Tutorial Ultimate Impala Hadoop di cui avrai mai bisogno [2022]
Pubblicato: 2020-05-14Impala è un database analitico nativo open source progettato per piattaforme in cluster come Apache Hadoop. È un motore di query interattivo simile a SQL che viene eseguito su Hadoop Distributed File System (HDFS) per facilitare l'elaborazione di enormi volumi di dati a una velocità fulminea. Inoltre, impala è uno dei migliori strumenti Hadoop per utilizzare i big data. Oggi parleremo di tutto ciò che riguarda l'Impala e, quindi, abbiamo progettato questo tutorial sull'Impala per te!
Questo tutorial Impala Hadoop è pensato appositamente per coloro che desiderano imparare l'Impala. Tuttavia, per sfruttare al massimo i vantaggi di questo tutorial di Impala, sarebbe utile avere una comprensione approfondita dei fondamenti di SQL insieme ai comandi Hadoop e HDFS.
Sommario
Cos'è l'Impala?
Impala è un motore di query SQL MPP (Massive Parallel Processing) scritto in C++ e Java. Il suo scopo principale è elaborare grandi volumi di dati archiviati nei cluster Hadoop. Impala promette prestazioni elevate e bassa latenza ed è fino ad oggi il motore SQL più performante (che offre un'esperienza simile a RDBMS) per fornire il modo più veloce per accedere ed elaborare i dati archiviati in HDFS.
Un altro aspetto vantaggioso di Impala è che si integra con il metastore Hive per consentire la condivisione delle informazioni della tabella tra entrambi i componenti. Sfrutta l'Apache Hive esistente per eseguire lavori di lunga durata orientati ai batch in formato di query SQL. L'integrazione Impala-Hive consente di utilizzare uno dei due componenti, Hive o Impala, per l'elaborazione dei dati o per creare tabelle in un unico file system condiviso (HDFS) senza alterare la definizione della tabella.
Perché Impala?
Impala combina le prestazioni multiutente di un database analitico tradizionale e il supporto SQL con la scalabilità e la flessibilità di Apache Hadoop. Lo fa utilizzando componenti Hadoop standard come HDFS, HBase, YARN, Sentry e Metastore. Poiché Impala utilizza gli stessi metadati, interfaccia utente (Hue Beeswax), sintassi SQL (Hive SQL) e driver ODBC (Open Database Connectivity) di Apache Hive, crea una piattaforma unificata e familiare per query batch-oriented e in tempo reale.
Leggi: Idee per progetti di Big Data per principianti

Impala può leggere quasi tutti i formati di file utilizzati da Hadoop, inclusi Parquet, Avro e RCFile. Inoltre, Impala non è basato su algoritmi MapReduce: implementa un'architettura distribuita basata su processi daemon che gestiscono e gestiscono tutto ciò che riguarda l'esecuzione di query in esecuzione sulla stessa macchina/e. Di conseguenza, aiuta a ridurre la latenza dell'utilizzo di MapReduce. Questo è esattamente ciò che rende Impala molto più veloce di Hive.
Impala – Caratteristiche
Le caratteristiche principali di Impala sono:
- È disponibile come motore di query SQL open source con licenza Apache.
- Ti consente di accedere ai dati utilizzando query simili a SQL.
- Supporta l'elaborazione dei dati in memoria: accede e analizza i dati archiviati sui nodi di dati Hadoop.
- Ti consente di archiviare i dati in sistemi di archiviazione come HDFS, Apache HBase e Amazon s3.
- Si integra facilmente con strumenti di BI come Tableau, Pentaho e Micro strategy.
- Supporta vari formati di file tra cui Sequence File, Avro, LZO, RCFile e Parquet.
Impala: vantaggi chiave
L'utilizzo di Impala offre alcuni vantaggi significativi agli utenti, come:
- Poiché Impala supporta l'elaborazione dei dati in memoria (l'elaborazione avviene dove risiedono i dati, sul cluster Hadoop), non è necessaria la trasformazione e lo spostamento dei dati.
