
Utilizarea rețelei neuronale convoluționale pentru clasificarea imaginilor
Publicat: 2020-08-14Clasificarea imaginilor primește o schimbare. Mulțumesc CNN.
Rețelele neuronale convoluționale (CNN) sunt coloana vertebrală a clasificării imaginilor, un fenomen de învățare profundă care preia o imagine și îi atribuie o clasă și o etichetă care o face unică. Clasificarea imaginilor folosind CNN formează o parte semnificativă a experimentelor de învățare automată.
Împreună cu utilizarea CNN și a capabilităților sale induse, este acum utilizat pe scară largă pentru o gamă largă de aplicații, de la etichetarea imaginilor Facebook la recomandările de produse Amazon și imaginile de îngrijire medicală până la mașini automate. Motivul pentru care CNN este atât de popular este că necesită foarte puțină preprocesare, ceea ce înseamnă că poate citi imagini 2D aplicând filtre pe care alți algoritmi convenționali nu le pot. Vom aprofunda procesul de funcționare a clasificării imaginilor folosind CNN .
Cuprins
Cum funcționează CNN?
CNN-urile sunt echipate cu un strat de intrare, un strat de ieșire și straturi ascunse, toate care ajută la procesarea și clasificarea imaginilor. Straturile ascunse cuprind straturi convoluționale, straturi ReLU, straturi de grupare și straturi complet conectate, toate acestea joacă un rol crucial. Aflați mai multe despre rețeaua neuronală convoluțională.
Să vedem cum funcționează clasificarea imaginilor folosind CNN :
Imaginează-ți că imaginea de intrare este cea a unui elefant. Această imagine, cu pixeli, este introdusă mai întâi în straturile convoluționale. Dacă este o imagine alb-negru, imaginea este interpretată ca un strat 2D, fiecărui pixel fiind atribuită o valoare între „0” și „255”, „0” fiind complet negru și „255” complet alb. Dacă, pe de altă parte, este o imagine color, aceasta devine o matrice 3D, cu un strat albastru, verde și roșu, cu fiecare valoare de culoare între 0 și 255.

Apoi începe citirea matricei, pentru care software-ul selectează o imagine mai mică, cunoscută sub numele de „filtru” (sau nucleu). Adâncimea filtrului este aceeași cu adâncimea intrării. Filtrul produce apoi o mișcare de convoluție împreună cu imaginea de intrare, mișcându-se de-a lungul imaginii cu 1 unitate.
Apoi înmulțește valorile cu valorile imaginii originale. Toate cifrele înmulțite se adună și se generează un singur număr. Procesul se repetă împreună cu întreaga imagine și se obține o matrice, mai mică decât imaginea de intrare originală.
Matricea finală se numește harta caracteristicilor unei hărți de activare. Convoluția unei imagini ajută la efectuarea unor operațiuni precum detectarea marginilor, clarificarea și estomparea, prin aplicarea diferitelor filtre. Tot ce trebuie să faceți este să specificați aspecte precum dimensiunea filtrului, numărul de filtre și/sau arhitectura rețelei.
Dintr-o perspectivă umană, această acțiune este asemănătoare cu identificarea culorilor și limitelor simple ale unei imagini. Cu toate acestea, pentru a clasifica imaginea și a recunoaște trăsăturile care o fac, să zicem, aceea a unui elefant și nu a unei pisici, trebuie identificate trăsături unice precum urechile mari și trunchiul elefantului. Aici intervin straturile neliniare și de grupare.
Stratul neliniar (ReLU) urmează stratul de convoluție, unde o funcție de activare este aplicată hărților caracteristici pentru a crește neliniaritatea imaginii. Stratul ReLU elimină toate valorile negative și mărește acuratețea imaginii. Deși există și alte operațiuni precum tanh sau sigmoid, ReLU este cea mai populară, deoarece poate antrena rețeaua mult mai rapid.
Următorul pas este să creați mai multe imagini ale aceluiași obiect, astfel încât rețeaua să poată recunoaște întotdeauna acea imagine, indiferent de dimensiunea sau locația acesteia. De exemplu, în imaginea elefantului, rețeaua trebuie să recunoască elefantul, fie că merge, stă nemișcat sau aleargă. Trebuie să existe flexibilitate a imaginii și aici intervine stratul de pooling.
Funcționează cu măsurătorile imaginii (înălțime și lățime) pentru a reduce progresiv dimensiunea imaginii de intrare, astfel încât obiectele din imagine să poată fi reperate și identificate oriunde se află.
