당신에게 필요한 궁극적인 Impala Hadoop 튜토리얼 [2022]
게시 됨: 2020-05-14Impala는 Apache Hadoop과 같은 클러스터 플랫폼용으로 설계된 오픈 소스 기본 분석 데이터베이스입니다. HDFS(Hadoop Distributed File System) 위에서 실행되는 대화형 SQL과 유사한 쿼리 엔진으로 엄청난 양의 데이터를 번개처럼 빠른 속도로 처리할 수 있습니다. 또한 임팔라는 빅 데이터를 사용하는 최고의 Hadoop 도구 중 하나입니다. 오늘, 우리는 Impala에 대한 모든 것에 대해 이야기할 것이므로, 우리는 당신을 위해 이 Impala 튜토리얼을 디자인했습니다!
이 Impala Hadoop 튜토리얼은 Impala를 배우려는 사람들을 위해 특별히 제작되었습니다. 그러나 이 Impala 튜토리얼의 이점을 최대한 활용하려면 Hadoop 및 HDFS 명령과 함께 SQL의 기본 사항을 깊이 이해하는 것이 도움이 될 것입니다.
목차
임팔라란?
Impala는 C++ 및 Java로 작성된 MPP(대규모 병렬 처리) SQL 쿼리 엔진 입니다. 주요 목적은 Hadoop 클러스터에 저장된 방대한 양의 데이터를 처리하는 것입니다. Impala는 고성능과 짧은 대기 시간을 약속하며 HDFS에 저장된 데이터에 액세스하고 처리하는 가장 빠른 방법을 제공하는 최고 성능의 SQL 엔진(RDBMS와 유사한 경험 제공)을 제공합니다.
Impala의 또 다른 이점은 Hive 메타스토어와 통합되어 두 구성 요소 간에 테이블 정보를 공유할 수 있다는 것입니다. 기존 Apache Hive를 활용하여 SQL 쿼리 형식으로 배치 지향의 장기 실행 작업을 수행합니다. Impala-Hive 통합을 통해 데이터 처리를 위해 Hive 또는 Impala의 두 구성 요소 중 하나를 사용하거나 테이블 정의를 변경하지 않고 단일 공유 파일 시스템(HDFS)에서 테이블을 생성할 수 있습니다.
왜 임팔라인가?
Impala는 기존 분석 데이터베이스의 다중 사용자 성능과 SQL 지원을 Apache Hadoop의 확장성 및 유연성과 결합합니다. HDFS, HBase, YARN, Sentry 및 Metastore와 같은 표준 Hadoop 구성 요소를 사용하여 이를 수행합니다. Impala는 Apache Hive와 동일한 메타데이터, 사용자 인터페이스(Hue Beeswax), SQL 구문(Hive SQL) 및 ODBC(Open Database Connectivity) 드라이버를 사용하기 때문에 배치 지향 및 실시간 쿼리를 위한 친숙하고 통합된 플랫폼을 생성합니다.
읽기: 초보자를 위한 빅 데이터 프로젝트 아이디어

Impala는 Parquet, Avro 및 RCFile을 포함하여 Hadoop에서 사용하는 거의 모든 파일 형식을 읽을 수 있습니다. 또한 Impala는 MapReduce 알고리즘을 기반으로 하지 않습니다. 동일한 시스템에서 실행되는 쿼리 실행과 관련된 모든 것을 처리하고 관리하는 데몬 프로세스를 기반으로 하는 분산 아키텍처를 구현합니다. 결과적으로 MapReduce 활용의 대기 시간을 줄이는 데 도움이 됩니다. 이것이 바로 Impala를 Hive보다 훨씬 빠르게 만드는 이유입니다.
임팔라 – 기능
Impala의 주요 기능은 다음과 같습니다.
- Apache 라이선스에 따라 오픈 소스 SQL 쿼리 엔진으로 사용할 수 있습니다.
