
Stork, часть 2: создание синтаксического анализатора выражений
Опубликовано: 2022-03-11В этой части нашей серии мы рассмотрим один из самых сложных (по крайней мере, на мой взгляд) компонентов написания сценариев для языкового движка, который является важным строительным блоком для каждого языка программирования: синтаксический анализатор выражений.
Вопрос, который читатель мог бы задать — и это справедливо — таков: почему бы нам просто не использовать некоторые сложные инструменты или библиотеки, которые уже есть в нашем распоряжении?
Почему бы нам не использовать Lex, YACC, Bison, Boost Spirit или хотя бы регулярные выражения?
На протяжении наших отношений моя жена заметила во мне одну черту, которую я не могу отрицать: всякий раз, когда я сталкиваюсь с трудным вопросом, я составляю список. Если подумать, в этом есть смысл — я использую количество, чтобы компенсировать отсутствие качества в моем ответе.
Я сделаю то же самое сейчас.
- Я хочу использовать стандартный C++. В данном случае это будет C++17. Я думаю, что язык довольно богат сам по себе, и я борюсь с желанием добавить в него что-то кроме стандартной библиотеки.
- Когда я разрабатывал свой первый язык сценариев, я не использовал никаких сложных инструментов. Я был под давлением и в сжатые сроки, но я не знал, как использовать Lex, YACC или что-то подобное. Поэтому я решил разрабатывать все вручную.
- Позже я нашел блог опытного разработчика языков программирования, который советовал не использовать ни один из этих инструментов. Он сказал, что эти инструменты решают более простую часть разработки языка, так что в любом случае у вас остаются сложные вещи. Я не могу найти этот блог прямо сейчас, так как это было давно, когда и интернет, и я были молоды.
- В то же время существовал мем, в котором говорилось: «У вас есть проблема, которую вы решили решить с помощью регулярных выражений. Теперь у тебя две проблемы.
- Я не знаю Lex, YACC, Bison или что-то подобное. Я знаю Boost Spirit, и это удобная и замечательная библиотека, но я все же предпочитаю лучше контролировать парсер.
- Мне нравится делать эти компоненты вручную. На самом деле, я мог бы просто дать этот ответ и полностью удалить этот список.
Полный код доступен на моей странице GitHub.
Итератор токенов
Есть некоторые изменения в коде по сравнению с Частью 1.
В основном это простые исправления и небольшие изменения, но одним важным дополнением к существующему коду синтаксического анализа является класс token_iterator . Это позволяет нам оценить текущий токен, не удаляя его из потока, что очень удобно.
class tokens_iterator { private: push_back_stream& _stream; token _current; public: tokens_iterator(push_back_stream& stream); const token& operator*() const; const token* operator->() const; tokens_iterator& operator++(); explicit operator bool() const; }; Он инициализируется с помощью push_back_stream , а затем его можно разыменовать и увеличить. Это можно проверить с помощью явного логического приведения, которое будет оцениваться как ложное, когда текущий токен равен eof.
Статически или динамически типизированный язык?
В этой части я должен принять одно решение: будет ли этот язык иметь статическую или динамическую типизацию?
Статически типизированный язык — это язык, который проверяет типы своих переменных во время компиляции.
С другой стороны, язык с динамической типизацией проверяет это не во время компиляции (если есть компиляция, которая не является обязательной для языка с динамической типизацией), а во время выполнения. Поэтому потенциальные ошибки могут жить в коде до тех пор, пока они не будут обнаружены.
Это очевидное преимущество статически типизированных языков. Всем нравится ловить свои ошибки как можно скорее. Мне всегда было интересно, в чем самое большое преимущество языков с динамической типизацией, и в последние пару недель меня осенил ответ: его намного проще разрабатывать!
Предыдущий язык, который я разработал, был динамически типизированным. Результат меня более-менее удовлетворил, и написать парсер выражений не составило особого труда. В основном вам не нужно проверять типы переменных, и вы полагаетесь на ошибки времени выполнения, которые вы кодируете почти спонтанно.
