Ultimate Impala Hadoop Tutorial de care veți avea vreodată nevoie [2022]
Publicat: 2020-05-14Impala este o bază de date analitică nativă, open-source, concepută pentru platforme în cluster precum Apache Hadoop. Este un motor interactiv de interogare asemănător SQL, care rulează pe sistemul de fișiere distribuit Hadoop (HDFS) pentru a facilita procesarea unor volume masive de date la o viteză fulgerătoare. De asemenea, impala este unul dintre cele mai importante instrumente Hadoop pentru a utiliza big data. Astăzi, vom vorbi despre toate lucrurile despre Impala și, prin urmare, am conceput acest tutorial Impala pentru tine!
Acest tutorial Impala Hadoop este special destinat celor care doresc să învețe Impala. Cu toate acestea, pentru a obține beneficiile maxime ale acestui tutorial Impala, ar fi de ajutor dacă aveți o înțelegere aprofundată a elementelor fundamentale ale SQL împreună cu comenzile Hadoop și HDFS.
Cuprins
Ce este Impala?
Impala este un motor de interogări SQL MPP (Massive Parallel Processing) scris în C++ și Java. Scopul său principal este de a procesa volume mari de date stocate în clustere Hadoop. Impala promite performanțe ridicate și latență scăzută și, până în prezent, motorul SQL de cea mai bună performanță (care oferă o experiență similară RDBMS) oferă cea mai rapidă modalitate de a accesa și procesa datele stocate în HDFS.
Un alt aspect benefic al Impala este că se integrează cu metamagazinul Hive pentru a permite partajarea informațiilor din tabel între ambele componente. Utilizează Apache Hive existent pentru a efectua joburi de lungă durată, orientate pe lot, în format de interogare SQL. Integrarea Impala-Hive vă permite să utilizați oricare dintre cele două componente – Hive sau Impala pentru procesarea datelor sau să creați tabele într-un singur sistem de fișiere partajat (HDFS) fără a modifica definiția tabelului.
De ce Impala?
Impala combină performanța multi-utilizator a unei baze de date analitice tradiționale și a suportului SQL cu scalabilitatea și flexibilitatea Apache Hadoop. Face acest lucru utilizând componente Hadoop standard precum HDFS, HBase, YARN, Sentry și Metastore. Deoarece Impala utilizează aceleași metadate, interfață de utilizator (Hue Beeswax), sintaxă SQL (Hive SQL) și driver ODBC (Open Database Connectivity) ca și Apache Hive, creează o platformă unificată și familiară pentru interogări în timp real și orientate pe lot.
Citiți: Idei de proiecte Big Data pentru începători

Impala poate citi aproape toate formatele de fișiere utilizate de Hadoop, inclusiv Parquet, Avro și RCFile. De asemenea, Impala nu este construit pe algoritmi MapReduce – implementează o arhitectură distribuită bazată pe procese daemon care gestionează și gestionează tot ceea ce are legătură cu execuția interogărilor care rulează pe aceeași mașină/e. Ca rezultat, ajută la reducerea latenței utilizării MapReduce. Acesta este exact ceea ce face Impala mult mai rapid decât Hive.
Impala – Caracteristici
Principalele caracteristici ale Impala sunt:
- Este disponibil ca motor de interogare SQL open-source sub licența Apache.
- Vă permite să accesați date utilizând interogări asemănătoare SQL.
- Acceptă procesarea datelor în memorie – accesează și analizează datele stocate pe nodurile de date Hadoop.
- Vă permite să stocați date în sisteme de stocare precum HDFS, Apache HBase și Amazon s3.
- Se integrează cu ușurință cu instrumente BI precum Tableau, Pentaho și Microstrategie.
- Acceptă diverse formate de fișiere, inclusiv Sequence File, Avro, LZO, RCFile și Parquet.
Impala – Avantaje cheie
Utilizarea Impala oferă utilizatorilor câteva avantaje semnificative, cum ar fi:
- Deoarece Impala acceptă procesarea datelor în memorie (procesarea are loc acolo unde se află datele – pe clusterul Hadoop), nu este nevoie de transformarea datelor și de mișcarea datelor.
