Tutoriel ultime Impala Hadoop dont vous aurez besoin [2022]
Publié: 2020-05-14Impala est une base de données analytique native open source conçue pour les plates-formes en cluster telles qu'Apache Hadoop. Il s'agit d'un moteur de requête interactif de type SQL qui s'exécute au-dessus du système de fichiers distribués Hadoop (HDFS) pour faciliter le traitement d'énormes volumes de données à une vitesse fulgurante. En outre, impala est l'un des meilleurs outils Hadoop pour utiliser le Big Data. Aujourd'hui, nous allons parler de tout ce qui concerne Impala, et c'est pourquoi nous avons conçu ce tutoriel Impala pour vous !
Ce tutoriel Impala Hadoop est spécialement destiné à ceux qui souhaitent apprendre Impala. Cependant, pour tirer le meilleur parti de ce didacticiel Impala, il serait utile que vous ayez une compréhension approfondie des principes fondamentaux de SQL ainsi que des commandes Hadoop et HDFS.
Table des matières
Qu'est-ce qu'Impala ?
Impala est un moteur de requête SQL MPP (Massive Parallel Processing) écrit en C++ et Java. Son objectif principal est de traiter de vastes volumes de données stockées dans des clusters Hadoop. Impala promet des performances élevées et une faible latence, et c'est à ce jour le moteur SQL le plus performant (qui offre une expérience de type RDBMS) pour fournir le moyen le plus rapide d'accéder et de traiter les données stockées dans HDFS.
Un autre aspect bénéfique d'Impala est qu'il s'intègre au métastore Hive pour permettre le partage des informations de table entre les deux composants. Il exploite la ruche Apache existante pour effectuer des tâches de longue durée orientées par lots au format de requête SQL. L'intégration Impala-Hive vous permet d'utiliser l'un des deux composants - Hive ou Impala pour le traitement des données ou pour créer des tables sous un seul système de fichiers partagé (HDFS) sans modifier la définition de la table.
Pourquoi Impala ?
Impala combine les performances multi-utilisateurs d'une base de données analytique traditionnelle et la prise en charge SQL avec l'évolutivité et la flexibilité d'Apache Hadoop. Pour ce faire, il utilise des composants Hadoop standard tels que HDFS, HBase, YARN, Sentry et Metastore. Étant donné qu'Impala utilise les mêmes métadonnées, interface utilisateur (Hue Beeswax), syntaxe SQL (Hive SQL) et pilote ODBC (Open Database Connectivity) qu'Apache Hive, il crée une plate-forme unifiée et familière pour les requêtes par lots et en temps réel.
Lire : Idées de projets Big Data pour les débutants

Impala peut lire presque tous les formats de fichiers utilisés par Hadoop, y compris Parquet, Avro et RCFile. De plus, Impala n'est pas construit sur des algorithmes MapReduce - il implémente une architecture distribuée basée sur des processus démons qui gèrent et gèrent tout ce qui concerne l'exécution des requêtes s'exécutant sur la ou les mêmes machines. En conséquence, cela aide à réduire la latence d'utilisation de MapReduce. C'est précisément ce qui rend Impala beaucoup plus rapide que Hive.
Impala – Caractéristiques
Les principales caractéristiques d'Impala sont :
- Il est disponible en tant que moteur de requête SQL open source sous la licence Apache.
- Il vous permet d'accéder aux données à l'aide de requêtes de type SQL.
- Il prend en charge le traitement des données en mémoire - il accède et analyse les données stockées sur les nœuds de données Hadoop.
- Il vous permet de stocker des données dans des systèmes de stockage tels que HDFS, Apache HBase et Amazon s3.
- Il s'intègre facilement aux outils de BI tels que Tableau, Pentaho et Micro Strategy.
- Il prend en charge divers formats de fichiers, notamment Sequence File, Avro, LZO, RCFile et Parquet.