- Per accedere ai dati archiviati in HDFS, HBase o Amazon s3 con Impala, non è necessaria alcuna conoscenza preliminare di Java (lavori MapReduce): puoi accedervi facilmente utilizzando query SQL di base.
- In genere, i dati devono essere sottoposti a un complicato ciclo di estrazione-trasformazione-carico (ETL) durante la scrittura di query negli strumenti aziendali. Tuttavia, con Impala, non ce n'è bisogno. Impala sostituisce le lunghe fasi di caricamento e riorganizzazione con tecniche avanzate come l'analisi esplorativa dei dati e il rilevamento dei dati, aumentando così la velocità del processo.
- Impala è un pioniere nell'utilizzo del formato di file Parquet, che è un layout di archiviazione a colonne ottimizzato per query su larga scala presenti nei data warehouse.
Impala – Svantaggi
Sebbene Impala offra numerosi vantaggi, ha anche alcune limitazioni:
- Non supporta la serializzazione e la deserializzazione.
- Non può leggere file binari personalizzati; può leggere solo file di testo.
- Ogni volta che nuovi record o file vengono aggiunti alla directory dei dati in HDFS, sarà necessario aggiornare la tabella dei dati.
Impala – Architettura
Impala è disaccoppiato dal suo motore di archiviazione (contrariamente ai sistemi di archiviazione tradizionali). Comprende tre componenti principali: Impala Daemon (Impalad) , Impala StateStore e Impala Metadata & MetaStore.
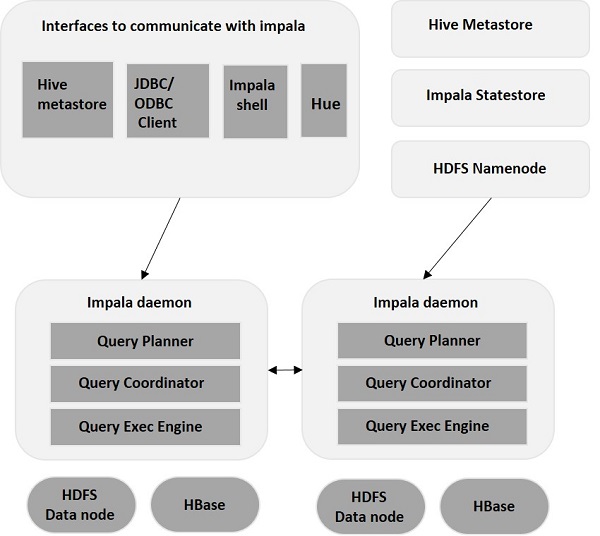
Demone Impala
Impala Daemon, alias Impalad, viene eseguito su singoli nodi in cui è installato Impala. Accetta query da più interfacce (shell Impala, browser Hue, ecc.) E le elabora. Ogni volta che una query viene inviata a un Impalad su un particolare nodo, il nodo diventa un "nodo coordinatore" per quella query. In questo modo, più query vengono servite da Impalad in esecuzione su altri nodi.
Una volta accettate le query, Impala legge e scrive file di dati e parallelizza le query distribuendo l'attività agli altri nodi Impala nel cluster. Gli utenti possono inviare query a un Impalad dedicato o in modo con bilanciamento del carico ad altri Impalad nel cluster, in base ai loro requisiti. Queste query iniziano quindi l'elaborazione sulle diverse istanze di Impalad e restituiscono il risultato al nodo di coordinamento primario.
Impala StateStore
L'Impala StateStore monitora e controlla lo stato di salute di ogni Impala e trasmette anche il rapporto sullo stato di salute di ciascun demone Impala agli altri demoni. Può essere eseguito sullo stesso nodo in cui è in esecuzione il server Impala o su un altro nodo del cluster. Nel caso in cui si verifichi un errore del nodo per qualche motivo, Impala StateStore aggiorna tutti gli altri nodi sull'errore. In tal caso, gli altri demoni Impala smettono di assegnare ulteriori query al nodo guasto.
