Ultimate Impala Hadoop บทช่วยสอนที่คุณต้องการ [2022]
เผยแพร่แล้ว: 2020-05-14Impala เป็นฐานข้อมูลเชิงวิเคราะห์แบบโอเพนซอร์สที่ออกแบบมาสำหรับแพลตฟอร์มแบบคลัสเตอร์ เช่น Apache Hadoop เป็นเอ็นจิ้นการสืบค้นแบบ SQL แบบโต้ตอบที่ทำงานบน Hadoop Distributed File System (HDFS) เพื่ออำนวยความสะดวกในการประมวลผลข้อมูลปริมาณมหาศาลด้วยความเร็วสูง นอกจากนี้ Impala ยังเป็นหนึ่งในเครื่องมือ Hadoop อันดับต้น ๆ ที่ใช้ข้อมูลขนาดใหญ่ วันนี้ เราจะมาพูดถึงทุกสิ่งเกี่ยวกับ Impala และด้วยเหตุนี้ เราจึงได้ออกแบบ บทช่วยสอน Impala นี้สำหรับคุณ!
บทช่วยสอน Impala Hadoop นี้จัดทำขึ้นเป็นพิเศษสำหรับผู้ที่ต้องการเรียนรู้ Impala อย่างไรก็ตาม เพื่อให้ได้รับประโยชน์สูงสุดจากบทช่วยสอน Impala นี้ จะช่วยให้คุณมีความเข้าใจในเชิงลึกเกี่ยวกับพื้นฐานของ SQL ควบคู่ไปกับคำสั่ง Hadoop และ HDFS
สารบัญ
อิมพาลาคืออะไร?
Impala เป็นเอ็นจิ้น การสืบค้น SQL ของ MPP (Massive Parallel Processing) ที่ เขียนในภาษา C++ และ Java วัตถุประสงค์หลักคือการประมวลผลข้อมูลปริมาณมหาศาลที่จัดเก็บไว้ในคลัสเตอร์ Hadoop Impala ให้คำมั่นสัญญาว่าจะมีประสิทธิภาพสูงและเวลาแฝงต่ำ และจนถึงขณะนี้เป็นเอ็นจิ้น SQL ที่มีประสิทธิภาพสูง (ซึ่งมอบประสบการณ์ที่เหมือน RDBMS) เพื่อมอบวิธีที่เร็วที่สุดในการเข้าถึงและประมวลผลข้อมูลที่จัดเก็บไว้ใน HDFS
ข้อดีอีกประการของ Impala คือการผสานรวมกับ Hive metastore เพื่ออนุญาตให้แบ่งปันข้อมูลตารางระหว่างทั้งสององค์ประกอบ ใช้ประโยชน์จาก Apache Hive ที่มีอยู่เพื่อทำงานแบบแบตช์และระยะยาวในรูปแบบคิวรี SQL การผสานรวม Impala-Hive ช่วยให้คุณใช้ส่วนประกอบทั้งสองอย่าง – Hive หรือ Impala สำหรับการประมวลผลข้อมูลหรือสร้างตารางภายใต้ระบบไฟล์ที่ใช้ร่วมกันเพียงระบบเดียว (HDFS) โดยไม่ต้องเปลี่ยนข้อกำหนดของตาราง
ทำไมต้องอิมพาลา?
