您將需要的終極 Impala Hadoop 教程 [2022]
已發表: 2020-05-14Impala 是一個開源的本地分析數據庫,專為 Apache Hadoop 等集群平台而設計。 它是一個交互式 SQL 式查詢引擎,運行在 Hadoop 分佈式文件系統 (HDFS) 之上,以促進以閃電般的速度處理海量數據。 此外,impala 是使用大數據的頂級 Hadoop 工具之一。 今天,我們將討論 Impala 的所有內容,因此,我們為您設計了這個 Impala 教程!
這個 Impala Hadoop 教程是專門為那些希望學習 Impala 的人準備的。 但是,為了獲得本 Impala 教程的最大好處,如果您深入了解 SQL 的基礎知識以及 Hadoop 和 HDFS 命令,將會有所幫助。
目錄
什麼是黑斑羚?
Impala 是一個用 C++ 和 Java 編寫的MPP(大規模並行處理)SQL 查詢引擎。 它的主要目的是處理存儲在 Hadoop 集群中的大量數據。 Impala 承諾高性能和低延遲,它是迄今為止性能最好的 SQL 引擎(提供類似 RDBMS 的體驗),以提供訪問和處理存儲在 HDFS 中的數據的最快方式。
Impala 的另一個優點是它與 Hive 元存儲集成以允許在兩個組件之間共享表信息。 它利用現有的 Apache Hive 以 SQL 查詢格式執行面向批處理的、長時間運行的作業。 Impala-Hive 集成允許您使用兩個組件中的任何一個 - Hive 或 Impala 進行數據處理,或者在單個共享文件系統 (HDFS) 下創建表,而無需更改表定義。
為什麼是黑斑羚?
Impala 將傳統分析數據庫的多用戶性能和 SQL 支持與 Apache Hadoop 的可擴展性和靈活性相結合。 它通過使用 HDFS、HBase、YARN、Sentry 和 Metastore 等標準 Hadoop 組件來實現。 由於 Impala 使用與 Apache Hive 相同的元數據、用戶界面 (Hue Beeswax)、SQL 語法 (Hive SQL) 和 ODBC(開放式數據庫連接)驅動程序,因此它為面向批處理和實時查詢創建了一個統一且熟悉的平台。
閱讀:面向初學者的大數據項目理念

Impala 可以讀取 Hadoop 使用的幾乎所有文件格式,包括 Parquet、Avro 和 RCFile。 此外,Impala 不是基於 MapReduce 算法構建的——它實現了一個基於守護進程的分佈式架構,該進程處理和管理與在同一台機器上運行的查詢執行相關的所有內容。 因此,它有助於減少使用 MapReduce 的延遲。 這正是使 Impala 比 Hive 快得多的原因。
Impala – 功能
Impala 的主要特點是:
- 它在 Apache 許可下可作為開源 SQL 查詢引擎使用。
- 它允許您使用類似 SQL 的查詢來訪問數據。
- 它支持內存數據處理——它訪問和分析存儲在 Hadoop 數據節點上的數據。
- 它允許您將數據存儲在 HDFS、Apache HBase 和 Amazon s3 等存儲系統中。
- 它可以輕鬆與 Tableau、Pentaho 和 Micro strategy 等 BI 工具集成。
- 它支持各種文件格式,包括 Sequence File、Avro、LZO、RCFile 和 Parquet。
Impala – 主要優勢
