您将需要的终极 Impala Hadoop 教程 [2022]
已发表: 2020-05-14Impala 是一个开源的本地分析数据库,专为 Apache Hadoop 等集群平台而设计。 它是一个交互式 SQL 式查询引擎,运行在 Hadoop 分布式文件系统 (HDFS) 之上,以促进以闪电般的速度处理海量数据。 此外,impala 是使用大数据的顶级 Hadoop 工具之一。 今天,我们将讨论 Impala 的所有内容,因此,我们为您设计了这个 Impala 教程!
这个 Impala Hadoop 教程是专门为那些希望学习 Impala 的人准备的。 但是,为了获得本 Impala 教程的最大好处,如果您深入了解 SQL 的基础知识以及 Hadoop 和 HDFS 命令,将会有所帮助。
目录
什么是黑斑羚?
Impala 是一个用 C++ 和 Java 编写的MPP(大规模并行处理)SQL 查询引擎。 它的主要目的是处理存储在 Hadoop 集群中的大量数据。 Impala 承诺高性能和低延迟,它是迄今为止性能最好的 SQL 引擎(提供类似 RDBMS 的体验),以提供访问和处理存储在 HDFS 中的数据的最快方式。
Impala 的另一个优点是它与 Hive 元存储集成以允许在两个组件之间共享表信息。 它利用现有的 Apache Hive 以 SQL 查询格式执行面向批处理的、长时间运行的作业。 Impala-Hive 集成允许您使用两个组件中的任何一个 - Hive 或 Impala 进行数据处理,或者在单个共享文件系统 (HDFS) 下创建表,而无需更改表定义。
为什么是黑斑羚?
Impala 将传统分析数据库的多用户性能和 SQL 支持与 Apache Hadoop 的可扩展性和灵活性相结合。 它通过使用 HDFS、HBase、YARN、Sentry 和 Metastore 等标准 Hadoop 组件来实现。 由于 Impala 使用与 Apache Hive 相同的元数据、用户界面 (Hue Beeswax)、SQL 语法 (Hive SQL) 和 ODBC(开放式数据库连接)驱动程序,因此它为面向批处理的实时查询创建了一个统一且熟悉的平台。
阅读:面向初学者的大数据项目理念

Impala 可以读取 Hadoop 使用的几乎所有文件格式,包括 Parquet、Avro 和 RCFile。 此外,Impala 不是基于 MapReduce 算法构建的——它实现了一个基于守护进程的分布式架构,该进程处理和管理与在同一台机器上运行的查询执行相关的所有内容。 因此,它有助于减少使用 MapReduce 的延迟。 这正是使 Impala 比 Hive 快得多的原因。
Impala – 功能
Impala 的主要特点是:
- 它在 Apache 许可下可作为开源 SQL 查询引擎使用。
- 它允许您使用类似 SQL 的查询来访问数据。
- 它支持内存数据处理——它访问和分析存储在 Hadoop 数据节点上的数据。
- 它允许您将数据存储在 HDFS、Apache HBase 和 Amazon s3 等存储系统中。
- 它可以轻松与 Tableau、Pentaho 和 Micro strategy 等 BI 工具集成。
- 它支持各种文件格式,包括 Sequence File、Avro、LZO、RCFile 和 Parquet。
Impala – 主要优势