- Pentru a accesa datele stocate în HDFS, sau HBase sau Amazon s3 cu Impala, nu aveți nevoie de cunoștințe anterioare despre Java (lucrări MapReduce) – le puteți accesa cu ușurință folosind interogări SQL de bază.
- În general, datele trebuie să treacă printr-un ciclu complicat de extragere-transformare-încărcare (ETL) în timp ce scriu interogări în instrumentele de afaceri. Cu toate acestea, cu Impala, nu este nevoie de asta. Impala înlocuiește etapele consumatoare de timp de încărcare și reorganizare cu tehnici avansate, cum ar fi analiza exploratorie a datelor și descoperirea datelor, crescând astfel viteza procesului.
- Impala este un pionier în utilizarea formatului de fișier Parquet, care este un aspect de stocare în coloană optimizat pentru interogări la scară largă găsite în depozitele de date.
Impala – Dezavantaje
Deși Impala oferă numeroase beneficii, are și anumite limitări:
- Nu are suport pentru serializare și deserializare.
- Nu poate citi fișiere binare personalizate; poate citi doar fișiere text.
- De fiecare dată când se adaugă noi înregistrări sau fișiere în directorul de date din HDFS, va trebui să reîmprospătați tabelul de date.
Impala – Arhitectură
Impala este decuplat de motorul său de stocare (contrar sistemelor tradiționale de stocare). Include trei componente principale – Impala Daemon (Impalad) , Impala StateStore și Impala Metadata & MetaStore.
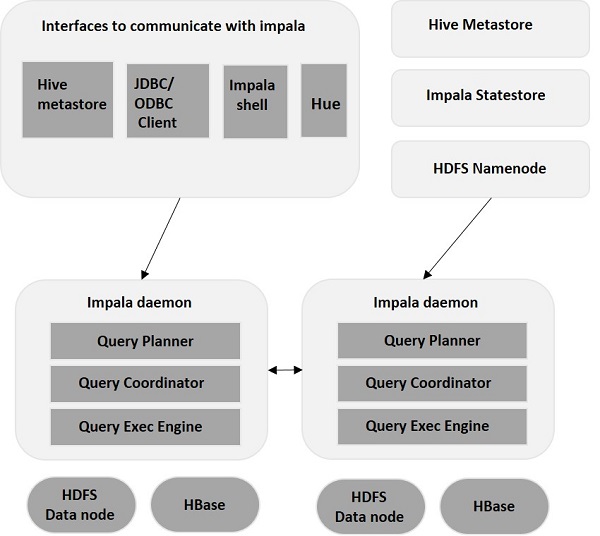
Impala Daemon
Impala Daemon, alias Impalad rulează pe noduri individuale unde este instalat Impala. Acceptă interogări de la mai multe interfețe (shell Impala, browser Hue etc.) și le procesează. De fiecare dată când o interogare este trimisă unui Impalad pe un anumit nod, nodul devine un „nod coordonator” pentru acea interogare. În acest fel, mai multe interogări sunt servite de Impalad care rulează pe alte noduri.
Odată ce interogările sunt acceptate, Impalad citește și scrie fișiere de date și paralelizează interogările prin distribuirea sarcinii celorlalte noduri Impala din cluster. Utilizatorii pot fie să trimită interogări către un Impalad dedicat, fie într-un mod echilibrat de încărcare altor Impalad din cluster, în funcție de cerințele lor. Aceste interogări încep apoi procesarea pe diferitele instanțe Impalad și returnează rezultatul la nodul de coordonare primar.
Impala StateStore
Impala StateStore monitorizează și verifică starea de sănătate a fiecărui Impalad și, de asemenea, transmite raportul de sănătate al fiecărui Impala Daemon celorlalți demoni. Poate rula pe același nod în care rulează serverul Impala sau într-un alt nod din cluster. În cazul în care există o defecțiune a nodului din anumite motive, Impala StateStore actualizează toate celelalte noduri despre defecțiune. Într-un astfel de eveniment, ceilalți daemoni Impala încetează să mai atribuie interogări suplimentare nodului eșuat.