使用 Impala 為用戶提供了一些顯著的優勢,例如:
- 由於 Impala 支持內存中數據處理(處理髮生在數據所在的位置 - 在 Hadoop 集群上),因此不需要數據轉換和數據移動。
- 要使用 Impala 訪問存儲在 HDFS、HBase 或 Amazon s3 中的數據,您不需要任何 Java(MapReduce 作業)的先驗知識——您可以使用基本的 SQL 查詢輕鬆訪問它。
- 通常,在業務工具中編寫查詢時,數據必須經歷複雜的提取-轉換-加載 (ETL) 循環。 然而,有了 Impala,就不需要這樣做了。 Impala 用探索性數據分析和數據發現等先進技術取代了耗時的加載和重組階段,從而提高了流程的速度。
- Impala 是使用 Parquet 文件格式的先驅,這是一種列式存儲佈局,針對數據倉庫中的大規模查詢進行了優化。
Impala – 缺點
儘管 Impala 提供了許多好處,但它也有一定的局限性:
- 它不支持序列化和反序列化。
- 它無法讀取自定義二進製文件; 它只能讀取文本文件。
- 每次向 HDFS 中的數據目錄添加新記錄或文件時,都需要刷新數據表。
Impala – 建築
Impala 與其存儲引擎分離(與傳統存儲系統相反)。 它包括三個主要組件——Impala Daemon (Impalad) 、Impala StateStore 和 Impala Metadata & MetaStore。
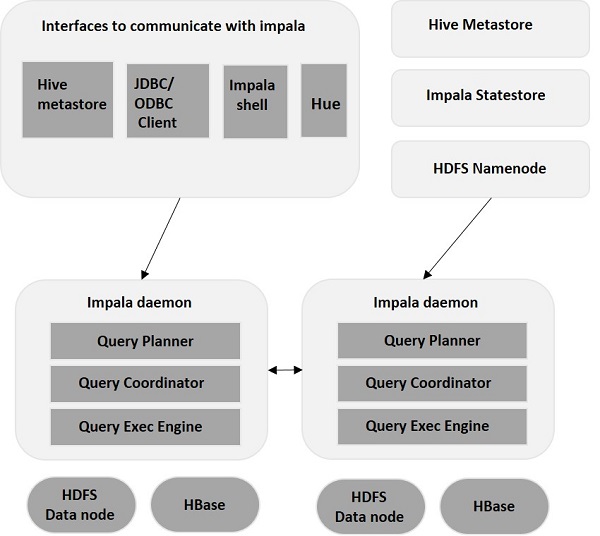
黑斑羚守護進程
Impala Daemon,又名 Impalad,在安裝 Impala 的各個節點上運行。 它接受來自多個接口(Impala shell、Hue 瀏覽器等)的查詢並處理它們。 每次向特定節點上的 Impalad 提交查詢時,該節點都會成為該查詢的“協調節點”。 通過這種方式,多個查詢由運行在其他節點上的 Impalad 提供服務。
一旦接受查詢, Impalad 就會讀取和寫入數據文件,並通過將任務分發到集群中的其他 Impala 節點來並行化查詢。 用戶可以根據自己的要求將查詢提交給專用的Impalad ,或者以負載均衡的方式提交給集群中的其他Impalad 。 然後這些查詢開始處理不同的Impalad 實例並將結果返回到主協調節點。
Impala StateStore
Impala StateStore 監控和檢查每個Impalad的健康狀況,並將每個 Impala Daemon 健康狀況的健康報告轉發給其他守護進程。 它可以在運行 Impala 服務器的同一節點上運行,也可以在集群中的另一個節點上運行。 如果由於某種原因出現節點故障,Impala StateStore 會更新所有其他節點的故障信息。 在這種情況下,其他 Impala 守護進程停止將任何進一步的查詢分配給故障節點。
Impala 元數據和元存儲
在 Impala 中,所有關鍵信息,包括表定義、表和列信息等,都存儲在稱為 MetaStore 的集中式數據庫中。 在處理包含多個分區的大量數據時,獲取特定於表的元數據變得具有挑戰性。 這就是 Impala 來救援的地方。 由於各個 Impala 節點在本地緩存所有元數據,因此很容易立即獲取特定信息。
每次更新表定義/表數據時,所有 Impala 守護進程還必須通過檢索最新元數據來更新其元數據緩存,然後才能針對特定表發出新查詢。