使用 Impala 为用户提供了一些显着的优势,例如:
- 由于 Impala 支持内存中数据处理(处理发生在数据所在的位置 - 在 Hadoop 集群上),因此不需要数据转换和数据移动。
- 要使用 Impala 访问存储在 HDFS、HBase 或 Amazon s3 中的数据,您不需要任何 Java(MapReduce 作业)的先验知识——您可以使用基本的 SQL 查询轻松访问它。
- 通常,在业务工具中编写查询时,数据必须经历复杂的提取-转换-加载 (ETL) 循环。 然而,有了 Impala,就不需要这样做了。 Impala 用探索性数据分析和数据发现等先进技术取代了耗时的加载和重组阶段,从而提高了流程的速度。
- Impala 是使用 Parquet 文件格式的先驱,这是一种列式存储布局,针对数据仓库中的大规模查询进行了优化。
Impala – 缺点
尽管 Impala 提供了许多好处,但它也有一定的局限性:
- 它不支持序列化和反序列化。
- 它无法读取自定义二进制文件; 它只能读取文本文件。
- 每次向 HDFS 中的数据目录添加新记录或文件时,都需要刷新数据表。
Impala – 建筑
Impala 与其存储引擎分离(与传统存储系统相反)。 它包括三个主要组件——Impala Daemon (Impalad) 、Impala StateStore 和 Impala Metadata & MetaStore。
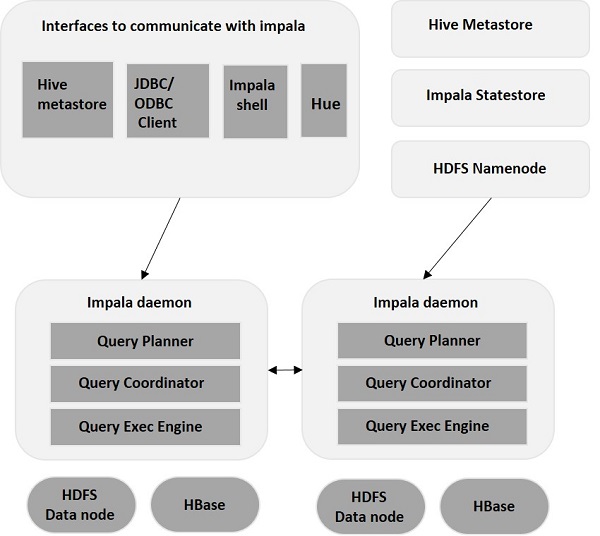
黑斑羚守护进程
Impala Daemon,又名 Impalad,在安装 Impala 的各个节点上运行。 它接受来自多个接口(Impala shell、Hue 浏览器等)的查询并处理它们。 每次向特定节点上的 Impalad 提交查询时,该节点都会成为该查询的“协调节点”。 通过这种方式,多个查询由运行在其他节点上的 Impalad 提供服务。
一旦接受查询, Impalad 就会读取和写入数据文件,并通过将任务分发到集群中的其他 Impala 节点来并行化查询。 用户可以根据自己的要求将查询提交给专用的Impalad ,或者以负载均衡的方式提交给集群中的其他Impalad 。 然后这些查询开始处理不同的Impalad 实例并将结果返回到主协调节点。
Impala StateStore
Impala StateStore 监控和检查每个Impalad的健康状况,并将每个 Impala Daemon 健康状况的健康报告转发给其他守护进程。 它可以在运行 Impala 服务器的同一节点上运行,也可以在集群中的另一个节点上运行。 如果由于某种原因出现节点故障,Impala StateStore 会更新所有其他节点的故障信息。 在这种情况下,其他 Impala 守护进程停止将任何进一步的查询分配给故障节点。
Impala 元数据和元存储
在 Impala 中,所有关键信息,包括表定义、表和列信息等,都存储在称为 MetaStore 的集中式数据库中。 在处理包含多个分区的大量数据时,获取特定于表的元数据变得具有挑战性。 这就是 Impala 来救援的地方。 由于各个 Impala 节点在本地缓存所有元数据,因此很容易立即获取特定信息。
每次更新表定义/表数据时,所有 Impala 守护进程还必须通过检索最新元数据来更新其元数据缓存,然后才能针对特定表发出新查询。