Например, если вам нужно написать двоичный оператор + и вы хотите сделать это для чисел, вам просто нужно оценить обе стороны этого оператора как числа во время выполнения. Если ни одна из сторон не может оценить число, вы просто создаете исключение. Я даже реализовал перегрузку операторов, проверяя информацию о типе переменных в выражении во время выполнения, и операторы были частью этой информации во время выполнения.
В первом языке, который я разработал (это мой третий), я выполнял проверку типов во время компиляции, но я не воспользовался этим в полной мере. Оценка выражения по-прежнему зависела от информации о типе среды выполнения.
Теперь я решил разработать язык со статической типизацией, и это оказалось гораздо более сложной задачей, чем ожидалось. Однако, поскольку я не планирую компилировать его в двоичный файл или какой-либо эмулируемый ассемблерный код, в скомпилированном коде неявно будет существовать некоторая информация.
Типы
В качестве минимума типов, которые мы должны поддерживать, мы начнем со следующего:
- Числа
- Струны
- Функции
- Массивы
Хотя мы можем добавить их в будущем, мы не будем поддерживать структуры (или классы, записи, кортежи и т. д.) в начале. Однако мы будем иметь в виду, что мы можем добавить их позже, поэтому мы не будем скреплять свою судьбу решениями, которые трудно изменить.
Во-первых, я хотел определить тип как строку, которая будет соответствовать некоторому соглашению. Каждый идентификатор будет хранить эту строку по значению во время компиляции, и иногда нам придется ее анализировать. Например, если мы закодируем тип массива чисел как «[число]», то нам придется обрезать первый и последний символы, чтобы получить внутренний тип, которым в данном случае является «число». Это довольно плохая идея, если подумать.
Затем я попытался реализовать его как класс. Этот класс будет иметь всю информацию о типе. Каждый идентификатор будет содержать общий указатель на этот класс. В конце концов, я подумал о том, чтобы во время компиляции использовался реестр всех типов, чтобы каждый идентификатор имел необработанный указатель на свой тип.
Мне понравилась эта идея, поэтому в итоге получилось следующее:
using type = std::variant<simple_type, array_type, function_type>; using type_handle = const type*;Простые типы являются членами перечисления:
enum struct simple_type { nothing, number, string, }; Элемент перечисления nothing здесь используется как заполнитель для void , который я не могу использовать, так как это ключевое слово в C++.
Типы массивов представлены структурой, имеющей единственный член type_handle .
struct array_type { type_handle inner_type_id; }; Очевидно, что длина массива не является частью array_type , поэтому массивы будут расти динамически. Это означает, что мы получим std::deque или что-то подобное, но об этом позже.
Тип функции состоит из типа возвращаемого значения, типа каждого из ее параметров и того, передается ли каждый из этих параметров по значению или по ссылке.
struct function_type { struct param { type_handle type_id; bool by_ref; }; type_handle return_type_id; std::vector<param> param_type_id; };Теперь мы можем определить класс, который будет хранить эти типы.
class type_registry { private: struct types_less{ bool operator()(const type& t1, const type& t2) const; }; std::set<type, types_less> _types; static type void_type; static type number_type; static type string_type; public: type_registry(); type_handle get_handle(const type& t); static type_handle get_void_handle() { return &void_type; } static type_handle get_number_handle() { return &number_type; } static type_handle get_string_handle() { return &string_type; } }; Типы хранятся в std::set , поскольку этот контейнер стабилен, а это означает, что указатели на его элементы действительны даже после вставки новых типов. Есть функция get_handle , которая регистрирует переданный тип и возвращает указатель на него. Если тип уже зарегистрирован, он вернет указатель на существующий тип. Существуют также удобные функции для получения примитивных типов.
Что касается неявного преобразования между типами, числа будут конвертироваться в строки. Это не должно быть опасно, так как обратное преобразование невозможно, а оператор конкатенации строк отличается от оператора сложения чисел. Даже если это преобразование будет удалено на более поздних стадиях развития этого языка, оно послужит хорошим упражнением на данном этапе. Для этого мне пришлось модифицировать парсер чисел, так как он всегда анализировал . как десятичная точка. Это может быть первый символ оператора конкатенации .. .
