Tutorial definitivo de Impala Hadoop que necesitará [2022]
Publicado: 2020-05-14Impala es una base de datos analítica nativa de código abierto diseñada para plataformas en clúster como Apache Hadoop. Es un motor de consulta interactivo similar a SQL que se ejecuta sobre el sistema de archivos distribuidos de Hadoop (HDFS) para facilitar el procesamiento de volúmenes masivos de datos a una velocidad ultrarrápida. Además, impala es una de las mejores herramientas de Hadoop para usar big data. Hoy vamos a hablar sobre todo lo relacionado con Impala y, por lo tanto, ¡hemos diseñado este tutorial de Impala para ti!
Este tutorial de Impala Hadoop está especialmente diseñado para aquellos que desean aprender Impala. Sin embargo, para obtener los máximos beneficios de este tutorial de Impala, sería útil tener un conocimiento profundo de los fundamentos de SQL junto con los comandos de Hadoop y HDFS.
Tabla de contenido
¿Qué es Impala?
Impala es un motor de consultas SQL MPP (Massive Parallel Processing) escrito en C++ y Java. Su objetivo principal es procesar grandes volúmenes de datos almacenados en clústeres de Hadoop. Impala promete alto rendimiento y baja latencia, y hasta la fecha es el motor SQL de mayor rendimiento (que ofrece una experiencia similar a RDBMS) para proporcionar la forma más rápida de acceder y procesar datos almacenados en HDFS.
Otro aspecto beneficioso de Impala es que se integra con el metastore de Hive para permitir compartir la información de la tabla entre ambos componentes. Aprovecha el Apache Hive existente para realizar trabajos de larga ejecución orientados a lotes en formato de consulta SQL. La integración Impala-Hive le permite usar cualquiera de los dos componentes: Hive o Impala para el procesamiento de datos o para crear tablas en un solo sistema de archivos compartidos (HDFS) sin alterar la definición de la tabla.
¿Por qué Impala?
Impala combina el rendimiento multiusuario de una base de datos analítica tradicional y la compatibilidad con SQL con la escalabilidad y flexibilidad de Apache Hadoop. Lo hace mediante el uso de componentes estándar de Hadoop como HDFS, HBase, YARN, Sentry y Metastore. Dado que Impala utiliza los mismos metadatos, interfaz de usuario (Hue Beeswax), sintaxis SQL (Hive SQL) y controlador ODBC (Open Database Connectivity) que Apache Hive, crea una plataforma unificada y familiar para consultas en tiempo real y orientadas a lotes.
Leer: Ideas de proyectos de Big Data para principiantes

Impala puede leer casi todos los formatos de archivo utilizados por Hadoop, incluidos Parquet, Avro y RCFile. Además, Impala no se basa en algoritmos MapReduce: implementa una arquitectura distribuida basada en procesos daemon que manejan y administran todo lo relacionado con la ejecución de consultas que se ejecutan en la misma máquina. Como resultado, ayuda a reducir la latencia de utilizar MapReduce. Esto es precisamente lo que hace que Impala sea mucho más rápido que Hive.
Impala – Características
Las principales características de Impala son:
- Está disponible como motor de consulta SQL de código abierto bajo la licencia de Apache.
- Le permite acceder a los datos mediante consultas de tipo SQL.
- Es compatible con el procesamiento de datos en memoria: accede y analiza los datos almacenados en los nodos de datos de Hadoop.
- Le permite almacenar datos en sistemas de almacenamiento como HDFS, Apache HBase y Amazon s3.
- Se integra fácilmente con herramientas de BI como Tableau, Pentaho y Microstrategy.
- Admite varios formatos de archivo, incluidos Sequence File, Avro, LZO, RCFile y Parquet.
Impala: ventajas clave
El uso de Impala ofrece algunas ventajas significativas a los usuarios, como:
- Dado que Impala admite el procesamiento de datos en memoria (el procesamiento ocurre donde residen los datos, en el clúster de Hadoop), no hay necesidad de transformación ni movimiento de datos.