Impala – 安装 Impala
就像您需要在 Linux 操作系统上安装 Hadoop 及其生态系统一样,您可以使用 Impala 执行相同的操作。 由于是 Cloudera 首次发布 Impala,您可以通过 Cloudera QuickStart VM 轻松访问它。
阅读: Hadoop 教程
如何下载 Cloudera 快速入门 VM
要下载 Cloudera QuickStart VM,您必须按照以下步骤进行操作。
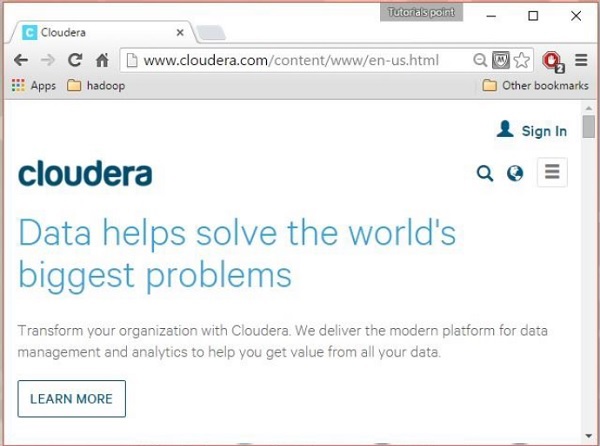
第1步
打开 Cloudera 主页 ( http://www.cloudera.com/ ),您会发现如下内容:
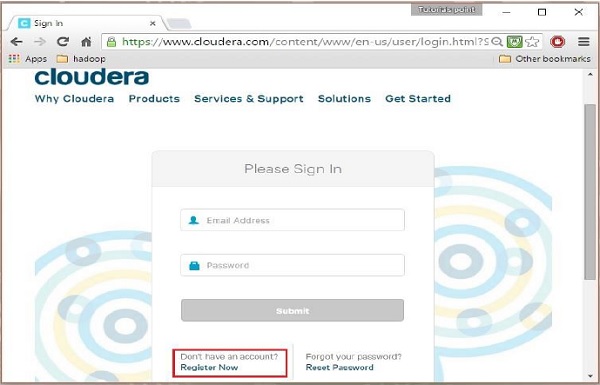
第2步
要在 Cloudera 上注册,您必须单击“立即注册”选项,这将打开“帐户注册”页面。 如果您已经在 Cloudera 上注册,您可以点击页面上的“登录”选项,它会进一步将您重定向到登录页面,如下所示:
第 3 步
登录后,点击页面左上角的“下载”选项,打开网站的下载页面,如下图:
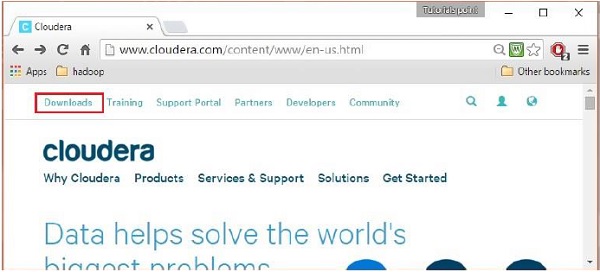
第四步
在此步骤中,您需要通过单击“立即下载”选项来下载 Cloudera QuickStartVM,如下所示:
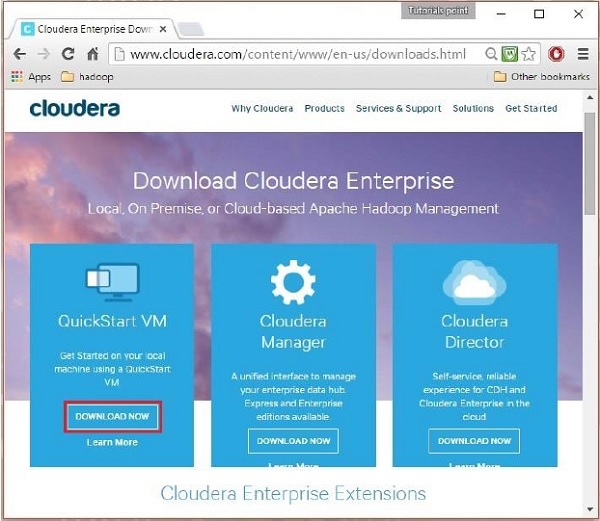
单击立即下载选项会将您重定向到 QuickStart VM 的下载页面:
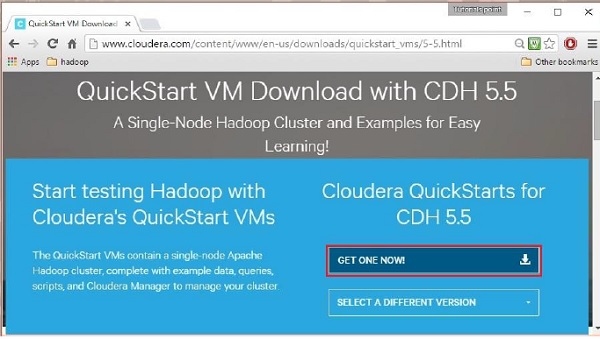
然后您必须选择 GET ONE NOW 选项,接受许可协议,然后提交,如下所示:
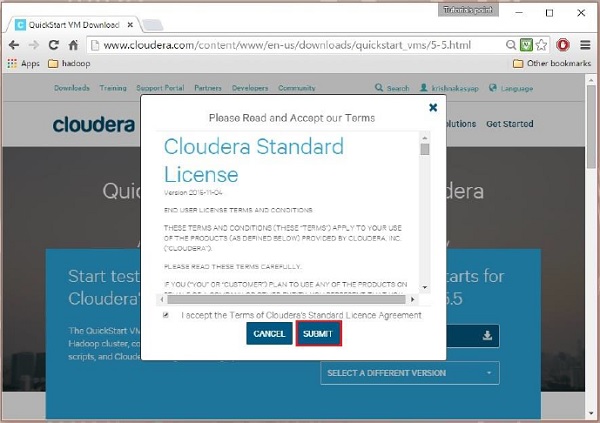
下载完成后,您会发现三个不同的 Cloudera VM Compatible 选项——VMware、KVM 和 VIRTUALBOX。 您可以选择您喜欢的选项。
资源
Impala – 查询处理接口
Impala 提供了三个处理查询的接口:
Impala-shell –使用 Cloudera VM 安装和设置 Impala 后,您可以通过在编辑器中键入命令“impala-shell”来激活 Impala-shell。
阅读:大数据和 Hadoop 之间的区别
Hue 界面 – Hue 浏览器允许您处理 Impala 查询。 它有一个 Impala 查询编辑器,您可以在其中键入和执行不同的 Impala 查询。 但是,要使用编辑器,首先需要登录 Hue 浏览器。
ODBC/JDBC 驱动程序——与每个数据库一样,Impala 也提供 ODBC/JDBC 驱动程序。 这些驱动程序允许您通过支持它们的编程语言(ODBC/JDBC 驱动程序)连接到 Impala,并使用相同的编程语言构建在 Impala 中处理查询的应用程序。

查询执行过程
每当您使用任何 Impala 接口传递查询时,集群中的 Impalad 通常都会接受您的查询。 然后这个 Impalad 将成为该特定查询的协调节点。 收到查询后,协调器使用 Hive Metastore 中的 Table Schema 验证查询是否合适。
