Ultimate Impala Hadoop Tutorial, который вам когда-либо понадобится [2022]
Опубликовано: 2020-05-14Impala — это собственная аналитическая база данных с открытым исходным кодом, разработанная для кластерных платформ, таких как Apache Hadoop. Это интерактивный SQL-подобный механизм запросов, который работает поверх распределенной файловой системы Hadoop (HDFS) для облегчения обработки огромных объемов данных с молниеносной скоростью. Кроме того, impala — один из лучших инструментов Hadoop для работы с большими данными. Сегодня мы поговорим обо всем, что связано с Impala, и поэтому мы разработали этот учебник по Impala для вас!
Это руководство по Impala Hadoop специально предназначено для тех, кто хочет изучить Impala. Однако, чтобы воспользоваться максимальными преимуществами этого руководства по Impala, было бы полезно, если бы у вас было глубокое понимание основ SQL, а также команд Hadoop и HDFS.
Оглавление
Что такое Импала?
Impala — это механизм запросов SQL MPP (Massive Parallel Processing), написанный на C++ и Java. Его основная цель — обрабатывать огромные объемы данных, хранящихся в кластерах Hadoop. Impala обещает высокую производительность и низкую задержку, и на сегодняшний день это самый производительный механизм SQL (который предлагает возможности, подобные СУБД), обеспечивающий самый быстрый способ доступа и обработки данных, хранящихся в HDFS.
Еще один полезный аспект Impala заключается в том, что он интегрируется с хранилищем метаданных Hive, что позволяет обмениваться информацией о таблицах между обоими компонентами. Он использует существующий Apache Hive для выполнения пакетных, длительных заданий в формате SQL-запросов. Интеграция Impala-Hive позволяет использовать любой из двух компонентов — Hive или Impala для обработки данных или для создания таблиц в единой общей файловой системе (HDFS) без изменения определения таблицы.
Почему Импала?
Impala сочетает в себе многопользовательскую производительность традиционной аналитической базы данных и поддержку SQL с масштабируемостью и гибкостью Apache Hadoop. Для этого используются стандартные компоненты Hadoop, такие как HDFS, HBase, YARN, Sentry и Metastore. Поскольку Impala использует те же метаданные, пользовательский интерфейс (Hue Beeswax), синтаксис SQL (Hive SQL) и драйвер ODBC (Open Database Connectivity), что и Apache Hive, она создает унифицированную и знакомую платформу для пакетных запросов и запросов в реальном времени.
Читайте: Идеи проекта больших данных для начинающих

Impala может читать практически все форматы файлов, используемые Hadoop, включая Parquet, Avro и RCFile. Кроме того, Impala не построена на алгоритмах MapReduce — она реализует распределенную архитектуру, основанную на процессах-демонах, которые обрабатывают и управляют всем, что связано с выполнением запросов, выполняемых на одной и той же машине/машинах. В результате это помогает уменьшить задержку использования MapReduce. Именно это делает Impala намного быстрее, чем Hive.
Импала – Особенности
Основные особенности Импалы:
- Он доступен как механизм запросов SQL с открытым исходным кодом по лицензии Apache.
- Он позволяет вам получать доступ к данным с помощью SQL-подобных запросов.
- Он поддерживает обработку данных в памяти — он получает доступ и анализирует данные, хранящиеся на узлах данных Hadoop.
- Он позволяет хранить данные в таких системах хранения, как HDFS, Apache HBase и Amazon s3.
- Он легко интегрируется с инструментами BI, такими как Tableau, Pentaho и Micro Strategy.
- Он поддерживает различные форматы файлов, включая Sequence File, Avro, LZO, RCFile и Parquet.
Импала – ключевые преимущества
Использование Impala предлагает пользователям ряд существенных преимуществ, таких как:
- Поскольку Impala поддерживает обработку данных в памяти (обработка происходит там, где данные находятся — в кластере Hadoop), нет необходимости в преобразовании и перемещении данных.
