Ultimate Impala Hadoop Tutorial, którego będziesz potrzebować [2022]
Opublikowany: 2020-05-14Impala to natywna analityczna baza danych typu open source przeznaczona dla platform klastrowych, takich jak Apache Hadoop. Jest to interaktywny silnik zapytań podobny do języka SQL, który działa w oparciu o rozproszony system plików Hadoop (HDFS), aby ułatwić przetwarzanie ogromnych ilości danych z błyskawiczną prędkością. Impala jest również jednym z najlepszych narzędzi Hadoop do korzystania z dużych zbiorów danych. Dzisiaj porozmawiamy o wszystkim, co dotyczy Impali, dlatego zaprojektowaliśmy dla Ciebie ten samouczek dotyczący Impali!
Ten samouczek Impala Hadoop jest specjalnie przeznaczony dla tych, którzy chcą nauczyć się Impala. Jednak, aby czerpać maksymalne korzyści z tego samouczka Impala, pomocne byłoby dogłębne zrozumienie podstaw SQL wraz z poleceniami Hadoop i HDFS.
Spis treści
Co to jest Impala?
Impala to silnik zapytań SQL MPP (Massive Parallel Processing) napisany w C++ i Javie. Jego głównym celem jest przetwarzanie ogromnych ilości danych przechowywanych w klastrach Hadoop. Impala obiecuje wysoką wydajność i niskie opóźnienia, a jak dotąd jest to najbardziej wydajny silnik SQL (który oferuje wrażenia podobne do RDBMS), aby zapewnić najszybszy sposób uzyskiwania dostępu i przetwarzania danych przechowywanych w HDFS.
Innym korzystnym aspektem Impali jest integracja z metamagazynem Hive, aby umożliwić udostępnianie informacji z tabeli między obydwoma komponentami. Wykorzystuje istniejący Apache Hive do wykonywania zorientowanych wsadowo, długotrwałych zadań w formacie zapytań SQL. Integracja Impala-Hive umożliwia użycie jednego z dwóch komponentów — Hive lub Impala do przetwarzania danych lub tworzenia tabel w ramach jednego współdzielonego systemu plików (HDFS) bez zmiany definicji tabeli.
Dlaczego Impala?
Impala łączy wydajność wielu użytkowników tradycyjnej analitycznej bazy danych i obsługę SQL ze skalowalnością i elastycznością Apache Hadoop. Robi to za pomocą standardowych komponentów Hadoop, takich jak HDFS, HBase, YARN, Sentry i Metastore. Ponieważ Impala używa tych samych metadanych, interfejsu użytkownika (Hue Beeswax), składni SQL (Hive SQL) i sterownika ODBC (Open Database Connectivity) jako Apache Hive, tworzy ujednoliconą i znaną platformę dla zapytań zorientowanych wsadowo i w czasie rzeczywistym.
Przeczytaj: Pomysły na projekty Big Data dla początkujących

Impala może czytać prawie wszystkie formaty plików używane przez Hadoop, w tym Parquet, Avro i RCFile. Ponadto Impala nie jest zbudowana na algorytmach MapReduce – implementuje architekturę rozproszoną opartą na procesach demonów, które obsługują i zarządzają wszystkim, co jest związane z wykonywaniem zapytań działających na tej samej maszynie/ach. W rezultacie pomaga zmniejszyć opóźnienie korzystania z MapReduce. To właśnie sprawia, że Impala jest znacznie szybsza niż Hive.
Impala – Funkcje
Główne cechy Impali to:
- Jest dostępny jako silnik zapytań SQL typu open source na licencji Apache.
- Umożliwia dostęp do danych za pomocą zapytań podobnych do SQL.
- Obsługuje przetwarzanie danych w pamięci — uzyskuje dostęp i analizuje dane przechowywane w węzłach danych Hadoop.
- Umożliwia przechowywanie danych w systemach pamięci masowej, takich jak HDFS, Apache HBase i Amazon s3.
- Łatwo integruje się z narzędziami BI, takimi jak Tableau, Pentaho i strategia Micro.
- Obsługuje różne formaty plików, w tym Sequence File, Avro, LZO, RCFile i Parquet.