Impala รวมเอาประสิทธิภาพของฐานข้อมูลการวิเคราะห์แบบดั้งเดิมและ SQL ที่รองรับผู้ใช้หลายคนเข้ากับความสามารถในการปรับขนาดและความยืดหยุ่นของ Apache Hadoop ทำได้โดยใช้ส่วนประกอบ Hadoop มาตรฐานเช่น HDFS, HBase, YARN, Sentry และ Metastore เนื่องจาก Impala ใช้ข้อมูลเมตาเดียวกัน ส่วนต่อประสานผู้ใช้ (Hue Beeswax), ไวยากรณ์ SQL (Hive SQL) และไดรเวอร์ ODBC (การเชื่อมต่อฐานข้อมูลแบบเปิด) เป็น Apache Hive จึงสร้างแพลตฟอร์มที่เป็นหนึ่งเดียวและคุ้นเคยสำหรับการสืบค้นแบบแบตช์และแบบเรียลไทม์
อ่าน: แนวคิดโครงการข้อมูลขนาดใหญ่สำหรับผู้เริ่มต้น

Impala สามารถอ่านรูปแบบไฟล์เกือบทั้งหมดที่ใช้โดย Hadoop รวมถึง Parquet, Avro และ RCFile นอกจากนี้ Impala ไม่ได้สร้างขึ้นบนอัลกอริธึม MapReduce แต่ใช้สถาปัตยกรรมแบบกระจายตามกระบวนการของ daemon ที่จัดการและจัดการทุกอย่างที่เกี่ยวข้องกับการดำเนินการค้นหาที่ทำงานบนเครื่องเดียวกัน ด้วยเหตุนี้ จึงช่วยลดเวลาแฝงของการใช้ MapReduce นี่คือสิ่งที่ทำให้ Impala เร็วกว่า Hive มาก
อิมพาลา – คุณสมบัติ
คุณสมบัติหลักของอิมพาลาคือ:
- มีให้ใช้งานในฐานะเอ็นจิ้นการสืบค้น SQL โอเพ่นซอร์สภายใต้ลิขสิทธิ์ Apache
- ช่วยให้คุณเข้าถึงข้อมูลโดยใช้การสืบค้นแบบ SQL
- รองรับการประมวลผลข้อมูลในหน่วยความจำ - เข้าถึงและวิเคราะห์ข้อมูลที่จัดเก็บไว้ในโหนดข้อมูล Hadoop
- ช่วยให้คุณสามารถจัดเก็บข้อมูลในระบบจัดเก็บข้อมูล เช่น HDFS, Apache HBase และ Amazon s3
- รวมเข้ากับเครื่องมือ BI เช่น Tableau, Pentaho และ Micro ได้อย่างง่ายดาย
- รองรับไฟล์รูปแบบต่างๆ รวมถึง Sequence File, Avro, LZO, RCFile และ Parquet
อิมพาลา – ข้อได้เปรียบที่สำคัญ
การใช้ Impala ให้ข้อดีที่สำคัญบางประการแก่ผู้ใช้ เช่น:
- เนื่องจาก Impala รองรับการประมวลผลข้อมูลในหน่วยความจำ (การประมวลผลเกิดขึ้นในที่ที่มีข้อมูลอยู่ – บนคลัสเตอร์ Hadoop) จึงไม่มีความจำเป็นสำหรับการแปลงข้อมูลและการย้ายข้อมูล
- ในการเข้าถึงข้อมูลที่จัดเก็บใน HDFS หรือ HBase หรือ Amazon s3 กับ Impala คุณไม่จำเป็นต้องมีความรู้เกี่ยวกับ Java (งาน MapReduce) มาก่อน คุณสามารถเข้าถึงได้ง่ายโดยใช้การสืบค้น SQL พื้นฐาน
