Ultimatives Impala Hadoop-Tutorial, das Sie jemals brauchen werden [2022]
Veröffentlicht: 2020-05-14Impala ist eine native Open-Source-Analysedatenbank, die für geclusterte Plattformen wie Apache Hadoop entwickelt wurde. Es handelt sich um eine interaktive SQL-ähnliche Abfrage-Engine, die auf dem Hadoop Distributed File System (HDFS) läuft, um die Verarbeitung großer Datenmengen mit blitzschneller Geschwindigkeit zu ermöglichen. Außerdem ist Impala eines der besten Hadoop-Tools zur Nutzung von Big Data. Heute werden wir über alles reden, was mit Impala zu tun hat, und deshalb haben wir dieses Impala-Tutorial für Sie entworfen!
Dieses Impala Hadoop-Tutorial ist speziell für diejenigen gedacht, die Impala lernen möchten. Um jedoch den größtmöglichen Nutzen aus diesem Impala-Lernprogramm zu ziehen, wäre es hilfreich, wenn Sie ein tiefgreifendes Verständnis der Grundlagen von SQL zusammen mit Hadoop- und HDFS-Befehlen haben.
Inhaltsverzeichnis
Was ist Impala?
Impala ist eine in C++ und Java geschriebene MPP-SQL-Abfragemaschine (Massive Parallel Processing) . Sein Hauptzweck ist die Verarbeitung großer Datenmengen, die in Hadoop-Clustern gespeichert sind. Impala verspricht hohe Leistung und geringe Latenz und ist bis heute die leistungsstärkste SQL-Engine (die ein RDBMS-ähnliches Erlebnis bietet), um den schnellsten Weg für den Zugriff auf und die Verarbeitung von in HDFS gespeicherten Daten zu bieten.
Ein weiterer vorteilhafter Aspekt von Impala ist die Integration in den Hive-Metastore, um die gemeinsame Nutzung der Tabelleninformationen zwischen beiden Komponenten zu ermöglichen. Es nutzt den vorhandenen Apache Hive, um stapelorientierte, lang andauernde Jobs im SQL-Abfrageformat auszuführen. Die Impala-Hive-Integration ermöglicht es Ihnen, eine der beiden Komponenten – Hive oder Impala – für die Datenverarbeitung zu verwenden oder Tabellen unter einem einzigen gemeinsam genutzten Dateisystem (HDFS) zu erstellen, ohne die Tabellendefinition zu ändern.
Warum Impala?
Impala kombiniert die Mehrbenutzerleistung einer herkömmlichen analytischen Datenbank und SQL-Unterstützung mit der Skalierbarkeit und Flexibilität von Apache Hadoop. Dazu werden Standard-Hadoop-Komponenten wie HDFS, HBase, YARN, Sentry und Metastore verwendet. Da Impala dieselben Metadaten, Benutzeroberflächen (Hue Beeswax), SQL-Syntax (Hive SQL) und ODBC-Treiber (Open Database Connectivity) wie Apache Hive verwendet, schafft es eine einheitliche und vertraute Plattform für Batch-orientierte und Echtzeit-Abfragen.
Lesen Sie: Big-Data-Projektideen für Anfänger

Impala kann fast alle von Hadoop verwendeten Dateiformate lesen, einschließlich Parquet, Avro und RCFile. Außerdem basiert Impala nicht auf MapReduce-Algorithmen – es implementiert eine verteilte Architektur basierend auf Daemon-Prozessen, die alles verarbeiten und verwalten, was mit der Abfrageausführung zu tun hat, die auf denselben Computern ausgeführt wird. Infolgedessen trägt es dazu bei, die Latenz bei der Verwendung von MapReduce zu reduzieren. Genau das macht Impala viel schneller als Hive.
Impala – Eigenschaften
Die Hauptmerkmale von Impala sind:
- Es ist als Open-Source-SQL-Abfrage-Engine unter der Apache-Lizenz verfügbar.
- Sie können auf Daten zugreifen, indem Sie SQL-ähnliche Abfragen verwenden.
- Es unterstützt die In-Memory-Datenverarbeitung – es greift auf Daten zu, die auf Hadoop-Datenknoten gespeichert sind, und analysiert diese.