- SQL과 유사한 쿼리를 사용하여 데이터에 액세스할 수 있습니다.
- 인메모리 데이터 처리를 지원하며 Hadoop 데이터 노드에 저장된 데이터에 액세스하고 분석합니다.
- HDFS, Apache HBase 및 Amazon s3와 같은 스토리지 시스템에 데이터를 저장할 수 있습니다.
- Tableau, Pentaho 및 Micro 전략과 같은 BI 도구와 쉽게 통합됩니다.
- Sequence File, Avro, LZO, RCFile, Parquet 등 다양한 파일 형식을 지원합니다.
임팔라 – 주요 장점
Impala를 사용하면 다음과 같은 몇 가지 중요한 이점을 사용자에게 제공합니다.
- Impala는 인메모리 데이터 처리를 지원하기 때문에(데이터가 있는 곳에서 처리가 발생합니다 – Hadoop 클러스터), 데이터 변환 및 데이터 이동이 필요하지 않습니다.
- Impala를 사용하여 HDFS, HBase 또는 Amazon s3에 저장된 데이터에 액세스하려면 Java(MapReduce 작업)에 대한 사전 지식이 필요하지 않습니다. 기본 SQL 쿼리를 사용하여 쉽게 액세스할 수 있습니다.
- 일반적으로 데이터는 비즈니스 도구에서 쿼리를 작성하는 동안 복잡한 ETL(추출-변환-로드) 주기를 거쳐야 합니다. 그러나 Impala에서는 이것이 필요하지 않습니다. Impala는 로딩 및 재구성의 시간 소모적인 단계를 탐색적 데이터 분석 및 데이터 검색과 같은 고급 기술로 대체하여 프로세스 속도를 높입니다.
- Impala는 데이터 웨어하우스에서 발견되는 대규모 쿼리에 최적화된 열 저장 레이아웃인 Parquet 파일 형식 사용의 선구자입니다.
임팔라 – 단점
Impala는 많은 이점을 제공하지만 다음과 같은 몇 가지 제한 사항도 있습니다.
- 직렬화 및 역직렬화를 지원하지 않습니다.
- 사용자 정의 바이너리 파일을 읽을 수 없습니다. 텍스트 파일만 읽을 수 있습니다.
- HDFS의 데이터 디렉토리에 새 레코드나 파일이 추가될 때마다 데이터 테이블을 새로 고쳐야 합니다.
임팔라 – 건축
Impala는 기존 스토리지 시스템과 달리 스토리지 엔진에서 분리됩니다. 여기에는 Impala Daemon (Impalad) , Impala StateStore, Impala Metadata & MetaStore의 세 가지 주요 구성 요소가 포함됩니다.
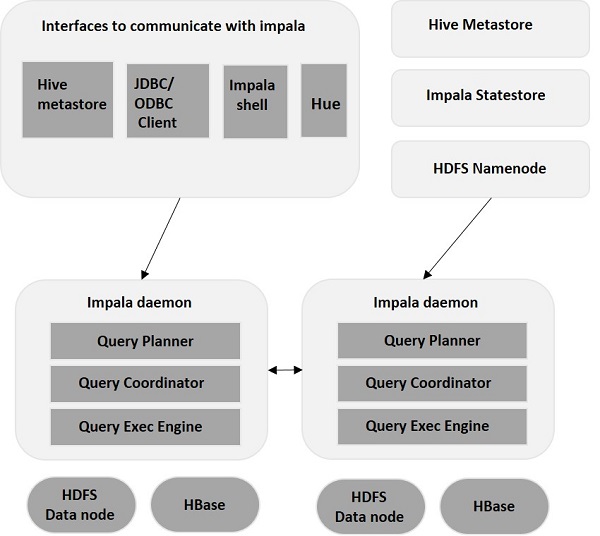
임팔라 데몬
Impala Daemon(일명 Impalad)은 Impala가 설치된 개별 노드에서 실행됩니다. 여러 인터페이스(Impala 셸, Hue 브라우저 등)에서 쿼리를 수락하고 처리합니다. 쿼리가 특정 노드의 Impalad에 제출될 때마다 노드는 해당 쿼리에 대한 "조정자 노드"가 됩니다. 이러한 방식으로 다른 노드에서 실행되는 Impalad가 여러 쿼리를 제공합니다.