Metadati Impala e MetaStore
In Impala, tutte le informazioni cruciali, comprese le definizioni delle tabelle, le informazioni su tabelle e colonne, ecc., sono archiviate in un database centralizzato noto come MetaStore. Quando si tratta di volumi sostanziali di dati contenenti più partizioni, diventa difficile ottenere metadati specifici della tabella. È qui che Impala viene in soccorso. Poiché i singoli nodi Impala memorizzano nella cache tutti i metadati localmente, diventa facile ottenere informazioni specifiche all'istante.
Ogni volta che aggiorni la definizione della tabella/i dati della tabella, tutti i Demoni Impala devono anche aggiornare la cache dei metadati recuperando i metadati più recenti prima di poter emettere una nuova query su una tabella particolare.
Impala – Installazione di Impala
Proprio come devi installare Hadoop e il suo ecosistema su Linux OS, puoi fare lo stesso con Impala. Poiché è stato Cloudera a spedire per primo Impala, puoi accedervi facilmente tramite la VM QuickStart di Cloudera.
Leggi: Tutorial Hadoop
Come scaricare la VM QuickStart di Cloudera
Per scaricare la VM Cloudera QuickStart, è necessario seguire i passaggi descritti di seguito.
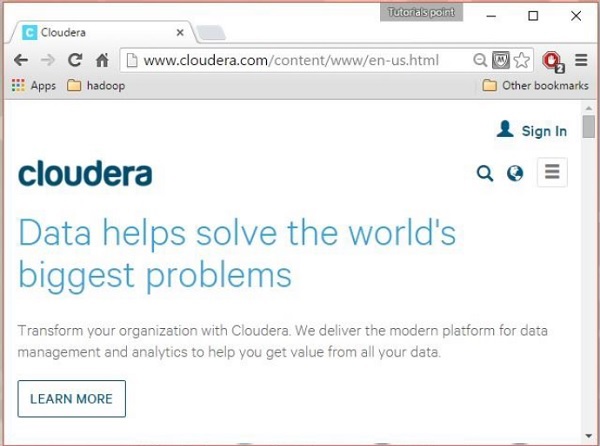
Passo 1
Apri la home page di Cloudera ( http://www.cloudera.com/ ) e troverai qualcosa del genere:
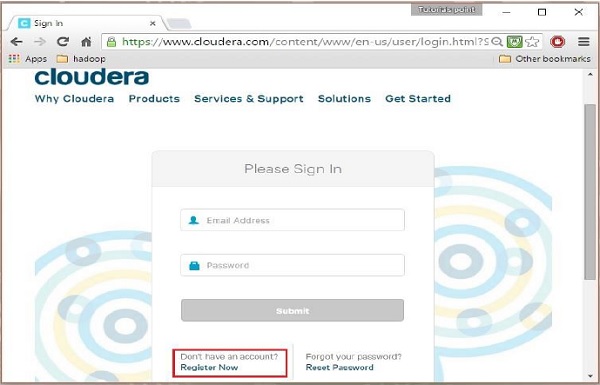
Passo 2