Impala Metadata și MetaStore
În Impala, toate informațiile esențiale, inclusiv definițiile tabelelor, informațiile tabelelor și coloanelor etc., sunt stocate într-o bază de date centralizată cunoscută sub numele de MetaStore. Când aveți de-a face cu volume substanțiale de date care conțin mai multe partiții, devine dificil să obțineți metadate specifice tabelului. Aici Impala vine în ajutor. Deoarece nodurile individuale Impala memorează în cache toate metadatele la nivel local, devine ușor să obțineți informații specifice instantaneu.
De fiecare dată când actualizați definiția tabelului/datele tabelului, toți Impala Daemons trebuie, de asemenea, să își actualizeze memoria cache a metadatelor prin preluarea celor mai recente metadate înainte de a putea emite o nouă interogare pentru un anumit tabel.
Impala – Instalarea Impala
La fel cum trebuie să instalați Hadoop și ecosistemul său pe sistemul de operare Linux, puteți face același lucru cu Impala. Deoarece Cloudera a fost cel care a livrat Impala pentru prima dată, îl puteți accesa cu ușurință prin intermediul VM Cloudera QuickStart.
Citiți: Tutorial Hadoop
Cum să descărcați VM Cloudera QuickStart
Pentru a descărca VM Cloudera QuickStart, trebuie să urmați pașii prezentați mai jos.
Pasul 1
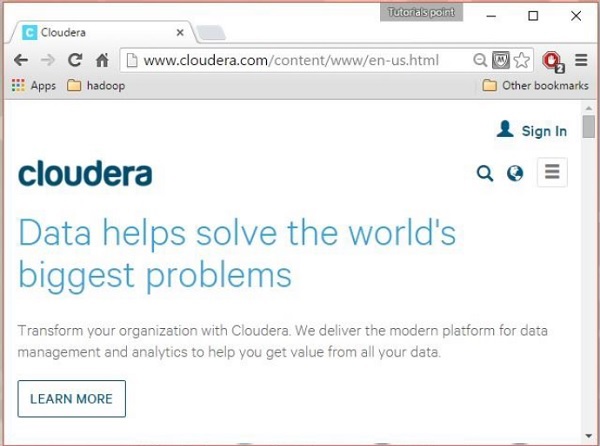
Deschideți pagina de pornire Cloudera ( http://www.cloudera.com/ ) și veți găsi ceva de genul acesta:
Pasul 2
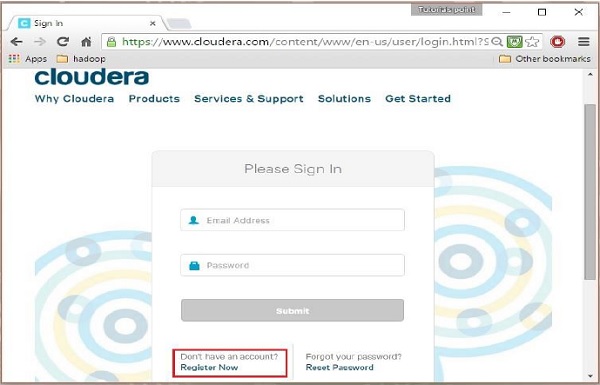