쿼리가 수락되면 Impalad 는 데이터 파일을 읽고 쓰고 클러스터의 다른 Impala 노드에 작업을 분산하여 쿼리를 병렬화합니다. 사용자는 요구 사항에 따라 전용 Impalad 에 쿼리를 제출하거나 클러스터의 다른 Impalad 에 부하 분산 방식으로 쿼리를 제출할 수 있습니다. 그런 다음 이러한 쿼리는 다른 Impalad 인스턴스 에서 처리를 시작 하고 결과를 기본 조정 노드로 반환합니다.
임팔라 스테이트스토어
Impala StateStore는 각 Impala의 상태를 모니터링 및 확인하고 각 Impala 데몬 상태의 상태 보고서를 다른 데몬에 전달합니다. Impala 서버가 실행 중인 동일한 노드 또는 클러스터의 다른 노드에서 실행할 수 있습니다. 어떤 이유로 노드 오류가 발생한 경우 Impala StateStore는 오류에 대해 다른 모든 노드를 업데이트합니다. 이러한 이벤트에서 다른 Impala 데몬은 실패한 노드에 추가 쿼리 할당을 중지합니다.
임팔라 메타데이터 및 메타스토어
Impala에서는 테이블 정의, 테이블 및 열 정보 등을 포함한 모든 중요한 정보가 MetaStore로 알려진 중앙 집중식 데이터베이스에 저장됩니다. 여러 파티션을 포함하는 상당한 양의 데이터를 처리할 때 테이블별 메타데이터를 얻는 것이 어려워집니다. 여기에서 Impala가 구출됩니다. 개별 Impala 노드는 모든 메타데이터를 로컬로 캐시하므로 특정 정보를 즉시 쉽게 얻을 수 있습니다.
테이블 정의/테이블 데이터를 업데이트할 때마다 모든 Impala 데몬은 특정 테이블에 대해 새 쿼리를 실행하기 전에 최신 메타데이터를 검색하여 메타데이터 캐시도 업데이트해야 합니다.
임팔라 – 임팔라 설치
Linux OS에 Hadoop과 해당 에코시스템을 설치해야 하는 것처럼 Impala에서도 동일한 작업을 수행할 수 있습니다. Impala를 처음 출시한 것은 Cloudera였으므로 Cloudera QuickStart VM을 통해 쉽게 액세스할 수 있습니다.
읽기: Hadoop 자습서
Cloudera QuickStart VM을 다운로드하는 방법
Cloudera QuickStart VM을 다운로드하려면 아래에 설명된 단계를 따라야 합니다.
1 단계
Cloudera 홈페이지( http://www.cloudera.com/ )를 열면 다음과 같은 내용을 찾을 수 있습니다.
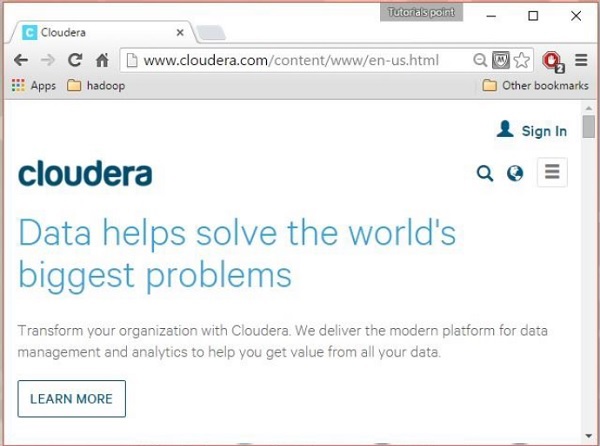
2 단계
Cloudera에 등록하려면 "지금 등록" 옵션을 클릭해야 계정 등록 페이지가 열립니다. Cloudera에 이미 등록되어 있는 경우 페이지에서 "로그인" 옵션을 클릭하면 다음과 같이 로그인 페이지로 리디렉션됩니다.
