Tutorial final do Impala Hadoop que você precisará [2022]
Publicados: 2020-05-14Impala é um banco de dados analítico nativo de código aberto projetado para plataformas em cluster como o Apache Hadoop. É um mecanismo de consulta interativo semelhante ao SQL que é executado no Hadoop Distributed File System (HDFS) para facilitar o processamento de grandes volumes de dados em uma velocidade extremamente rápida. Além disso, o impala é uma das principais ferramentas do Hadoop para usar big data. Hoje, vamos falar sobre todas as coisas do Impala e, portanto, criamos este tutorial do Impala para você!
Este tutorial Impala Hadoop é especialmente destinado para aqueles que desejam aprender Impala. No entanto, para obter o máximo de benefícios deste tutorial do Impala, seria útil se você tivesse uma compreensão profunda dos fundamentos do SQL junto com os comandos Hadoop e HDFS.
Índice
O que é Impala?
Impala é um mecanismo de consulta SQL MPP (Massive Parallel Processing) escrito em C++ e Java. Seu objetivo principal é processar grandes volumes de dados armazenados em clusters Hadoop. O Impala promete alto desempenho e baixa latência, e até hoje é o mecanismo SQL de melhor desempenho (que oferece uma experiência semelhante a RDBMS) para fornecer a maneira mais rápida de acessar e processar dados armazenados em HDFS.
Outro aspecto benéfico do Impala é que ele se integra ao metastore do Hive para permitir o compartilhamento das informações da tabela entre os dois componentes. Ele aproveita o Apache Hive existente para executar tarefas de longa duração orientadas a lotes no formato de consulta SQL. A integração Impala-Hive permite que você use um dos dois componentes – Hive ou Impala para processamento de dados ou para criar tabelas em um único sistema de arquivos compartilhado (HDFS) sem alterar a definição da tabela.
Por que Impala?
O Impala combina o desempenho multiusuário de um banco de dados analítico tradicional e suporte SQL com a escalabilidade e flexibilidade do Apache Hadoop. Ele faz isso usando componentes padrão do Hadoop, como HDFS, HBase, YARN, Sentry e Metastore. Como o Impala usa os mesmos metadados, interface de usuário (Hue Beeswax), sintaxe SQL (Hive SQL) e driver ODBC (Open Database Connectivity) do Apache Hive, ele cria uma plataforma unificada e familiar para consultas orientadas a lotes e em tempo real.
Leia: Ideias de projetos de big data para iniciantes

O Impala pode ler quase todos os formatos de arquivo usados pelo Hadoop, incluindo Parquet, Avro e RCFile. Além disso, o Impala não é construído em algoritmos MapReduce – ele implementa uma arquitetura distribuída baseada em processos daemon que tratam e gerenciam tudo relacionado à execução de consultas em execução na(s) mesma(s) máquina(s). Como resultado, ajuda a reduzir a latência de utilização do MapReduce. Isso é precisamente o que torna o Impala muito mais rápido que o Hive.
Impala – Características
As principais características do Impala são:
- Ele está disponível como um mecanismo de consulta SQL de código aberto sob a licença Apache.
- Ele permite que você acesse dados usando consultas do tipo SQL.
- Ele suporta o processamento de dados na memória – ele acessa e analisa os dados armazenados nos nós de dados do Hadoop.
- Ele permite que você armazene dados em sistemas de armazenamento como HDFS, Apache HBase e Amazon s3.
- Ele se integra facilmente a ferramentas de BI como Tableau, Pentaho e Micro strategy.
- Ele suporta vários formatos de arquivo, incluindo Sequence File, Avro, LZO, RCFile e Parquet.
Impala – Principais vantagens
O uso do Impala oferece algumas vantagens significativas para os usuários, como:
- Como o Impala oferece suporte ao processamento de dados na memória (o processamento ocorre onde os dados residem – no cluster Hadoop), não há necessidade de transformação e movimentação de dados.
- Para acessar dados armazenados em HDFS, HBase ou Amazon s3 com Impala, você não precisa de nenhum conhecimento prévio de Java (trabalhos MapReduce) – você pode acessá-los facilmente usando consultas SQL básicas.
- Geralmente, os dados precisam passar por um ciclo complicado de extração-transformação-carga (ETL) ao escrever consultas em ferramentas de negócios. No entanto, com Impala, não há necessidade disso. O Impala substitui os estágios demorados de carregamento e reorganização por técnicas avançadas, como análise exploratória de dados e descoberta de dados, aumentando assim a velocidade do processo.
