Tutorial Impala Hadoop Terbaik yang Anda Butuhkan [2022]
Diterbitkan: 2020-05-14Impala adalah database analitik asli open-source yang dirancang untuk platform cluster seperti Apache Hadoop. Ini adalah mesin kueri seperti SQL interaktif yang berjalan di atas Hadoop Distributed File System (HDFS) untuk memfasilitasi pemrosesan volume data yang sangat besar dengan kecepatan secepat kilat. Juga, impala adalah salah satu alat Hadoop teratas untuk menggunakan data besar. Hari ini, kita akan membicarakan semua hal tentang Impala, dan karenanya, kami telah merancang tutorial Impala ini untuk Anda!
Tutorial Impala Hadoop ini khusus ditujukan bagi mereka yang ingin belajar Impala. Namun, untuk mendapatkan manfaat maksimal dari tutorial Impala ini, akan sangat membantu jika Anda memiliki pemahaman mendalam tentang dasar-dasar SQL bersama dengan perintah Hadoop dan HDFS.
Daftar isi
Apa itu Impala?
Impala adalah mesin kueri SQL MPP (Massive Parallel Processing) yang ditulis dalam C++ dan Java. Tujuan utamanya adalah untuk memproses volume besar data yang disimpan di cluster Hadoop. Impala menjanjikan kinerja tinggi dan latensi rendah, dan hingga saat ini mesin SQL berperforma terbaik (yang menawarkan pengalaman seperti RDBMS) menyediakan cara tercepat untuk mengakses dan memproses data yang disimpan dalam HDFS.
Aspek lain yang bermanfaat dari Impala adalah ia terintegrasi dengan metastore Hive untuk memungkinkan berbagi informasi tabel di antara kedua komponen. Ini memanfaatkan Apache Hive yang ada untuk melakukan pekerjaan yang berorientasi batch dan berjalan lama dalam format kueri SQL. Integrasi Impala-Hive memungkinkan Anda menggunakan salah satu dari dua komponen – Hive atau Impala untuk pemrosesan data atau membuat tabel di bawah satu sistem file bersama (HDFS) tanpa mengubah definisi tabel.
Mengapa Impala?
Impala menggabungkan kinerja multi-pengguna dari database analitik tradisional dan dukungan SQL dengan skalabilitas dan fleksibilitas Apache Hadoop. Ia melakukannya dengan menggunakan komponen Hadoop standar seperti HDFS, HBase, YARN, Sentry, dan Metastore. Karena Impala menggunakan metadata, antarmuka pengguna (Hue Beeswax), sintaks SQL (Hive SQL), dan driver ODBC (Open Database Connectivity) yang sama dengan Apache Hive, Impala menciptakan platform terpadu dan akrab untuk kueri berorientasi batch dan real-time.
Baca: Ide Proyek Big Data untuk Pemula

Impala dapat membaca hampir semua format file yang digunakan Hadoop, termasuk Parket, Avro, dan RCFile. Selain itu, Impala tidak dibangun di atas algoritme MapReduce – ia mengimplementasikan arsitektur terdistribusi berdasarkan proses daemon yang menangani dan mengelola segala sesuatu yang terkait dengan eksekusi kueri yang berjalan pada mesin yang sama. Akibatnya, ini membantu mengurangi latensi penggunaan MapReduce. Inilah yang membuat Impala jauh lebih cepat daripada Hive.
Impala – Fitur
Fitur utama dari Impala adalah:
- Ini tersedia sebagai mesin kueri SQL sumber terbuka di bawah lisensi Apache.
- Ini memungkinkan Anda mengakses data dengan menggunakan kueri seperti SQL.
- Mendukung pemrosesan data dalam memori – mengakses dan menganalisis data yang disimpan di node data Hadoop.
- Ini memungkinkan Anda untuk menyimpan data dalam sistem penyimpanan seperti HDFS, Apache HBase, dan Amazon s3.
- Mudah diintegrasikan dengan alat BI seperti Tableau, Pentaho, dan strategi Mikro.
- Ini mendukung berbagai format file termasuk Sequence File, Avro, LZO, RCFile, dan Parket.