Контекст компилятора
Во время компиляции различные функции компилятора должны получить информацию о скомпилированном коде. Мы будем хранить эту информацию в compiler_context . Поскольку мы собираемся реализовать синтаксический анализ выражений, нам нужно будет получить информацию об идентификаторах, с которыми мы сталкиваемся.
Во время выполнения мы будем хранить переменные в двух разных контейнерах. Один из них будет контейнером глобальной переменной, а другой — стеком. Стек будет расти по мере того, как мы будем вызывать функции и вводить области видимости. Он будет уменьшаться по мере того, как мы возвращаемся из функций и покидаем области видимости. Когда мы вызываем какую-то функцию, мы передаем параметры функции, а затем функция выполняется. Его возвращаемое значение будет помещено на вершину стека, когда оно выйдет. Поэтому для каждой функции стек будет выглядеть так:
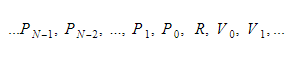
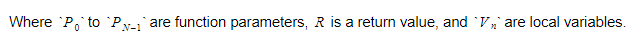
Функция сохранит абсолютный индекс возвращаемой переменной, и каждая переменная или параметр будут найдены относительно этого индекса.
Сейчас мы будем рассматривать функции как постоянные глобальные идентификаторы.
Это класс, который служит информацией идентификатора:
class identifier_info { private: type_handle _type_id; size_t _index; bool _is_global; bool _is_constant; public: identifier_info(type_handle type_id, size_t index, bool is_global, bool is_constant); type_handle type_id() const; size_t index() const; bool is_global() const; bool is_constant() const; }; Для локальных переменных и параметров функции index функции возвращает индекс относительно возвращаемого значения. Он возвращает абсолютный глобальный индекс в случае глобальных идентификаторов.
У нас будет три разных поиска идентификаторов в compile_context :
- Поиск глобального идентификатора, который будет содержать
compile_contextпо значению, так как он одинаков на протяжении всей компиляции. - Поиск локального идентификатора в виде
unique_ptr, который будет иметь значениеnullptrв глобальной области видимости и будет инициализирован в любой функции. Всякий раз, когда мы входим в область действия, новый локальный контекст будет инициализирован старым контекстом в качестве его родителя. Когда мы покинем область видимости, она будет заменена родителем. - Поиск идентификатора функции, который будет необработанным указателем. Это будет
nullptrв глобальной области видимости и то же значение, что и самая внешняя локальная область видимости в любой функции.
class compiler_context { private: global_identifier_lookup _globals; function_identifier_lookup* _params; std::unique_ptr<local_identifier_lookup> _locals; type_registry _types; public: compiler_context(); type_handle get_handle(const type& t); const identifier_info* find(const std::string& name) const; const identifier_info* create_identifier(std::string name, type_handle type_id, bool is_constant); const identifier_info* create_param(std::string name, type_handle type_id); void enter_scope(); void enter_function(); bool leave_scope(); };Дерево выражений
Когда токены выражений анализируются, они преобразуются в дерево выражений. Подобно всем деревьям, это тоже состоит из узлов.

Существует два разных типа узлов:
- Листовые узлы, которые могут быть:
а) Идентификаторы
б) Числа
в) Струны - Внутренние узлы, которые представляют операции над своими дочерними узлами. Он хранит своих дочерних элементов с
unique_ptr.
Для каждого узла имеется информация о его типе и о том, возвращает ли он значение lvalue (значение, которое может отображаться слева от оператора = ).
Когда внутренний узел создан, он попытается преобразовать возвращаемые типы своих дочерних элементов в ожидаемые типы. Допускаются следующие неявные преобразования:
- lvalue в не-lvalue
- Что-нибудь, чтобы
void -
numberвstring
Если преобразование не разрешено, будет выдана семантическая ошибка.
Вот определение класса без некоторых вспомогательных функций и деталей реализации:
enum struct node_operation { ... }; using node_value = std::variant< node_operation, std::string, double, identifier >; struct node { private: node_value _value; std::vector<node_ptr> _children; type_handle _type_id; bool _lvalue; public: node( compiler_context& context, node_value value, std::vector<node_ptr> children ); const node_value& get_value() const; const std::vector<node_ptr>& get_children() const; type_handle get_type_id() const; bool is_lvalue() const; void check_conversion(type_handle type_id, bool lvalue); }; Функциональность методов не требует пояснений, за исключением функции check_conversion . Он проверит, можно ли преобразовать тип в переданный type_id и логическое значение lvalue , подчиняясь правилам преобразования типов, и выдаст исключение, если это не так.