Pentru a vă înregistra pe Cloudera, trebuie să faceți clic pe opțiunea „Înregistrați-vă acum”, care va deschide pagina de înregistrare a contului. Dacă sunteți deja înregistrat pe Cloudera, puteți face clic pe opțiunea „Conectați-vă” de pe pagină și vă va redirecționa în continuare către pagina de conectare astfel:
Pasul 3
După ce v-ați conectat, deschideți pagina de descărcare a site-ului web făcând clic pe opțiunea „Descărcări” din colțul din stânga sus al paginii, după cum se arată mai jos:
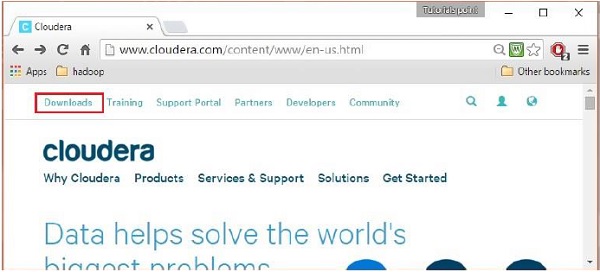
Pasul 4
În acest pas, trebuie să descărcați Cloudera QuickStartVM făcând clic pe opțiunea „Descărcați acum” astfel:
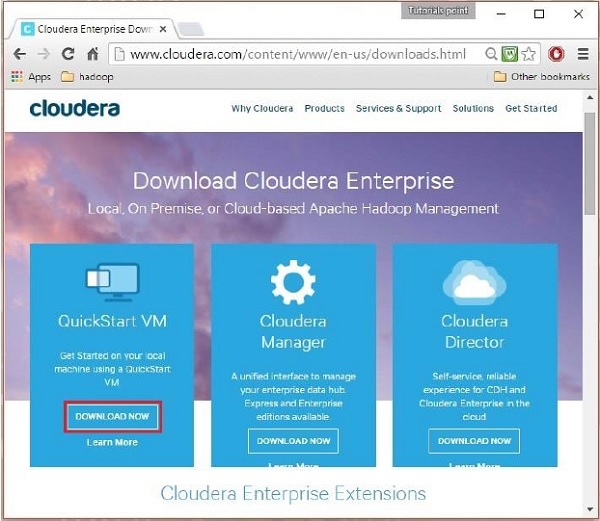
Făcând clic pe opțiunea Descărcare acum, veți fi redirecționat către pagina de descărcare a QuickStart VM:
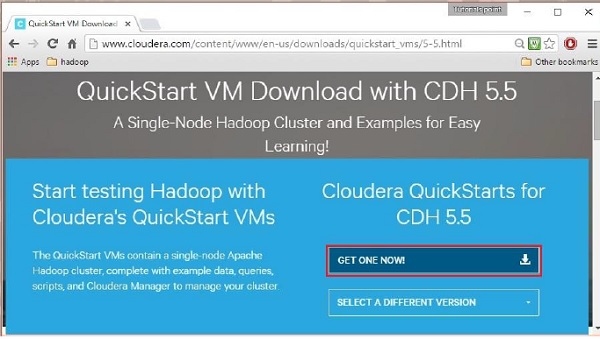
Apoi trebuie să selectați opțiunea GET ONE NOW, să acceptați acordul de licență și să îl trimiteți după cum se arată mai jos:
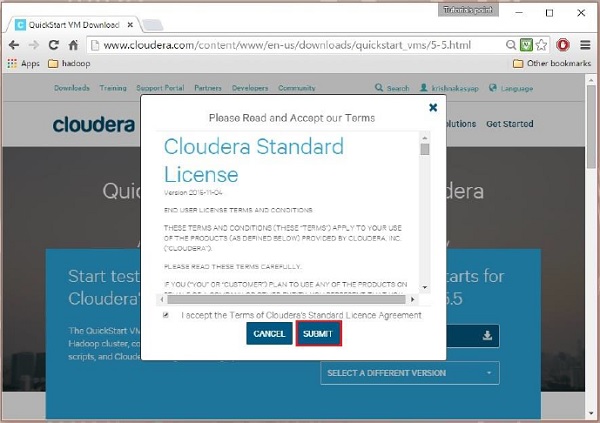
După ce descărcarea este finalizată, veți găsi trei opțiuni diferite compatibile cu Cloudera VM - VMware, KVM și VIRTUALBOX. Puteți alege opțiunea preferată.

Sursă
Impala – Interfețe de procesare a interogărilor
Impala oferă trei interfețe pentru procesarea interogărilor:
Impala-shell – Odată ce ați instalat și configurat Impala folosind VM Cloudera, puteți activa Impala-shell tastând comanda „impala-shell” în editor.