Impala – Keuntungan Utama
Menggunakan Impala menawarkan beberapa keuntungan signifikan bagi pengguna, seperti:
- Karena Impala mendukung pemrosesan data dalam memori (pemrosesan terjadi di tempat data berada – di klaster Hadoop), tidak diperlukan transformasi data dan perpindahan data.
- Untuk mengakses data yang disimpan dalam HDFS, atau HBase, atau Amazon s3 dengan Impala, Anda tidak memerlukan pengetahuan sebelumnya tentang Java (pekerjaan MapReduce) – Anda dapat dengan mudah mengaksesnya menggunakan kueri SQL dasar.
- Umumnya, data harus menjalani siklus extract-transform-load (ETL) yang rumit saat menulis kueri di alat bisnis. Namun, dengan Impala, tidak perlu untuk ini. Impala menggantikan tahapan pemuatan & penataan ulang yang memakan waktu dengan teknik canggih seperti analisis data eksplorasi & penemuan data, sehingga meningkatkan kecepatan proses.
- Impala adalah pelopor untuk menggunakan format file Parket, yang merupakan tata letak penyimpanan berbentuk kolom yang dioptimalkan untuk kueri skala besar yang ditemukan di gudang data.
Impala – Kekurangan
Meskipun Impala menawarkan banyak manfaat, ia juga memiliki batasan tertentu:
- Itu tidak memiliki dukungan untuk serialisasi dan deserialisasi.
- Itu tidak dapat membaca file biner khusus; itu hanya dapat membaca file teks.
- Setiap kali catatan atau file baru ditambahkan ke direktori data di HDFS, Anda perlu me-refresh tabel data.
Impala – Arsitektur
Impala dipisahkan dari mesin penyimpanannya (berlawanan dengan sistem penyimpanan tradisional). Ini mencakup tiga komponen utama – Impala Daemon (Impalad) , Impala StateStore, dan Impala Metadata & MetaStore.
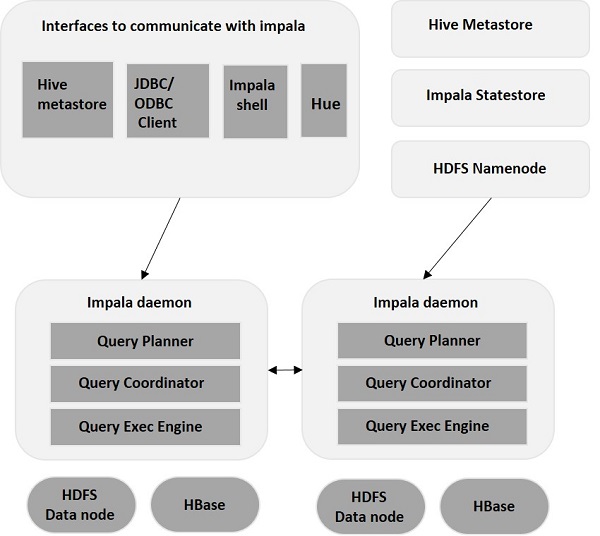
Impala Daemon
Impala Daemon, alias Impalad berjalan pada node individual tempat Impala diinstal. Ia menerima kueri dari beberapa antarmuka (Impala shell, browser Hue, dll.) dan memprosesnya. Setiap kali query dikirimkan ke Impalad pada node tertentu, node tersebut menjadi “coordinator node” untuk query tersebut. Dengan cara ini, beberapa kueri dilayani oleh Impalad yang berjalan di node lain.
Setelah kueri diterima, Impalad membaca dan menulis file data dan memparalelkan kueri dengan mendistribusikan tugas ke node Impala lain di cluster. Pengguna dapat mengirimkan kueri ke Impalad khusus atau dengan cara yang seimbang ke Impalad lain di cluster, berdasarkan kebutuhan mereka. Kueri ini kemudian mulai memproses pada instance Impalad yang berbeda dan mengembalikan hasilnya ke node koordinasi utama.