- Es ermöglicht Ihnen, Daten in Speichersystemen wie HDFS, Apache HBase und Amazon s3 zu speichern.
- Es lässt sich problemlos in BI-Tools wie Tableau, Pentaho und Micro Strategy integrieren.
- Es unterstützt verschiedene Dateiformate, darunter Sequence File, Avro, LZO, RCFile und Parquet.
Impala – Hauptvorteile
Die Verwendung von Impala bietet den Benutzern einige erhebliche Vorteile, wie zum Beispiel:
- Da Impala In-Memory-Datenverarbeitung unterstützt (die Verarbeitung erfolgt dort, wo sich die Daten befinden – auf dem Hadoop-Cluster), besteht keine Notwendigkeit für Datentransformation und Datenverschiebung.
- Um mit Impala auf Daten zuzugreifen, die in HDFS, HBase oder Amazon s3 gespeichert sind, benötigen Sie keine Vorkenntnisse in Java (MapReduce-Jobs) – Sie können einfach mit einfachen SQL-Abfragen darauf zugreifen.
- Im Allgemeinen müssen Daten beim Schreiben von Abfragen in Geschäftstools einen komplizierten ETL-Zyklus (Extract-Transform-Load) durchlaufen. Bei Impala ist dies jedoch nicht erforderlich. Impala ersetzt die zeitaufwändigen Phasen des Ladens und Neuorganisierens durch fortschrittliche Techniken wie explorative Datenanalyse und Datenermittlung, wodurch der Prozess beschleunigt wird.
- Impala ist ein Pionier bei der Verwendung des Parquet-Dateiformats, einem spaltenförmigen Speicherlayout, das für umfangreiche Abfragen in Data Warehouses optimiert ist.
Impala – Nachteile
Obwohl Impala zahlreiche Vorteile bietet, hat es auch gewisse Einschränkungen:
- Es bietet keine Unterstützung für Serialisierung und Deserialisierung.
- Es kann keine benutzerdefinierten Binärdateien lesen; Es kann nur Textdateien lesen.
- Jedes Mal, wenn dem Datenverzeichnis in HDFS neue Datensätze oder Dateien hinzugefügt werden, müssen Sie die Datentabelle aktualisieren.
Impala – Architektur
Impala ist von seiner Speicher-Engine entkoppelt (im Gegensatz zu herkömmlichen Speichersystemen). Es umfasst drei Hauptkomponenten – Impala Daemon (Impalad) , Impala StateStore und Impala Metadata & MetaStore.
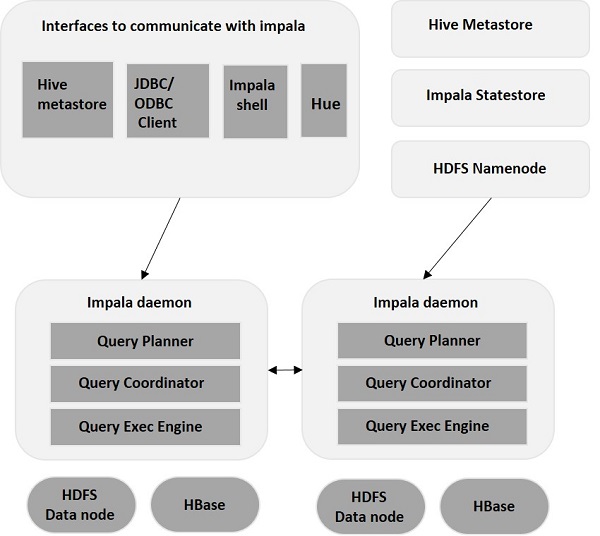
Impala-Dämon
Impala Daemon, auch bekannt als Impalad, läuft auf einzelnen Knoten, auf denen Impala installiert ist. Es akzeptiert Anfragen von mehreren Schnittstellen (Impala-Shell, Hue-Browser usw.) und verarbeitet sie. Jedes Mal, wenn eine Abfrage an einen Impalad auf einem bestimmten Knoten gesendet wird, wird der Knoten zu einem „Koordinatorknoten“ für diese Abfrage. Auf diese Weise werden mehrere Abfragen von Impalad bedient, das auf anderen Knoten ausgeführt wird.