- Для доступа к данным, хранящимся в HDFS, HBase или Amazon s3 с помощью Impala, вам не нужны какие-либо предварительные знания Java (задания MapReduce) — вы можете легко получить к ним доступ, используя простые SQL-запросы.
- Как правило, данные должны пройти сложный цикл извлечения-преобразования-загрузки (ETL) при написании запросов в бизнес-инструментах. Однако с Impala в этом нет необходимости. Impala заменяет трудоемкие этапы загрузки и реорганизации передовыми методами, такими как исследовательский анализ данных и обнаружение данных, тем самым повышая скорость процесса.
- Impala является пионером в использовании формата файлов Parquet, представляющего собой столбчатую схему хранения, оптимизированную для крупномасштабных запросов, встречающихся в хранилищах данных.
Импала – недостатки
Хотя Impala предлагает множество преимуществ, она также имеет определенные ограничения:
- Он не поддерживает сериализацию и десериализацию.
- Он не может читать пользовательские двоичные файлы; он может только читать текстовые файлы.
- Каждый раз, когда новые записи или файлы добавляются в каталог данных в HDFS, вам нужно будет обновлять таблицу данных.
Импала – Архитектура
Impala отделена от своего механизма хранения (в отличие от традиционных систем хранения). Он включает в себя три основных компонента: Impala Daemon (Impalad) , Impala StateStore и Impala Metadata & MetaStore.
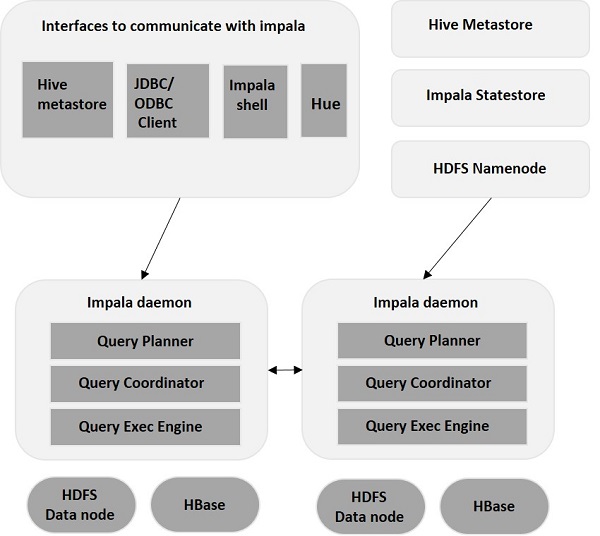
Импала Демон
Демон Impala, также известный как Impalad, работает на отдельных узлах, где установлена Impala. Он принимает запросы от нескольких интерфейсов (оболочка Impala, браузер Hue и т. д.) и обрабатывает их. Каждый раз, когда запрос отправляется в Impalad на определенном узле, этот узел становится «узлом-координатором» для этого запроса. Таким образом, Impalad обслуживает несколько запросов, работающих на других узлах.
Как только запросы приняты, Impalad считывает и записывает файлы данных и распараллеливает запросы, распределяя задачу на другие узлы Impala в кластере. Пользователи могут либо отправлять запросы на выделенный Impalad, либо с балансировкой нагрузки на другой Impalad в кластере в зависимости от своих требований. Затем эти запросы начинают обрабатываться на разных экземплярах Impalad и возвращают результат основному координирующему узлу.
Государственный магазин Импала
Impala StateStore отслеживает и проверяет работоспособность каждого Impalad, а также передает отчет о работоспособности каждого демона Impala другим демонам. Он может работать на том же узле, где работает сервер Impala, или на другом узле кластера. В случае сбоя узла по какой-либо причине Impala StateStore обновляет все остальные узлы о сбое. В таком случае другие демоны Impala перестают назначать любые дальнейшие запросы отказавшему узлу.
Импала Метаданные и MetaStore
В Impala вся важная информация, включая определения таблиц, информацию о таблицах и столбцах и т. д., хранится в централизованной базе данных, известной как MetaStore. При работе со значительными объемами данных, содержащих несколько разделов, становится сложно получить метаданные для конкретных таблиц. Тут на помощь приходит Импала. Поскольку отдельные узлы Impala кэшируют все метаданные локально, становится легко мгновенно получать конкретную информацию.