Per registrarti su Cloudera, devi fare clic sull'opzione "Registrati ora", che aprirà la pagina di registrazione dell'account. Se sei già registrato su Cloudera, puoi fare clic sull'opzione "Accedi" nella pagina e ti reindirizzerà ulteriormente alla pagina di accesso in questo modo:
Passaggio 3
Una volta effettuato l'accesso, apri la pagina di download del sito Web facendo clic sull'opzione "Download" nell'angolo in alto a sinistra della pagina, come mostrato di seguito:
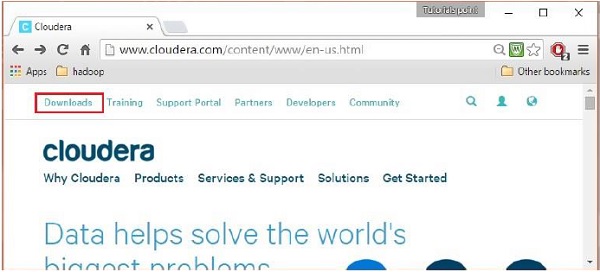
Passaggio 4
In questo passaggio, devi scaricare Cloudera QuickStartVM facendo clic sull'opzione "Scarica ora" in questo modo:
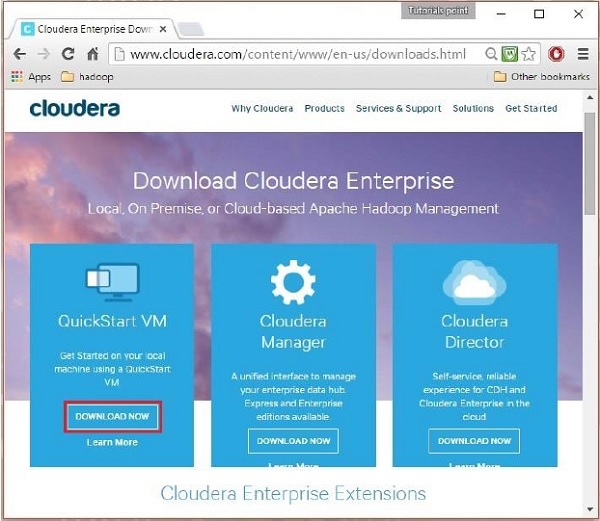
Facendo clic sull'opzione Scarica ora verrai reindirizzato alla pagina di download di QuickStart VM:
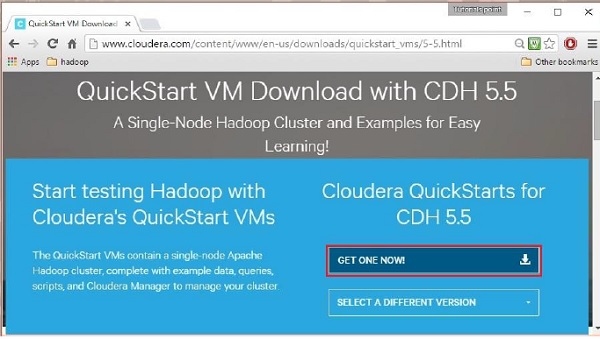
Quindi devi selezionare l'opzione OTTIENI UNO ORA, accettare il contratto di licenza e inviarlo come mostrato di seguito:
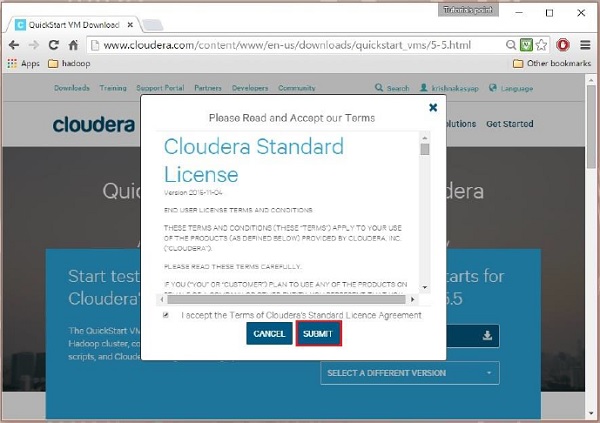
Al termine del download, troverai tre diverse opzioni compatibili con Cloudera VM: VMware, KVM e VIRTUALBOX. Puoi scegliere la tua opzione preferita.

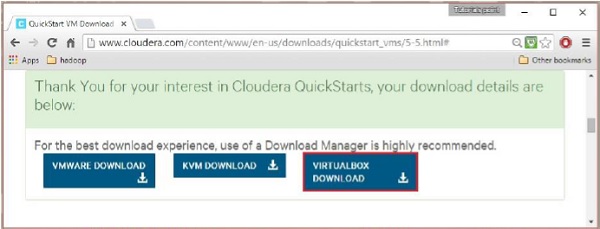
Fonte
Impala – Interfacce di elaborazione delle query
Impala offre tre interfacce per l'elaborazione delle query:
Impala-shell – Dopo aver installato e configurato Impala utilizzando la Cloudera VM, puoi attivare Impala-shell digitando il comando “impala-shell” nell'editor.