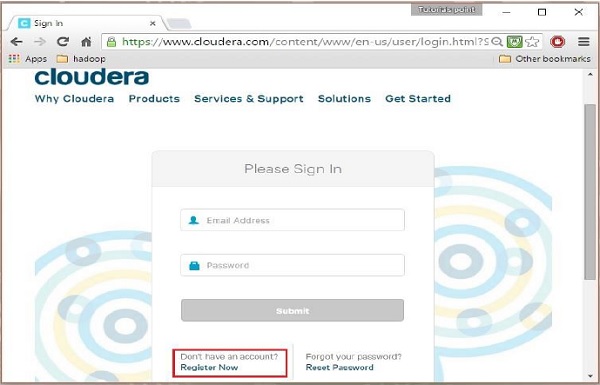
3단계
로그인한 후 아래와 같이 페이지의 왼쪽 상단 모서리에 있는 "다운로드" 옵션을 클릭하여 웹사이트의 다운로드 페이지를 엽니다.
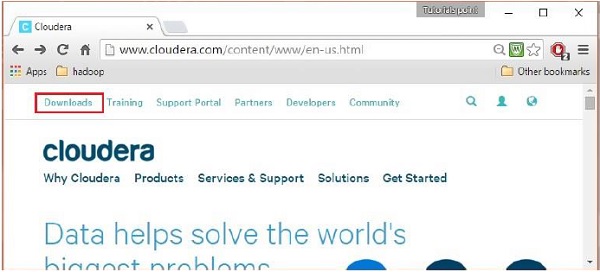
4단계
이 단계에서 다음과 같이 "지금 다운로드" 옵션을 클릭하여 Cloudera QuickStartVM을 다운로드해야 합니다.
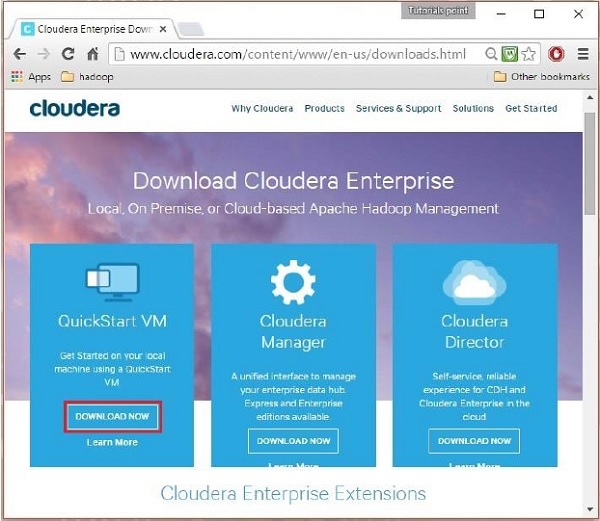
지금 다운로드 옵션을 클릭하면 QuickStart VM의 다운로드 페이지로 리디렉션됩니다.
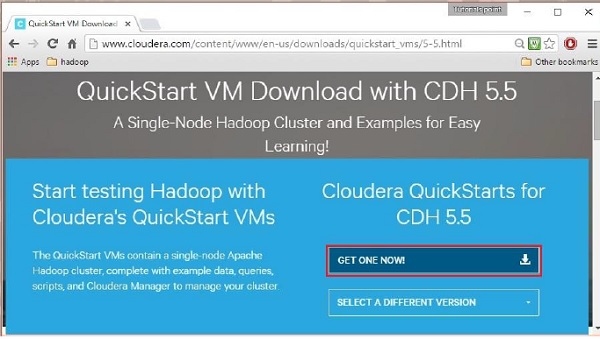
그런 다음 GET ONE NOW 옵션을 선택하고 라이선스 계약에 동의한 다음 아래와 같이 제출해야 합니다.