在此之后,它从 HDFS 名称节点收集有关执行查询所需的数据位置的信息,并将此信息转发到层次结构中的其他 Impalad 以促进查询执行。 一旦 Impalads 读取指定的数据块,它们就会处理查询。 当集群中的所有 Impalad 处理完查询后,协调器节点会收集结果并将其交付给您。
Impala Shell 命令
如果您熟悉 Hive Shell,则可以轻松找出 Impala Shell,因为它们具有非常相似的结构——它们允许创建数据库和表、插入数据和发出查询。 Impala Shell 命令分为三大类:通用命令、查询特定选项以及表和数据库特定选项。
一般命令
- 帮助
help 命令提供了 Impala 中可用的有用命令列表。
[quickstart.cloudera:21000] > 帮助;
记录的命令(输入帮助 <topic>):
==================================================== ======
计算描述插入集未设置版本
连接解释退出显示值使用
退出历史配置文件选择外壳提示
未记录的命令:
==========================================
alter create desc drop help load 摘要
- 版本
此命令为您提供 Impala 的当前版本。
[quickstart.cloudera:21000] > 版本;
Shell 版本:Impala Shell v2.3.0-cdh5.5.0 (0c891d7) 于 11 月 9 日星期一构建
2015 年太平洋标准时间 12:18:12
服务器版本:impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- 历史
此命令显示在 Impala Shell 中执行的最后十个命令。
[quickstart.cloudera:21000] > 历史;
[1]:版本;
[2]:帮助;
[3]:显示数据库;
[4]:使用 my_db;
[5]:历史;
- 连接
此命令有助于连接到给定的 Impala 实例。 如果您不指定任何实例,则默认情况下,它将连接到默认端口 21000。
[quickstart.cloudera:21000] > 连接;
连接到 quickstart.cloudera:21000
服务器版本:impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- 退出/退出
顾名思义,exit/quit 命令让您退出 Impala Shell。
[quickstart.cloudera:21000] > 退出;
再见云时代
查询特定选项
- 解释
此命令返回特定查询的执行计划。
[quickstart.cloudera:21000] > 解释 select * from sample;
查询:说明 select * from sample
+——————————————————————————————+
| 解释字符串
|
+——————————————————————————————+
| 估计的每台主机要求:内存 = 48.00MB VCores = 1
|
| 警告:以下表格缺少相关的表格和/或列统计信息。 |
| my_db.customers |
| 01:EXCHANGE [未分区]
|
| 00:扫描 HDFS [my_db.customers] |
| 分区 = 1/1 文件 = 6 大小 = 148B |