Если узел инициализирован с помощью std::string или double , его тип будет string или number соответственно, и он не будет lvalue. Если он инициализирован идентификатором, он примет тип этого идентификатора и будет lvalue, если идентификатор не является постоянным.
Однако если он инициализируется с помощью операции узла, его тип будет зависеть от операции, а иногда и от типа ее дочерних элементов. Запишем типы выражений в таблицу. Я буду использовать суффикс & для обозначения lvalue. В случаях, когда несколько выражений имеют одинаковую обработку, я буду писать дополнительные выражения в круглых скобках.
Унарные операции
| Операция | Тип операции | х тип |
| ++х (--х) | количество& | количество& |
| х++ (х--) | количество | количество& |
| +х (-х ~х !х) | количество | количество |
Бинарные операции
| Операция | Тип операции | х тип | у тип |
| x+y (xy x*yx/yx\yx%y x&y x|yx^y x<<y x>>y x&&y x||y) | количество | количество | количество |
| х==у (х!=у х<у х>у х<=у х>=у) | количество | число или строка | то же, что х |
| х..у | нить | нить | нить |
| х=у | то же, что х | ценность чего-либо | то же, что и x, без lvalue |
| x+=y (x-=yx*=yx/=yx\=yx%=y x&=yx|=yx^=y x<<=y x>>=y) | количество& | количество& | количество |
| х..=у | нить& | нить& | нить |
| х, у | то же, что и ты | пустота | что-нибудь |
| х[у] | тип элемента x | тип массива | количество |
Тернарные операции
| Операция | Тип операции | х тип | у тип | г тип |
| х?у:г | то же, что и ты | количество | что-нибудь | то же, что и ты |
Вызов функции
Когда дело доходит до вызова функции, все становится немного сложнее. Если функция имеет N аргументов, операция вызова функции имеет N+1 дочерних элементов, где первый дочерний элемент — это сама функция, а остальные дочерние элементы соответствуют аргументам функции.
Однако мы не допустим неявной передачи аргументов по ссылке. Мы потребуем, чтобы вызывающий абонент поставил перед ними знак & . На данный момент это будет не дополнительный оператор, а способ разбора вызова функции. Если мы не будем анализировать амперсанд, когда ожидается аргумент, мы удалим lvalue-ness из этого аргумента, добавив фальшивую унарную операцию, которую мы называем node_operation::param . Эта операция имеет тот же тип, что и ее дочерний элемент, но это не lvalue.
Затем, когда мы строим узел с этой операцией вызова, если у нас есть аргумент, который является lvalue, но не ожидается функцией, мы сгенерируем ошибку, так как это означает, что вызывающая сторона случайно ввела амперсанд. Несколько удивительно, что & , если рассматривать его как оператор, будет иметь наименьший приоритет, поскольку он не имеет семантического значения при анализе внутри выражения. Мы можем изменить его позже.
Анализатор выражений
В одном из своих утверждений о потенциале программистов известный философ информатики Эдсгер Дейкстра однажды сказал:
«Практически невозможно научить хорошему программированию студентов, ранее знакомых с BASIC. Как потенциальные программисты, они психически изуродованы без надежды на восстановление».
Итак, всем вам, кто не знаком с BASIC, будьте благодарны за то, что вы избежали «умственного увечья».
Остальные из нас, искалеченные программисты, давайте вспомним те времена, когда мы программировали на Бейсике. Был оператор \ , который использовался для целочисленного деления. В языке, где у вас нет отдельных типов для целых чисел и чисел с плавающей запятой, это очень удобно, поэтому я добавил тот же оператор в Stork. Я также добавил оператор \= , который, как вы догадались, будет выполнять целочисленное деление, а затем присваивать.
Я думаю, что такие операторы были бы оценены, например, программистами JavaScript. Я даже не хочу представлять, что сказал бы о них Дейкстра, если бы он прожил достаточно долго, чтобы увидеть растущую популярность JS.