Impala – kluczowe zalety
Korzystanie z Impali daje użytkownikom kilka znaczących korzyści, takich jak:
- Ponieważ Impala obsługuje przetwarzanie danych w pamięci (przetwarzanie odbywa się tam, gdzie dane się znajdują – w klastrze Hadoop), nie ma potrzeby przekształcania danych i przenoszenia danych.
- Aby uzyskać dostęp do danych przechowywanych w HDFS lub HBase lub Amazon s3 za pomocą Impala, nie potrzebujesz żadnej wcześniejszej znajomości języka Java (zadania MapReduce) – możesz łatwo uzyskać do nich dostęp za pomocą podstawowych zapytań SQL.
- Ogólnie rzecz biorąc, podczas pisania zapytań w narzędziach biznesowych dane muszą przejść skomplikowany cykl ekstrakcji-transformacji-ładowania (ETL). Jednak w przypadku Impali nie ma takiej potrzeby. Impala zastępuje czasochłonne etapy ładowania i reorganizacji zaawansowanymi technikami, takimi jak eksploracyjna analiza danych i odkrywanie danych, przyspieszając w ten sposób proces.
- Impala jest pionierem w korzystaniu z formatu plików Parquet, który jest kolumnowym układem pamięci zoptymalizowanym pod kątem zapytań na dużą skalę znalezionych w hurtowniach danych.
Impala – wady
Chociaż Impala oferuje wiele korzyści, ma też pewne ograniczenia:
- Nie obsługuje serializacji i deserializacji.
- Nie może czytać niestandardowych plików binarnych; może czytać tylko pliki tekstowe.
- Za każdym razem, gdy do katalogu danych w HDFS dodawane są nowe rekordy lub pliki, konieczne będzie odświeżenie tabeli danych.
Impala – Architektura
Impala jest oddzielona od swojego silnika pamięci masowej (w przeciwieństwie do tradycyjnych systemów pamięci masowej). Zawiera trzy główne komponenty – Impala Daemon (Impalad) , Impala StateStore oraz Impala Metadata & MetaStore.
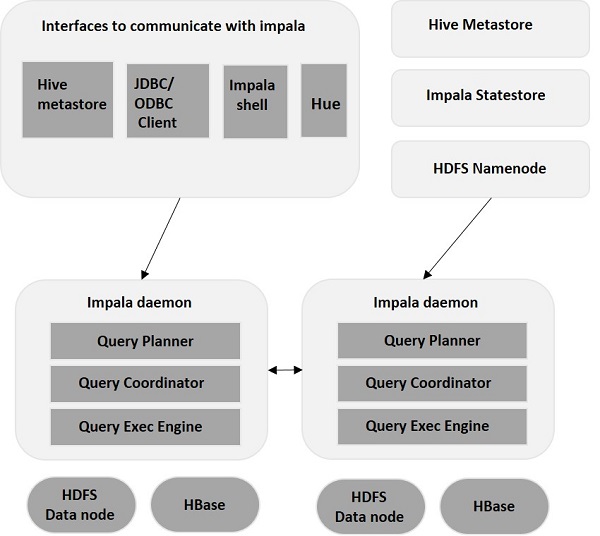
Demon Impala
Impala Daemon, czyli Impalad, działa na poszczególnych węzłach, w których zainstalowano Impala. Przyjmuje zapytania z wielu interfejsów (powłoka Impala, przeglądarka Hue itp.) i przetwarza je. Za każdym razem, gdy zapytanie jest przesyłane do Impaladu w określonym węźle, węzeł ten staje się „węzłem koordynatora” dla tego zapytania. W ten sposób Impalad działający na innych węzłach obsługuje wiele zapytań.
Gdy zapytania zostaną zaakceptowane, Impalad odczytuje i zapisuje pliki danych oraz paralelizuje zapytania poprzez dystrybucję zadania do innych węzłów Impala w klastrze. Użytkownicy mogą przesyłać zapytania do dedykowanego Impaladu lub w sposób zrównoważony do innego Impaladu w klastrze, w zależności od swoich wymagań. Zapytania te następnie rozpoczynają przetwarzanie w różnych instancjach Impalad i zwracają wynik do głównego węzła koordynującego.