Sobald die Abfragen akzeptiert wurden, liest und schreibt Impalad Datendateien und parallelisiert die Abfragen, indem es die Aufgabe an die anderen Impala-Knoten im Cluster verteilt. Benutzer können je nach ihren Anforderungen Abfragen entweder an ein dediziertes Impalad oder mit Lastenausgleich an andere Impalads im Cluster senden. Diese Abfragen beginnen dann mit der Verarbeitung auf den verschiedenen Impalad-Instanzen und geben das Ergebnis an den primären Koordinierungsknoten zurück.
Impala StateStore
Der Impala StateStore überwacht und überprüft den Zustand jedes Impalads und leitet auch den Zustandsbericht des Zustands jedes Impala-Daemons an die anderen Daemons weiter. Es kann auf demselben Knoten ausgeführt werden, auf dem der Impala-Server ausgeführt wird, oder auf einem anderen Knoten im Cluster. Falls aus irgendeinem Grund ein Knoten ausfällt, aktualisiert der Impala StateStore alle anderen Knoten über den Ausfall. In einem solchen Fall stellen die anderen Impala-Daemons die Zuweisung weiterer Abfragen an den ausgefallenen Knoten ein.
Impala-Metadaten und MetaStore
In Impala werden alle wichtigen Informationen, einschließlich Tabellendefinitionen, Tabellen- und Spalteninformationen usw., in einer zentralen Datenbank gespeichert, die als MetaStore bekannt ist. Beim Umgang mit beträchtlichen Datenmengen, die mehrere Partitionen enthalten, wird es schwierig, tabellenspezifische Metadaten zu erhalten. Hier kommt Impala zur Rettung. Da einzelne Impala-Knoten alle Metadaten lokal zwischenspeichern, wird es einfach, spezifische Informationen sofort zu erhalten.
Jedes Mal, wenn Sie die Tabellendefinition/Tabellendaten aktualisieren, müssen alle Impala-Daemons auch ihren Metadaten-Cache aktualisieren, indem sie die neuesten Metadaten abrufen, bevor sie eine neue Abfrage für eine bestimmte Tabelle ausführen können.
Impala – Installation von Impala
So wie Sie Hadoop und sein Ökosystem unter Linux OS installieren müssen, können Sie dasselbe mit Impala tun. Da Impala zuerst von Cloudera ausgeliefert wurde, können Sie ganz einfach über die Cloudera QuickStart VM darauf zugreifen.
Lesen Sie: Hadoop-Tutorial