- A Impala é pioneira no uso do formato de arquivo Parquet, que é um layout de armazenamento colunar otimizado para consultas em grande escala encontradas em data warehouses.
Impala – Desvantagens
Embora o Impala ofereça vários benefícios, ele também possui algumas limitações:
- Não tem suporte para serialização e desserialização.
- Ele não pode ler arquivos binários personalizados; ele só pode ler arquivos de texto.
- Sempre que novos registros ou arquivos são adicionados ao diretório de dados no HDFS, você precisará atualizar a tabela de dados.
Impala – Arquitetura
Impala é desacoplado de seu mecanismo de armazenamento (ao contrário dos sistemas de armazenamento tradicionais). Inclui três componentes principais – Impala Daemon (Impalad) , Impala StateStore e Impala Metadata & MetaStore.
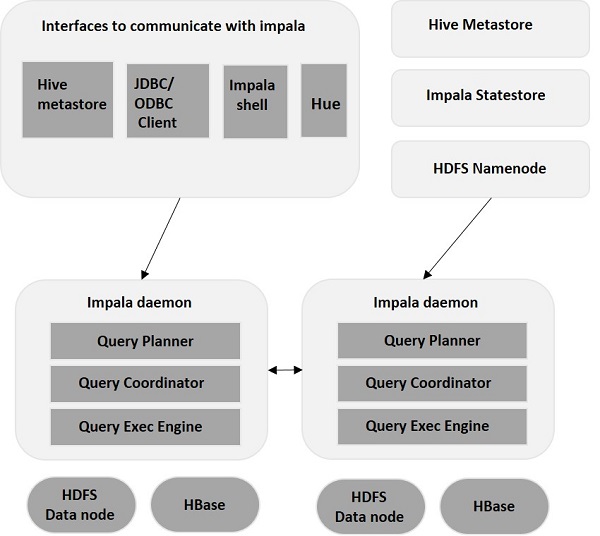
Impala Daemon
O Impala Daemon, também conhecido como Impalad, é executado em nós individuais onde o Impala está instalado. Ele aceita consultas de várias interfaces (shell Impala, navegador Hue, etc.) e as processa. Cada vez que uma consulta é submetida a um Impalad em um nó específico, o nó se torna um “nó coordenador” para aquela consulta. Dessa forma, várias consultas são atendidas pelo Impalad em execução em outros nós.
Depois que as consultas são aceitas, o Impalad lê e grava arquivos de dados e paraleliza as consultas distribuindo a tarefa para os outros nós do Impala no cluster. Os usuários podem enviar consultas para um Impalad dedicado ou com balanceamento de carga para outro Impalad no cluster, com base em seus requisitos. Essas consultas iniciam o processamento nas diferentes instâncias do Impalad e retornam o resultado para o nó de coordenação primário.
Impala StateStore
O Impala StateStore monitora e verifica a integridade de cada Impalad e também transmite o relatório de integridade de cada Impala Daemon para os outros daemons. Ele pode ser executado no mesmo nó em que o servidor Impala está sendo executado ou em outro nó do cluster. Caso haja uma falha de nó por algum motivo, o Impala StateStore atualiza todos os outros nós sobre a falha. Nesse caso, os outros daemons do Impala param de atribuir outras consultas ao nó com falha.
Metadados e MetaStore Impala
No Impala, todas as informações cruciais, incluindo definições de tabelas, informações de tabelas e colunas, etc., são armazenadas em um banco de dados centralizado conhecido como MetaStore. Ao lidar com volumes substanciais de dados contendo várias partições, torna-se um desafio obter metadados específicos da tabela. É aqui que Impala vem em socorro. Como os nós individuais do Impala armazenam em cache todos os metadados localmente, fica fácil obter informações específicas instantaneamente.
Cada vez que você atualiza a definição da tabela/dados da tabela, todos os Impala Daemons também devem atualizar seu cache de metadados recuperando os metadados mais recentes antes que possam emitir uma nova consulta em uma tabela específica.
Impala – Instalando o Impala
Assim como você precisa instalar o Hadoop e seu ecossistema no sistema operacional Linux, você pode fazer o mesmo com o Impala. Como foi o Cloudera que lançou o Impala pela primeira vez, você pode acessá-lo facilmente por meio da VM Cloudera QuickStart.
Leia: Tutorial Hadoop
Como baixar a VM Cloudera QuickStart
Para baixar a VM Cloudera QuickStart, você deve seguir as etapas descritas abaixo.
