必要になる究極のImpalaHadoopチュートリアル[2022]
公開: 2020-05-14Impalaは、ApacheHadoopなどのクラスター化されたプラットフォーム向けに設計されたオープンソースのネイティブ分析データベースです。 これは、Hadoop分散ファイルシステム(HDFS)上で実行されるインタラクティブなSQLのようなクエリエンジンであり、大量のデータを超高速で処理しやすくします。 また、impalaはビッグデータを使用するためのトップHadoopツールの1つです。 今日は、Impalaのすべてについてお話しします。そのため、このImpalaチュートリアルを作成しました。
このImpalaHadoopチュートリアルは、Impalaを学びたい人を対象としています。 ただし、このImpalaチュートリアルの最大のメリットを享受するには、HadoopおよびHDFSコマンドとともにSQLの基本を深く理解していると役立ちます。
目次
インパラとは何ですか?
Impalaは、C ++およびJavaで記述されたMPP(Massive Parallel Processing)SQLクエリエンジンです。 その主な目的は、Hadoopクラスターに格納されている大量のデータを処理することです。 Impalaは、高性能と低遅延を約束します。これまでのところ、HDFSに格納されているデータにアクセスして処理するための最速の方法を提供するのは、最高のパフォーマンスを発揮するSQLエンジン(RDBMSのようなエクスペリエンスを提供)です。
Impalaのもう1つの有益な側面は、Hiveメタストアと統合して、両方のコンポーネント間でテーブル情報を共有できるようにすることです。 既存のApacheHiveを利用して、SQLクエリ形式でバッチ指向の長時間実行ジョブを実行します。 ImpalaとHiveの統合により、データ処理にHiveまたはImpalaの2つのコンポーネントのいずれかを使用したり、テーブル定義を変更せずに単一の共有ファイルシステム(HDFS)でテーブルを作成したりできます。
なぜインパラ?
Impalaは、従来の分析データベースとSQLサポートのマルチユーザーパフォーマンスを、ApacheHadoopのスケーラビリティと柔軟性と組み合わせています。 これは、HDFS、HBase、YARN、Sentry、Metastoreなどの標準のHadoopコンポーネントを使用して行われます。 Impalaは、Apache Hiveと同じメタデータ、ユーザーインターフェイス(Hue Beeswax)、SQL構文(Hive SQL)、およびODBC(Open Database Connectivity)ドライバーを使用するため、バッチ指向のリアルタイムクエリ用の統一された使い慣れたプラットフォームを作成します。
読む:初心者のためのビッグデータプロジェクトのアイデア

Impalaは、Parquet、Avro、RCFileなど、Hadoopで使用されるほぼすべてのファイル形式を読み取ることができます。 また、ImpalaはMapReduceアルゴリズムに基づいて構築されていません。同じマシンで実行されているクエリ実行に関連するすべてを処理および管理する、デーモンプロセスに基づく分散アーキテクチャを実装しています。 その結果、MapReduceを利用する際のレイテンシーを減らすのに役立ちます。 これこそが、ImpalaをHiveよりもはるかに高速にする理由です。
インパラ–機能
Impalaの主な機能は次のとおりです。
- Apacheライセンスの下でオープンソースのSQLクエリエンジンとして利用できます。
- SQLのようなクエリを使用してデータにアクセスできます。
- インメモリデータ処理をサポートします–Hadoopデータノードに保存されているデータにアクセスして分析します。
- これにより、HDFS、Apache HBase、Amazons3などのストレージシステムにデータを保存できます。
- Tableau、Pentaho、Micro戦略などのBIツールと簡単に統合できます。