Impala – 安裝 Impala
就像您需要在 Linux 操作系統上安裝 Hadoop 及其生態系統一樣,您可以使用 Impala 執行相同的操作。 由於是 Cloudera 首次發布 Impala,您可以通過 Cloudera QuickStart VM 輕鬆訪問它。
閱讀: Hadoop 教程
如何下載 Cloudera 快速入門 VM
要下載 Cloudera QuickStart VM,您必須按照以下步驟進行操作。
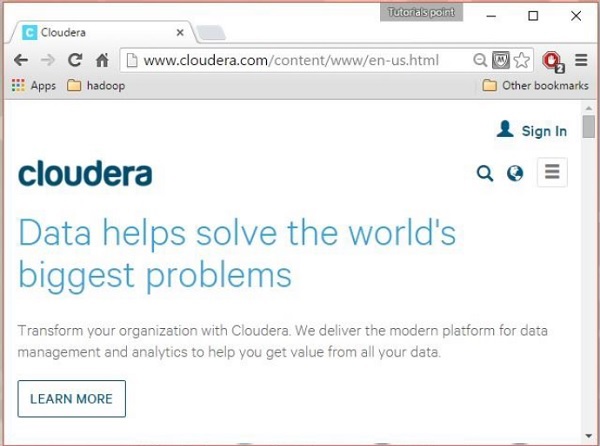
第1步
打開 Cloudera 主頁 ( http://www.cloudera.com/ ),您會發現如下內容:
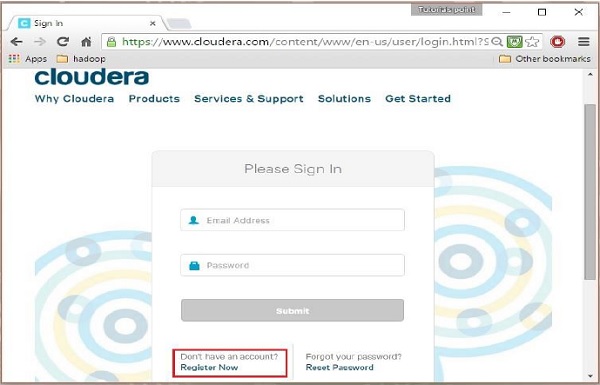
第2步
要在 Cloudera 上註冊,您必須單擊“立即註冊”選項,這將打開“帳戶註冊”頁面。 如果您已經在 Cloudera 上註冊,您可以點擊頁面上的“登錄”選項,它會進一步將您重定向到登錄頁面,如下所示:
第 3 步
登錄後,點擊頁面左上角的“下載”選項,打開網站的下載頁面,如下圖:
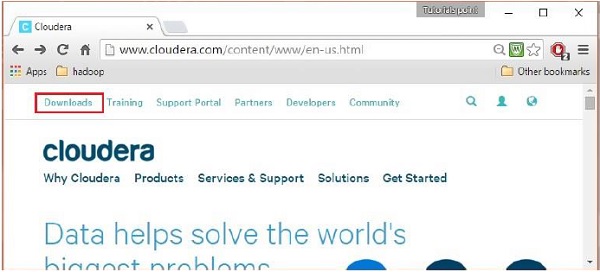
第四步
在此步驟中,您需要通過單擊“立即下載”選項來下載 Cloudera QuickStartVM,如下所示:
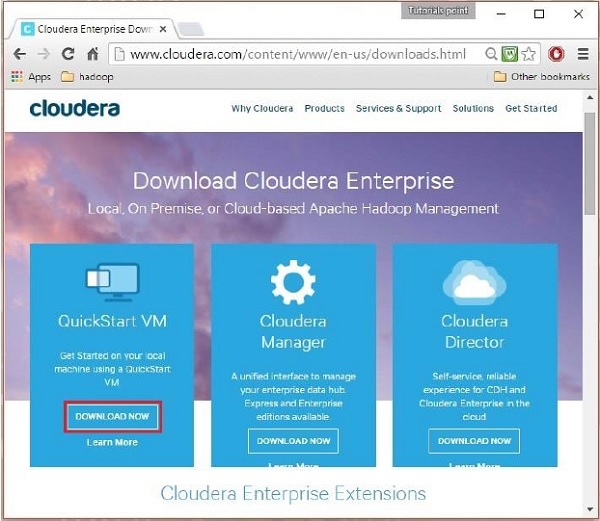
單擊立即下載選項會將您重定向到 QuickStart VM 的下載頁面:
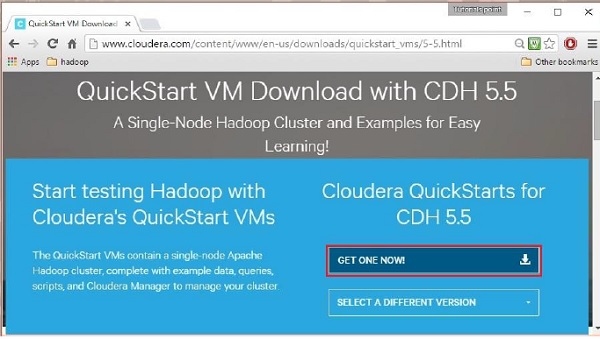
然後您必須選擇 GET ONE NOW 選項,接受許可協議,然後提交,如下所示:
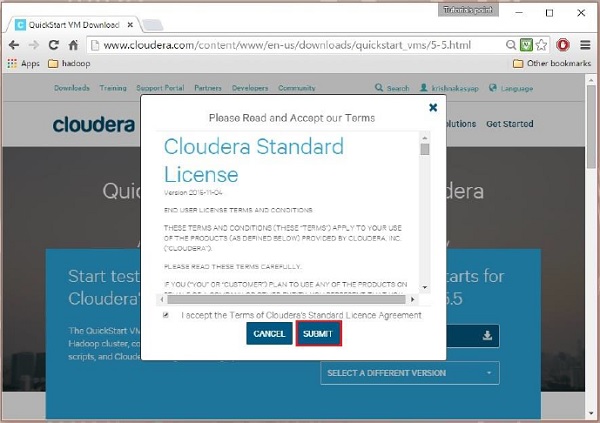
下載完成後,您會發現三個不同的 Cloudera VM Compatible 選項——VMware、KVM 和 VIRTUALBOX。 您可以選擇您喜歡的選項。
資源
Impala – 查詢處理接口
Impala 提供了三個處理查詢的接口:
Impala-shell –使用 Cloudera VM 安裝和設置 Impala 後,您可以通過在編輯器中鍵入命令“impala-shell”來激活 Impala-shell。
閱讀:大數據和 Hadoop 之間的區別
Hue 界面 – Hue 瀏覽器允許您處理 Impala 查詢。 它有一個 Impala 查詢編輯器,您可以在其中鍵入和執行不同的 Impala 查詢。 但是,要使用編輯器,首先需要登錄 Hue 瀏覽器。
ODBC/JDBC 驅動程序——與每個數據庫一樣,Impala 也提供 ODBC/JDBC 驅動程序。 這些驅動程序允許您通過支持它們的編程語言(ODBC/JDBC 驅動程序)連接到 Impala,並使用相同的編程語言構建在 Impala 中處理查詢的應用程序。

查詢執行過程
每當您使用任何 Impala 接口傳遞查詢時,集群中的 Impalad 通常都會接受您的查詢。 然後這個 Impalad 將成為該特定查詢的協調節點。 收到查詢後,協調器使用 Hive Metastore 中的 Table Schema 驗證查詢是否合適。