Impala – Principaux avantages
L'utilisation d'Impala offre des avantages significatifs aux utilisateurs, tels que :
- Étant donné qu'Impala prend en charge le traitement des données en mémoire (le traitement a lieu là où les données résident - sur le cluster Hadoop), il n'est pas nécessaire de transformer et de déplacer les données.
- Pour accéder aux données stockées dans HDFS, HBase ou Amazon s3 avec Impala, vous n'avez besoin d'aucune connaissance préalable de Java (tâches MapReduce) - vous pouvez facilement y accéder à l'aide de requêtes SQL de base.
- En règle générale, les données doivent subir un cycle d'extraction-transformation-chargement (ETL) compliqué lors de l'écriture des requêtes dans les outils métier. Cependant, avec Impala, cela n'est pas nécessaire. Impala remplace les étapes fastidieuses de chargement et de réorganisation par des techniques avancées telles que l'analyse exploratoire des données et la découverte des données, accélérant ainsi la vitesse du processus.
- Impala est un pionnier dans l'utilisation du format de fichier Parquet, qui est une disposition de stockage en colonnes optimisée pour les requêtes à grande échelle trouvées dans les entrepôts de données.
Impala – Inconvénients
Bien qu'Impala offre de nombreux avantages, il présente également certaines limites :
- Il ne prend pas en charge la sérialisation et la désérialisation.
- Il ne peut pas lire les fichiers binaires personnalisés ; il ne peut lire que des fichiers texte.
- Chaque fois que de nouveaux enregistrements ou fichiers sont ajoutés au répertoire de données dans HDFS, vous devrez actualiser la table de données.
Impala – Architecture
Impala est découplé de son moteur de stockage (contrairement aux systèmes de stockage traditionnels). Il comprend trois composants principaux - Impala Daemon (Impalad) , Impala StateStore et Impala Metadata & MetaStore.
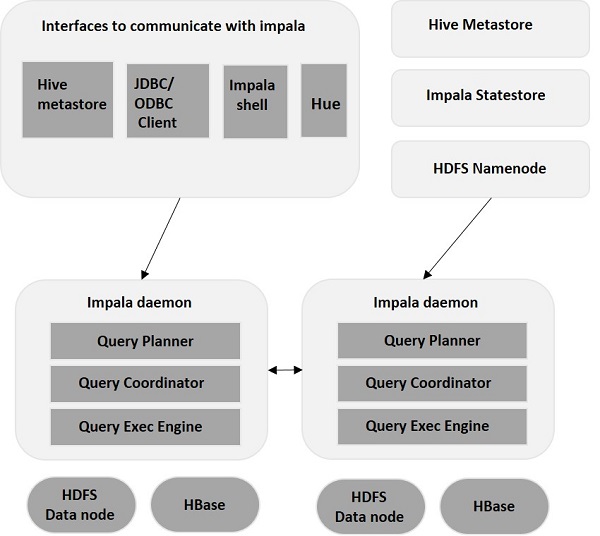
Démon Impala
Impala Daemon, alias Impalad, s'exécute sur des nœuds individuels où Impala est installé. Il accepte les requêtes de plusieurs interfaces (shell Impala, navigateur Hue, etc.) et les traite. Chaque fois qu'une requête est soumise à un Impalad sur un nœud particulier, le nœud devient un « nœud coordinateur » pour cette requête. De cette façon, plusieurs requêtes sont servies par Impalad s'exécutant sur d'autres nœuds.
Une fois les requêtes acceptées, Impalad lit et écrit les fichiers de données et parallélise les requêtes en distribuant la tâche aux autres nœuds Impala du cluster. Les utilisateurs peuvent soumettre des requêtes à un Impalad dédié ou de manière équilibrée à d'autres Impalad du cluster, en fonction de leurs besoins. Ces requêtes commencent ensuite à être traitées sur les différentes instances d'Impalad et renvoient le résultat au nœud de coordination principal.