Impala StateStore
Impala StateStore monitoruje i sprawdza kondycję każdego Impalada , a także przekazuje raport o kondycji każdego demona Impala innym demonom. Może działać w tym samym węźle, na którym działa serwer Impala, lub w innym węźle w klastrze. W przypadku awarii węzła z jakiegoś powodu, Impala StateStore aktualizuje wszystkie inne węzły o awarii. W takim przypadku inne demony Impala przestają przypisywać dalsze zapytania do uszkodzonego węzła.
Metadane Impala i MetaStore
W Impali wszystkie kluczowe informacje, w tym definicje tabel, informacje o tabelach i kolumnach itp., są przechowywane w scentralizowanej bazie danych zwanej MetaStore. W przypadku dużych ilości danych zawierających wiele partycji uzyskanie metadanych specyficznych dla tabeli staje się trudne. I tu z pomocą przychodzi Impala. Ponieważ poszczególne węzły Impala buforują lokalnie wszystkie metadane, łatwo jest natychmiast uzyskać określone informacje.
Za każdym razem, gdy aktualizujesz definicję tabeli/dane tabeli, wszystkie demony Impala muszą również aktualizować swoją pamięć podręczną metadanych, pobierając najnowsze metadane, zanim będą mogły wysłać nowe zapytanie do określonej tabeli.
Impala – Instalacja Impala
Tak jak musisz zainstalować Hadoop i jego ekosystem w systemie operacyjnym Linux, możesz zrobić to samo z Impala. Ponieważ to Cloudera jako pierwsza wypuściła Impalę, możesz łatwo uzyskać do niej dostęp za pośrednictwem maszyny wirtualnej Cloudera QuickStart.
Przeczytaj: samouczek Hadoop
Jak pobrać maszynę wirtualną Cloudera QuickStart?