So laden Sie die Cloudera QuickStart-VM herunter
Um die Cloudera QuickStart-VM herunterzuladen, müssen Sie die unten beschriebenen Schritte ausführen.
Schritt 1
Öffnen Sie die Cloudera-Homepage ( http://www.cloudera.com/ ), und Sie werden so etwas finden:
Schritt 2
Um sich bei Cloudera zu registrieren, müssen Sie auf die Option „Jetzt registrieren“ klicken, wodurch die Seite „Kontoregistrierung“ geöffnet wird. Wenn Sie bereits bei Cloudera registriert sind, können Sie auf der Seite auf die Option „Anmelden“ klicken, die Sie wie folgt weiter zur Anmeldeseite weiterleitet:
Schritt 3
Sobald Sie sich angemeldet haben, öffnen Sie die Download-Seite der Website, indem Sie auf die Option „Downloads“ in der oberen linken Ecke der Seite klicken, wie unten gezeigt:
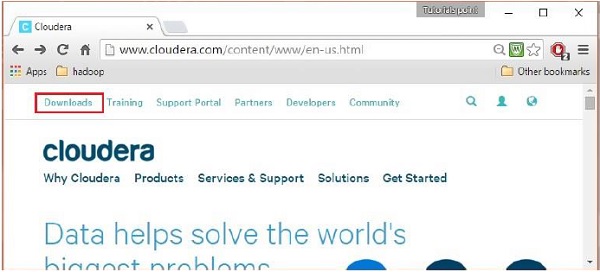
Schritt 4
In diesem Schritt müssen Sie die Cloudera QuickStartVM herunterladen, indem Sie wie folgt auf die Option „Jetzt herunterladen“ klicken:
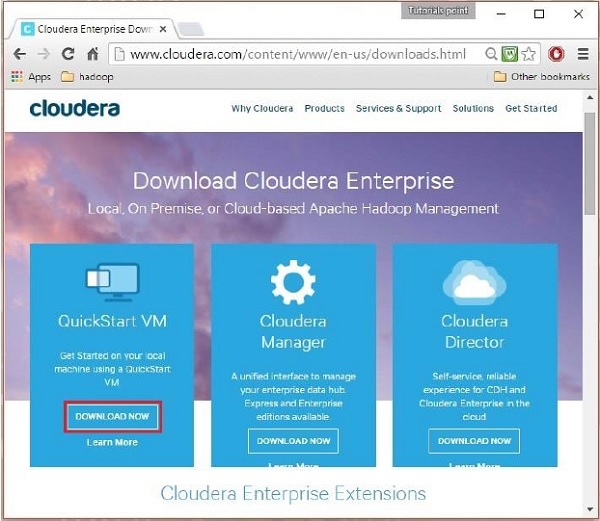
Wenn Sie auf die Option Jetzt herunterladen klicken, werden Sie zur Downloadseite von QuickStart VM weitergeleitet:
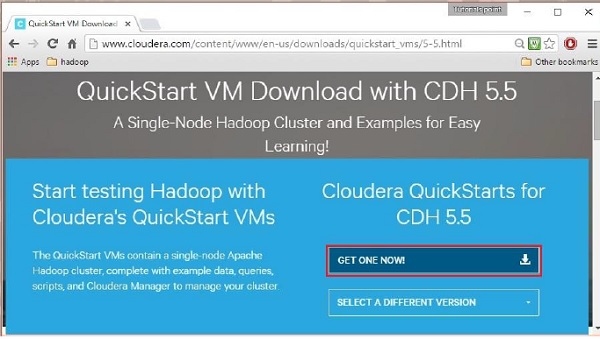
Dann müssen Sie die Option GET ONE NOW auswählen, die Lizenzvereinbarung akzeptieren und wie unten gezeigt einreichen:
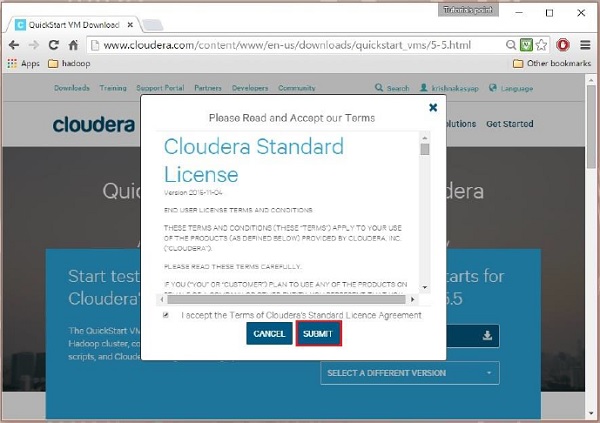

Nachdem der Download abgeschlossen ist, finden Sie drei verschiedene Cloudera VM-kompatible Optionen – VMware, KVM und VIRTUALBOX. Sie können Ihre bevorzugte Option auswählen.
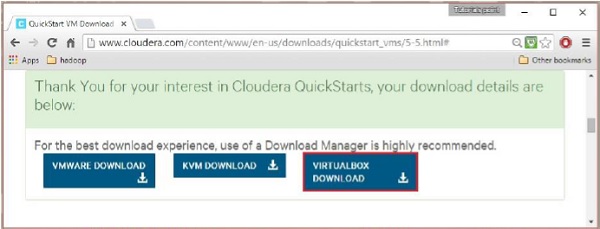
Quelle
Impala – Abfrageverarbeitungsschnittstellen
Impala bietet drei Schnittstellen zur Verarbeitung von Anfragen:
Impala-shell – Nachdem Sie Impala mithilfe der Cloudera-VM installiert und eingerichtet haben, können Sie Impala-shell aktivieren, indem Sie den Befehl „impala-shell“ in den Editor eingeben.
Lesen Sie: Unterschied zwischen Big Data und Hadoop
Hue-Oberfläche – Mit dem Hue-Browser können Sie Impala-Anfragen verarbeiten. Es verfügt über einen Impala-Abfrage-Editor, in dem Sie verschiedene Impala-Abfragen eingeben und ausführen können. Um den Editor zu verwenden, müssen Sie sich jedoch zuerst beim Hue-Browser anmelden.