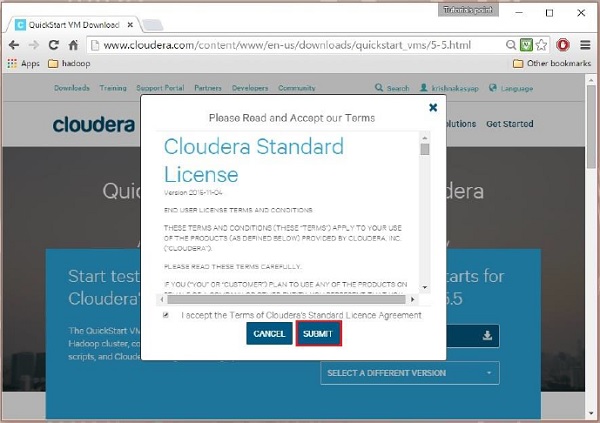
다운로드가 완료되면 VMware, KVM 및 VIRTUALBOX의 세 가지 Cloudera VM 호환 옵션을 찾을 수 있습니다. 원하는 옵션을 선택할 수 있습니다.
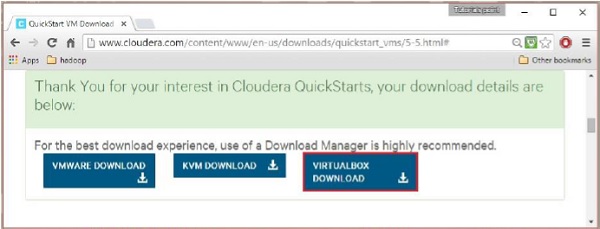
원천
Impala – 쿼리 처리 인터페이스
Impala는 쿼리 처리를 위한 세 가지 인터페이스를 제공합니다.
Impala-shell – Cloudera VM을 사용하여 Impala를 설치하고 설정했으면 편집기에서 "impala-shell" 명령을 입력하여 Impala-shell을 활성화할 수 있습니다.
읽기: 빅 데이터와 하둡의 차이점

Hue 인터페이스 – Hue 브라우저를 사용하면 Impala 쿼리를 처리할 수 있습니다. 다른 Impala 쿼리를 입력하고 실행할 수 있는 Impala 쿼리 편집기가 있습니다. 그러나 편집기를 사용하려면 먼저 Hue 브라우저에 로그인해야 합니다.
ODBC/JDBC 드라이버 – 모든 데이터베이스와 마찬가지로 Impala는 ODBC/JDBC 드라이버도 제공합니다. 이러한 드라이버를 사용하면 지원하는 프로그래밍 언어(ODBC/JDBC 드라이버)를 통해 Impala에 연결하고 동일한 프로그래밍 언어를 사용하여 Impala에서 쿼리를 처리하는 애플리케이션을 빌드할 수 있습니다.
쿼리 실행 절차
Impala 인터페이스를 사용하여 쿼리를 전달할 때마다 클러스터의 Impalad는 일반적으로 쿼리를 수락합니다. 그러면 이 Impalad가 해당 특정 쿼리에 대한 조정자 노드가 됩니다. 코디네이터는 쿼리를 수신한 후 Hive Metastore의 Table Schema를 이용하여 쿼리의 적합성 여부를 검증한다.