Impala StateStore
L'Impala StateStore surveille et vérifie la santé de chaque Impalad et transmet également le rapport de santé de la santé de chaque démon Impala aux autres démons. Il peut s'exécuter sur le même nœud où le serveur Impala est en cours d'exécution ou sur un autre nœud du cluster. En cas de défaillance d'un nœud pour une raison quelconque, l'Impala StateStore met à jour tous les autres nœuds à propos de la défaillance. Dans un tel cas, les autres démons Impala cessent d'attribuer d'autres requêtes au nœud défaillant.
Impala Métadonnées et MetaStore
Dans Impala, toutes les informations cruciales, y compris les définitions de table, les informations de table et de colonne, etc., sont stockées dans une base de données centralisée appelée MetaStore. Lorsqu'il s'agit de volumes importants de données contenant plusieurs partitions, il devient difficile d'obtenir des métadonnées spécifiques à une table. C'est là qu'Impala vient à la rescousse. Étant donné que les nœuds Impala individuels mettent en cache toutes les métadonnées localement, il devient facile d'obtenir instantanément des informations spécifiques.
Chaque fois que vous mettez à jour la définition de table/les données de table, tous les démons Impala doivent également mettre à jour leur cache de métadonnées en récupérant les dernières métadonnées avant de pouvoir émettre une nouvelle requête sur une table particulière.
Impala – Installation d'Impala
Tout comme vous devez installer Hadoop et son écosystème sur le système d'exploitation Linux, vous pouvez faire de même avec Impala. Comme c'est Cloudera qui a livré Impala pour la première fois, vous pouvez facilement y accéder via la machine virtuelle Cloudera QuickStart.