Passo 1
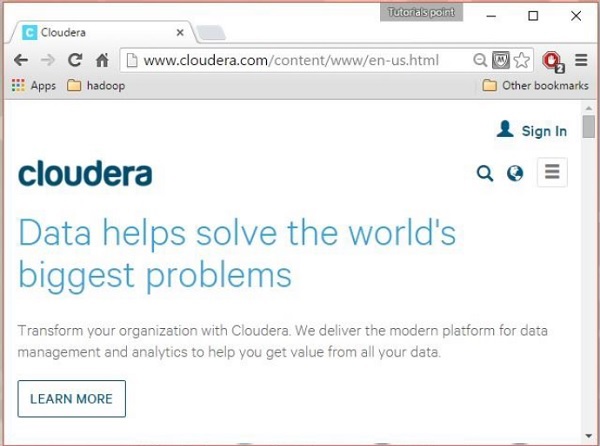
Abra a página inicial do Cloudera ( http://www.cloudera.com/ ) e você encontrará algo assim:
Passo 2
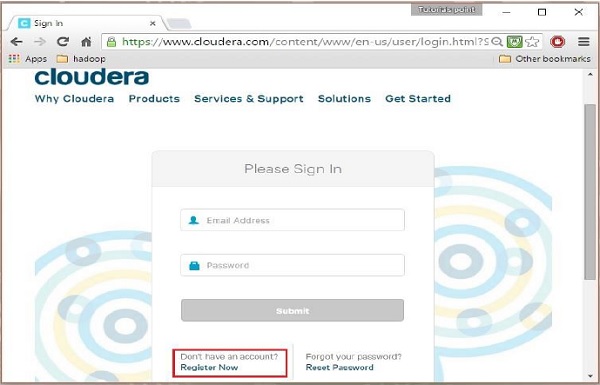
Para se registrar no Cloudera, você deve clicar na opção “Cadastre-se agora”, que abrirá a página de Cadastro de Conta. Se você já está registrado no Cloudera, você pode clicar na opção “Sign In” na página, e ele irá redirecioná-lo para a página de login da seguinte forma:
etapa 3
Após fazer login, abra a página de download do site clicando na opção “Downloads” no canto superior esquerdo da página, conforme mostrado abaixo:
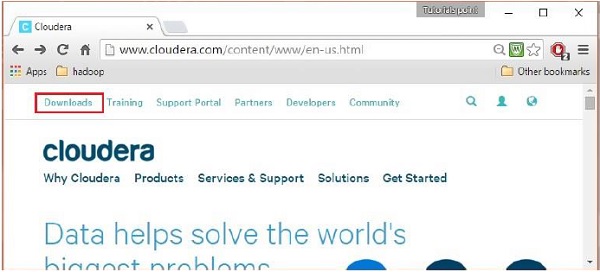
Passo 4
Nesta etapa, você precisa baixar o Cloudera QuickStartVM clicando na opção “Baixar agora” da seguinte forma:
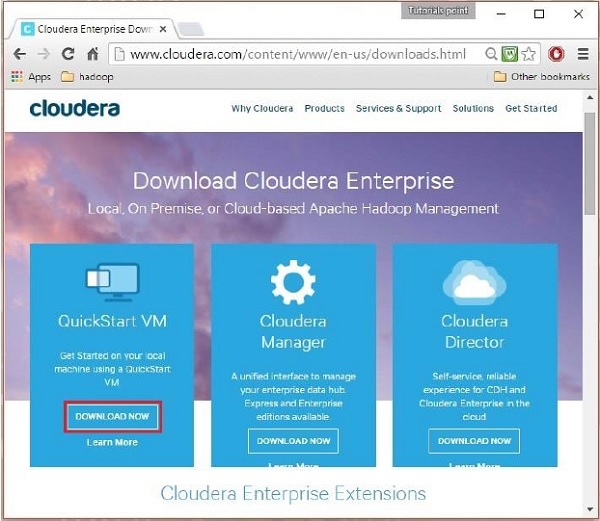
Clicar na opção Download Now irá redirecioná-lo para a página de download do QuickStart VM:
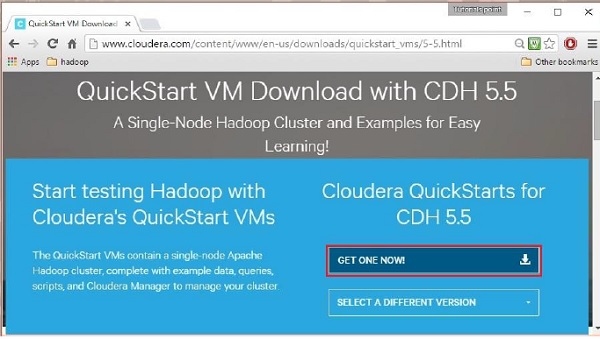
Em seguida, você deve selecionar a opção GET ONE NOW, aceitar o contrato de licença e enviá-lo conforme mostrado abaixo:
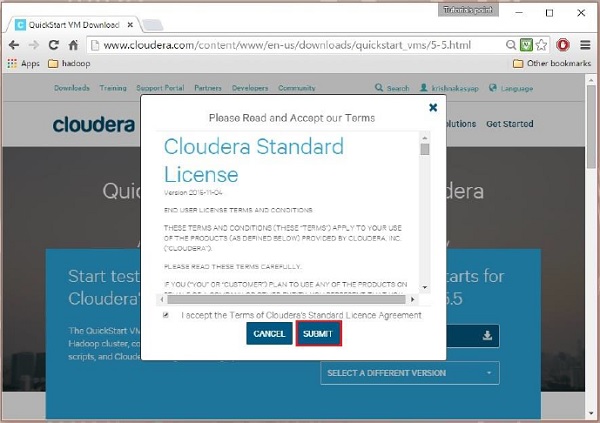
Após a conclusão do download, você encontrará três opções diferentes compatíveis com Cloudera VM – VMware, KVM e VIRTUALBOX. Você pode escolher sua opção preferida.

Fonte
Impala – Interfaces de Processamento de Consultas
O Impala oferece três interfaces para processamento de consultas:
Impala-shell – Depois de instalar e configurar o Impala usando a Cloudera VM, você pode ativar o Impala-shell digitando o comando “impala-shell” no editor.
Leia: Diferença entre Big Data e Hadoop
Interface Hue – O navegador Hue permite processar consultas Impala. Possui um editor de consultas Impala onde você pode digitar e executar diferentes consultas Impala. No entanto, para usar o editor, primeiro você precisará fazer login no navegador Hue.
Drivers ODBC/JDBC – Como acontece com todos os bancos de dados, o Impala também oferece drivers ODBC/JDBC. Esses drivers permitem que você se conecte ao Impala por meio de linguagens de programação que os suportem (drivers ODBC/JDBC) e crie aplicativos que processam consultas no Impala usando as mesmas linguagens de programação.