- โดยทั่วไป ข้อมูลจะต้องผ่านวงจร extract-transform-load (ETL) ที่ซับซ้อนขณะเขียนการสืบค้นในเครื่องมือทางธุรกิจ อย่างไรก็ตาม ด้วยอิมพาลา ไม่จำเป็นต้องมีสิ่งนี้ Impala แทนที่ขั้นตอนที่ใช้เวลานานในการโหลดและจัดระเบียบใหม่ด้วยเทคนิคขั้นสูง เช่น การวิเคราะห์ข้อมูลเชิงสำรวจและการค้นพบข้อมูล ซึ่งจะช่วยเพิ่มความเร็วของกระบวนการ
- Impala เป็นผู้บุกเบิกการใช้รูปแบบไฟล์ Parquet ซึ่งเป็นรูปแบบการจัดเก็บแบบเสาที่ปรับให้เหมาะสมสำหรับการสืบค้นขนาดใหญ่ที่พบในคลังข้อมูล
อิมพาลา – ข้อเสีย
แม้ว่า Impala จะมีประโยชน์มากมาย แต่ก็มีข้อจำกัดบางประการเช่นกัน:
- ไม่รองรับการทำให้เป็นอนุกรมและดีซีเรียลไลซ์เซชั่น
- ไม่สามารถอ่านไฟล์ไบนารีที่กำหนดเองได้ สามารถอ่านได้เฉพาะไฟล์ข้อความเท่านั้น
- ทุกครั้งที่มีการเพิ่มระเบียนหรือไฟล์ใหม่ลงในไดเร็กทอรีข้อมูลใน HDFS คุณจะต้องรีเฟรชตารางข้อมูล
อิมพาลา – สถาปัตยกรรม
Impala แยกออกจากกลไกการจัดเก็บข้อมูล (ตรงกันข้ามกับระบบจัดเก็บข้อมูลแบบเดิม) ประกอบด้วยสามองค์ประกอบหลัก – Impala Daemon (Impalad) , Impala StateStore และ Impala Metadata & MetaStore
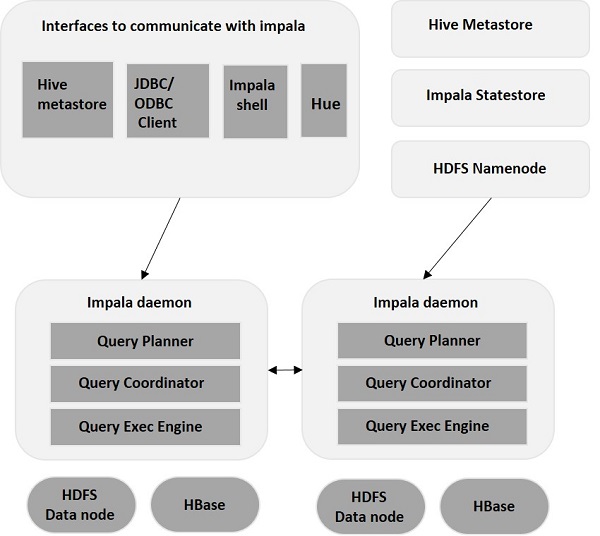
Impala Daemon
Impala Daemon หรือที่รู้จักว่า Impalad ทำงานบนแต่ละโหนดที่ติดตั้ง Impala ยอมรับการสืบค้นจากหลายอินเทอร์เฟซ (Impala shell, Hue browser ฯลฯ ) และประมวลผล ทุกครั้งที่ส่งแบบสอบถามไปยัง Impalad บนโหนดใดโหนดหนึ่ง โหนดนั้นจะกลายเป็น “โหนดผู้ประสานงาน” สำหรับการสืบค้นนั้น ด้วยวิธีนี้ Impalad ทำงานบนโหนดอื่น ๆ แบบสอบถามหลายรายการ
เมื่อยอมรับการสืบค้นแล้ว Impalad จะอ่านและเขียนไฟล์ข้อมูลและทำให้การสืบค้นเป็นแบบขนานโดยการกระจายงานไปยังโหนด Impala อื่นในคลัสเตอร์ ผู้ใช้สามารถส่งคำถามไปยัง Impalad เฉพาะ หรือในลักษณะโหลดบาลานซ์ไปยัง Impalad อื่นๆ ในคลัสเตอร์ ตามความต้องการของพวกเขา ข้อความค้นหาเหล่านี้จะเริ่มประมวลผลกับ อินสแตนซ์ Impalad ต่างๆ และส่งคืนผลลัพธ์ไปยังโหนดประสานงานหลัก