Lire : Tutoriel Hadoop
Comment télécharger la machine virtuelle Cloudera QuickStart
Pour télécharger la machine virtuelle Cloudera QuickStart, vous devez suivre les étapes décrites ci-dessous.
Étape 1
Ouvrez la page d'accueil de Cloudera ( http://www.cloudera.com/ ) et vous trouverez quelque chose comme ceci :
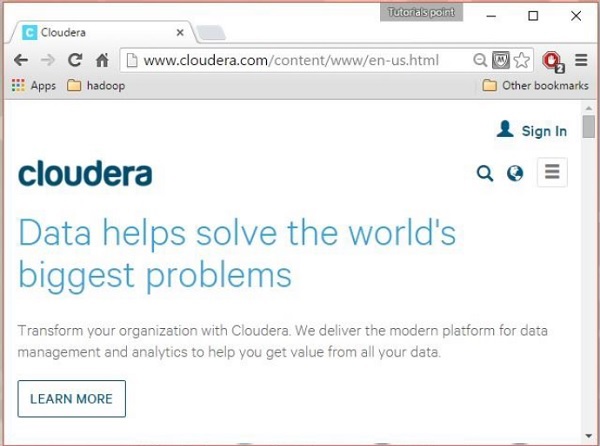
Étape 2
Pour vous inscrire sur Cloudera, vous devez cliquer sur l'option « S'inscrire maintenant », ce qui ouvrira la page d'inscription du compte. Si vous êtes déjà inscrit sur Cloudera, vous pouvez cliquer sur l'option "Connexion" sur la page, et cela vous redirigera davantage vers la page de connexion comme suit :
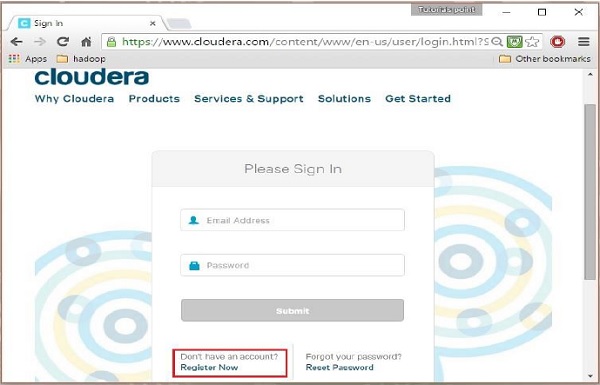
Étape 3
Une fois connecté, ouvrez la page de téléchargement du site Web en cliquant sur l'option "Téléchargements" dans le coin supérieur gauche de la page, comme indiqué ci-dessous :
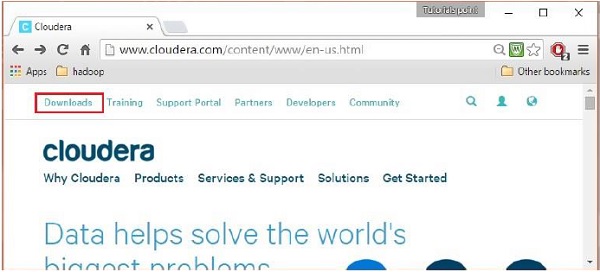
Étape 4
Dans cette étape, vous devez télécharger Cloudera QuickStartVM en cliquant sur l'option "Télécharger maintenant" comme suit :
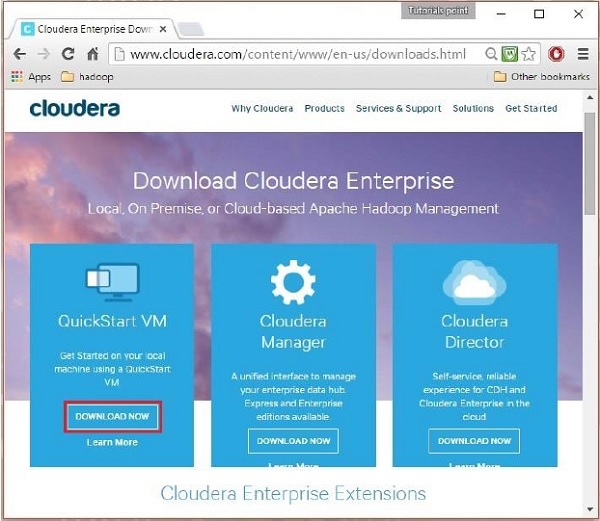
Cliquer sur l'option Télécharger maintenant vous redirigera vers la page de téléchargement de QuickStart VM :
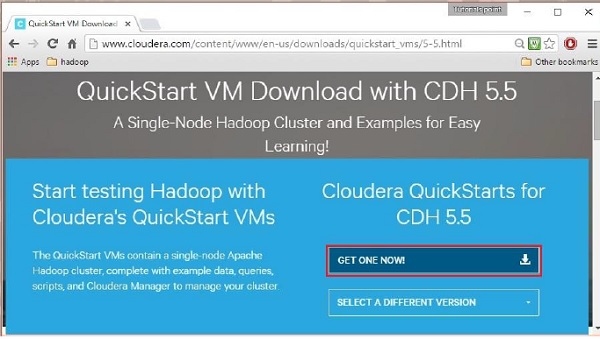
Ensuite, vous devez sélectionner l'option GET ONE NOW, accepter le contrat de licence et le soumettre comme indiqué ci-dessous :
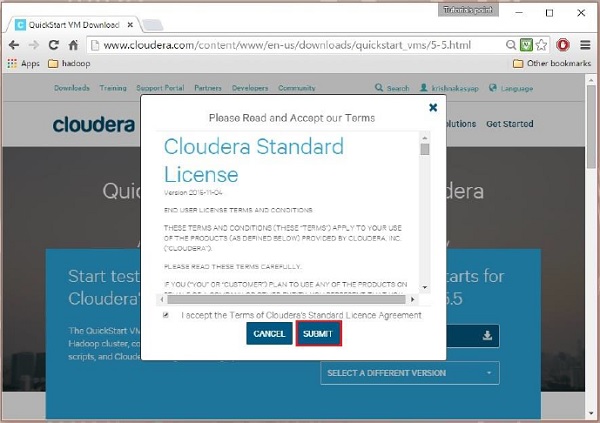

Une fois le téléchargement terminé, vous trouverez trois options compatibles Cloudera VM différentes - VMware, KVM et VIRTUALBOX. Vous pouvez choisir votre option préférée.