在此之後,它從 HDFS 名稱節點收集有關執行查詢所需的數據位置的信息,並將此信息轉發到層次結構中的其他 Impalad 以促進查詢執行。 一旦 Impalads 讀取指定的數據塊,它們就會處理查詢。 當集群中的所有 Impalad 處理完查詢後,協調器節點會收集結果並將其交付給您。
Impala Shell 命令
如果您熟悉 Hive Shell,則可以輕鬆找出 Impala Shell,因為它們具有非常相似的結構——它們允許創建數據庫和表、插入數據和發出查詢。 Impala Shell 命令分為三大類:通用命令、查詢特定選項以及表和數據庫特定選項。
一般命令
- 幫助
help 命令提供了 Impala 中可用的有用命令列表。
[quickstart.cloudera:21000] > 幫助;
記錄的命令(輸入幫助 <topic>):
==================================================== ======
計算描述插入集未設置版本
連接解釋退出顯示值使用
退出歷史配置文件選擇外殼提示
未記錄的命令:
==========================================
alter create desc drop help load 摘要
- 版本
此命令為您提供 Impala 的當前版本。
[quickstart.cloudera:21000] > 版本;
Shell 版本:Impala Shell v2.3.0-cdh5.5.0 (0c891d7) 於 11 月 9 日星期一構建
2015 年太平洋標準時間 12:18:12
服務器版本:impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- 歷史
此命令顯示在 Impala Shell 中執行的最後十個命令。
[quickstart.cloudera:21000] > 歷史;
[1]:版本;
[2]:幫助;
[3]:顯示數據庫;
[4]:使用 my_db;
[5]:歷史;
- 連接
此命令有助於連接到給定的 Impala 實例。 如果您不指定任何實例,則默認情況下,它將連接到默認端口 21000。
[quickstart.cloudera:21000] > 連接;
連接到 quickstart.cloudera:21000
服務器版本:impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- 退出/退出
顧名思義,exit/quit 命令讓您退出 Impala Shell。
[quickstart.cloudera:21000] > 退出;
再見雲時代
查詢特定選項
- 解釋
此命令返回特定查詢的執行計劃。
[quickstart.cloudera:21000] > 解釋 select * from sample;
查詢:說明 select * from sample
+——————————————————————————————+
| 解釋字符串
|
+——————————————————————————————+
| 估計的每台主機要求:內存 = 48.00MB VCores = 1
|
| 警告:以下表格缺少相關的表格和/或列統計信息。 |
| my_db.customers |
| 01:EXCHANGE [未分區]
|
| 00:掃描 HDFS [my_db.customers] |
| 分區 = 1/1 文件 = 6 大小 = 148B |