ODBC/JDBC-Treiber – Wie jede Datenbank bietet auch Impala ODBC/JDBC-Treiber an. Mit diesen Treibern können Sie über Programmiersprachen, die sie unterstützen (ODBC/JDBC-Treiber), eine Verbindung zu Impala herstellen und Anwendungen erstellen, die Abfragen in Impala mit denselben Programmiersprachen verarbeiten.
Abfrageausführungsverfahren
Immer wenn Sie eine Abfrage über eine beliebige Impala-Schnittstelle übergeben, akzeptiert normalerweise ein Impalad im Cluster Ihre Abfrage. Dieser Impalad wird dann zum Koordinatorknoten für diese bestimmte Abfrage. Nach Erhalt der Abfrage überprüft der Koordinator, ob die Abfrage angemessen ist, indem er das Tabellenschema aus dem Hive-Metastore verwendet.
Danach sammelt es Informationen über den Speicherort der Daten, die für die Abfrageausführung vom HDFS-Namensknoten benötigt werden, und leitet diese Informationen an andere Impalads in der Hierarchie weiter, um die Abfrageausführung zu erleichtern. Sobald die Impalads den angegebenen Datenblock gelesen haben, verarbeiten sie die Abfrage. Wenn alle Impalads im Cluster die Abfrage verarbeitet haben, sammelt der Koordinatorknoten das Ergebnis und liefert es Ihnen.
Impala Shell-Befehle
Wenn Sie mit Hive Shell vertraut sind, können Sie Impala Shell leicht herausfinden, da beide eine ziemlich ähnliche Struktur haben – sie ermöglichen das Erstellen von Datenbanken und Tabellen, das Einfügen von Daten und das Ausgeben von Abfragen. Impala-Shell-Befehle fallen in drei große Kategorien: allgemeine Befehle, abfragespezifische Optionen und tabellen- und datenbankspezifische Optionen.
Allgemeine Befehle
- Hilfe
Der Hilfebefehl bietet eine Liste nützlicher Befehle, die in Impala verfügbar sind.
[quickstart.cloudera:21000] > Hilfe;
Dokumentierte Befehle (geben Sie help <topic> ein):
=============================================== ======
berechnen beschreiben einfügen set mit Version nicht gesetzt
Verbinden Erklären Beenden Werte anzeigen Verwenden
Verlaufsprofil verlassen Shell-Tipp auswählen
Undokumentierte Befehle:
=======================================
alter create desc drop help Zusammenfassung laden
- Ausführung
Dieser Befehl liefert Ihnen die aktuelle Version von Impala.
[quickstart.cloudera:21000] > Version;
Shell-Version: Impala Shell v2.3.0-cdh5.5.0 (0c891d7), erstellt am Montag, 9. November
12:18:12 PST 2015
Serverversion: Impalad-Version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- Geschichte
Dieser Befehl zeigt die letzten zehn in Impala Shell ausgeführten Befehle an.
[quickstart.cloudera:21000] > Verlauf;
[1]:Version;
[2]:Hilfe;
[3]: Datenbanken anzeigen;
[4]:use my_db;
[5]:Geschichte;
- anschließen
Dieser Befehl hilft beim Herstellen einer Verbindung zu einer bestimmten Instanz von Impala. Wenn Sie keine Instanz angeben, wird standardmäßig eine Verbindung zum Standardport 21000 hergestellt.
[quickstart.cloudera:21000] > verbinden;
Verbunden mit quickstart.cloudera:21000
Serverversion: Impalad-Version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- verlassen/beenden
Wie der Name schon sagt, können Sie mit dem Befehl exit/quit die Impala Shell verlassen.
[quickstart.cloudera:21000] > beenden;
Auf Wiedersehen cloudera
Abfragespezifische Optionen
- erklären
Dieser Befehl gibt den Ausführungsplan für eine bestimmte Abfrage zurück.