그런 다음 HDFS 이름 노드에서 쿼리 실행에 필요한 데이터의 위치에 대한 정보를 수집하고 이 정보를 계층 구조의 다른 Impalad에 전달하여 쿼리 실행을 용이하게 합니다. Impalad가 지정된 데이터 블록을 읽으면 쿼리를 처리합니다. 클러스터의 모든 Impalad가 쿼리를 처리하면 코디네이터 노드가 결과를 수집하여 사용자에게 전달합니다.
Impala 셸 명령
Hive Shell에 익숙하다면 Impala Shell이 매우 유사한 구조를 공유하기 때문에 쉽게 이해할 수 있습니다. 데이터베이스와 테이블을 만들고, 데이터를 삽입하고, 쿼리를 실행할 수 있습니다. Impala Shell 명령은 일반 명령, 쿼리별 옵션, 테이블 및 데이터베이스별 옵션의 세 가지 광범위한 범주로 나뉩니다.
일반 명령
- 돕다
help 명령은 Impala에서 사용할 수 있는 유용한 명령 목록을 제공합니다.
[quickstart.cloudera:21000] > 도움말;
문서화된 명령(help <topic> 입력):
==================================================== ======
버전으로 설정되지 않은 삽입 세트를 설명합니다.
연결 설명 종료 표시 값 사용
종료 기록 프로필 선택 셸 팁
문서화되지 않은 명령:
==========================================
변경 작성 설명 삭제 도움말 로드 요약
- 버전
이 명령은 현재 버전의 Impala를 제공합니다.
[quickstart.cloudera:21000] > 버전;
셸 버전: 11월 9일 월요일에 빌드된 Impala Shell v2.3.0-cdh5.5.0(0c891d7)
2015년 12:18:12 PST
서버 버전: impalad 버전 2.3.0-cdh5.5.0 RELEASE(빌드
0c891d79aa38f297d244855a32f1e17280e2129b)
- 역사
이 명령은 Impala Shell에서 실행된 마지막 10개의 명령을 표시합니다.
[quickstart.cloudera:21000] > 기록;
[1]:버전;
[2]:도움
[3]: 데이터베이스 표시;
[4]: my_db를 사용합니다.
[5]:역사;
- 연결하다
이 명령은 주어진 Impala 인스턴스에 연결하는 데 도움이 됩니다. 인스턴스를 지정하지 않으면 기본적으로 기본 포트 21000에 연결됩니다.
[quickstart.cloudera:21000] > 연결
quickstart.cloudera:21000에 연결됨
서버 버전: impalad 버전 2.3.0-cdh5.5.0 RELEASE(빌드
0c891d79aa38f297d244855a32f1e17280e2129b)
- 나가다/종료하다
이름에서 알 수 있듯이 exit/quit 명령을 사용하면 Impala Shell을 종료할 수 있습니다.
[quickstart.cloudera:21000] > 종료;
굿바이 클라우데라
쿼리별 옵션
- 설명
이 명령은 특정 쿼리에 대한 실행 계획을 반환합니다.
[quickstart.cloudera:21000] > 샘플에서 * 선택 설명;
쿼리: 샘플에서 선택 * 설명
+————————————————————————————+
| 문자열 설명
|
+————————————————————————————+
| 호스트별 예상 요구 사항: 메모리 = 48.00MB VCore = 1
|
| 경고: 다음 테이블에는 관련 테이블 및/또는 열 통계가 없습니다. |
| my_db.customers |
| 01:교환 [분할되지 않음]
|
| 00: HDFS 스캔 [my_db.customers] |
| 파티션 = 1/1 파일 = 6 크기 = 148B |
+————————————————————————————+
0.17초 동안 7개 행을 가져옴
- 프로필
이 명령은 최근/최신 쿼리에 대한 하위 수준 정보를 표시합니다. 쿼리의 진단 및 성능 튜닝에 사용됩니다.