+——————————————————————————————+
在 0.17 秒內獲取 7 行
- 輪廓
此命令顯示有關最近/最新查詢的低級信息。 它用於查詢的診斷和性能調整。
[快速入門。 cloudera : 21000 ] >個人資料;
查詢運行時配置文件:
查詢( id = 164b1294a1049189 : a67598a6699e3ab6 ):
摘要:
會話ID : e74927207cd752b5 : 65ca61e630ad3ad
會話類型: BEESWAX
開始時間: 2016 – 04 – 17 23 : 49 : 26.08148000結束時間: 2016 – 04 – 17 23 : 49 : 26.2404000
查詢類型:解釋
查詢狀態:已完成
查詢狀態: OK
Impala版本: impalad 2.3版。 0 - cdh5 。 5.0發布(構建0c891d77280e2129b )
用戶: cloudera
連接用戶: cloudera
委託用戶:
網絡地址: 10.0 。 2.15 : 43870
默認數據庫: my_db
Sql語句:解釋select * from sample
協調員:快速入門。 雲時代: 22000
: 0ns
查詢時間線: 167.304ms
–開始執行: 41.292us ( 41.292us ) –計劃完成: 56.42ms ( 56.386ms )
–可用行數: 58.247 毫秒( 1.819 毫秒)
–獲取的第一行: 160.72ms ( 101.824ms )
–註銷查詢: 166.325ms ( 6.253ms )
黑斑服務器:
– ClientFetchWaitTimer : 107.969ms
– RowMaterializationTimer : 0ns
表和數據庫特定選項
- 改變
alter 命令有助於更改表的結構和名稱。
- 描述
describe 命令提供表的元數據。 它包含列及其數據類型等信息。
- 降低
drop 命令有助於刪除一個構造,它可以是一個表、一個視圖或一個數據庫函數。
- 插入
insert 命令有助於將數據(列)附加到表中並覆蓋現有表的數據
- 選擇
select 命令可用於對特定數據集執行特定操作。 它通常提到要在其上完成操作的數據集。
- 顯示
show 命令顯示各種結構(如表和數據庫)的元存儲。
- 採用
use 命令有助於更改特定數據庫的當前上下文。
黑斑羚 – 評論
在 Impala 中,註釋類似於 SQL 語言中的註釋。 通常,有兩種類型的註釋:
單行註釋
後跟“-”的每一行都成為 Impala 中的註釋。
— 您好,歡迎來到 upGrad。
多行註釋
/* 和 */ 之間的所有行都是 Impala 中的多行註釋。
/*
你好這是一個例子

Impala 中的多行註釋
*/
結論
我們希望這個詳細的 Impala 教程可以幫助您了解它的複雜性以及它的功能。
如果您有興趣了解有關大數據的更多信息,請查看我們的 PG 大數據軟件開發專業文憑課程,該課程專為在職專業人士設計,提供 7 多個案例研究和項目,涵蓋 14 種編程語言和工具,實用的動手操作研討會,超過 400 小時的嚴格學習和頂級公司的就業幫助。
從世界頂級大學在線學習軟件開發課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。