Citiți: Diferența dintre Big Data și Hadoop
Interfața Hue – Browserul Hue vă permite să procesați interogări Impala. Are un editor de interogări Impala unde puteți tasta și executa diferite interogări Impala. Cu toate acestea, pentru a utiliza editorul, mai întâi, va trebui să vă conectați la browserul Hue.
Drivere ODBC/JDBC – Așa cum este adevărat pentru fiecare bază de date, Impala oferă și drivere ODBC/JDBC. Aceste drivere vă permit să vă conectați la Impala prin limbaje de programare care le acceptă (drivere ODBC/JDBC) și să construiți aplicații care procesează interogări în Impala folosind aceleași limbaje de programare.
Procedura de executare a interogărilor
Ori de câte ori treceți o interogare folosind orice interfață Impala, un Impalad din cluster acceptă de obicei interogarea dvs. Acest Impalad devine apoi nodul coordonator pentru respectiva interogare. După primirea interogării, coordonatorul verifică dacă interogarea este adecvată sau nu utilizând Schema de tabel din Hive Metastore.
După aceasta, adună informații despre locația datelor care sunt necesare pentru execuția interogării din nodul de nume HDFS și transmite aceste informații altor Impalad din ierarhie pentru a facilita execuția interogării. Odată ce Impalad-ii citesc blocul de date specificat, procesează interogarea. Când Impalad-urile din cluster au procesat interogarea, nodul coordonator colectează rezultatul și vi-l livrează.
Comenzi Impala Shell
Dacă sunteți familiarizat cu Hive Shell, vă puteți da seama cu ușurință de Impala Shell, deoarece ambele au o structură destul de asemănătoare - permit crearea de baze de date și tabele, inserarea datelor și eliberarea de interogări. Comenzile Impala Shell se încadrează în trei categorii mari: comenzi generale, opțiuni specifice de interogare și opțiuni specifice tabelului și bazei de date.
Comenzi generale
- Ajutor
Comanda de ajutor oferă o listă de comenzi utile disponibile în Impala.
[quickstart.cloudera:21000] > ajutor;
Comenzi documentate (tastați help <subiect>):
==================================================== ======
calculează descrie inserează set unset cu versiunea
conectați explicați ieșiți arată valorile folosiți
ieșiți din istoricul profil selectați sfatul shell
Comenzi nedocumentate:
==========================================
alter create desc drop ajutor rezumat încărcare
- Versiune
Această comandă vă oferă versiunea curentă a Impala.
[quickstart.cloudera:21000] > versiune;
Versiunea Shell: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) construită pe Luni, 9 noiembrie
12:18:12 PST 2015
Versiunea serverului: Impalad versiunea 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- istorie
Această comandă afișează ultimele zece comenzi executate în Impala Shell.
[quickstart.cloudera:21000] > istoric;
[1]:versiune;
[2]:ajutor;
[3]:arata bazele de date;
[4]:utilizați my_db;
[5]:istorie;
- conectați
Această comandă ajută la conectarea la o anumită instanță a lui Impala. Dacă nu specificați nicio instanță, atunci implicit, se va conecta la portul implicit 21000.
[quickstart.cloudera:21000] > conectați;
Conectat la quickstart.cloudera:21000
Versiunea serverului: Impalad versiunea 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- ieșire/ieșire
După cum sugerează și numele, comanda exit/quit vă permite să părăsiți Impala Shell.
[quickstart.cloudera:21000] > ieșire;
La revedere, Cloudera
Interogați opțiuni specifice
- explica
Această comandă returnează planul de execuție pentru o anumită interogare.
[quickstart.cloudera:21000] > explicați selectarea * din eșantion;
Interogare: explicați selectarea * din eșantion
+—————————————————————————————+
| Explicați String
|
+—————————————————————————————+
| Cerințe estimate pentru fiecare gazdă: memorie = 48,00 MB VCcores = 1
|
| AVERTISMENT: Următoarele tabele lipsesc statistici relevante de tabel și/sau coloană. |
| my_db.clientii |
| 01:SCHIMB [NEPARTIȚIONAT]
|
| 00:SCANATE HDFS [my_db.customers] |
| partiții = 1/1 fișiere = 6 dimensiune = 148B |
+—————————————————————————————+
S-au preluat 7 rânduri în 0,17 s
- profil
Această comandă afișează informațiile de nivel scăzut despre interogarea recentă/ultima. Este folosit pentru diagnosticarea și reglarea performanței unei interogări.
