard 알고리즘은 오류 검사를 거의 하지 않으므로 잘못된 표현식이 올바른 표현식으로 구문 분석될 가능성이 매우 높습니다. 따라서 연산자 또는 피연산자가 필요한지 확인하는 부울 변수를 추가했습니다. 피연산자가 예상되면 단항 접두사 연산자도 구문 분석할 수 있습니다. 그렇게 하면 잘못된 표현식이 레이더를 통과할 수 없으며 표현식 구문 검사가 완료됩니다.
마무리
시리즈의 이 부분에 대한 코딩을 시작할 때 표현식 작성기에 대해 쓸 계획이었습니다. 평가할 수 있는 표현을 만들고 싶었습니다. 그러나 하나의 블로그 게시물에는 너무 복잡하여 반으로 나누기로 결정했습니다. 이 부분에서 우리는 구문 분석 표현식을 마쳤고 다음 기사에서 표현식 객체를 작성하는 방법에 대해 쓸 것입니다.
제 기억이 맞다면, 약 15년 전, 제 모국어의 첫 번째 버전을 작성하는 데 일주일이 걸렸습니다. 그래서 이번에는 무엇이 잘못되었는지 궁금합니다.
내가 나이가 들고 재치가 없어진다는 사실을 부정하기 위해 두 살배기 아들이 여가 시간에 너무 많은 것을 요구하는 것에 대해 비난할 것입니다.
1부에서처럼 내 GitHub 페이지에서 코드를 읽거나 다운로드하거나 컴파일할 수도 있습니다.