Leggi: Differenza tra Big Data e Hadoop
Interfaccia Hue: il browser Hue consente di elaborare le query Impala. Ha un editor di query Impala in cui puoi digitare ed eseguire diverse query Impala. Tuttavia, per utilizzare l'editor, devi prima accedere al browser Hue.
Driver ODBC/JDBC – Come per ogni database, Impala offre anche driver ODBC/JDBC. Questi driver consentono di connettersi a Impala tramite linguaggi di programmazione che li supportano (driver ODBC/JDBC) e creare applicazioni che elaborano query in Impala utilizzando gli stessi linguaggi di programmazione.
Procedura di esecuzione della query
Ogni volta che passi una query utilizzando qualsiasi interfaccia Impala, un Impala nel cluster di solito accetta la tua query. Questo Impalad diventa quindi il nodo coordinatore per quella particolare query. Dopo aver ricevuto la query, il coordinatore verifica se la query è appropriata o meno utilizzando lo schema della tabella da Hive Metastore.
Successivamente, raccoglie informazioni sulla posizione dei dati necessari per l'esecuzione della query dal nodo del nome HDFS e inoltra queste informazioni ad altri Impalad nella gerarchia per facilitare l'esecuzione della query. Una volta che gli Impalad hanno letto il blocco di dati specificato, elaborano la query. Quando tutti gli Impalad nel cluster hanno elaborato la query, il nodo coordinatore raccoglie il risultato e te lo consegna.
Comandi della shell Impala
Se hai familiarità con Hive Shell, puoi facilmente capire Impala Shell poiché entrambi condividono una struttura abbastanza simile: consentono di creare database e tabelle, inserire dati ed emettere query. I comandi di Impala Shell rientrano in tre grandi categorie: comandi generali, opzioni specifiche per query e opzioni specifiche per tabelle e database.
Comandi generali
- aiuto
Il comando help offre un elenco di comandi utili disponibili in Impala.
[quickstart.cloudera:21000] > aiuto;
Comandi documentati (digitare help <argomento>):
====================================================================================================================================== ======
calcola descrivi inserisci set disinserito con versione
connetti spiega esci mostra valori usa
esci dal profilo della cronologia seleziona il suggerimento della shell
Comandi non documentati:
=============================================================
alter create desc drop aiuto caricamento riepilogo
- Versione
Questo comando fornisce la versione corrente di Impala.
[quickstart.cloudera:21000] > versione;
Versione Shell: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) costruita il lunedì 9 novembre
12:18:12 PST 2015
Versione server: impalad versione 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- storia
Questo comando mostra gli ultimi dieci comandi eseguiti in Impala Shell.
[quickstart.cloudera:21000] > cronologia;
[1]:versione;
[2]: aiuto;
[3]: mostra i database;
[4]:usa mio_db;
[5]:storia;
- Collegare
Questo comando aiuta a connettersi a una determinata istanza di Impala. Se non specifichi alcuna istanza, per impostazione predefinita, si connetterà alla porta predefinita 21000.
[quickstart.cloudera:21000] > connetti;
Connesso a quickstart.cloudera:21000
Versione server: impalad versione 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- uscire/uscire
Come suggerisce il nome, il comando exit/quit ti consente di uscire da Impala Shell.
[quickstart.cloudera:21000] > esci;
Addio cloudera
Opzioni specifiche per query
- spiegare
Questo comando restituisce il piano di esecuzione per una particolare query.