Procedimento de execução da consulta
Sempre que você passa uma consulta usando qualquer interface do Impala, um Impalad no cluster geralmente aceita sua consulta. Este Impalad torna-se então o nó coordenador para essa consulta específica. Após receber a consulta, o coordenador verifica se a consulta é apropriada ou não usando o Esquema de Tabela do Hive Metastore.
Depois disso, ele reúne informações sobre a localização dos dados necessários para a execução da consulta do nó de nome do HDFS e encaminha essas informações para outros Impalads na hierarquia para facilitar a execução da consulta. Uma vez que os Impalads leem o bloco de dados especificado, eles processam a consulta. Quando todos os Impalads no cluster tiverem processado a consulta, o nó coordenador coletará o resultado e o entregará a você.
Comandos de shell Impala
Se você estiver familiarizado com o Hive Shell, poderá descobrir facilmente o Impala Shell, pois ambos compartilham uma estrutura bastante semelhante – eles permitem criar bancos de dados e tabelas, inserir dados e emitir consultas. Os comandos do Impala Shell se enquadram em três categorias amplas: comandos gerais, opções específicas de consulta e opções específicas de tabela e banco de dados.
Comandos Gerais
- ajuda
O comando help oferece uma lista de comandos úteis disponíveis no Impala.
[início rápido.cloudera:21000] > ajuda;
Comandos documentados (digite help <topic>):
================================================== ======
computar descrever inserir o conjunto não definido com a versão
conectar explicar sair mostrar valores usar
sair do perfil do histórico selecionar a dica do shell
Comandos não documentados:
=========================================
alter create desc drop help load resumo
- Versão
Este comando fornece a versão atual do Impala.
[início rápido.cloudera:21000] > versão;
Versão do Shell: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) construído em segunda-feira, 9 de novembro
12:18:12 PST 2015
Versão do servidor: versão impalad 2.3.0-cdh5.5.0 RELEASE (compilação
0c891d79aa38f297d244855a32f1e17280e2129b)
- história
Este comando exibe os últimos dez comandos executados no Impala Shell.