Impala StateStore
StateStore Impala memantau dan memeriksa kesehatan setiap Impala dan juga menyampaikan laporan kesehatan setiap kesehatan Daemon Impala ke daemon lainnya. Itu dapat berjalan di node yang sama di mana server Impala berjalan atau di node lain di cluster. Jika terjadi kegagalan node karena alasan tertentu, Impala StateStore memperbarui semua node lain tentang kegagalan tersebut. Dalam kejadian seperti itu, daemon Impala lainnya berhenti memberikan kueri lebih lanjut ke node yang gagal.
Impala Metadata & MetaStore
Di Impala, semua informasi penting, termasuk definisi tabel, informasi tabel dan kolom, dll., disimpan dalam database terpusat yang dikenal sebagai MetaStore. Ketika berhadapan dengan volume data yang substansial yang berisi banyak partisi, menjadi sulit untuk mendapatkan metadata khusus tabel. Di sinilah Impala datang untuk menyelamatkan. Karena node Impala individual menyimpan semua metadata secara lokal, menjadi mudah untuk mendapatkan informasi spesifik secara instan.
Setiap kali Anda memperbarui definisi tabel/data tabel, semua Daemon Impala juga harus memperbarui cache metadata mereka dengan mengambil metadata terbaru sebelum mereka dapat mengeluarkan kueri baru terhadap tabel tertentu.
Impala – Memasang Impala
Sama seperti Anda perlu menginstal Hadoop dan ekosistemnya di OS Linux, Anda dapat melakukan hal yang sama dengan Impala. Karena Cloudera yang pertama kali mengirimkan Impala, Anda dapat dengan mudah mengaksesnya melalui Cloudera QuickStart VM.