- シーケンスファイル、Avro、LZO、RCFile、Parquetなどのさまざまなファイル形式をサポートしています。
インパラ–主な利点
Impalaを使用すると、次のようないくつかの重要な利点がユーザーに提供されます。
- Impalaはメモリ内データ処理(データが存在する場所で処理が行われる– Hadoopクラスター上)をサポートしているため、データ変換やデータ移動の必要はありません。
- HDFS、HBase、またはImpalaを使用してAmazon s3に保存されているデータにアクセスするには、Java(MapReduceジョブ)の予備知識は必要ありません。基本的なSQLクエリを使用して簡単にアクセスできます。
- 一般に、ビジネスツールでクエリを記述している間、データは複雑な抽出-変換-読み込み(ETL)サイクルを経る必要があります。 ただし、Impalaでは、これは必要ありません。 Impalaは、読み込みと再編成の時間のかかる段階を探索的データ分析やデータ検出などの高度な手法に置き換え、それによってプロセスの速度を向上させます。
- Impalaは、データウェアハウスで見られる大規模なクエリ用に最適化された列型ストレージレイアウトであるParquetファイル形式を使用するパイオニアです。
インパラ–欠点
Impalaには多くの利点がありますが、次のような制限もあります。
- シリアル化と逆シリアル化はサポートされていません。
- カスタムバイナリファイルを読み取ることはできません。 テキストファイルのみを読み取ることができます。
- 新しいレコードまたはファイルがHDFSのデータディレクトリに追加されるたびに、データテーブルを更新する必要があります。
Impala –アーキテクチャ
Impalaは、ストレージエンジンから切り離されています(従来のストレージシステムとは異なります)。 これには、Impala Daemon (Impalad) 、Impala StateStore、およびImpala Metadata&MetaStoreの3つの主成分が含まれています。
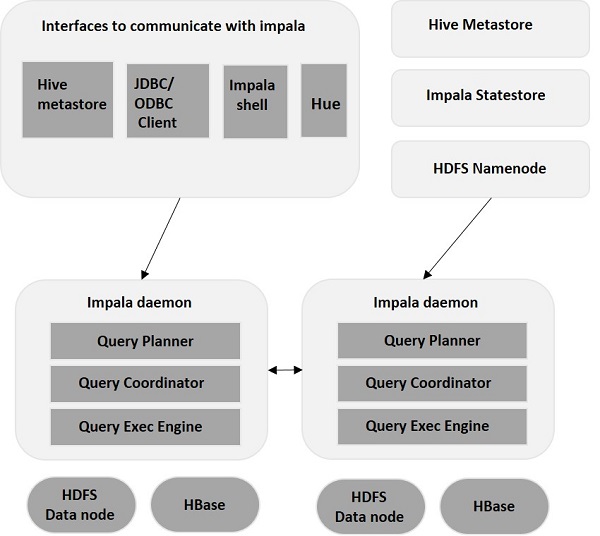
インパラデーモン
Impalaデーモン、別名Impaladは、Impalaがインストールされている個々のノードで実行されます。 複数のインターフェース(Impalaシェル、Hueブラウザーなど)からのクエリを受け入れ、それらを処理します。 クエリが特定のノードのImpaladに送信されるたびに、そのノードはそのクエリの「コーディネーターノード」になります。 このように、複数のクエリは、他のノードで実行されているImpaladによって処理されます。
クエリが受け入れられると、 Impaladはデータファイルの読み取りと書き込みを行い、クラスター内の他のImpalaノードにタスクを分散することでクエリを並列化します。 ユーザーは、要件に基づいて、専用のImpaladにクエリを送信するか、クラスター内の他のImpaladに負荷分散してクエリを送信できます。 次に、これらのクエリはさまざまなImpaladインスタンスで処理を開始し、結果をプライマリ調整ノードに返します。
インパラStateStore
Impala StateStoreは、各Impaladのヘルスを監視およびチェックし、各Impalaデーモンのヘルスのヘルスレポートを他のデーモンに中継します。 Impalaサーバーが実行されているのと同じノードで実行することも、クラスター内の別のノードで実行することもできます。 何らかの理由でノードに障害が発生した場合、ImpalaStateStoreは障害について他のすべてのノードを更新します。 このような場合、他のImpalaデーモンは、障害が発生したノードへのそれ以上のクエリの割り当てを停止します。
ImpalaメタデータとMetaStore
Impalaでは、テーブル定義、テーブルと列の情報などを含むすべての重要な情報が、MetaStoreと呼ばれる一元化されたデータベース内に保存されます。 複数のパーティションを含む大量のデータを処理する場合、テーブル固有のメタデータを取得することが困難になります。 ここでImpalaが救いの手を差し伸べます。 個々のImpalaノードはすべてのメタデータをローカルにキャッシュするため、特定の情報を即座に取得することが容易になります。