Каждый раз, когда вы обновляете определение таблицы/данные таблицы, все демоны Impala также должны обновлять свой кэш метаданных, извлекая последние метаданные, прежде чем они смогут выполнить новый запрос к конкретной таблице.
Импала – Установка Импалы
Точно так же, как вам нужно установить Hadoop и его экосистему на ОС Linux, вы можете сделать то же самое с Impala. Поскольку именно Cloudera первой поставила Impala, вы можете легко получить к ней доступ через виртуальную машину Cloudera QuickStart.
Читать: Учебник по Hadoop
Как загрузить Cloudera QuickStart VM
Чтобы загрузить виртуальную машину Cloudera QuickStart, необходимо выполнить шаги, описанные ниже.
Шаг 1
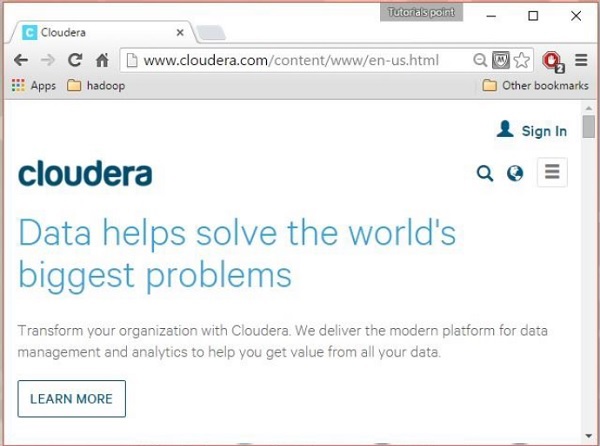
Откройте домашнюю страницу Cloudera ( http://www.cloudera.com/ ), и вы найдете что-то вроде этого:
Шаг 2
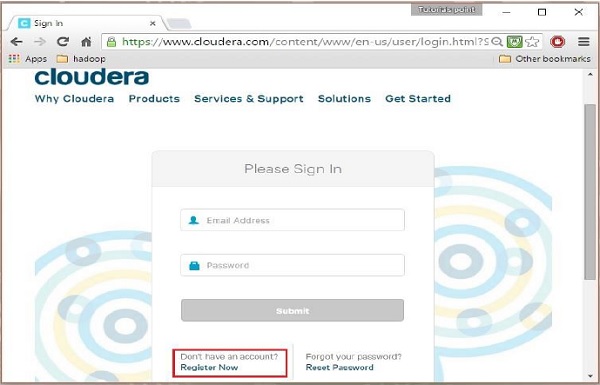
Чтобы зарегистрироваться в Cloudera, вы должны нажать «Зарегистрироваться сейчас», после чего откроется страница регистрации учетной записи. Если вы уже зарегистрированы в Cloudera, вы можете нажать на кнопку «Войти» на странице, и она перенаправит вас на страницу входа следующим образом:
Шаг 3
После входа в систему откройте страницу загрузки веб-сайта, щелкнув параметр «Загрузки» в верхнем левом углу страницы, как показано ниже:
Шаг 4
На этом шаге вам необходимо загрузить Cloudera QuickStartVM, щелкнув опцию «Загрузить сейчас» следующим образом:
Нажав на опцию «Загрузить сейчас», вы перенаправите вас на страницу загрузки QuickStart VM:
Затем вам нужно выбрать вариант ПОЛУЧИТЬ ОДИН СЕЙЧАС, принять лицензионное соглашение и отправить его, как показано ниже:
После завершения загрузки вы найдете три различных варианта совместимости с Cloudera VM — VMware, KVM и VIRTUALBOX. Вы можете выбрать предпочтительный вариант.

Источник
Impala — интерфейсы обработки запросов
Impala предлагает три интерфейса для обработки запросов:
Impala-shell — после того, как вы установили и настроили Impala с помощью виртуальной машины Cloudera, вы можете активировать Impala-shell, введя команду «impala-shell» в редакторе.