Baca: Tutorial Hadoop
Cara mengunduh VM Cloudera QuickStart
Untuk mengunduh Cloudera QuickStart VM, Anda harus mengikuti langkah-langkah yang diuraikan di bawah ini.
Langkah 1
Buka beranda Cloudera ( http://www.cloudera.com/ ), dan Anda akan menemukan sesuatu seperti ini:
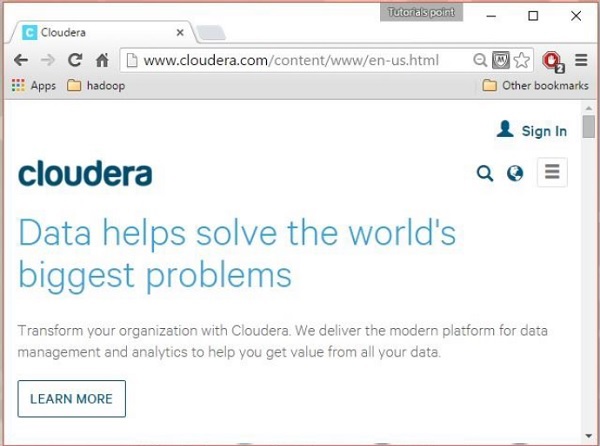
Langkah 2
Untuk mendaftar di Cloudera, Anda harus mengklik opsi “Daftar Sekarang”, yang akan membuka halaman Pendaftaran Akun. Jika Anda sudah terdaftar di Cloudera, Anda dapat mengklik opsi "Masuk" di halaman, dan selanjutnya akan mengarahkan Anda ke halaman masuk seperti:
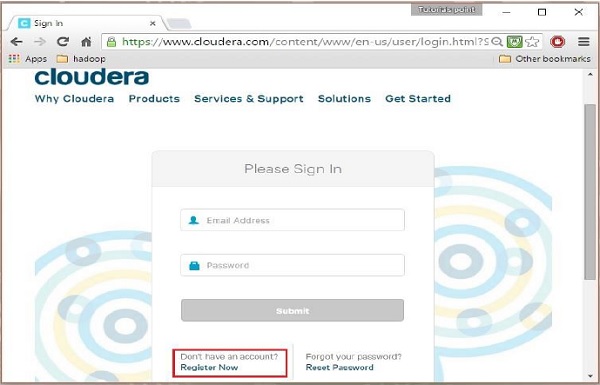
Langkah 3
Setelah Anda masuk, buka halaman unduh situs web dengan mengklik opsi "Unduhan" di sudut kiri atas halaman, seperti yang ditunjukkan di bawah ini:
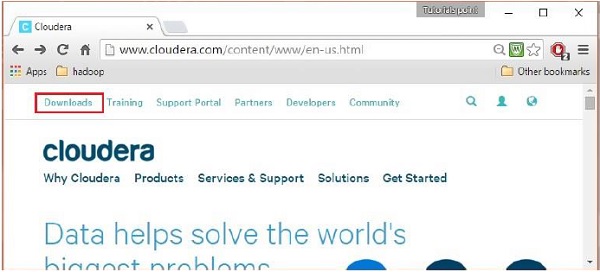
Langkah 4
Pada langkah ini, Anda perlu mengunduh Cloudera QuickStartVM dengan mengklik opsi “Unduh Sekarang” seperti:
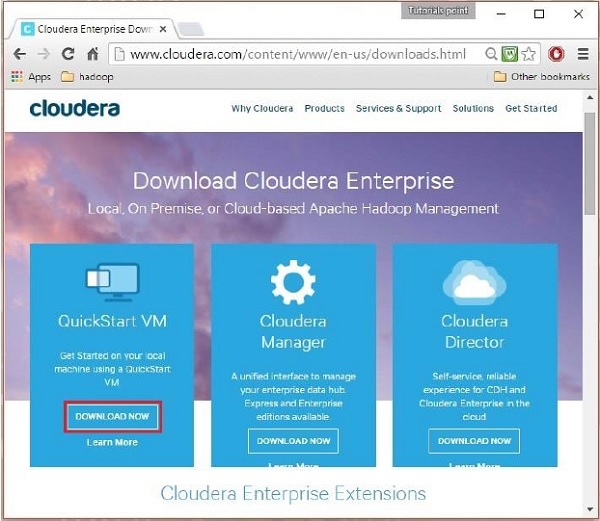
Mengklik opsi Unduh Sekarang akan mengarahkan Anda ke halaman unduhan QuickStart VM:
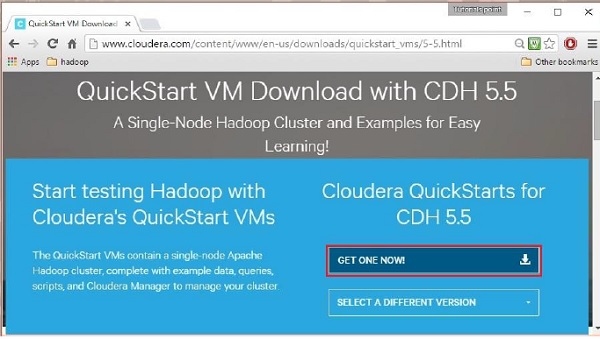
Kemudian Anda harus memilih opsi GET ONE NOW, menerima perjanjian lisensi, dan mengirimkannya seperti yang ditunjukkan di bawah ini:
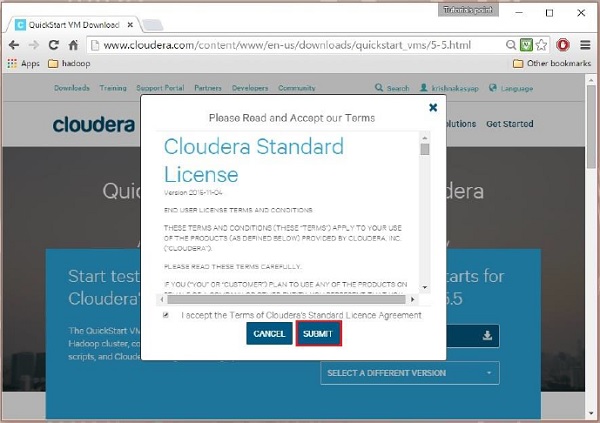
Setelah pengunduhan selesai, Anda akan menemukan tiga opsi Kompatibel Cloudera VM yang berbeda – VMware, KVM, dan VIRTUALBOX. Anda dapat memilih opsi pilihan Anda.