Impala StateStore
Impala StateStore จะตรวจสอบและตรวจสอบความสมบูรณ์ของ Impalad แต่ละอัน และยังถ่ายทอดรายงานความสมบูรณ์ของความสมบูรณ์ของ Impala Daemon ไปยัง Daemon อื่นๆ มันสามารถทำงานบนโหนดเดียวกันกับที่เซิร์ฟเวอร์ Impala กำลังทำงานหรือในโหนดอื่นในคลัสเตอร์ ในกรณีที่โหนดล้มเหลวเนื่องจากสาเหตุบางประการ Impala StateStore จะอัปเดตโหนดอื่นๆ ทั้งหมดเกี่ยวกับความล้มเหลว ในกรณีดังกล่าว Impala daemons อื่นๆ จะหยุดกำหนดเคียวรีเพิ่มเติมใดๆ ให้กับโหนดที่ล้มเหลว
Impala Metadata & MetaStore
ใน Impala ข้อมูลสำคัญทั้งหมด รวมถึงคำจำกัดความของตาราง ข้อมูลตารางและคอลัมน์ ฯลฯ จะถูกจัดเก็บไว้ในฐานข้อมูลแบบรวมศูนย์ที่เรียกว่า MetaStore เมื่อต้องจัดการกับข้อมูลจำนวนมากที่มีพาร์ติชั่นหลายพาร์ติชั่น การรับเมตาดาต้าเฉพาะตารางจะกลายเป็นเรื่องท้าทาย นี่คือจุดที่อิมพาลาเข้ามาช่วยเหลือ เนื่องจากแต่ละโหนด Impala แคชข้อมูลเมตาทั้งหมดในเครื่อง จึงง่ายต่อการรับข้อมูลเฉพาะทันที
ทุกครั้งที่คุณอัปเดตคำจำกัดความของตาราง/ข้อมูลตาราง Impala Daemons ทั้งหมดต้องอัปเดตแคชข้อมูลเมตาด้วยการดึงข้อมูลเมตาล่าสุดก่อนจึงจะสามารถสืบค้นข้อมูลใหม่กับตารางใดตารางหนึ่งได้
Impala – การติดตั้ง Impala
เช่นเดียวกับที่คุณต้องติดตั้ง Hadoop และระบบนิเวศของมันบน Linux OS คุณสามารถทำเช่นเดียวกันกับ Impala เนื่องจากเป็น Cloudera ที่ส่ง Impala เป็นครั้งแรก คุณจึงสามารถเข้าถึงได้ง่ายผ่าน Cloudera QuickStart VM
อ่าน: Hadoop กวดวิชา
วิธีดาวน์โหลด Cloudera QuickStart VM
ในการดาวน์โหลด Cloudera QuickStart VM คุณต้องทำตามขั้นตอนด้านล่าง
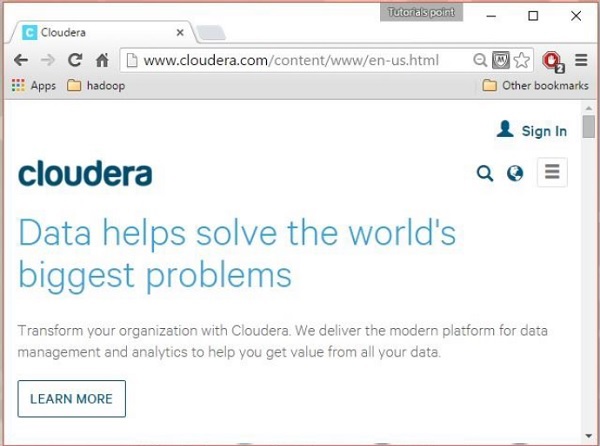
ขั้นตอนที่ 1
เปิดหน้าแรกของ Cloudera ( http://www.cloudera.com/ ) และคุณจะพบสิ่งนี้:
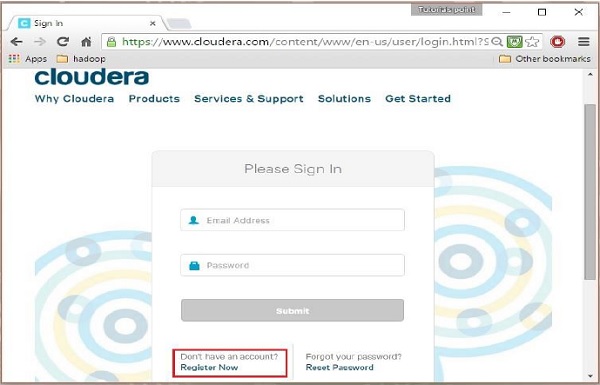
ขั้นตอนที่ 2
ในการลงทะเบียนบน Cloudera คุณต้องคลิกตัวเลือก "ลงทะเบียนทันที" ซึ่งจะเปิดหน้าการลงทะเบียนบัญชี หากคุณได้ลงทะเบียนบน Cloudera แล้ว คุณสามารถคลิกที่ตัวเลือก “ลงชื่อเข้าใช้” บนหน้านั้น และมันจะเปลี่ยนเส้นทางคุณไปยังหน้าลงชื่อเข้าใช้เพิ่มเติมดังนี้:
ขั้นตอนที่ 3
เมื่อคุณลงชื่อเข้าใช้แล้ว ให้เปิดหน้าดาวน์โหลดของเว็บไซต์โดยคลิกที่ตัวเลือก "ดาวน์โหลด" ที่มุมซ้ายบนของหน้าดังที่แสดงด้านล่าง:
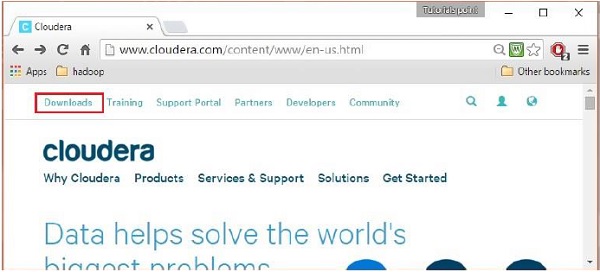
ขั้นตอนที่ 4
ในขั้นตอนนี้ คุณต้องดาวน์โหลด Cloudera QuickStartVM โดยคลิกที่ตัวเลือก "ดาวน์โหลดทันที" ดังนี้:
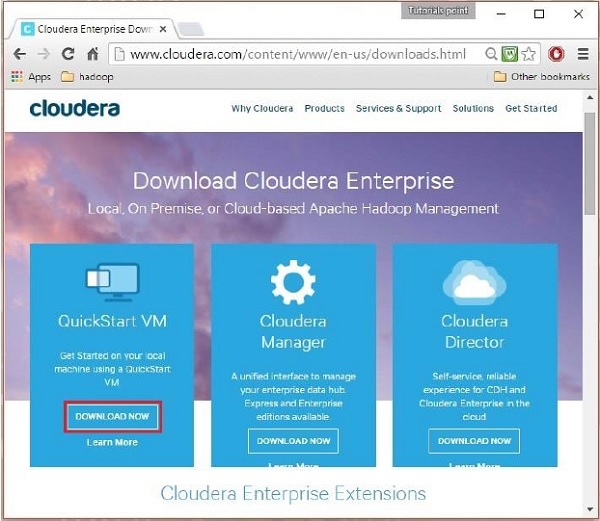
การคลิกที่ตัวเลือก Download Now จะนำคุณไปยังหน้าดาวน์โหลดของ QuickStart VM:
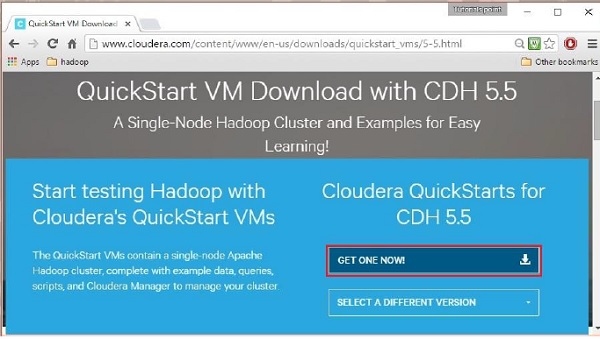
จากนั้นคุณต้องเลือกตัวเลือก GET ONE NOW ยอมรับข้อตกลงใบอนุญาต และส่งตามที่แสดงด้านล่าง:
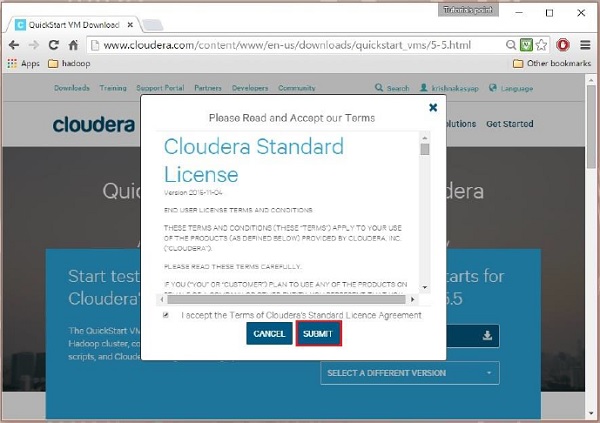
หลังจากดาวน์โหลดเสร็จสิ้น คุณจะพบกับตัวเลือกที่เข้ากันได้กับ Cloudera VM สามตัวเลือก – VMware, KVM และ VIRTUALBOX คุณสามารถเลือกตัวเลือกที่ต้องการได้

แหล่งที่มา
Impala – อินเทอร์เฟซการประมวลผลแบบสอบถาม
Impala มีอินเทอร์เฟซสามแบบสำหรับการประมวลผลคำค้นหา:
Impala-shell – เมื่อคุณติดตั้งและตั้งค่า Impala โดยใช้ Cloudera VM แล้ว คุณสามารถเปิดใช้งาน Impala-shell ได้โดยพิมพ์คำสั่ง “impala-shell” ในตัวแก้ไข
อ่าน: ความแตกต่างระหว่าง Big Data & Hadoop
ส่วนต่อประสาน Hue - เบราว์เซอร์ Hue อนุญาตให้คุณประมวลผลการสืบค้น Impala มีตัวแก้ไขแบบสอบถาม Impala ซึ่งคุณสามารถพิมพ์และดำเนินการค้นหา Impala ที่แตกต่างกันได้ อย่างไรก็ตาม ในการใช้ตัวแก้ไข ก่อนอื่น คุณจะต้องลงชื่อเข้าใช้เบราว์เซอร์ Hue
ไดรเวอร์ ODBC/JDBC – เช่นเดียวกับทุกฐานข้อมูล Impala ยังมีไดรเวอร์ ODBC/JDBC อีกด้วย ไดรเวอร์เหล่านี้ช่วยให้คุณเชื่อมต่อกับ Impala ผ่านภาษาการเขียนโปรแกรมที่รองรับ (ไดรเวอร์ ODBC/JDBC) และสร้างแอปพลิเคชันที่ประมวลผลการสืบค้นใน Impala โดยใช้ภาษาการเขียนโปรแกรมเดียวกัน
ขั้นตอนการดำเนินการสอบถาม
เมื่อใดก็ตามที่คุณส่งแบบสอบถามโดยใช้อินเทอร์เฟซ Impala ใดๆ Impalad ในคลัสเตอร์มักจะยอมรับการสืบค้นของคุณ Impalad นี้จะกลายเป็นโหนดประสานงานสำหรับแบบสอบถามนั้น ๆ หลังจากได้รับแบบสอบถาม ผู้ประสานงานจะตรวจสอบว่าแบบสอบถามมีความเหมาะสมหรือไม่โดยใช้ Table Schema จาก Hive Metastore