[quickstart.cloudera:21000] > spiega seleziona * dal campione;
Query: spiegare selezionare * dal campione
+—————————————————————————————+
| Spiega la stringa
|
+—————————————————————————————+
| Requisiti stimati per host: memoria = 48,00 MB VCore = 1
|
| ATTENZIONE: nelle tabelle seguenti mancano statistiche relative a tabelle e/o colonne. |
| mio_db.clienti |
| 01:CAMBIO [NON PARTIZIONATO]
|
| 00:SCAN HDFS [my_db.clienti] |
| partizioni = 1/1 file = 6 dimensioni = 148B |
+—————————————————————————————+
Recuperato 7 righe in 0,17 secondi
- profilo
Questo comando visualizza le informazioni di basso livello sulla query recente/ultima. Viene utilizzato per la diagnosi e l'ottimizzazione delle prestazioni di una query.
[ avvio rapido . cloudera : 21000 ] > profilo ;
Profilo di runtime della query :
Query ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Riepilogo :
ID sessione : e74927207cd752b5 : 65ca61e630ad3ad
Tipo di sessione : CERA D'API
Ora di inizio : 2016 – 04 – 17 23 : 49 : 26.08148000 Ora di fine : 2016 – 04 – 17 23 : 49 : 26.2404000
Tipo di richiesta : SPIEGAZIONE
Stato della query : FINITO
Stato della richiesta : OK
Versione Impala : versione Impala 2.3 . 0 – cdh5 . VERSIONE 5.0 ( build 0c891d77280e2129b )
Utente : cloudera
Utente connesso : cloudera
Utente delegato :
Indirizzo di rete : 10.0 . 2.15 : 43870
Db predefinito : my_db
Sql Statement : spiega seleziona * dal campione
Coordinatore : avvio rapido . cloudera : 22000
: 0ns
Sequenza temporale della query : 167.304 ms
– Inizio esecuzione : 41.292us ( 41.292us ) – Pianificazione terminata : 56.42ms ( 56.386ms )
– Righe disponibili : 58.247 ms ( 1.819 ms )
– Prima riga recuperata : 160,72 ms ( 101,824 ms )
– Annulla registrazione query : 166,325 ms ( 6,253 ms )
Impala Server :
– ClientFetchWaitTimer : 107.969 ms
– RowMaterializationTimer : 0ns
Opzioni specifiche per tabelle e database
- alterare
Il comando alter aiuta a modificare la struttura e il nome di una tabella.
- descrivere
Il comando describe fornisce i metadati di una tabella. Contiene informazioni come colonne e relativi tipi di dati.
- far cadere
Il comando drop aiuta a rimuovere un costrutto, che può essere una tabella, una vista o una funzione di database.
- inserire
Il comando di inserimento aiuta ad aggiungere dati (colonne) in una tabella e sovrascrivere i dati di una tabella esistente
- Selezionare
Il comando select può essere utilizzato per eseguire un'operazione specifica su un determinato set di dati. Di solito menziona il set di dati su cui deve essere completata l'azione.
- mostrare
Il comando show mostra il metastore di vari costrutti come tabelle e database.
- utilizzo
Il comando use aiuta a cambiare il contesto corrente di un particolare database.
Impala – Commenti
In Impala, i commenti sono simili a quelli del linguaggio SQL. In genere, ci sono due tipi di commenti:
Commenti a riga singola
Ogni riga seguita da "—" diventa un commento in Impala.
— Ciao, benvenuto in upGrad.
Commenti su più righe
Tutte le righe contenute tra /* e */ sono commenti su più righe in Impala.
/*
Ciao questo è un esempio

Di commenti su più righe in Impala
*/
Conclusione
Ci auguriamo che questo tutorial dettagliato di Impala ti abbia aiutato a capire le sue complessità e come funziona.
Se sei interessato a saperne di più sui Big Data, dai un'occhiata al nostro PG Diploma in Software Development Specialization nel programma Big Data, progettato per professionisti che lavorano e fornisce oltre 7 casi di studio e progetti, copre 14 linguaggi e strumenti di programmazione, pratiche pratiche workshop, oltre 400 ore di apprendimento rigoroso e assistenza all'inserimento lavorativo con le migliori aziende.
Impara i corsi di sviluppo software online dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.