Sumber
Impala – Antarmuka Pemrosesan Kueri
Impala menawarkan tiga antarmuka untuk memproses kueri:
Impala-shell – Setelah Anda menginstal dan mengatur Impala menggunakan Cloudera VM, Anda dapat mengaktifkan Impala-shell dengan mengetikkan perintah “impala-shell” di editor.
Baca: Perbedaan Big Data & Hadoop
Antarmuka Hue – Peramban Hue memungkinkan Anda memproses kueri Impala. Ini memiliki editor kueri Impala tempat Anda dapat mengetik dan menjalankan kueri Impala yang berbeda. Namun, untuk menggunakan editor, pertama-tama Anda harus masuk ke browser Hue.
Driver ODBC/JDBC – Seperti halnya setiap database, Impala juga menawarkan driver ODBC/JDBC. Driver ini memungkinkan Anda terhubung ke Impala melalui bahasa pemrograman yang mendukungnya (driver ODBC/JDBC) dan membangun aplikasi yang memproses kueri di Impala menggunakan bahasa pemrograman yang sama.
Prosedur Eksekusi Kueri
Setiap kali Anda meneruskan kueri menggunakan antarmuka Impala apa pun, Impalad di kluster biasanya menerima kueri Anda. Impalad ini kemudian menjadi node koordinator untuk query tersebut. Setelah menerima kueri, koordinator memverifikasi apakah kueri sesuai atau tidak dengan menggunakan Skema Tabel dari Hive Metastore.
Setelah ini, ia mengumpulkan informasi tentang lokasi data yang diperlukan untuk eksekusi kueri dari node nama HDFS dan meneruskan informasi ini ke Impalad lain dalam hierarki untuk memfasilitasi eksekusi kueri. Setelah Impalad membaca blok data yang ditentukan, mereka memproses kueri. Ketika semua Impalad di cluster telah memproses kueri, node koordinator mengumpulkan hasilnya dan mengirimkannya kepada Anda.
Perintah Shell Impala
Jika Anda terbiasa dengan Hive Shell, Anda dapat dengan mudah mengetahui Impala Shell karena keduanya memiliki struktur yang sangat mirip – keduanya memungkinkan untuk membuat database dan tabel, menyisipkan data, dan mengeluarkan kueri. Perintah Impala Shell termasuk dalam tiga kategori besar: perintah umum, opsi khusus kueri, dan opsi khusus tabel dan basis data.
Perintah Umum
- Tolong
Perintah bantuan menawarkan daftar perintah berguna yang tersedia di Impala.
[quickstart.cloudera:21000] > bantuan;
Perintah terdokumentasi (ketik bantuan <topik>):
================================================== ======
menghitung menggambarkan sisipan set tidak disetel dengan versi
hubungkan, jelaskan, keluar, tampilkan nilai, gunakan
keluar dari profil riwayat pilih tip shell
Perintah tidak berdokumen:
===========================================
ubah buat desc drop help load ringkasan
- Versi: kapan
Perintah ini memberi Anda versi Impala saat ini.
[quickstart.cloudera:21000] > versi;
Versi shell: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) dibuat pada Senin 9 Nov
12:18:12 PST 2015
Versi server: impalad versi 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- sejarah
Perintah ini menampilkan sepuluh perintah terakhir yang dijalankan di Impala Shell.
[quickstart.cloudera:21000] > riwayat;
[1]:versi;
[2]:bantuan;
[3]:tampilkan database;
[4]: gunakan my_db;
[5]:sejarah;
- Menghubung
Perintah ini membantu terhubung ke instance Impala yang diberikan. Jika Anda tidak menentukan instance apa pun, maka secara default, itu akan terhubung ke port default 21000.
[quickstart.cloudera:21000] > sambungkan;
Terhubung ke quickstart.cloudera:21000
Versi server: impalad versi 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- keluar/keluar
Seperti namanya, perintah exit/quit memungkinkan Anda keluar dari Impala Shell.
[quickstart.cloudera:21000] > keluar;
Selamat tinggal cloudera
Opsi Khusus Permintaan
- menjelaskan
Perintah ini mengembalikan rencana eksekusi untuk kueri tertentu.