- Para acceder a los datos almacenados en HDFS, HBase o Amazon s3 con Impala, no necesita ningún conocimiento previo de Java (trabajos de MapReduce); puede acceder fácilmente a ellos mediante consultas SQL básicas.
- En general, los datos deben pasar por un ciclo complicado de extracción, transformación y carga (ETL) mientras se escriben consultas en las herramientas comerciales. Sin embargo, con Impala, no hay necesidad de esto. Impala reemplaza las etapas de carga y reorganización que consumen mucho tiempo con técnicas avanzadas como el análisis exploratorio de datos y el descubrimiento de datos, lo que aumenta la velocidad del proceso.
- Impala es pionera en el uso del formato de archivo Parquet, que es un diseño de almacenamiento en columnas optimizado para consultas a gran escala que se encuentran en almacenes de datos.
Impala – Inconvenientes
Aunque Impala ofrece numerosos beneficios, también tiene ciertas limitaciones:
- No tiene soporte para serialización y deserialización.
- No puede leer archivos binarios personalizados; solo puede leer archivos de texto.
- Cada vez que se agreguen nuevos registros o archivos al directorio de datos en HDFS, deberá actualizar la tabla de datos.
Impala – Arquitectura
Impala está desacoplado de su motor de almacenamiento (al contrario de los sistemas de almacenamiento tradicionales). Incluye tres componentes principales: Impala Daemon (Impalad) , Impala StateStore e Impala Metadata & MetaStore.
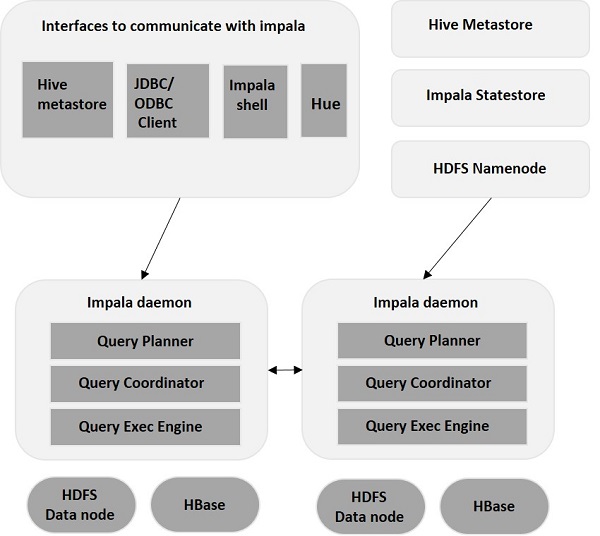
Demonio Impala
Impala Daemon, también conocido como Impalad, se ejecuta en nodos individuales donde está instalado Impala. Acepta consultas de múltiples interfaces (shell Impala, navegador Hue, etc.) y las procesa. Cada vez que se envía una consulta a un Impalad en un nodo en particular, el nodo se convierte en un "nodo coordinador" para esa consulta. De esta forma, Impalad atiende múltiples consultas ejecutándose en otros nodos.
Una vez que se aceptan las consultas, Impalad lee y escribe archivos de datos y paraleliza las consultas distribuyendo la tarea a los otros nodos de Impala en el clúster. Los usuarios pueden enviar consultas a un Impalad dedicado o de manera equilibrada a otro Impalad en el clúster, según sus requisitos. Luego, estas consultas comienzan a procesarse en las diferentes instancias de Impalad y devuelven el resultado al nodo de coordinación principal.
Impala StateStore
Impala StateStore monitorea y verifica la salud de cada Impalad y también transmite el informe de salud de cada Impala Daemon a los otros demonios. Puede ejecutarse en el mismo nodo donde se ejecuta el servidor Impala o en otro nodo del clúster. En caso de que haya una falla en un nodo por algún motivo, Impala StateStore actualiza todos los demás nodos sobre la falla. En tal caso, los otros demonios de Impala dejan de asignar más consultas al nodo fallido.