Aby pobrać maszynę wirtualną Cloudera QuickStart, należy wykonać czynności opisane poniżej.
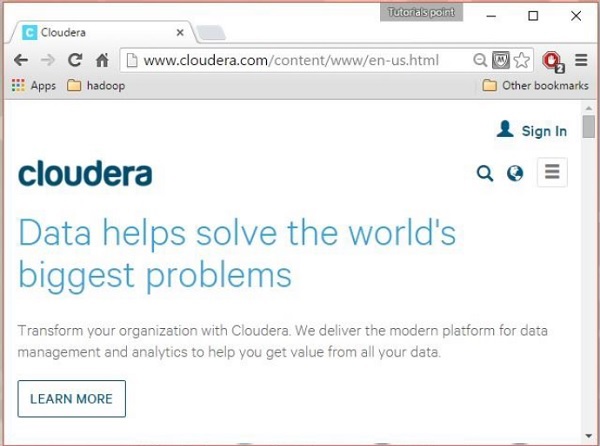
Krok 1
Otwórz stronę główną Cloudera ( http://www.cloudera.com/ ), a znajdziesz coś takiego:
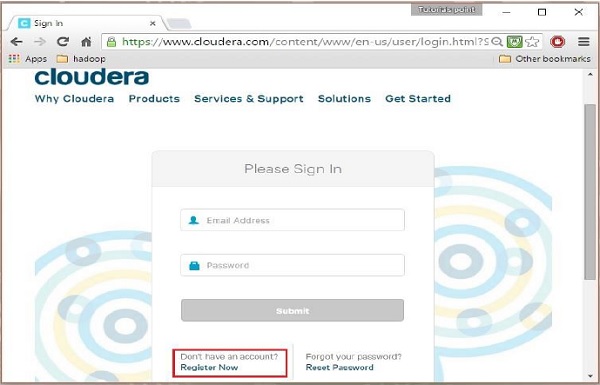
Krok 2
Aby zarejestrować się w Cloudera należy kliknąć opcję „Zarejestruj się teraz”, która otworzy stronę rejestracji konta. Jeśli jesteś już zarejestrowany w Cloudera, możesz kliknąć opcję „Zaloguj się” na stronie, co spowoduje dalsze przekierowanie do strony logowania w następujący sposób:
Krok 3
Po zalogowaniu otwórz stronę pobierania witryny, klikając opcję „Pobieranie” w lewym górnym rogu strony, jak pokazano poniżej:
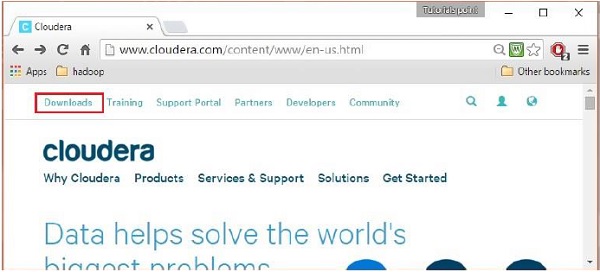
Krok 4
W tym kroku musisz pobrać Cloudera QuickStartVM, klikając opcję „Pobierz teraz” w następujący sposób:
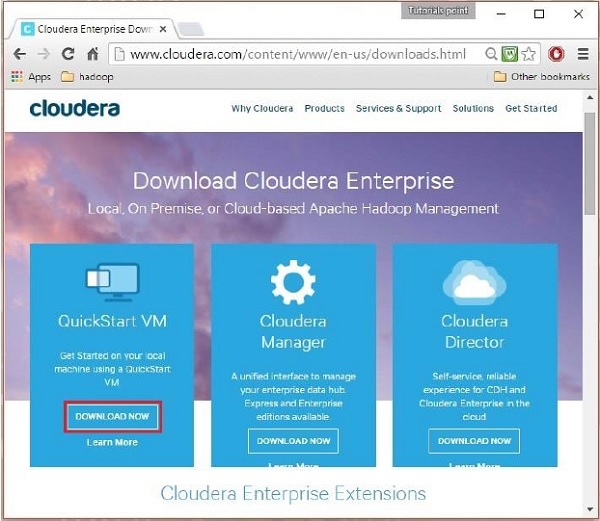
Kliknięcie opcji Pobierz teraz spowoduje przekierowanie do strony pobierania QuickStart VM:
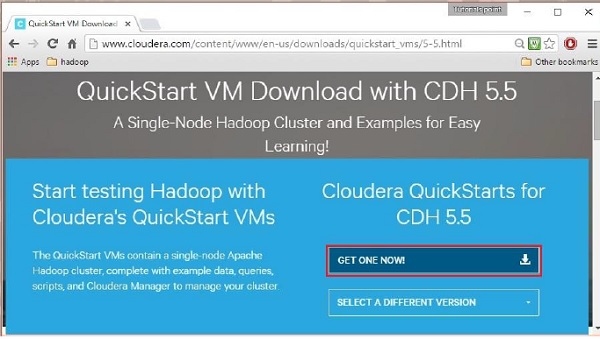
Następnie musisz wybrać opcję GET ONE NOW, zaakceptować umowę licencyjną i przesłać ją, jak pokazano poniżej:
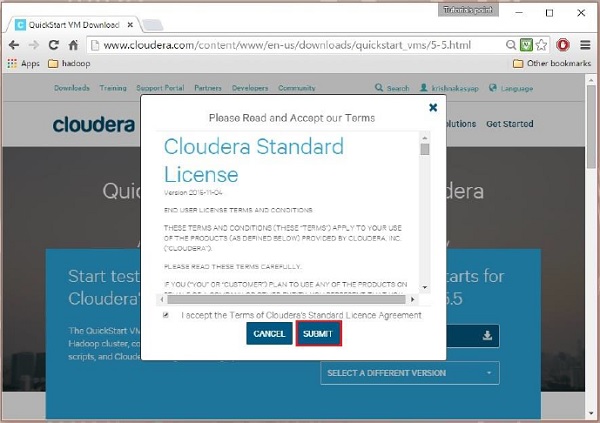
Po zakończeniu pobierania znajdziesz trzy różne opcje kompatybilności z Cloudera VM – VMware, KVM i VIRTUALBOX. Możesz wybrać preferowaną opcję.

Źródło
Impala – interfejsy przetwarzania zapytań
Impala oferuje trzy interfejsy do przetwarzania zapytań:
Impala-shell – Po zainstalowaniu i skonfigurowaniu Impala przy użyciu maszyny wirtualnej Cloudera możesz aktywować powłokę Impala, wpisując polecenie „impala-shell” w edytorze.