La source
Impala – Interfaces de traitement des requêtes
Impala propose trois interfaces pour le traitement des requêtes :
Impala-shell – Une fois que vous avez installé et configuré Impala à l'aide de la machine virtuelle Cloudera, vous pouvez activer Impala-shell en tapant la commande « impala-shell » dans l'éditeur.
Lire : Différence entre Big Data et Hadoop
Interface Hue – Le navigateur Hue vous permet de traiter les requêtes Impala. Il dispose d'un éditeur de requêtes Impala dans lequel vous pouvez taper et exécuter différentes requêtes Impala. Cependant, pour utiliser l'éditeur, vous devez d'abord vous connecter au navigateur Hue.
Pilotes ODBC/JDBC – Comme c'est le cas pour toutes les bases de données, Impala propose également des pilotes ODBC/JDBC. Ces pilotes vous permettent de vous connecter à Impala via des langages de programmation qui les prennent en charge (pilotes ODBC/JDBC) et de créer des applications qui traitent les requêtes dans Impala en utilisant les mêmes langages de programmation.
Procédure d'exécution de la requête
Chaque fois que vous transmettez une requête à l'aide d'une interface Impala, un Impalad du cluster accepte généralement votre requête. Cet Impalad devient alors le nœud coordinateur pour cette requête particulière. Après avoir reçu la requête, le coordinateur vérifie si la requête est appropriée ou non en utilisant le schéma de table du Hive Metastore.
Après cela, il rassemble des informations sur l'emplacement des données nécessaires à l'exécution de la requête à partir du nœud de nom HDFS et transmet ces informations aux autres Impalads de la hiérarchie pour faciliter l'exécution de la requête. Une fois que les Impalads ont lu le bloc de données spécifié, ils traitent la requête. Lorsque tous les Impalad du cluster ont traité la requête, le nœud coordinateur collecte le résultat et vous le transmet.
Commandes du shell Impala
Si vous connaissez Hive Shell, vous pouvez facilement comprendre Impala Shell car les deux partagent une structure assez similaire - ils permettent de créer des bases de données et des tables, d'insérer des données et d'émettre des requêtes. Les commandes Impala Shell se répartissent en trois grandes catégories : les commandes générales, les options spécifiques aux requêtes et les options spécifiques aux tables et aux bases de données.
Commandes générales
- aider
La commande help propose une liste de commandes utiles disponibles dans Impala.
[quickstart.cloudera:21000] > aide ;
Commandes documentées (tapez help <topic>) :
================================================= ======
calculer décrire insérer définir unset avec la version
se connecter expliquer quitter afficher les valeurs utiliser
quitter le profil d'historique sélectionner l'astuce du shell
Commandes non documentées :
========================================
modifier créer desc déposer aide charger résumé
- Version
Cette commande vous fournit la version actuelle d'Impala.
[quickstart.cloudera:21000] > version ;
Version Shell : Impala Shell v2.3.0-cdh5.5.0 (0c891d7) construite le lundi 9 novembre
12:18:12 HNP 2015
Version serveur : impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- l'histoire
Cette commande affiche les dix dernières commandes exécutées dans Impala Shell.
[quickstart.cloudera:21000] > historique ;
[1] :version ;
[2] : aide ;
[3] :afficher les bases de données ;
[4] : utilisez my_db ;
[5] :historique ;
- relier
Cette commande permet de se connecter à une instance donnée d'Impala. Si vous ne spécifiez aucune instance, alors par défaut, elle se connectera au port par défaut 21000.
[quickstart.cloudera:21000] > connecter ;
Connecté à quickstart.cloudera:21000
Version serveur : impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- quitter/quitter
Comme son nom l'indique, la commande exit/quit vous permet de quitter Impala Shell.
[quickstart.cloudera:21000] > quitter ;
Au revoir cloudera
Options spécifiques à la requête
- Explique
Cette commande renvoie le plan d'exécution pour une requête particulière.