Impala Metadatos y MetaStore
En Impala, toda la información crucial, incluidas las definiciones de tablas, la información de tablas y columnas, etc., se almacena en una base de datos centralizada conocida como MetaStore. Cuando se trata de volúmenes sustanciales de datos que contienen varias particiones, se vuelve un desafío obtener metadatos específicos de la tabla. Aquí es donde Impala viene al rescate. Dado que los nodos individuales de Impala almacenan en caché todos los metadatos localmente, resulta fácil obtener información específica al instante.
Cada vez que actualice la definición de la tabla/los datos de la tabla, todos los Impala Daemons también deben actualizar su caché de metadatos recuperando los metadatos más recientes antes de que puedan emitir una nueva consulta en una tabla en particular.
Impala – Instalación de Impala
Al igual que necesita instalar Hadoop y su ecosistema en el sistema operativo Linux, puede hacer lo mismo con Impala. Dado que fue Cloudera el que envió Impala por primera vez, puede acceder fácilmente a él a través de Cloudera QuickStart VM.
Leer: Tutorial de Hadoop
Cómo descargar la máquina virtual Cloudera QuickStart
Para descargar Cloudera QuickStart VM, debe seguir los pasos que se describen a continuación.
Paso 1
Abra la página de inicio de Cloudera ( http://www.cloudera.com/ ), y encontrará algo como esto:
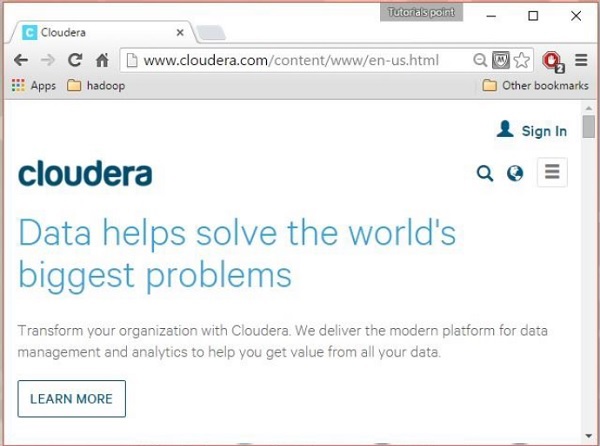
Paso 2
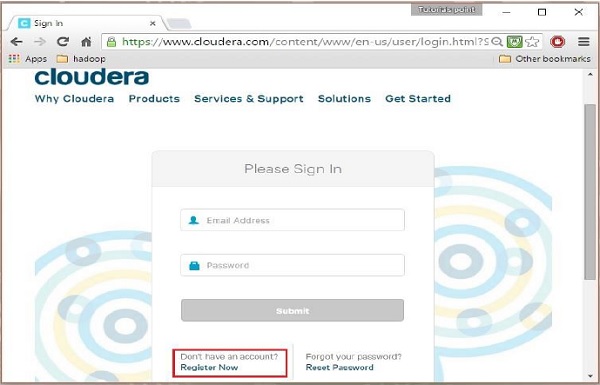