หลังจากนี้ จะรวบรวมข้อมูลเกี่ยวกับตำแหน่งของข้อมูลที่จำเป็นสำหรับการดำเนินการค้นหาจากโหนดชื่อ HDFS และส่งต่อข้อมูลนี้ไปยัง Impalads อื่นๆ ในลำดับชั้นเพื่ออำนวยความสะดวกในการดำเนินการค้นหา เมื่อ Impalads อ่านบล็อคข้อมูลที่ระบุแล้ว พวกเขาจะประมวลผลการสืบค้น เมื่อ Impalads ทั้งหมดในคลัสเตอร์ได้ประมวลผลการสืบค้นแล้ว โหนดผู้ประสานงานจะรวบรวมผลลัพธ์และส่งให้คุณ
คำสั่งอิมพาลาเชลล์
หากคุณคุ้นเคยกับ Hive Shell คุณจะเข้าใจ Impala Shell ได้อย่างง่ายดาย เนื่องจากทั้งคู่มีโครงสร้างที่คล้ายคลึงกัน ซึ่งอนุญาตให้สร้างฐานข้อมูลและตาราง แทรกข้อมูล และสอบถามปัญหา คำสั่ง Impala Shell อยู่ภายใต้หมวดหมู่กว้างๆ สามประเภท: คำสั่งทั่วไป ตัวเลือกเฉพาะการสืบค้น และตัวเลือกเฉพาะตารางและฐานข้อมูล
คำสั่งทั่วไป
- ช่วย
คำสั่ง help แสดงรายการคำสั่งที่มีประโยชน์ใน Impala
[quickstart.cloudera:21000] > ช่วยด้วย;
เอกสารคำสั่ง (พิมพ์ help <topic>):
================================================= =======
คำนวณอธิบายชุดแทรกที่ไม่ได้ตั้งค่าด้วยเวอร์ชัน
เชื่อมต่อ อธิบาย เลิก แสดงค่า ใช้
ออกจากโปรไฟล์ประวัติเลือกเคล็ดลับเชลล์
คำสั่งที่ไม่มีเอกสาร:
========================================
แก้ไข สร้าง desc drop ช่วยเหลือ โหลดสรุป
- เวอร์ชั่น
คำสั่งนี้จะให้ Impala เวอร์ชันปัจจุบันแก่คุณ
[quickstart.cloudera:21000] > รุ่น;
เวอร์ชันของเชลล์: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) สร้างขึ้นในวันจันทร์ที่ 9 พ.ย
12:18:12 PST 2015
เวอร์ชันของเซิร์ฟเวอร์: impalad เวอร์ชัน 2.3.0-cdh5.5.0 รีลีส (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- ประวัติศาสตร์
คำสั่งนี้แสดงคำสั่งสิบคำสั่งสุดท้ายที่ดำเนินการใน Impala Shell
[quickstart.cloudera:21000] > ประวัติ;
[1]:รุ่น;
[2]:ช่วย;
[3]:แสดงฐานข้อมูล;
[4]:ใช้ my_db;
[5]:ประวัติศาสตร์;
- เชื่อมต่อ