[ 빠른 시작 . 클라우데라 : 21000 ] > 프로필 ;
쿼리 런타임 프로필 :
쿼리 ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
요약 :
세션 ID : e74927207cd752b5 : 65ca61e630ad3ad
세션 유형 : BEESWAX
시작 시간 : 2016 – 04 – 17 23 : 49 : 26.08148000 종료 시간 : 2016 – 04 – 17 23 : 49 : 26.2404000
쿼리 유형 : EXPLAIN
쿼리 상태 : FINISHED
쿼리 상태 : 확인
임팔라 버전 : 임팔라 버전 2.3 . 0 – cdh5 . 5.0 릴리스 ( 빌드 0c891d77280e2129b )
사용자 : 클라우데라
접속 사용자 : 클라우데라
위임된 사용자 :
네트워크 주소 : 10.0 . 2.15 : 43870
기본 DB : my_db
SQL 문 : 샘플 에서 선택 * 설명
코디네이터 : 빠른 시작 . 클라우데라 : 22000
: 0ns
쿼리 타임라인 : 167.304ms
– 실행 시작 : 41.292us ( 41.292us ) – 계획 완료 : 56.42ms ( 56.386ms )
– 사용 가능한 행 : 58.247ms ( 1.819ms )
– 첫 번째 행 페치 : 160.72ms ( 101.824ms )
– 쿼리 등록 해제 : 166.325ms ( 6.253ms )
임팔라 서버 :
– ClientFetchWaitTimer : 107.969ms
– RowMaterializationTimer : 0ns
테이블 및 데이터베이스 특정 옵션
- 바꾸다
alter 명령은 테이블의 구조와 이름을 변경하는 데 도움이 됩니다.
- 설명하다
describe 명령은 테이블의 메타데이터를 제공합니다. 여기에는 열 및 해당 데이터 유형과 같은 정보가 포함됩니다.
- 하락
drop 명령은 테이블, 뷰 또는 데이터베이스 함수가 될 수 있는 구성을 제거하는 데 도움이 됩니다.
- 끼워 넣다
insert 명령은 데이터(열)를 테이블에 추가하고 기존 테이블의 데이터를 재정의하는 데 도움이 됩니다.
- 고르다
select 명령을 사용하여 특정 데이터 세트에 대한 특정 작업을 수행할 수 있습니다. 일반적으로 작업이 완료될 데이터 세트를 언급합니다.
- 보여 주다
show 명령은 테이블 및 데이터베이스와 같은 다양한 구성의 메타스토어를 표시합니다.
- 사용
use 명령은 특정 데이터베이스의 현재 컨텍스트를 변경하는 데 도움이 됩니다.
임팔라 – 댓글
Impala에서 주석은 SQL 언어의 주석과 유사합니다. 일반적으로 두 가지 유형의 주석이 있습니다.
한 줄 주석
"-" 다음에 오는 각 행은 Impala에서 주석이 됩니다.
— 안녕하세요, upGrad에 오신 것을 환영합니다.
여러 줄 주석
/*와 */ 사이에 포함된 모든 줄은 Impala에서 여러 줄 주석입니다.
/*
안녕하세요 예시입니다

Impala의 여러 줄 주석
*/
결론
이 상세한 Impala 튜토리얼이 복잡함과 작동 방식을 이해하는 데 도움이 되었기를 바랍니다.
빅 데이터에 대해 더 알고 싶다면 PG 디플로마 빅 데이터 소프트웨어 개발 전문화 프로그램을 확인하십시오. 이 프로그램은 실무 전문가를 위해 설계되었으며 7개 이상의 사례 연구 및 프로젝트를 제공하고 14개 프로그래밍 언어 및 도구, 실용적인 실습을 다룹니다. 워크샵, 400시간 이상의 엄격한 학습 및 최고의 기업과의 취업 지원.
세계 최고의 대학에서 온라인으로 소프트웨어 개발 과정 을 배우십시오 . 이그 제 큐 티브 PG 프로그램, 고급 인증 프로그램 또는 석사 프로그램을 획득하여 경력을 빠르게 추적하십시오.