Para registrarse en Cloudera, debe hacer clic en la opción "Registrarse ahora", que abrirá la página de registro de la cuenta. Si ya está registrado en Cloudera, puede hacer clic en la opción "Iniciar sesión" en la página y lo redirigirá a la página de inicio de sesión de la siguiente manera:
Paso 3
Una vez que haya iniciado sesión, abra la página de descarga del sitio web haciendo clic en la opción "Descargas" en la esquina superior izquierda de la página, como se muestra a continuación:
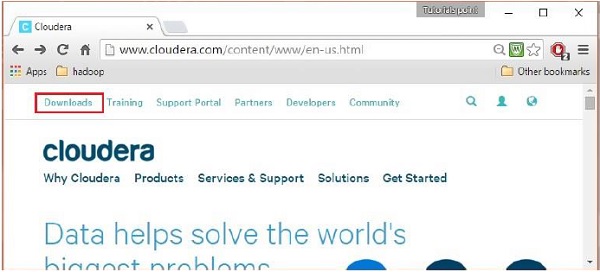
Etapa 4
En este paso, debe descargar Cloudera QuickStartVM haciendo clic en la opción "Descargar ahora" de la siguiente manera:
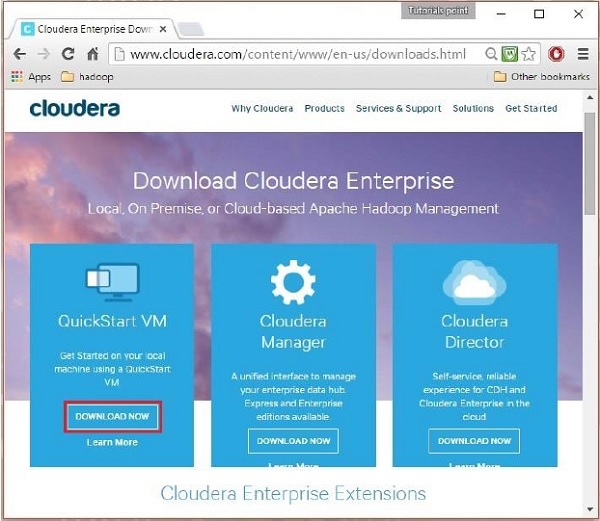
Al hacer clic en la opción Descargar ahora, se le redirigirá a la página de descarga de QuickStart VM:
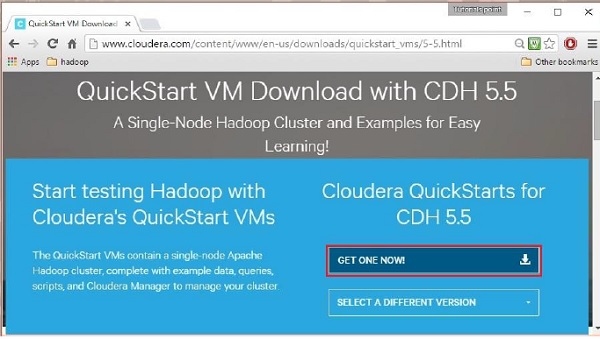
Luego, debe seleccionar la opción OBTENER UNO AHORA, aceptar el acuerdo de licencia y enviarlo como se muestra a continuación:
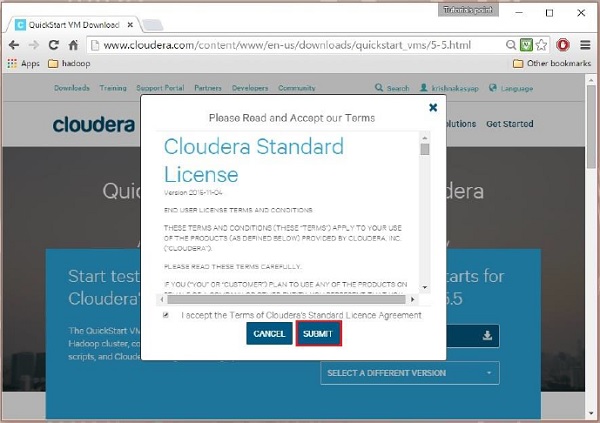
Una vez completada la descarga, encontrará tres opciones diferentes compatibles con Cloudera VM: VMware, KVM y VIRTUALBOX. Puedes elegir tu opción preferida.

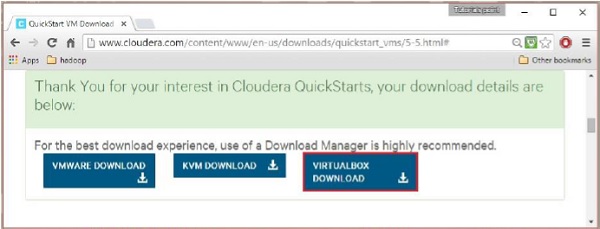
Fuente
Impala: interfaces de procesamiento de consultas
Impala ofrece tres interfaces para procesar consultas:
Impala-shell: una vez que haya instalado y configurado Impala con Cloudera VM, puede activar Impala-shell escribiendo el comando "impala-shell" en el editor.