Читайте: Разница между большими данными и Hadoop
Интерфейс Hue. Браузер Hue позволяет обрабатывать запросы Impala. Он имеет редактор запросов Impala, где вы можете вводить и выполнять различные запросы Impala. Однако, чтобы использовать редактор, сначала вам нужно будет войти в браузер Hue.
Драйверы ODBC/JDBC . Как и для любой базы данных, Impala также предлагает драйверы ODBC/JDBC. Эти драйверы позволяют подключаться к Impala через поддерживающие их языки программирования (драйверы ODBC/JDBC) и создавать приложения, обрабатывающие запросы в Impala, используя те же языки программирования.
Процедура выполнения запроса
Всякий раз, когда вы передаете запрос с использованием любых интерфейсов Impala, Impalad в кластере обычно принимает ваш запрос. Затем этот Impalad становится узлом-координатором для этого конкретного запроса. После получения запроса координатор проверяет, подходит ли запрос, используя схему таблицы из хранилища метаданных Hive.
После этого он собирает информацию о расположении данных, необходимых для выполнения запроса, из узла имени HDFS и пересылает эту информацию другим Impalad в иерархии для облегчения выполнения запроса. Как только Impalads прочитают указанный блок данных, они обработают запрос. Когда все Impalads в кластере обработают запрос, узел-координатор собирает результат и доставляет его вам.
Команды оболочки Impala
Если вы знакомы с Hive Shell, вы легко разберетесь с Impala Shell, поскольку обе имеют довольно схожую структуру — они позволяют создавать базы данных и таблицы, вставлять данные и выполнять запросы. Команды оболочки Impala делятся на три широкие категории: общие команды, параметры, специфичные для запроса, и параметры, специфичные для таблиц и баз данных.
Общие команды
- помощь
Команда help предлагает список полезных команд, доступных в Impala.
[quickstart.cloudera:21000] > помощь;
Документированные команды (введите help <topic>):
================================================== ======
вычислить описать вставить набор неустановленных с версией
подключить объяснить выйти показать значения использовать
выйти из профиля истории выбрать подсказку оболочки
Недокументированные команды:
=========================================
изменить создать описание удалить помочь загрузить сводку
- Версия
Эта команда предоставляет вам текущую версию Impala.
[quickstart.cloudera:21000] > версия;
Версия оболочки: Impala Shell v2.3.0-cdh5.5.0 (0c891d7), построенная в понедельник, 9 ноября.
12:18:12 по тихоокеанскому времени 2015 г.
Версия сервера: версия impalad 2.3.0-cdh5.5.0 RELEASE (сборка
0c891d79aa38f297d244855a32f1e17280e2129b)
- история
Эта команда отображает последние десять команд, выполненных в оболочке Impala.
[quickstart.cloudera:21000] > история;
[1]:версия;
[2]:помощь;
[3]: показать базы данных;
[4]: использовать my_db;
[5]: история;
- соединять
Эта команда помогает подключиться к данному экземпляру Impala. Если вы не укажете какой-либо экземпляр, то по умолчанию он будет подключаться к стандартному порту 21000.
[quickstart.cloudera:21000] > подключиться;
Подключено к quickstart.cloudera: 21000
Версия сервера: версия impalad 2.3.0-cdh5.5.0 RELEASE (сборка
0c891d79aa38f297d244855a32f1e17280e2129b)
- выйти/выйти
Как следует из названия, команда exit/quit позволяет выйти из оболочки Impala.
[quickstart.cloudera:21000]> выход;
До свидания
Специальные параметры запроса
- объяснять
Эта команда возвращает план выполнения для конкретного запроса.