คำสั่งนี้ช่วยเชื่อมต่อกับอินสแตนซ์ของ Impala ที่กำหนด หากคุณไม่ระบุอินสแตนซ์ใดๆ อินสแตนซ์จะเชื่อมต่อกับพอร์ตเริ่มต้น 21000 ตามค่าเริ่มต้น
[quickstart.cloudera:21000] > เชื่อมต่อ;
เชื่อมต่อกับ quickstart.cloudera:21000
เวอร์ชันของเซิร์ฟเวอร์: impalad เวอร์ชัน 2.3.0-cdh5.5.0 รีลีส (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- ออก/ออก
ตามชื่อที่แนะนำ คำสั่ง exit/quit ให้คุณออกจาก Impala Shell
[quickstart.cloudera:21000] > ออก;
ลาก่อน cloudera
แบบสอบถามตัวเลือกเฉพาะ
- อธิบาย
คำสั่งนี้ส่งคืนแผนการดำเนินการสำหรับแบบสอบถามเฉพาะ
[quickstart.cloudera:21000] > อธิบายการเลือก * จากตัวอย่าง
แบบสอบถาม: อธิบายการเลือก * จากตัวอย่าง
+————————————————————————+
| อธิบายสตริง
|
+————————————————————————+
| ข้อกำหนดต่อโฮสต์โดยประมาณ: หน่วยความจำ = 48.00MB VCores = 1
|
| คำเตือน: ตารางต่อไปนี้ไม่มีสถิติตารางและ/หรือคอลัมน์ที่เกี่ยวข้อง |
| my_db.customers |
| 01:การแลกเปลี่ยน [ไม่แบ่งส่วน]
|
| 00:SCAN HDFS [my_db.customers] |
| พาร์ติชั่น = 1/1 ไฟล์ = 6 ขนาด = 148B |
+————————————————————————+
ดึงข้อมูล 7 แถวใน 0.17s
- ข้อมูลส่วนตัว
คำสั่งนี้แสดงข้อมูลระดับต่ำเกี่ยวกับการสืบค้นล่าสุด/ล่าสุด ใช้สำหรับการวินิจฉัยและการปรับแต่งประสิทธิภาพของแบบสอบถาม
[ เริ่มต้นอย่าง รวดเร็ว cloudera : 21000 ] > โปรไฟล์ ;
โปรไฟล์ รันไทม์ ของแบบสอบถาม :
ข้อความค้นหา ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
สรุป :
รหัส เซสชัน : e74927207cd752b5 : 65ca61e630ad3ad
ประเภท เซสชัน : BEESWAX
เวลา เริ่มต้น : 2016 – 04 – 17 23 : 49 : 26.08148000 เวลา สิ้นสุด : 2016 – 04 – 17 23 : 49 : 26.2404000
ประเภท ของ ข้อความค้นหา : EXPLAIN
สถานะ ข้อความค้นหา : FINISHED
สถานะ ข้อความค้นหา : OK
เวอร์ชัน อิมพาลา : เวอร์ชัน อิ ม พาลา 2.3 0 – cdh5 . 5.0 ปล่อย ( สร้าง 0c891d77280e2129b )
User : cloudera
ผู้ใช้ ที่ เชื่อมต่อ : cloudera
ผู้ ใช้ ที่ได้รับมอบหมาย :
ที่อยู่ เครือข่าย : 10.0 . 2.15 : 43870