テーブル定義/テーブルデータを更新するたびに、すべてのImpalaデーモンは、特定のテーブルに対して新しいクエリを発行する前に、最新のメタデータを取得してメタデータキャッシュも更新する必要があります。
Impala –Impalaのインストール
Linux OSにHadoopとそのエコシステムをインストールする必要があるのと同じように、Impalaでも同じことができます。 Impalaを最初に出荷したのはClouderaであったため、ClouderaQuickStartVMを介して簡単にアクセスできます。
読む: Hadoopチュートリアル
ClouderaQuickStartVMをダウンロードする方法
Cloudera QuickStart VMをダウンロードするには、以下に概説する手順に従う必要があります。
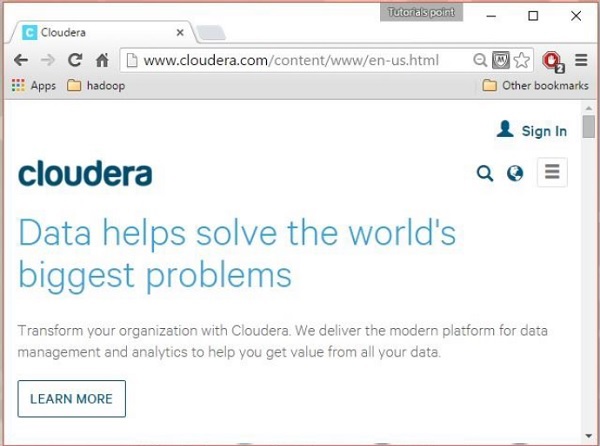
ステップ1
Clouderaのホームページ( http://www.cloudera.com/ )を開くと、次のようなものが見つかります。
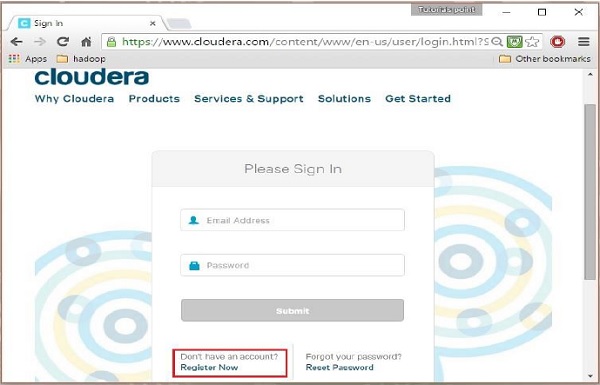
ステップ2
Clouderaに登録するには、[今すぐ登録]オプションをクリックする必要があります。これにより、[アカウント登録]ページが開きます。 すでにClouderaに登録している場合は、ページの[サインイン]オプションをクリックすると、次のようにサインインページにさらにリダイレクトされます。
ステップ3
サインインしたら、以下に示すように、ページの左上隅にある[ダウンロード]オプションをクリックして、Webサイトのダウンロードページを開きます。
ステップ4
このステップでは、次のように[今すぐダウンロード]オプションをクリックしてClouderaQuickStartVMをダウンロードする必要があります。
[今すぐダウンロード]オプションをクリックすると、QuickStartVMのダウンロードページにリダイレクトされます。
次に、[今すぐ入手]オプションを選択し、使用許諾契約に同意して、以下に示すように送信する必要があります。
ダウンロードが完了すると、VMware、KVM、VIRTUALBOXの3つの異なるClouderaVM互換オプションが見つかります。 お好みのオプションを選択できます。
ソース
Impala –クエリ処理インターフェイス
Impalaは、クエリを処理するための3つのインターフェイスを提供します。
Impala-shell – Cloudera VMを使用してImpalaをインストールおよびセットアップしたら、エディターでコマンド「impala-shell」を入力してImpala-shellをアクティブ化できます。
読む:ビッグデータとHadoopの違い
Hueインターフェース– Hueブラウザーを使用すると、Impalaクエリを処理できます。 さまざまなImpalaクエリを入力して実行できるImpalaクエリエディタがあります。 ただし、エディターを使用するには、まず、Hueブラウザーにログインする必要があります。

ODBC / JDBCドライバー–すべてのデータベースに当てはまるように、ImpalaはODBC/JDBCドライバーも提供しています。 これらのドライバーを使用すると、それらをサポートするプログラミング言語(ODBC / JDBCドライバー)を介してImpalaに接続し、同じプログラミング言語を使用してImpalaでクエリを処理するアプリケーションを構築できます。
クエリ実行手順
Impalaインターフェースを使用してクエリを渡すときは常に、クラスター内のImpaladが通常クエリを受け入れます。 このImpaladは、その特定のクエリのコーディネーターノードになります。 クエリを受信した後、コーディネーターは、Hive Metastoreのテーブルスキーマを使用して、クエリが適切かどうかを確認します。