+——————————————————————————————+
在 0.17 秒内获取 7 行
- 轮廓
此命令显示有关最近/最新查询的低级信息。 它用于查询的诊断和性能调整。
[快速入门。 cloudera : 21000 ] >个人资料;
查询运行时配置文件:
查询( id = 164b1294a1049189 : a67598a6699e3ab6 ):
摘要:
会话ID : e74927207cd752b5 : 65ca61e630ad3ad
会话类型: BEESWAX
开始时间: 2016 – 04 – 17 23 : 49 : 26.08148000结束时间: 2016 – 04 – 17 23 : 49 : 26.2404000
查询类型:解释
查询状态:已完成
查询状态: OK
Impala版本: impalad 2.3版。 0 - cdh5 。 5.0发布(构建0c891d77280e2129b )
用户: cloudera
连接用户: cloudera
委托用户:
网络地址: 10.0 。 2.15 : 43870
默认数据库: my_db
Sql语句:解释select * from sample
协调员:快速入门。 云时代: 22000
: 0ns
查询时间线: 167.304ms
–开始执行: 41.292us ( 41.292us ) –计划完成: 56.42ms ( 56.386ms )
–可用行数: 58.247 毫秒( 1.819 毫秒)
–获取的第一行: 160.72ms ( 101.824ms )
–注销查询: 166.325ms ( 6.253ms )
黑斑服务器:
– ClientFetchWaitTimer : 107.969ms
– RowMaterializationTimer : 0ns
表和数据库特定选项
- 改变
alter 命令有助于更改表的结构和名称。
- 描述
describe 命令提供表的元数据。 它包含列及其数据类型等信息。
- 降低
drop 命令有助于删除一个构造,它可以是一个表、一个视图或一个数据库函数。
- 插入
insert 命令有助于将数据(列)附加到表中并覆盖现有表的数据
- 选择
select 命令可用于对特定数据集执行特定操作。 它通常提到要在其上完成操作的数据集。
- 显示
show 命令显示各种结构(如表和数据库)的元存储。
- 采用
use 命令有助于更改特定数据库的当前上下文。
黑斑羚 – 评论
在 Impala 中,注释类似于 SQL 语言中的注释。 通常,有两种类型的注释:
单行注释
后跟“-”的每一行都成为 Impala 中的注释。
— 您好,欢迎来到 upGrad。
多行注释
/* 和 */ 之间的所有行都是 Impala 中的多行注释。
/*
你好这是一个例子

Impala 中的多行注释
*/
结论
我们希望这个详细的 Impala 教程可以帮助您了解它的复杂性以及它的功能。
如果您有兴趣了解有关大数据的更多信息,请查看我们的 PG 大数据软件开发专业文凭课程,该课程专为在职专业人士设计,提供 7 多个案例研究和项目,涵盖 14 种编程语言和工具,实用的动手操作研讨会,超过 400 小时的严格学习和顶级公司的就业帮助。
从世界顶级大学在线学习软件开发课程。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。