Leer: Diferencia entre Big Data y Hadoop
Interfaz Hue: el navegador Hue le permite procesar consultas de Impala. Tiene un editor de consultas de Impala donde puede escribir y ejecutar diferentes consultas de Impala. Sin embargo, para usar el editor, primero deberá iniciar sesión en el navegador Hue.
Controladores ODBC/JDBC: como ocurre con todas las bases de datos, Impala también ofrece controladores ODBC/JDBC. Estos controladores le permiten conectarse a Impala a través de lenguajes de programación que los admiten (controladores ODBC/JDBC) y crear aplicaciones que procesan consultas en Impala utilizando los mismos lenguajes de programación.
Procedimiento de ejecución de consultas
Cada vez que pasa una consulta utilizando cualquier interfaz de Impala, un Impalad en el clúster generalmente acepta su consulta. Este Impalad se convierte entonces en el nodo coordinador de esa consulta en particular. Después de recibir la consulta, el coordinador verifica si la consulta es apropiada o no utilizando el esquema de tabla de Hive Metastore.
Después de esto, recopila información sobre la ubicación de los datos necesarios para la ejecución de la consulta desde el nodo de nombre HDFS y envía esta información a otros Impalads en la jerarquía para facilitar la ejecución de la consulta. Una vez que los Impalads leen el bloque de datos especificado, procesan la consulta. Cuando todos los Impalads del clúster hayan procesado la consulta, el nodo coordinador recopila el resultado y se lo entrega.
Comandos de la carcasa de Impala
Si está familiarizado con Hive Shell, puede descubrir fácilmente Impala Shell, ya que ambos comparten una estructura bastante similar: permiten crear bases de datos y tablas, insertar datos y emitir consultas. Los comandos de Impala Shell se dividen en tres amplias categorías: comandos generales, opciones específicas de consulta y opciones específicas de tablas y bases de datos.
Comandos Generales
- ayuda
El comando de ayuda ofrece una lista de comandos útiles disponibles en Impala.
[inicio rápido.cloudera:21000] > ayuda;
Comandos documentados (escriba ayuda <tema>):
================================================== ======
computar describir insertar establecer desarmar con versión
conectar explicar salir mostrar valores usar
salir historial perfil seleccionar shell tip
Comandos no documentados:
=========================================
modificar crear desc soltar ayuda cargar resumen
- Versión
Este comando le proporciona la versión actual de Impala.
[inicio rápido.cloudera:21000] > versión;
Versión de Shell: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) construido el lunes 9 de noviembre
12:18:12 PDT 2015
Versión del servidor: IMPALAD versión 2.3.0-cdh5.5.0 VERSIÓN (compilación
0c891d79aa38f297d244855a32f1e17280e2129b)
- historia
Este comando muestra los últimos diez comandos ejecutados en Impala Shell.
[quickstart.cloudera:21000] > historial;
[1]:versión;
[2]: ayuda;
[3]:mostrar bases de datos;
[4]: usa mi_base de datos;
[5]:historia;
- conectar
Este comando ayuda a conectarse a una instancia determinada de Impala. Si no especifica ninguna instancia, entonces, de manera predeterminada, se conectará al puerto predeterminado 21000.
[inicio rápido.cloudera:21000] > conectar;
Conectado a quickstart.cloudera:21000
Versión del servidor: IMPALAD versión 2.3.0-cdh5.5.0 VERSIÓN (compilación
0c891d79aa38f297d244855a32f1e17280e2129b)
- salir/salir
Como sugiere el nombre, el comando exit/quit le permite salir de Impala Shell.
[inicio rápido.cloudera:21000] > salir;
Adiós cloudera
Opciones específicas de consulta
- explicar
Este comando devuelve el plan de ejecución para una consulta en particular.