[ pornire rapidă . cloudera : 21000 ] > profil ;
Profil de rulare a interogării :
Interogare ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
Rezumat :
ID sesiune : e74927207cd752b5 : 65ca61e630ad3ad
Tip de sesiune : CEARA DE ALBINE
Ora de începere : 2016 – 04 – 17 23 : 49 : 26.08148000 Ora de încheiere : 2016 – 04 – 17 23 : 49 : 26.2404000
Tip de interogare : EXPLAIN
Stare interogare : TERMINAT
Stare interogare : OK
Versiunea Impala : versiunea Impala 2.3 . 0 – cdh5 . VERSIUNEA 5.0 ( build 0c891d77280e2129b )
Utilizator : cloudera
Utilizator conectat : cloudera
Utilizator delegat :
Adresa de rețea : 10.0 . 2,15 : 43870
Db implicit : my_db
Declarație Sql : explicați select * din eșantion
Coordonator : pornire rapidă . cloudera : 22000
: 0ns
Cronologia interogării : 167,304 ms
– Începe execuția : 41.292us ( 41.292us ) – Planificarea finalizată : 56.42ms ( 56.386ms )
– Rânduri disponibile : 58,247 ms ( 1,819 ms )
– Primul rând preluat : 160,72 ms ( 101,824 ms )
– Anulați înregistrarea interogării : 166.325ms ( 6.253ms )
ImpalaServer :
– ClientFetchWaitTimer : 107,969 ms
– RowMaterializationTimer : 0ns
Opțiuni specifice pentru tabele și baze de date
- modifica
Comanda alter ajută la schimbarea structurii și numelui unui tabel.
- descrie
Comanda describe oferă metadatele unui tabel. Conține informații precum coloanele și tipurile lor de date.
- cădere brusca
Comanda drop ajută la eliminarea unui construct, care poate fi un tabel, o vizualizare sau o funcție de bază de date.
- introduce
Comanda insert vă ajută să adăugați date (coloane) într-un tabel și să suprascrieți datele unui tabel existent
- Selectați
Comanda select poate fi folosită pentru a efectua o anumită operație pe un anumit set de date. De obicei, menționează setul de date pe care urmează să fie finalizată acțiunea.
- spectacol
Comanda show afișează metamagazinul diferitelor constructe, cum ar fi tabele și baze de date.
- utilizare
Comanda use ajută la schimbarea contextului curent al unei anumite baze de date.
Impala – Comentarii
În Impala, comentariile sunt similare cu cele din limbajul SQL. De obicei, există două tipuri de comentarii:
Comentarii pe o singură linie
Fiecare rând care este urmat de „—” devine un comentariu în Impala.
— Bună, bine ați venit la upGrad.
Comentarii pe mai multe linii
Toate rândurile cuprinse între /* și */ sunt comentarii pe mai multe linii în Impala.
/*
Salut, acesta este un exemplu

De comentarii pe mai multe linii în Impala
*/
Concluzie
Sperăm că acest tutorial detaliat Impala v-a ajutat să înțelegeți complexitățile sale și cum funcționează.
Dacă sunteți interesat să aflați mai multe despre Big Data, consultați programul nostru PG Diploma în Dezvoltare Software Specializare în Big Data, care este conceput pentru profesioniști care lucrează și oferă peste 7 studii de caz și proiecte, acoperă 14 limbaje și instrumente de programare, practică practică. ateliere de lucru, peste 400 de ore de învățare riguroasă și asistență pentru plasarea unui loc de muncă cu firme de top.
Învață cursuri de dezvoltare software online de la cele mai bune universități din lume. Câștigați programe Executive PG, programe avansate de certificat sau programe de master pentru a vă accelera cariera.