[quickstart.cloudera:21000] > jelaskan pilih * dari sampel;
Pertanyaan: jelaskan pilih * dari sampel
+——————————————————————————————+
| Jelaskan String
|
+——————————————————————————————+
| Perkiraan Persyaratan Per-Host: Memori = 48.00MB VCores = 1
|
| PERINGATAN: Tabel berikut tidak memiliki statistik tabel dan/atau kolom yang relevan. |
| my_db.customers |
| 01:PERTUKARAN [TIDAK DIPARTISISI]
|
| 00:SCAN HDFS [my_db.customers] |
| partisi = 1/1 file = 6 ukuran = 148B |
+——————————————————————————————+
Mengambil 7 baris dalam 0,17 detik
- Profil
Perintah ini menampilkan informasi tingkat rendah tentang kueri terbaru/terbaru. Ini digunakan untuk diagnosis dan penyetelan kinerja kueri.
[ mulai cepat . cloudera : 21000 ] > profil ;
Profil Waktu Proses Kueri :
Kueri ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Ringkasan :
ID sesi : e74927207cd752b5 : 65ca61e630ad3ad
Jenis Sesi : BEESWAX
Waktu Mulai : 2016 – 04 – 17 23 : 49 : 26.08148000 Waktu Akhir : 2016 – 04 – 17 23 : 49 : 26.2404000
Jenis Kueri : JELASKAN
Status Kueri : SELESAI
Status Kueri : OK
Impala Versi : impalad versi 2.3 . 0 – cdh5 . 5.0 RELEASE ( membangun 0c891d77280e2129b )
Pengguna : cloudera
Pengguna Terhubung : cloudera
Pengguna yang Didelegasikan :
Alamat Jaringan : 10.0 . 2.15 : 43870
Db bawaan : my_db
Pernyataan Sql : jelaskan pilih * dari sampel
Koordinator : quickstart . cloudera : 22000
: 0ns
Garis Waktu Kueri : 167.304ms
– Mulai eksekusi : 41.292us ( 41.292us ) – Perencanaan selesai : 56.42ms ( 56.386ms )
– Baris yang tersedia : 58.247ms ( 1.819ms )
– Baris pertama diambil : 160.72ms ( 101.824ms )
– Batalkan pendaftaran kueri : 166.325ms ( 6.253ms )
Server Impala :
– ClientFetchWaitTimer : 107.969ms
– RowMaterialisasiTimer : 0ns
Opsi Khusus Tabel dan Basis Data
- mengubah
Perintah alter membantu mengubah struktur dan nama tabel.
- menggambarkan
Perintah deskripsikan menyediakan metadata dari sebuah tabel. Ini berisi informasi seperti kolom dan tipe datanya.
- menjatuhkan
Perintah drop membantu menghapus konstruksi, yang dapat berupa tabel, tampilan, atau fungsi database.
- memasukkan
Perintah insert membantu untuk menambahkan data (kolom) ke dalam tabel dan menimpa data dari tabel yang ada
- Pilih
Perintah pilih dapat digunakan untuk melakukan operasi tertentu pada kumpulan data tertentu. Biasanya menyebutkan kumpulan data tempat tindakan harus diselesaikan.
- menunjukkan
Perintah show menampilkan metastore dari berbagai konstruksi seperti tabel dan database.
- menggunakan
Perintah use membantu mengubah konteks database tertentu saat ini.
Impala – Komentar
Di Impala, komentarnya mirip dengan yang ada di bahasa SQL. Biasanya, ada dua jenis komentar:
Komentar satu baris
Setiap baris yang diikuti dengan “—” menjadi komentar di Impala.
— Halo, selamat datang di upGrad.
Komentar multibaris
Semua baris yang terdapat di antara /* dan */ adalah komentar multibaris di Impala.
/*
Hai ini contohnya

Dari komentar multibaris di Impala
*/
Kesimpulan
Kami berharap tutorial Impala yang mendetail ini membantu Anda memahami seluk-beluknya dan bagaimana fungsinya.
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.
Pelajari Kursus Pengembangan Perangkat Lunak online dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Lanjutan, atau Program Magister untuk mempercepat karier Anda.