[quickstart.cloudera:21000] > explicar select * from sample;
Consulta: explique seleccionar * de la muestra
+—————————————————————————————+
| Explicar cadena
|
+—————————————————————————————+
| Requisitos estimados por host: Memoria = 48,00 MB VCores = 1
|
| ADVERTENCIA: A las siguientes tablas les faltan estadísticas relevantes de tabla y/o columna. |
| mis_db.clientes |
| 01: INTERCAMBIO [SIN PARTICIONES]
|
| 00:ESCANEAR HDFS [my_db.clientes] |
| particiones = 1/1 archivos = 6 tamaño = 148B |
+—————————————————————————————+
Obtuvo 7 filas en 0,17 s
- perfil
Este comando muestra la información de bajo nivel sobre la consulta reciente/más reciente. Se utiliza para el diagnóstico y el ajuste del rendimiento de una consulta.
[ inicio rápido . cloudera : 21000 ] > perfil ;
Consultar perfil de tiempo de ejecución :
Consulta ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Resumen :
ID de sesión : e74927207cd752b5 : 65ca61e630ad3ad
Tipo de sesión : CERA DE ABEJAS
Hora de inicio : 2016 – 04 – 17 23 : 49 : 26.08148000 Hora de finalización : 2016 – 04 – 17 23 : 49 : 26.2404000
Tipo de consulta : EXPLICAR
Estado de consulta : FINALIZADO
Estado de la consulta : OK
Versión Impala : impalad versión 2.3 . 0 - cdh5 . VERSIÓN 5.0 ( compilación 0c891d77280e2129b )
Usuario : cloudera
Usuario conectado : cloudera
Usuario Delegado :
Dirección de red : 10.0 . 2,15 : 43870
Base de datos predeterminada : my_db
Declaración Sql : explique seleccionar * de la muestra
Coordinador : inicio rápido . nube : 22000
: 0ns
Línea de tiempo de consulta : 167.304ms
– Inicio ejecución : 41.292us ( 41.292us ) – Planificación finalizada : 56.42ms ( 56.386ms )
– Filas disponibles : 58.247ms ( 1.819ms )
– Primera fila recuperada : 160,72 ms ( 101,824 ms )
– Anular consulta de registro : 166.325ms ( 6.253ms )
Servidor Impala :
– ClientFetchWaitTimer : 107.969ms
– Temporizador de materialización de filas : 0ns
Opciones específicas de tablas y bases de datos
- alterar
El comando alter ayuda a cambiar la estructura y el nombre de una tabla.
- describir
El comando describe proporciona los metadatos de una tabla. Contiene información como columnas y sus tipos de datos.
- soltar
El comando soltar ayuda a eliminar una construcción, que puede ser una tabla, una vista o una función de base de datos.
- insertar
El comando de inserción ayuda a agregar datos (columnas) en una tabla y anular los datos de una tabla existente
- Seleccione
El comando de selección se puede utilizar para realizar una operación específica en un conjunto de datos en particular. Por lo general, menciona el conjunto de datos en el que se va a completar la acción.
- show
El comando show muestra el metastore de varias construcciones como tablas y bases de datos.
- utilizar
El comando use ayuda a cambiar el contexto actual de una base de datos en particular.
Impala – Comentarios
En Impala, los comentarios son similares a los del lenguaje SQL. Por lo general, hay dos tipos de comentarios:
Comentarios de una sola línea
Cada línea seguida de “—” se convierte en un comentario en Impala.
— Hola, bienvenido a upGrad.
Comentarios de varias líneas
Todas las líneas contenidas entre /* y */ son comentarios de varias líneas en Impala.
/*
hola este es un ejemplo

De comentarios de varias líneas en Impala
*/
Conclusión
Esperamos que este tutorial detallado de Impala lo haya ayudado a comprender sus complejidades y cómo funciona.
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.
Aprenda cursos de desarrollo de software en línea de las mejores universidades del mundo. Obtenga Programas PG Ejecutivos, Programas de Certificado Avanzado o Programas de Maestría para acelerar su carrera.