[quickstart.cloudera:21000] > expliquer sélectionner * à partir de l'exemple ;
Requête : expliquer sélectionner * à partir de l'échantillon
+————————————————————————————+
| Expliquer la chaîne
|
+————————————————————————————+
| Estimation des besoins par hôte : mémoire = 48,00 Mo VCores = 1
|
| AVERTISSEMENT : les tables suivantes manquent de statistiques de table et/ou de colonne pertinentes. |
| my_db.clients |
| 01 : ÉCHANGE [NON PARTITIONNÉ]
|
| 00:SCAN HDFS [my_db.customers] |
| partitions = 1/1 fichiers = 6 taille = 148B |
+————————————————————————————+
Récupéré 7 ligne(s) en 0.17s
- profil
Cette commande affiche les informations de bas niveau sur la requête récente/dernière. Il est utilisé pour le diagnostic et le réglage des performances d'une requête.
[ démarrage rapide . cloudera : 21000 ] > profil ;
Profil d' exécution de la requête :
Requête ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Résumé :
ID de session : e74927207cd752b5 : 65ca61e630ad3ad
Type de session : CIRE D'ABEILLE
Heure de début : 2016 – 04 – 17 23 : 49 : 26.08148000 Heure de fin : 2016 – 04 – 17 23 : 49 : 26.2404000
Type de requête : EXPLIQUER
État de la requête : TERMINÉ
État de la requête : OK
Version Impala : version impala 2.3 . 0 – cdh5 . VERSION 5.0 ( version 0c891d77280e2129b )
Utilisateur : cloudera
Utilisateur Connecté : cloudera
Utilisateur délégué :
Adresse réseau : 10.0 . 2.15 : 43870
Base de données par défaut : my_db
Instruction SQL : expliquer sélectionner * à partir de l'échantillon
Coordinateur : démarrage rapide . cloudera : 22000
: 0ns
Chronologie de la requête : 167,304 ms
– Début d'exécution : 41.292us ( 41.292us ) – Planification terminée : 56.42ms ( 56.386ms )
– Lignes disponibles : 58.247ms ( 1.819ms )
– Première ligne extraite : 160,72 ms ( 101,824 ms )
– Requête de désenregistrement : 166,325 ms ( 6,253 ms )
Serveur Impala :
– ClientFetchWaitTimer : 107.969ms
– RowMaterializationTimer : 0ns
Options spécifiques aux tables et aux bases de données
- modifier
La commande alter aide à changer la structure et le nom d'une table.
- décris
La commande describe fournit les métadonnées d'une table. Il contient des informations telles que les colonnes et leurs types de données.
- laissez tomber
La commande drop permet de supprimer une construction, qui peut être une table, une vue ou une fonction de base de données.
- insérer
La commande insert permet d'ajouter des données (colonnes) dans une table et de remplacer les données d'une table existante
- sélectionner
La commande select peut être utilisée pour effectuer une opération spécifique sur un jeu de données particulier. Il mentionne généralement le jeu de données sur lequel l'action doit être effectuée.
- Afficher
La commande show affiche le metastore de diverses constructions telles que des tables et des bases de données.
- utiliser
La commande use aide à changer le contexte actuel d'une base de données particulière.
Impala – Commentaires
Dans Impala, les commentaires sont similaires à ceux du langage SQL. En règle générale, il existe deux types de commentaires :
Commentaires sur une seule ligne
Chaque ligne suivie de "-" devient un commentaire dans Impala.
— Bonjour, bienvenue sur upGrad.
Commentaires multilignes
Toutes les lignes contenues entre /* et */ sont des commentaires multilignes dans Impala.
/*
salut c'est un exemple

Des commentaires multilignes dans Impala
*/
Conclusion
Nous espérons que ce tutoriel détaillé sur l'Impala vous a aidé à comprendre ses subtilités et son fonctionnement.
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.
Apprenez des cours de développement de logiciels en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.