Przeczytaj: Różnica między Big Data a Hadoop
Interfejs Hue – Przeglądarka Hue umożliwia przetwarzanie zapytań Impala. Posiada edytor zapytań Impala, w którym można wpisywać i wykonywać różne zapytania Impala. Aby jednak skorzystać z edytora, musisz najpierw zalogować się do przeglądarki Hue.
Sterowniki ODBC/JDBC – Jak każda baza danych, Impala oferuje również sterowniki ODBC/JDBC. Sterowniki te umożliwiają łączenie się z Impala za pomocą języków programowania, które je obsługują (sterowniki ODBC/JDBC) i budowanie aplikacji przetwarzających zapytania w Impali przy użyciu tych samych języków programowania.
Procedura wykonywania zapytania
Za każdym razem, gdy przekazujesz zapytanie za pomocą dowolnego interfejsu Impala, Impalad w klastrze zwykle akceptuje Twoje zapytanie. Impalad staje się wtedy węzłem koordynującym dla tego konkretnego zapytania. Po otrzymaniu zapytania koordynator sprawdza, czy zapytanie jest odpowiednie, używając schematu tabeli z Hive Metastore.
Następnie zbiera informacje o lokalizacji danych potrzebnych do wykonania zapytania z węzła nazwy HDFS i przekazuje te informacje do innych Impaladów w hierarchii, aby ułatwić wykonanie zapytania. Gdy Impalady odczytają określony blok danych, przetwarzają zapytanie. Po przetworzeniu zapytania przez wszystkie Impalady w klastrze węzeł koordynujący zbiera wynik i dostarcza go użytkownikowi.
Polecenia powłoki Impala
Jeśli znasz Hive Shell, możesz łatwo rozgryźć Impala Shell, ponieważ oba mają dość podobną strukturę – pozwalają tworzyć bazy danych i tabele, wstawiać dane i wydawać zapytania. Polecenia Impala Shell dzielą się na trzy szerokie kategorie: polecenia ogólne, opcje specyficzne dla zapytania oraz opcje specyficzne dla tabeli i bazy danych.
Polecenia ogólne
- Wsparcie
Polecenie help oferuje listę przydatnych poleceń dostępnych w Impali.
[szybki start.cloudera:21000] > pomoc;
Udokumentowane polecenia (wpisz help <temat>):
=========================================================== ======
obliczyć opisz wstawić zestaw nieustawiony z wersją
połącz wyjaśnij zakończ pokaż wartości użyj
wyjdź z profilu historii wybierz wskazówkę powłoki
Nieudokumentowane polecenia:
=================================================
zmień utwórz opis upuść pomoc podsumowanie wczytywania
- Wersja
To polecenie udostępnia aktualną wersję Impali.
[szybki start.cloudera:21000] > wersja;
Wersja powłoki: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) zbudowana w poniedziałek 9 listopada
12:18:12 PST 2015
Wersja serwera: wersja impalad 2.3.0-cdh5.5.0 RELEASE (kompilacja
0c891d79aa38f297d244855a32f1e17280e2129b)
- historia
To polecenie wyświetla ostatnie dziesięć poleceń wykonanych w Impala Shell.
[szybki start.cloudera:21000] > historia;
[1]:wersja;
[2]:pomoc;
[3]:pokaż bazy danych;
[4]:użyj my_db;
[5]:historia;
- połączyć
To polecenie pomaga połączyć się z daną instancją Impali. Jeśli nie określisz żadnej instancji, domyślnie połączy się ona z domyślnym portem 21000.
[szybki start.cloudera:21000] > połącz;
Połączono z quickstart.cloudera:21000
Wersja serwera: wersja impalad 2.3.0-cdh5.5.0 RELEASE (kompilacja
0c891d79aa38f297d244855a32f1e17280e2129b)
- wyjdź/zakończ
Jak sama nazwa wskazuje, polecenie exit/quit pozwala wyjść z powłoki Impala.
[szybki start.cloudera:21000] > wyjdź;
Żegnaj chmuro
Opcje specyficzne dla zapytania
- wyjaśnić
To polecenie zwraca plan wykonania dla konkretnego zapytania.