[quickstart.cloudera:21000] > объяснить, выбрать * из примера;
Запрос: объясните, выберите * из образца
+———————————————————————————+
| Объяснить строку
|
+———————————————————————————+
| Приблизительные требования к хосту: Память = 48,00 МБ VCores = 1
|
| ПРЕДУПРЕЖДЕНИЕ. В следующих таблицах отсутствуют соответствующие статистические данные по таблицам и/или столбцам. |
| my_db.customers |
| 01:ОБМЕН [НЕРАЗДЕЛЕННЫЙ]
|
| 00:СКАНИРОВАНИЕ HDFS [my_db.customers] |
| разделы = 1/1 файлы = 6 размер = 148Б |
+———————————————————————————+
Получено 7 строк за 0,17 с.
- профиль
Эта команда отображает низкоуровневую информацию о последнем/последнем запросе. Он используется для диагностики и настройки производительности запроса.
[ быстрый старт . cloudera : 21000 ] > профиль ;
Профиль выполнения запроса :
Запрос ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Резюме :
Идентификатор сеанса : e74927207cd752b5 : 65ca61e630ad3ad
Тип сеанса : ПЧЕЛИНЫЙ ВОСК
Время начала : 2016 – 04 – 17 23 : 49 : 26.08148000 Время окончания : 2016 – 04 – 17 23 : 49 : 26.2404000
Тип запроса : ОБЪЯСНЕНИЕ
Состояние запроса : ЗАВЕРШЕН
Статус запроса : ОК
Версия Impala : версия Impala 2.3 . 0 – cdh5 . ВЫПУСК 5.0 ( сборка 0c891d77280e2129b )
Пользователь : Cloudera
Подключенный пользователь : cloudera
Делегированный пользователь :
Сетевой адрес : 10.0 . 2,15 : 43870
БД по умолчанию : my_db
Заявление Sql : объяснить , выбрать * из образца
Координатор : быстрый старт . клаудера : 22000
: 0 нс
Временная шкала запроса : 167,304 мс
– Начало выполнения : 41,292 мкс ( 41,292 мкс ) – Планирование завершено : 56,42 мс ( 56,386 мс )
- Доступные строки : 58,247 мс ( 1,819 мс )
– Получена первая строка : 160,72 мс ( 101,824 мс )
– Отменить регистрацию запроса : 166,325 мс ( 6,253 мс )
ИмпалаСервер :
– ClientFetchWaitTimer : 107,969 мс
– RowMaterializationTimer : 0 нс
Специальные параметры таблицы и базы данных
- изменить
Команда alter помогает изменить структуру и имя таблицы.
- описывать
Команда описать предоставляет метаданные таблицы. Он содержит такую информацию, как столбцы и их типы данных.
- уронить
Команда drop помогает удалить конструкцию, которая может быть таблицей, представлением или функцией базы данных.
- вставлять
Команда вставки помогает добавить данные (столбцы) в таблицу и переопределить данные существующей таблицы.
- Выбрать
Команда select может использоваться для выполнения определенной операции с определенным набором данных. Обычно в нем упоминается набор данных, над которым должно быть выполнено действие.
- показывать
Команда show отображает хранилище метаданных различных конструкций, таких как таблицы и базы данных.
- использовать
Команда use помогает изменить текущий контекст конкретной базы данных.
Импала – Комментарии
В Impala комментарии аналогичны комментариям в языке SQL. Как правило, есть два типа комментариев:
Однострочные комментарии
Каждая строка, за которой следует «—», становится комментарием в Impala.
— Привет, добро пожаловать в upGrad.
Многострочные комментарии
Все строки, содержащиеся между /* и */, являются многострочными комментариями в Impala.
/*
Привет это пример

Многострочных комментариев в Impala
*/
Заключение
Мы надеемся, что это подробное руководство по Impala помогло вам разобраться в его тонкостях и принципах работы.
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma в области разработки программного обеспечения со специализацией в области больших данных, которая предназначена для работающих профессионалов и включает более 7 тематических исследований и проектов, охватывает 14 языков и инструментов программирования, практические занятия. семинары, более 400 часов интенсивного обучения и помощь в трудоустройстве в ведущих фирмах.
Изучайте онлайн-курсы по разработке программного обеспечения в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.