ฐานข้อมูล เริ่มต้น : my_db
คำ สั่ง sql : อธิบายการ เลือก * จาก ตัวอย่าง
ผู้ประสาน งาน : quickstart cloudera : 22000
: 0ns
คิวรี่ ไทม์ไลน์ : 167.304ms
– เริ่ม ดำเนินการ : 41.292us ( 41.292us ) – การวางแผน เสร็จสิ้น : 56.42ms ( 56.386ms )
– แถว ที่ใช้ได้ : 58.247ms ( 1.819ms )
– ดึงแถว แรก : 160.72ms ( 101.824ms )
– ยกเลิก การลงทะเบียน แบบสอบถาม : 166.325ms ( 6.253ms )
เซิร์ฟเวอร์อิมพาลา :
– ClientFetchWaitTimer : 107.969ms
– RowMaterializationTimer : 0ns
ตัวเลือกเฉพาะของตารางและฐานข้อมูล
- alter
คำสั่ง alter ช่วยในการเปลี่ยนโครงสร้างและชื่อของตาราง
- บรรยาย
คำสั่งอธิบายให้ข้อมูลเมตาของตาราง ประกอบด้วยข้อมูลเช่นคอลัมน์และประเภทข้อมูล
- หยด
คำสั่ง drop ช่วยในการลบโครงสร้าง ซึ่งอาจเป็นตาราง มุมมอง หรือฟังก์ชันฐานข้อมูล
- แทรก
คำสั่งแทรกช่วยในการผนวกข้อมูล (คอลัมน์) ลงในตารางและแทนที่ข้อมูลของตารางที่มีอยู่
- เลือก
คำสั่ง select สามารถใช้เพื่อดำเนินการกับชุดข้อมูลเฉพาะได้ โดยปกติแล้วจะกล่าวถึงชุดข้อมูลที่จะดำเนินการให้เสร็จสิ้น
- แสดง
คำสั่ง show แสดง metastore ของโครงสร้างต่างๆ เช่น ตารางและฐานข้อมูล
- ใช้
คำสั่ง use ช่วยเปลี่ยนบริบทปัจจุบันของฐานข้อมูลเฉพาะ
Impala – ความคิดเห็น
ใน Impala ความคิดเห็นจะคล้ายกับความคิดเห็นในภาษา SQL โดยทั่วไป ความคิดเห็นมีสองประเภท:
ความคิดเห็นบรรทัดเดียว
แต่ละบรรทัดที่ตามด้วย “—” จะกลายเป็นความคิดเห็นใน Impala
— สวัสดี ยินดีต้อนรับสู่ upGrad
ความคิดเห็นหลายบรรทัด
บรรทัดทั้งหมดที่มีระหว่าง /* และ */ เป็นความคิดเห็นแบบหลายบรรทัดใน Impala
/*
สวัสดี นี่คือตัวอย่าง

ของความคิดเห็นหลายบรรทัดใน Impala
*/
บทสรุป
เราหวังว่าบทช่วยสอน Impala แบบละเอียดนี้จะช่วยให้คุณเข้าใจความซับซ้อนและวิธีการทำงาน
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ
เรียนรู้ หลักสูตรการพัฒนาซอฟต์แวร์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม Executive PG โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว