برنامج تعليمي Impala Hadoop المطلق الذي ستحتاج إليه على الإطلاق [2022]
نشرت: 2020-05-14Impala هي قاعدة بيانات تحليلية أصلية مفتوحة المصدر مصممة لمنصات مجمعة مثل Apache Hadoop. إنه محرك استعلام تفاعلي يشبه SQL يتم تشغيله أعلى نظام الملفات الموزعة Hadoop (HDFS) لتسهيل معالجة كميات هائلة من البيانات بسرعة البرق. تعد إمبالا أيضًا واحدة من أفضل أدوات Hadoop لاستخدام البيانات الضخمة. اليوم ، سنتحدث عن كل الأشياء في إمبالا ، وبالتالي ، قمنا بتصميم برنامج إمبالا التعليمي هذا من أجلك!
تم تصميم برنامج Impala Hadoop التعليمي هذا خصيصًا لأولئك الذين يرغبون في تعلم Impala. ومع ذلك ، لجني أقصى الفوائد من هذا البرنامج التعليمي Impala ، سيكون من المفيد أن يكون لديك فهم متعمق لأساسيات SQL جنبًا إلى جنب مع أوامر Hadoop و HDFS.
جدول المحتويات
ما هي إمبالا؟
Impala هو محرك استعلام SQL MPP (معالجة موازية ضخمة) مكتوب بلغة C ++ و Java. الغرض الأساسي منه هو معالجة كميات هائلة من البيانات المخزنة في مجموعات Hadoop. تعد إمبالا بأداء عالٍ وزمن انتقال منخفض ، وهو حتى الآن محرك SQL الأفضل أداء (الذي يقدم تجربة تشبه RDBMS) لتوفير أسرع طريقة للوصول إلى البيانات المخزنة في HDFS ومعالجتها.
جانب آخر مفيد من إمبالا هو أنه يتكامل مع الخلية النقيلي للسماح بمشاركة معلومات الجدول بين كلا المكونين. إنها تستفيد من Apache Hive الحالية لأداء مهام موجهة نحو الدُفعات طويلة المدى بتنسيق استعلام SQL. يتيح لك تكامل Impala-Hive استخدام أي من المكونين - Hive أو Impala لمعالجة البيانات أو لإنشاء جداول ضمن نظام ملفات مشترك واحد (HDFS) دون تغيير تعريف الجدول.
لماذا إمبالا؟
تجمع إمبالا بين أداء المستخدمين المتعددين لقاعدة البيانات التحليلية التقليدية ودعم SQL مع قابلية التوسع والمرونة في Apache Hadoop. يقوم بذلك باستخدام مكونات Hadoop القياسية مثل HDFS و HBase و YARN و Sentry و Metastore. نظرًا لأن Impala تستخدم نفس البيانات الوصفية ، وواجهة المستخدم (Hue Beeswax) ، وبناء جملة SQL (Hive SQL) ، وبرنامج تشغيل ODBC (اتصال قاعدة البيانات المفتوح) مثل Apache Hive ، فإنها تنشئ نظامًا أساسيًا موحدًا ومألوفًا للاستعلامات الموجهة بالدُفعات وفي الوقت الحقيقي.
قراءة: أفكار مشاريع البيانات الضخمة للمبتدئين

يمكن لـ Impala قراءة جميع تنسيقات الملفات التي يستخدمها Hadoop تقريبًا ، بما في ذلك Parquet و Avro و RCFile. أيضًا ، لا يتم إنشاء Impala على خوارزميات MapReduce - فهي تنفذ بنية موزعة بناءً على عمليات خفية تتعامل مع وتدير كل ما يتعلق بتنفيذ الاستعلام الذي يعمل على نفس الجهاز / الأجهزة. نتيجة لذلك ، فإنه يساعد في تقليل زمن الوصول لاستخدام MapReduce. هذا هو بالضبط ما يجعل إمبالا أسرع بكثير من الخلية.
إمبالا - الميزات
الميزات الرئيسية لسيارة إمبالا هي:
- وهي متاحة كمحرك استعلام SQL مفتوح المصدر بموجب ترخيص Apache.
- يتيح لك الوصول إلى البيانات باستخدام استعلامات تشبه SQL.
- يدعم معالجة البيانات في الذاكرة - يصل إلى البيانات المخزنة على عقد بيانات Hadoop ويحللها.
- يسمح لك بتخزين البيانات في أنظمة التخزين مثل HDFS و Apache HBase و Amazon s3.
- يتكامل بسهولة مع أدوات ذكاء الأعمال مثل Tableau و Pentaho و Micro Strategy.
- وهو يدعم تنسيقات ملفات مختلفة بما في ذلك Sequence File و Avro و LZO و RCFile و Parquet.
إمبالا - المزايا الرئيسية
يوفر استخدام إمبالا بعض المزايا المهمة للمستخدمين ، مثل:
- نظرًا لأن Impala تدعم معالجة البيانات داخل الذاكرة (تحدث المعالجة حيث توجد البيانات - على مجموعة Hadoop) ، ليست هناك حاجة لتحويل البيانات وحركة البيانات.
- للوصول إلى البيانات المخزنة في HDFS أو HBase أو Amazon s3 مع Impala ، لا تحتاج إلى أي معرفة مسبقة بجافا (وظائف MapReduce) - يمكنك الوصول إليها بسهولة باستخدام استعلامات SQL الأساسية.
- بشكل عام ، يجب أن تخضع البيانات لدورة استخراج وتحويل معقدة (ETL) أثناء كتابة الاستعلامات في أدوات الأعمال. ومع ذلك ، مع إمبالا ، ليست هناك حاجة لذلك. تستبدل إمبالا المراحل التي تستغرق وقتًا طويلاً من التحميل وإعادة التنظيم بتقنيات متقدمة مثل تحليل البيانات الاستكشافية واكتشاف البيانات ، وبالتالي زيادة سرعة العملية.
- تعتبر إمبالا رائدة في استخدام تنسيق ملف باركيه ، وهو تخطيط تخزين عمودي محسّن للاستعلامات واسعة النطاق الموجودة في مستودعات البيانات.
إمبالا - عيوب
على الرغم من أن إمبالا تقدم العديد من المزايا ، إلا أن لها بعض القيود أيضًا:
- لا يدعم التسلسل وإلغاء التسلسل.
- لا يمكن قراءة الملفات الثنائية المخصصة ؛ يمكنه قراءة الملفات النصية فقط.
- في كل مرة يتم فيها إضافة سجلات أو ملفات جديدة إلى دليل البيانات في HDFS ، ستحتاج إلى تحديث جدول البيانات.
إمبالا - العمارة
تنفصل إمبالا عن محرك التخزين الخاص بها (على عكس أنظمة التخزين التقليدية). يتضمن ثلاثة مكونات رئيسية - Impala Daemon (Impalad) و Impala StateStore و Impala Metadata و MetaStore.
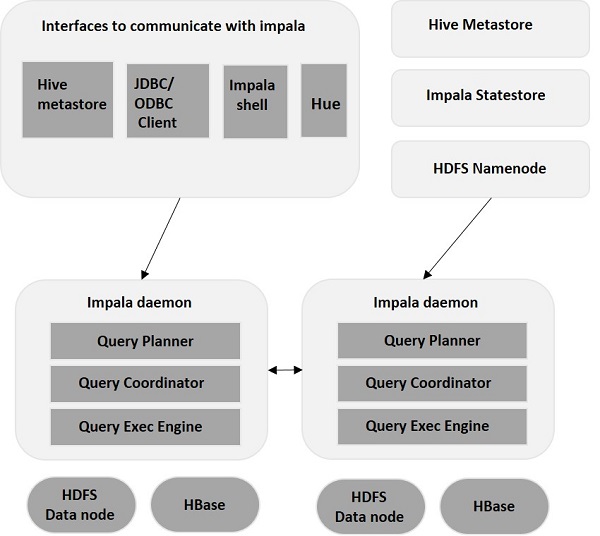
إمبالا الشيطان
يعمل Impala Daemon ، المعروف أيضًا باسم Impalad على العقد الفردية حيث يتم تثبيت Impala. يقبل الاستعلامات من واجهات متعددة (Impala shell ، مستعرض Hue ، إلخ) ويقوم بمعالجتها. في كل مرة يتم فيها تقديم استعلام إلى Impalad على عقدة معينة ، تصبح العقدة "عقدة منسقة" لهذا الاستعلام. بهذه الطريقة ، يتم تقديم استعلامات متعددة بواسطة Impalad تعمل على العقد الأخرى.
بمجرد قبول الاستعلامات ، يقوم إمبالاد بقراءة وكتابة ملفات البيانات ويوازي الاستعلامات عن طريق توزيع المهمة على عقد إمبالا الأخرى في المجموعة. يمكن للمستخدمين إما إرسال استعلامات إلى Impalad مخصص أو بطريقة متوازنة التحميل إلى Impalad الأخرى في الكتلة ، بناءً على متطلباتهم. ثم تبدأ هذه الاستعلامات في المعالجة على مثيلات Impalad المختلفة وتعيد النتيجة إلى عقدة التنسيق الأساسية.
إمبالا ستيتستور
يراقب Impala StateStore ويتحقق من صحة كل Impalad وينقل أيضًا التقرير الصحي لكل صحة Impala Daemon إلى الشياطين الأخرى. يمكن أن يعمل على نفس العقدة حيث يعمل خادم Impala أو في عقدة أخرى في الكتلة. في حالة حدوث فشل في العقدة لسبب ما ، يقوم Impala StateStore بتحديث جميع العقد الأخرى حول الفشل. في مثل هذه الحالة ، تتوقف شياطين إمبالا الأخرى عن تعيين أي استعلامات أخرى للعقدة الفاشلة.
إمبالا ميتاداتا و ميتا ستور
في Impala ، يتم تخزين جميع المعلومات المهمة ، بما في ذلك تعريفات الجدول ومعلومات الجدول والعمود وما إلى ذلك ، داخل قاعدة بيانات مركزية تُعرف باسم MetaStore. عند التعامل مع كميات كبيرة من البيانات التي تحتوي على أقسام متعددة ، يصبح من الصعب الحصول على بيانات وصفية خاصة بالجدول. هذا هو المكان الذي تأتي فيه إمبالا لإنقاذ. نظرًا لأن عقد إمبالا الفردية تخزن جميع البيانات الوصفية محليًا ، يصبح من السهل الحصول على معلومات محددة على الفور.
في كل مرة تقوم فيها بتحديث تعريف الجدول / بيانات الجدول ، يجب على جميع Impala Daemons أيضًا تحديث ذاكرة التخزين المؤقت لبيانات التعريف الخاصة بهم عن طريق استرداد أحدث البيانات الوصفية قبل أن يتمكنوا من إصدار استعلام جديد مقابل جدول معين.
إمبالا - تركيب إمبالا
تمامًا مثلما تحتاج إلى تثبيت Hadoop ونظامه البيئي على نظام التشغيل Linux ، يمكنك فعل الشيء نفسه مع Impala. نظرًا لأن Cloudera هي أول من شحنت إمبالا ، يمكنك الوصول إليها بسهولة عبر Cloudera QuickStart VM.
قراءة: برنامج Hadoop التعليمي
كيفية تنزيل Cloudera QuickStart VM
لتنزيل Cloudera QuickStart VM ، يجب عليك اتباع الخطوات الموضحة أدناه.
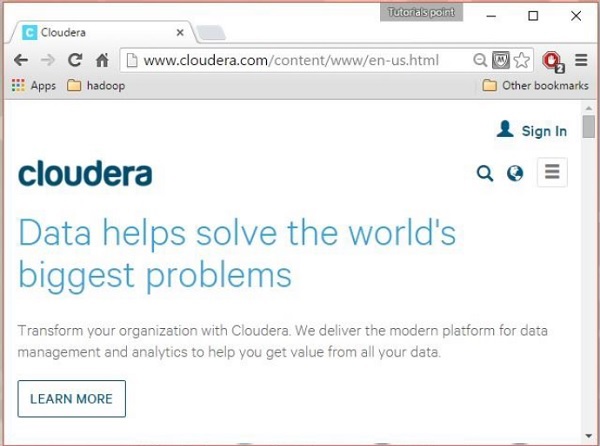
الخطوة 1
افتح صفحة Cloudera الرئيسية ( http://www.cloudera.com/ ) ، وستجد شيئًا مثل هذا:
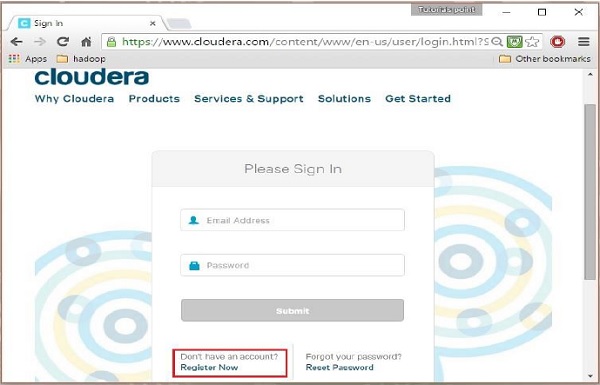
الخطوة 2
للتسجيل في Cloudera ، يجب النقر فوق خيار "سجل الآن" ، والذي سيفتح صفحة تسجيل الحساب. إذا كنت مسجلاً بالفعل في Cloudera ، فيمكنك النقر فوق خيار "تسجيل الدخول" في الصفحة ، وسيعيد توجيهك إلى صفحة تسجيل الدخول كما يلي:
الخطوه 3
بمجرد تسجيل الدخول ، افتح صفحة التنزيل الخاصة بالموقع الإلكتروني بالنقر فوق خيار "التنزيلات" في الزاوية اليسرى العلوية من الصفحة ، كما هو موضح أدناه:
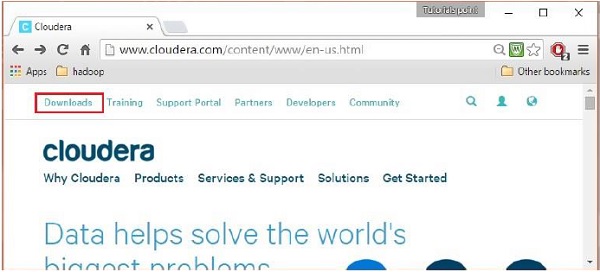
الخطوة 4
في هذه الخطوة ، تحتاج إلى تنزيل Cloudera QuickStartVM بالنقر فوق خيار "تنزيل الآن" مثل:
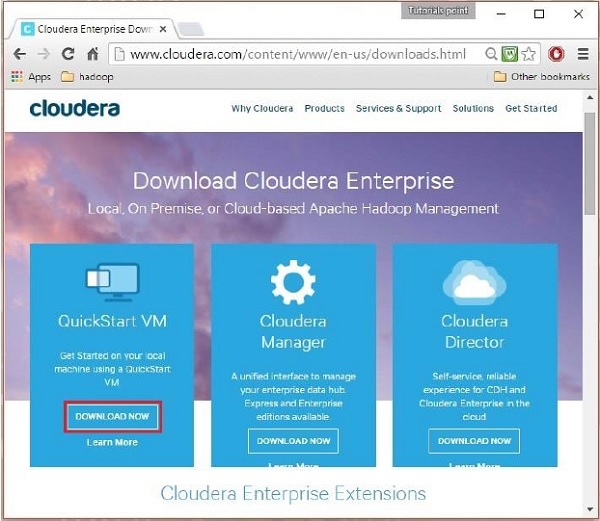
سيؤدي النقر فوق خيار التنزيل الآن إلى إعادة توجيهك إلى صفحة التنزيل الخاصة بـ QuickStart VM:
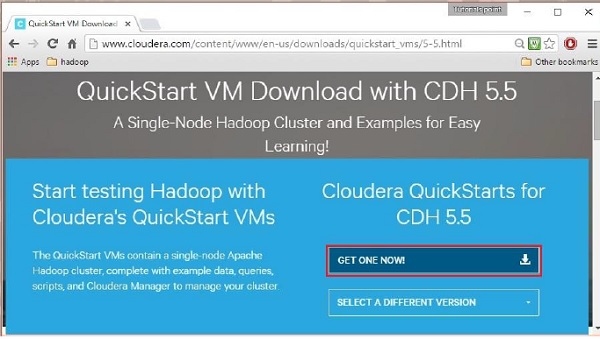
ثم يتعين عليك تحديد خيار GET ONE NOW ، وقبول اتفاقية الترخيص ، وإرسالها كما هو موضح أدناه:
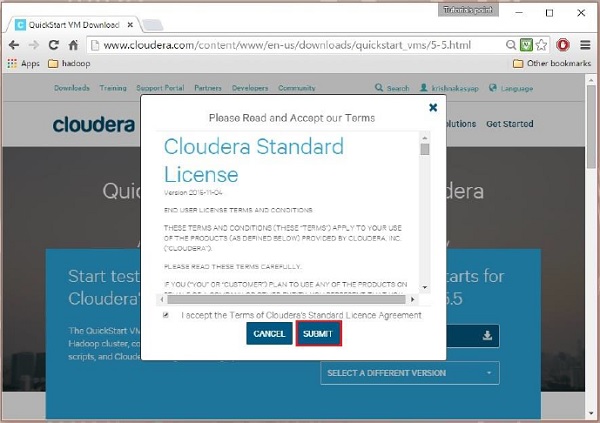
بعد اكتمال التنزيل ، ستجد ثلاثة خيارات مختلفة متوافقة مع Cloudera VM - VMware و KVM و VIRTUALBOX. يمكنك اختيار الخيار المفضل لديك.
مصدر
إمبالا - واجهات معالجة الاستعلام
تقدم إمبالا ثلاث واجهات لمعالجة الاستعلامات:
Impala-shell - بمجرد تثبيت Impala وإعداده باستخدام Cloudera VM ، يمكنك تنشيط Impala-shell بكتابة الأمر “impala-shell” في المحرر.
قراءة: الفرق بين البيانات الضخمة و Hadoop
واجهة Hue - يتيح لك متصفح Hue معالجة استعلامات Impala. يحتوي على محرر استعلام Impala حيث يمكنك كتابة وتنفيذ استعلامات Impala المختلفة. ومع ذلك ، لاستخدام المحرر ، ستحتاج أولاً إلى تسجيل الدخول إلى متصفح Hue.
برامج تشغيل ODBC / JDBC - كما هو الحال في كل قاعدة بيانات ، تقدم Impala أيضًا برامج تشغيل ODBC / JDBC. تتيح لك برامج التشغيل هذه الاتصال بـ Impala من خلال لغات البرمجة التي تدعمها (برامج تشغيل ODBC / JDBC) وإنشاء تطبيقات تعالج الاستعلامات في Impala باستخدام نفس لغات البرمجة.

إجراء تنفيذ الاستعلام
كلما مررت استعلامًا باستخدام أي واجهات Impala ، عادةً ما يقبل Impalad الموجود في المجموعة استعلامك. ثم تصبح Impalad هذه العقدة المنسقة لهذا الاستعلام المحدد. بعد استلام الاستعلام ، يتحقق المنسق مما إذا كان الاستعلام مناسبًا أم لا باستخدام مخطط الجدول من Hive Metastore.
بعد ذلك ، يقوم بجمع معلومات حول موقع البيانات المطلوبة لتنفيذ الاستعلام من عقدة اسم HDFS وإعادة توجيه هذه المعلومات إلى Impalads الأخرى في التسلسل الهرمي لتسهيل تنفيذ الاستعلام. بمجرد قراءة Impalads كتلة البيانات المحددة ، يقومون بمعالجة الاستعلام. عندما تقوم جميع Impalads في المجموعة بمعالجة الاستعلام ، تقوم عقدة المنسق بجمع النتيجة وتسليمها إليك.
أوامر إمبالا شل
إذا كنت معتادًا على Hive Shell ، فيمكنك بسهولة اكتشاف Impala Shell نظرًا لأن كلاهما يشتركان في بنية متشابهة إلى حد كبير - يسمحان بإنشاء قواعد بيانات وجداول وإدراج البيانات وإصدار استعلامات. تندرج أوامر Impala Shell ضمن ثلاث فئات عامة: الأوامر العامة ، وخيارات الاستعلام المحددة ، والخيارات الخاصة بالجدول وقاعدة البيانات.
أوامر عامة
- مساعدة
يقدم أمر التعليمات قائمة بالأوامر المفيدة المتوفرة في Impala.
[quickstart.cloudera: 21000]> مساعدة ؛
أوامر موثقة (اكتب مساعدة <موضوع>):
==================================================== ======
وصف الحوسبة إدراج مجموعة غير مضبوطة مع الإصدار
ربط شرح إنهاء إظهار استخدام القيم
الخروج من الملف الشخصي التاريخ حدد قذيفة تلميح
أوامر غير موثقة:
===========================================
تغيير إنشاء وصف وإسقاط مساعدة ملخص تحميل
- الإصدار
يوفر لك هذا الأمر الإصدار الحالي من Impala.
[quickstart.cloudera: 21000]> الإصدار ؛
إصدار شل: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) الذي تم إنشاؤه في الاثنين 9 نوفمبر
12:18:12 توقيت المحيط الهادي 2015
إصدار الخادم: إصدار Impalad 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- التاريخ
يعرض هذا الأمر آخر عشرة أوامر تم تنفيذها في Impala Shell.
[quickstart.cloudera: 21000]> التاريخ ؛
[1]: إصدار ؛
[2]: مساعدة ؛
[3]: إظهار قواعد البيانات ؛
[4]: استخدم my_db؛
[5]: التاريخ؛
- الاتصال
يساعد هذا الأمر في الاتصال بمثيل معين من Impala. إذا لم تحدد أي مثيل ، فسيتم الاتصال بالمنفذ الافتراضي 21000 افتراضيًا.
[quickstart.cloudera: 21000]> اتصال ؛
متصل بـ quickstart.cloudera: 21000
إصدار الخادم: إصدار Impalad 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
- خروج / خروج
كما يوحي الاسم ، يتيح لك الأمر exit / quit الخروج من Impala Shell.
[quickstart.cloudera: 21000]> خروج ؛
وداعا كلوديرا
خيارات محددة الاستعلام
- يشرح
يقوم هذا الأمر بإرجاع خطة التنفيذ لاستعلام معين.
[quickstart.cloudera: 21000]> شرح تحديد * من العينة ؛
الاستعلام: شرح تحديد * من العينة
+ ———————————————————————————— +
| اشرح السلسلة
|
+ ———————————————————————————— +
| المتطلبات المقدرة لكل مضيف: الذاكرة = 48.00 ميجا بايت VCores = 1
|
| تحذير: تفتقد الجداول التالية إحصائيات الجدول و / أو العمود ذات الصلة. |
| my_db.customers |
| 01: تبادل [غير مقسم]
|
| 00: SCAN HDFS [my_db.customers] |
| الأقسام = 1/1 ملفات = 6 الحجم = 148B |
+ ———————————————————————————— +
تم جلب 7 صف (صفوف) في 0.17 ثانية
- الملف الشخصي
يعرض هذا الأمر المعلومات ذات المستوى المنخفض حول آخر / أحدث استعلام. يتم استخدامه لتشخيص وضبط أداء الاستعلام.
[ بداية سريعة . cloudera : 21000 ] > الملف الشخصي ؛
ملف تعريف وقت تشغيل الاستعلام :
الاستعلام ( id = 164b1294a1049189 : a67598a6699e3ab6 ):
ملخص :
معرف الجلسة : e74927207cd752b5 : 65ca61e630ad3ad
نوع الجلسة : BEESWAX
وقت البدء : 2016-04-17 23 : 49 : 26.08148000 وقت الانتهاء : 2016-04-17 23 : 49 : 26.2404000 _ _ _ _ _ _ _ _
نوع الاستعلام : شرح
حالة الاستعلام : انتهى
حالة الاستعلام : حسنًا
إصدار إمبالا : إمبالاد الإصدار 2.3 . 0 - سي دي إتش 5 . 5.0 الإصدار ( النسخة 0c891d77280e2129b )
المستخدم : cloudera
المستخدم المتصل : cloudera
المستخدم المفوض :
عنوان الشبكة : 10.0 . 2.15 : 43870
الافتراضي Db : my_db
بيان SQL : شرح تحديد * من العينة
المنسق : quickstart . كلوديرا : 22000
: 0ns
الجدول الزمني للاستعلام : 167.304 مللي ثانية
- بدء التنفيذ : 41.292us ( 41.292us ) - انتهى التخطيط : 56.42 مللي ثانية ( 56.386 مللي ثانية )
- الصفوف المتاحة : 58.247 مللي ثانية ( 1.819 مللي ثانية )
- تم جلب الصف الأول : 160.72 مللي ثانية ( 101.824 مللي ثانية )
- استعلام غير مسجل : 166.325 مللي ثانية ( 6.253 مللي ثانية )
إمبالا سيرفر :
- ClientFetchWaitTimer : 107.969ms
- RowMaterializationTimer : 0ns
خيارات خاصة بالجدول وقاعدة البيانات
- تبديل
يساعد الأمر alter على تغيير بنية الجدول واسمه.
- يصف
يوفر الأمر description البيانات الأولية للجدول. يحتوي على معلومات مثل الأعمدة وأنواع بياناتها.
- يسقط
يساعد الأمر drop في إزالة بنية ، والتي يمكن أن تكون جدولًا أو طريقة عرض أو وظيفة قاعدة بيانات.
- إدراج
يساعد الأمر insert على إلحاق البيانات (الأعمدة) بالجدول وتجاوز بيانات الجدول الموجود
- تحديد
يمكن استخدام الأمر select لإجراء عملية محددة على مجموعة بيانات معينة. يذكر عادةً مجموعة البيانات التي سيتم إكمال الإجراء عليها.
- يعرض
يعرض الأمر show المخزن الأساسي للعديد من التركيبات مثل الجداول وقواعد البيانات.
- استعمال
يساعد الأمر use في تغيير السياق الحالي لقاعدة بيانات معينة.
إمبالا - تعليقات
في Impala ، التعليقات مماثلة لتلك الموجودة في لغة SQL. عادة ، هناك نوعان من التعليقات:
تعليقات من سطر واحد
يصبح كل سطر يتبعه "-" تعليقًا في إمبالا.
- أهلا ومرحبا بكم في upGrad.
تعليقات متعددة الأسطر
جميع الأسطر الموجودة بين / * و * / هي تعليقات متعددة الأسطر في إمبالا.
/ *
مرحبا هذا مثال

من التعليقات متعددة الأسطر في إمبالا
* /
خاتمة
نأمل أن يساعدك هذا البرنامج التعليمي التفصيلي في إمبالا على فهم تعقيداتها وكيفية عملها.
إذا كنت مهتمًا بمعرفة المزيد عن البيانات الضخمة ، فراجع دبلومة PG في تخصص تطوير البرمجيات في برنامج البيانات الضخمة المصمم للمهنيين العاملين ويوفر أكثر من 7 دراسات حالة ومشاريع ، ويغطي 14 لغة وأدوات برمجة ، وتدريب عملي عملي ورش العمل ، أكثر من 400 ساعة من التعلم الصارم والمساعدة في التوظيف مع الشركات الكبرى.
تعلم دورات تطوير البرمجيات عبر الإنترنت من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.