[quickstart.cloudera:21000] > wyjaśnij wybierz * z próbki;
Zapytanie: wyjaśnij wybierz * z próbki
+————————————————————————————+
| Wyjaśnij ciąg
|
+————————————————————————————+
| Szacowane wymagania na hosta: Pamięć = 48,00 MB rdzeni wirtualnych = 1
|
| OSTRZEŻENIE: W poniższych tabelach brakuje odpowiednich statystyk tabel i/lub kolumn. |
| my_db.klienci |
| 01:WYMIANA [BEZ PARTYCJI]
|
| 00:SKANUJ HDFS [moja_baza.klienci] |
| partycje = 1/1 pliki = 6 rozmiar = 148B |
+————————————————————————————+
Pobrano 7 wierszy w 0,17 s
- profil
To polecenie wyświetla informacje niskiego poziomu dotyczące ostatniego/najnowszego zapytania. Służy do diagnozowania i dostrajania wydajności zapytania.
[ szybki start . cloudera : 21000 ] > profil ;
Profil środowiska wykonawczego zapytania :
Zapytanie ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Podsumowanie :
Identyfikator sesji : e74927207cd752b5 : 65ca61e630ad3ad
Typ sesji : WOSK PSZCZELI
Czas rozpoczęcia : 2016 – 04 – 17 23 : 49 : 26.08148000 Czas zakończenia : 2016 – 04 – 17 23 : 49 : 26.2404000
Typ zapytania : WYJAŚNIJ
Stan zapytania : ZAKOŃCZONY
Stan zapytania : OK
Wersja Impala : wersja impala 2.3 . 0 – cdh5 . 5.0 WYDANIE ( kompilacja 0c891d77280e2129b )
Użytkownik : cloudera
Połączony użytkownik : cloudera
Użytkownik delegowany :
Adres sieciowy : 10.0 . 2,15 : 43870
Domyślna baza danych : my_db
Sql Statement : wyjaśnij wybierz * z próbki
Koordynator : szybki start . chmurka : 22000
: 0ns
Oś czasu zapytań : 167,304 ms
– Rozpoczęcie wykonywania : 41,292us ( 41,292us ) – Planowanie zakończone : 56,42ms ( 56,386ms )
– Dostępne rzędy : 58,247ms ( 1,819ms )
– Pobrano pierwszy wiersz : 160,72 ms ( 101.824 ms )
– Wyrejestruj zapytanie : 166,325 ms ( 6,253 ms )
ImpalaSerwer :
– ClientFetchWaitTimer : 107,969 ms
– RowMaterializationTimer : 0ns
Opcje specyficzne dla tabeli i bazy danych
- zmieniać
Polecenie alter pomaga zmienić strukturę i nazwę tabeli.
- opisać
Polecenie opisu udostępnia metadane tabeli. Zawiera informacje, takie jak kolumny i ich typy danych.
- upuść
Polecenie drop pomaga usunąć konstrukcję, która może być tabelą, widokiem lub funkcją bazy danych.
- wstawić
Polecenie wstaw pomaga dołączyć dane (kolumny) do tabeli i nadpisać dane z istniejącej tabeli
- Wybierz
Polecenia select można użyć do wykonania określonej operacji na określonym zbiorze danych. Zwykle wymienia zbiór danych, na którym akcja ma zostać zakończona.
- pokazać
Polecenie show wyświetla metastore różnych konstrukcji, takich jak tabele i bazy danych.
- stosowanie
Polecenie use pomaga zmienić aktualny kontekst konkretnej bazy danych.
Impala – Komentarze
W Impali komentarze są podobne do tych w języku SQL. Zazwyczaj istnieją dwa rodzaje komentarzy:
Komentarze jednowierszowe
Każda linia, po której następuje „—” staje się komentarzem w Impali.
— Witam, witamy w uaktualnieniu.
Komentarze wielowierszowe
Wszystkie wiersze zawarte między /* i */ są wielowierszowymi komentarzami w Impali.
/*
Cześć, to jest przykład

Wielowierszowych komentarzy w Impala
*/
Wniosek
Mamy nadzieję, że ten szczegółowy samouczek Impala pomógł ci zrozumieć jego zawiłości i sposób działania.
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.
Ucz się kursów rozwoju oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.