[quickstart.cloudera:21000] > Erklären Sie select * from sample;
Abfrage: Erkläre select * from sample
+————————————————————————————+
| Erklären Sie Zeichenfolge
|
+————————————————————————————+
| Geschätzte Anforderungen pro Host: Arbeitsspeicher = 48,00 MB VCores = 1
|
| WARNUNG: In den folgenden Tabellen fehlen relevante Tabellen- und/oder Spaltenstatistiken. |
| meine_db.kunden |
| 01:AUSTAUSCH [UNPARTITIONIERT]
|
| 00:SCAN HDFS [meine_db.kunden] |
| Partitionen = 1/1 Dateien = 6 Größe = 148B |
+————————————————————————————+
7 Zeile(n) in 0,17 s abgerufen
- Profil
Dieser Befehl zeigt die Low-Level-Informationen über die letzte/neueste Abfrage an. Es wird zur Diagnose und Leistungsoptimierung einer Abfrage verwendet.
[ Schnellstart . Cloudera : 21000 ] > Profil ;
Laufzeitprofil abfragen : _
Abfrage ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Zusammenfassung :
Sitzungs - ID : e74927207cd752b5 : 65ca61e630ad3ad
Sitzungstyp : BIENENWACHS _
Startzeit : 2016 – 04 – 17 23 : 49 : 26.08148000 Endzeit : 2016 – 04 – 17 23 : 49 : 26.2404000 _ _
Abfragetyp : EXPLAIN _
Abfragestatus : BEENDET _
Abfragestatus : OK _
Impala - Version : Impalad-Version 2.3 . 0 – cdh5 . 5.0 - VERSION ( build 0c891d77280e2129b )
Benutzer : cloudera
Verbundener Benutzer : cloudera
Delegierter Benutzer :
Netzwerkadresse : 10.0 . _ 2.15 : 43870
Standard -DB : my_db
SQL- Anweisung : Erklären Sie select * from sample
Koordinator : Schnellstart . Cloudera : 22000
: 0ns
Abfragezeitachse : 167,304 ms
– Ausführung starten : 41.292us ( 41.292us ) – Planung beendet : 56.42ms ( 56.386ms )
– Verfügbare Zeilen : 58,247 ms ( 1,819 ms )
– Erste Zeile abgerufen : 160,72 ms ( 101,824 ms )
– Abmeldungsabfrage : 166,325 ms ( 6,253 ms )
ImpalaServer :
– ClientFetchWaitTimer : 107,969 ms
– RowMaterializationTimer : 0ns
Tabellen- und datenbankspezifische Optionen
- ändern
Der Befehl alter hilft, die Struktur und den Namen einer Tabelle zu ändern.
- beschreiben
Der Befehl "describe" stellt die Metadaten einer Tabelle bereit. Es enthält Informationen wie Spalten und deren Datentypen.
- Tropfen
Der Befehl drop hilft beim Entfernen eines Konstrukts, das eine Tabelle, eine Ansicht oder eine Datenbankfunktion sein kann.
- Einfügung
Der Einfügebefehl hilft, Daten (Spalten) in eine Tabelle einzufügen und die Daten einer bestehenden Tabelle zu überschreiben
- auswählen
Der select-Befehl kann verwendet werden, um eine bestimmte Operation an einem bestimmten Datensatz auszuführen. In der Regel wird der Datensatz erwähnt, an dem die Aktion ausgeführt werden soll.
- Show
Der Befehl show zeigt den Metastore verschiedener Konstrukte wie Tabellen und Datenbanken an.
- verwenden
Der use-Befehl hilft, den aktuellen Kontext einer bestimmten Datenbank zu ändern.
Impala – Kommentare
In Impala ähneln die Kommentare denen in der SQL-Sprache. Normalerweise gibt es zwei Arten von Kommentaren:
Einzeilige Kommentare
Jede Zeile, auf die „—“ folgt, wird in Impala zu einem Kommentar.
— Hallo, willkommen bei upGrad.
Mehrzeilige Kommentare
Alle Zeilen zwischen /* und */ sind mehrzeilige Kommentare in Impala.
/*
Hallo, das ist ein Beispiel

Von mehrzeiligen Kommentaren in Impala
*/
Fazit
Wir hoffen, dass dieses ausführliche Impala-Tutorial Ihnen geholfen hat, seine Feinheiten und seine Funktionsweise zu verstehen.
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.
Lernen Sie Softwareentwicklungskurse online von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.