この後、HDFSネームノードからクエリの実行に必要なデータの場所に関する情報を収集し、この情報を階層内の他のImpaladに転送して、クエリの実行を容易にします。 Impaladsが指定されたデータブロックを読み取ると、クエリを処理します。 クラスタ内のすべてのImpaladsがクエリを処理すると、コーディネータノードが結果を収集して配信します。
Impalaシェルコマンド
Hive Shellに精通している場合は、どちらも非常によく似た構造を共有しているため、Impala Shellを簡単に理解できます。データベースとテーブルの作成、データの挿入、クエリの発行が可能です。 Impala Shellコマンドは、一般的なコマンド、クエリ固有のオプション、およびテーブルとデータベース固有のオプションの3つの大きなカテゴリに分類されます。
一般的なコマンド
- ヘルプ
ヘルプコマンドは、Impalaで使用できる便利なコマンドのリストを提供します。
[quickstart.cloudera:21000]>ヘルプ;
文書化されたコマンド(help <topic>と入力):
================================================== ======
計算記述挿入セットがバージョンで設定されていない
接続説明終了表示値の使用
終了履歴プロファイルシェルチップを選択
文書化されていないコマンド:
=========================================
変更作成descドロップヘルプロードの概要
- バージョン
このコマンドは、Impalaの現在のバージョンを提供します。
[quickstart.cloudera:21000]>バージョン;
シェルバージョン:11月9日月曜日に構築されたImpala Shell v2.3.0-cdh5.5.0(0c891d7)
12:18:12 PST 2015
サーバーバージョン:impaladバージョン2.3.0-cdh5.5.0 RELEASE(ビルド
0c891d79aa38f297d244855a32f1e17280e2129b)
- 歴史
このコマンドは、ImpalaShellで実行された最後の10個のコマンドを表示します。
[quickstart.cloudera:21000]>履歴;
[1]:バージョン;
[2]:ヘルプ;
[3]:データベースを表示します。
[4]:my_dbを使用します;
[5]:履歴;
- 接続
このコマンドは、Impalaの特定のインスタンスに接続するのに役立ちます。 インスタンスを指定しない場合、デフォルトでは、デフォルトのポート21000に接続します。
[quickstart.cloudera:21000]>接続;
quickstart.cloudera:21000に接続しました
サーバーバージョン:impaladバージョン2.3.0-cdh5.5.0 RELEASE(ビルド
0c891d79aa38f297d244855a32f1e17280e2129b)
- 終了/終了
名前が示すように、exit/quitコマンドを使用するとImpalaシェルを終了できます。
[quickstart.cloudera:21000]>終了;
さようならcloudera
クエリ固有のオプション
- 説明
このコマンドは、特定のクエリの実行プランを返します。
[quickstart.cloudera:21000]> Explain select * from sample;
クエリ:サンプルからselect*を説明する
+ ———————————————————————————— +
| 説明文字列
|
+ ———————————————————————————— +
| ホストごとの推定要件:メモリ= 48.00MB VCores = 1
|
| 警告:次のテーブルには、関連するテーブルや列の統計がありません。 |
| my_db.customers |
| 01:交換[パーティションなし]
|