[início rápido.cloudera:21000] > histórico;
[1]:versão;
[2]:ajuda;
[3]:mostrar bancos de dados;
[4]:use meu_db;
[5]:história;
- conectar
Este comando ajuda a conectar a uma determinada instância do Impala. Se você não especificar nenhuma instância, por padrão, ela se conectará à porta padrão 21000.
[início rápido.cloudera:21000] > conectar;
Conectado ao quickstart.cloudera:21000
Versão do servidor: versão impalad 2.3.0-cdh5.5.0 RELEASE (compilação
0c891d79aa38f297d244855a32f1e17280e2129b)
- sair/sair
Como o nome sugere, o comando exit/quit permite sair do Impala Shell.
[início rápido.cloudera:21000] > sair;
Adeus cloudera
Opções específicas de consulta
- explique
Este comando retorna o plano de execução para uma consulta específica.
[quickstart.cloudera:21000] > explique selecione * da amostra;
Consulta: explique selecionar * da amostra
+————————————————————————————+
| Explicar String
|
+————————————————————————————+
| Requisitos estimados por host: memória = 48,00 MB VCores = 1
|
| AVISO: As tabelas a seguir não possuem estatísticas relevantes de tabela e/ou coluna. |
| meu_db.clientes |
| 01:CÂMBIO [NÃO PARTICIONADO]
|
| 00:SCAN HDFS [meu_db.clientes] |
| partições = 1/1 arquivos = 6 tamanho = 148B |
+————————————————————————————+
Obteve 7 linha(s) em 0,17s
- perfil
Este comando exibe as informações de baixo nível sobre a consulta recente/mais recente. Ele é usado para diagnóstico e ajuste de desempenho de uma consulta.
[ início rápido . cloudera : 21000 ] > perfil ;
Perfil de tempo de execução da consulta :
Consulta ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Resumo :
ID da sessão : e74927207cd752b5 : 65ca61e630ad3ad
Tipo de sessão : BEESWAX
Hora de início : 2016 – 04 – 17 23 : 49 : 26.08148000 Hora de término : 2016 – 04 – 17 23 : 49 : 26.2404000
Tipo de consulta : EXPLAIN
Estado da consulta : CONCLUÍDO
Status da consulta : OK
Versão Impala : versão impala 2.3 . 0 – cdh5 . 5.0 RELEASE ( compilação 0c891d77280e2129b )
Usuário : cloudera
Usuário conectado : cloudera
Usuário Delegado :
Endereço de rede : 10.0 . 2.15 : 43870
Db padrão : my_db
Instrução SQL : explique selecionar * da amostra
Coordenador : início rápido . cloudera : 22000
: 0ns
Linha do tempo da consulta : 167,304 ms
– Início da execução : 41.292us ( 41.292us ) – Planejamento finalizado : 56,42ms ( 56.386ms )
– Linhas disponíveis : 58,247ms ( 1,819ms )
– Primeira linha buscada : 160,72ms ( 101,824ms )
– Consulta de cancelamento de registro : 166,325ms ( 6,253ms )
ImpalaServer :
– ClientFetchWaitTimer : 107.969ms
– RowMaterializationTimer : 0ns
Opções específicas de tabela e banco de dados
- alterar
O comando alter ajuda a alterar a estrutura e o nome de uma tabela.
- descrever
O comando describe fornece os metadados de uma tabela. Ele contém informações como colunas e seus tipos de dados.
- derrubar
O comando drop ajuda a remover uma construção, que pode ser uma tabela, uma visão ou uma função de banco de dados.
- inserir
O comando insert ajuda a anexar dados (colunas) em uma tabela e substituir os dados de uma tabela existente
- selecionar
O comando select pode ser usado para realizar uma operação específica em um determinado conjunto de dados. Geralmente menciona o conjunto de dados no qual a ação deve ser concluída.
- exposição
O comando show exibe o metastore de várias construções como tabelas e bancos de dados.
- usar
O comando use ajuda a alterar o contexto atual de um determinado banco de dados.
Impala – Comentários
No Impala, os comentários são semelhantes aos da linguagem SQL. Normalmente, existem dois tipos de comentários:
Comentários de linha única
Cada linha seguida por “—” torna-se um comentário no Impala.
— Olá, bem-vindo ao upGrad.
Comentários de várias linhas
Todas as linhas contidas entre /* e */ são comentários de várias linhas no Impala.
/*
Olá, este é um exemplo

De comentários de várias linhas no Impala
*/
Conclusão
Esperamos que este tutorial detalhado do Impala tenha ajudado você a entender seus meandros e como ele funciona.
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.
Aprenda cursos de desenvolvimento de software online das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.