Говоря об этом, одна из самых больших проблем, с которыми я сталкиваюсь при работе с JavaScript, — это несоответствие следующих выражений:
-
"1" - “1”оценивается как0 -
"1" * “1”равно1 -
"1" / “1”равно1 -
"1" + “1”равно“11”
У хорватского хип-хоп-дуэта «Tram 11», названного в честь трамвая, который соединяет отдаленные районы Загреба, была песня, которая примерно переводится как: «Один и один не два, а 11». Он вышел в конце 90-х, так что это не ссылка на JavaScript, но он достаточно хорошо иллюстрирует несоответствие.
Чтобы избежать этих несоответствий, я запретил неявное преобразование строки в число и добавил оператор .. для конкатенации (и ..= для конкатенации с присваиванием). Я не помню, откуда у меня появилась идея для этого оператора. Это не из BASIC или PHP, и я не буду искать фразу «конкатенация Python», потому что гугление чего-либо о Python вызывает у меня мурашки по спине. У меня фобия змей, а в сочетании с «конкатенацией» — нет, спасибо! Может позже, с каким-нибудь архаичным текстовым браузером, без ASCII-арта.
Но вернемся к теме этого раздела — нашему парсеру выражений. Мы будем использовать адаптацию «Алгоритма сортировочной станции».
Это алгоритм, который приходит в голову любому, даже среднему программисту, после того, как он поразмышляет над проблемой в течение 10 минут или около того. Его можно использовать для вычисления инфиксного выражения или преобразования его в обратную польскую нотацию, чего мы делать не будем.
Идея алгоритма заключается в чтении операндов и операторов слева направо. Когда мы читаем операнд, мы помещаем его в стек операндов. Когда мы читаем оператор, мы не можем оценить его немедленно, так как мы не знаем, будет ли следующий оператор иметь лучший приоритет, чем тот. Поэтому мы помещаем его в стек операторов.
Однако сначала мы проверяем, имеет ли оператор на вершине стека более высокий приоритет, чем тот, который мы только что прочитали. В этом случае мы оцениваем оператор с вершины стека с операндами в стеке операндов. Мы помещаем результат в стек операндов. Мы сохраняем его до тех пор, пока не прочитаем все, а затем оцениваем все операторы слева от стека операторов с операндами в стеке операндов, помещая результаты обратно в стек операндов до тех пор, пока не останемся без операторов и с одним операндом, который результат.
Когда два оператора имеют одинаковый приоритет, мы выберем левый, если эти операторы левоассоциативны; в противном случае, мы берем правильный. Два оператора с одинаковым приоритетом не могут иметь разную ассоциативность.
Исходный алгоритм также обрабатывает круглые скобки, но вместо этого мы будем делать это рекурсивно, поскольку таким образом алгоритм будет чище.
Эдсгер Дейкстра назвал алгоритм «Маневровой станцией», потому что он напоминает работу маневровой станции на железной дороге.
Однако исходный алгоритм маневровой станции почти не проверяет ошибки, поэтому вполне возможно, что недопустимое выражение будет проанализировано как правильное. Поэтому я добавил логическую переменную, которая проверяет, ожидаем ли мы оператора или операнда. Если мы ожидаем операнды, мы также можем анализировать унарные префиксные операторы. Таким образом, ни одно недопустимое выражение не останется незамеченным, а проверка синтаксиса выражения будет завершена.
Подведение итогов
Когда я начал писать код для этой части серии, я планировал написать о построителе выражений. Я хотел построить выражение, которое можно вычислить. Однако это оказалось слишком сложно для одного поста в блоге, поэтому я решил разделить его пополам. В этой части мы завершили синтаксический анализ выражений, а о построении объектов-выражений я напишу в следующей статье.
Если я правильно помню, около 15 лет назад мне потребовались одни выходные, чтобы написать первую версию моего первого языка, что заставляет меня задуматься, что пошло не так на этот раз.
Пытаясь отрицать, что я становлюсь старше и менее остроумна, я буду обвинять своего двухлетнего сына в том, что он слишком требователен в свободное время.
Как и в первой части, вы можете прочитать, загрузить или даже скомпилировать код с моей страницы GitHub.