| 00:SCAN HDFS [my_db.customers] |
| パーティション=1/1ファイル=6サイズ=148B|
+ ———————————————————————————— +
0.17秒で7行をフェッチ
- プロフィール
このコマンドは、最近/最新のクエリに関する低レベルの情報を表示します。 クエリの診断とパフォーマンスの調整に使用されます。
[クイックスタート。 cloudera : 21000 ] >プロファイル;
ランタイムプロファイルのクエリ:
クエリ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
まとめ:
セッションID : e74927207cd752b5 : 65ca61e630ad3ad
セッションタイプ:蜜蝋
開始時間: 2016 – 04 – 17 23 : 49 : 26.08148000終了時間: 2016 – 04 – 17 23 : 49 : 26.2404000
クエリタイプ: EXPLAIN
クエリ状態: FINISHED
クエリステータス: OK
Impalaバージョン: impaladバージョン2.3 。 0 –cdh5 。 _ 5.0リリース(ビルド0c891d77280e2129b )
ユーザー: cloudera
接続ユーザー: cloudera
委任されたユーザー:
ネットワークアドレス: 10.0 。 2.15 : 43870
デフォルトのDb : my_db
SQLステートメント:サンプルからselect *を説明します
コーディネーター:クイックスタート。 cloudera : 22000
: 0ns
クエリタイムライン: 167.304ms
–実行の開始: 41.292us ( 41.292us ) –計画の終了: 56.42ms ( 56.386ms )
–使用可能な行: 58.247ms ( 1.819ms )
–フェッチされた最初の行: 160.72ms ( 101.824ms )
–クエリの登録解除: 166.325ms ( 6.253ms )
ImpalaServer :
– ClientFetchWaitTimer : 107.969ms
– rowMaterializationTimer : 0ns
テーブルおよびデータベース固有のオプション
- 変更する
alterコマンドは、テーブルの構造と名前を変更するのに役立ちます。
- 説明
describeコマンドは、テーブルのメタデータを提供します。 列やそのデータ型などの情報が含まれています。
- 落とす
dropコマンドは、テーブル、ビュー、またはデータベース関数などの構成を削除するのに役立ちます。
- 入れる
挿入コマンドは、データ(列)をテーブルに追加し、既存のテーブルのデータをオーバーライドするのに役立ちます
- 選択する
selectコマンドを使用して、特定のデータセットに対して特定の操作を実行できます。 通常、アクションが完了するデータセットについて言及します。
- 見せる
showコマンドは、テーブルやデータベースなどのさまざまな構成のメタストアを表示します。
- 使用する
useコマンドは、特定のデータベースの現在のコンテキストを変更するのに役立ちます。
インパラ–コメント
Impalaでは、コメントはSQL言語のコメントと似ています。 通常、コメントには2つのタイプがあります。
1行のコメント
「—」が続く各行は、Impalaのコメントになります。
—こんにちは、upGradへようこそ。
複数行のコメント
/*と*/の間に含まれるすべての行は、Impalaでは複数行のコメントです。
/ *
こんにちはこれは例です

Impalaの複数行コメントの
* /
結論
この詳細なImpalaチュートリアルが、その複雑さと機能を理解するのに役立つことを願っています。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。
世界のトップ大学からオンラインでソフトウェア開発コースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。