De asemenea, punerea în comun ajută la controlul „suprafitting” în cazul în care există prea multe informații, fără posibilitate pentru altele noi. Poate că cel mai comun exemplu de pooling este max pooling, unde imaginea este împărțită într-o serie de zone care nu se suprapun.
Regruparea maximă se referă la identificarea valorii maxime în fiecare zonă, astfel încât toate informațiile suplimentare să fie excluse, iar imaginea să devină mai mică. Această acțiune ajută și la distorsiunile din imagine.
Acum vine stratul complet conectat care adaugă o rețea neuronală artificială pentru utilizarea CNN. Această rețea artificială combină diferite caracteristici și ajută la prezicerea claselor de imagini cu o mai mare acuratețe. În această etapă, se calculează gradientul funcției de eroare cu privire la greutatea rețelei neuronale. Greutățile și detectoarele de caracteristici sunt ajustate pentru a optimiza performanța, iar acest proces se repetă în mod repetat.
Iată cum arată arhitectura CNN:
Sursă
Utilizarea seturilor de date pentru CNN Application-MNIST
Mai multe seturi de date pot fi utilizate pentru a aplica CNN în mod eficient. Cele mai populare trei elemente vitale în clasificarea imaginilor folosind CNN sunt MNIST, CIFAR-10 și ImageNet. Să ne uităm mai întâi la MNIST.
1. MNIST
MNIST este un acronim pentru setul de date modificat al Institutului Național de Standarde și Tehnologie și cuprinde 60.000 de imagini mici, pătrate, în tonuri de gri, de 28×28, cu cifre unice, scrise de mână, între 0 și 9. MNIST este un set de date popular și bine înțeles, adică pentru cei mai mari. parte, „rezolvat”. Poate fi folosit în viziunea computerizată și în învățarea profundă pentru a practica, dezvolta și evalua clasificarea imaginilor folosind CNN . Printre altele, aceasta include pași pentru evaluarea performanței modelului, explorarea posibilelor îmbunătățiri și utilizarea acestuia pentru a prezice date noi.
USP-ul său este că are deja un set de date de tren și de testare bine definit pe care îl putem folosi. Acest set de antrenament poate fi împărțit în continuare într-un tren și poate valida un set de date dacă este necesar să se evalueze performanța unui model de antrenament. Performanța sa în tren și setul de validare la fiecare cursă pot fi înregistrate ca curbe de învățare pentru o mai bună perspectivă asupra cât de bine învață modelul problema.
Keras, unul dintre cele mai importante API-uri de rețea neuronală, susține acest lucru prin stipularea argumentului „validation_data ” la model. Funcția Fit() atunci când antrenează modelul, care în cele din urmă returnează un obiect care menționează performanța modelului pentru pierderea și metricile la fiecare rulare de antrenament. Din fericire, MNIST este echipat implicit cu Keras, iar fișierele de tren și de testare pot fi încărcate folosind doar câteva linii de cod.
Interesant este că un articol al lui Yann LeCun, profesor la Institutul Courant de Științe Matematice de la Universitatea din New York și Corinna Cortes, cercetător la Google Labs din New York, subliniază că baza de date specială 3 (SD-3) a MNIST a fost inițial atribuită ca un set de antrenament. Baza de date specială 1 (SD-1) a fost desemnată ca set de testare.

Cu toate acestea, ei cred că SD-3 este mult mai ușor de identificat și recunoscut decât SD-1, deoarece SD-3 a fost adunat de la angajații care lucrează în Biroul de Recensământ, în timp ce SD-1 a fost obținut din rândul elevilor de liceu. Deoarece concluziile precise din experimentele de învățare impun că rezultatul trebuie să fie independent de setul de antrenament și de testare, s-a considerat necesar să se dezvolte o nouă bază de date prin lipsa setului de date.
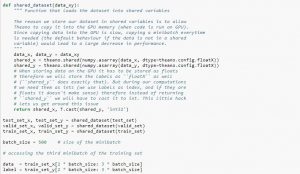
Când utilizați setul de date, este recomandat să îl împărțiți în minibatch, să îl stocați în variabile partajate și să îl accesați pe baza indexului minibatch. S-ar putea să vă întrebați de necesitatea variabilelor partajate, dar acest lucru este legat de utilizarea GPU-ului. Ce se întâmplă este că atunci când copiați date în memoria GPU, dacă copiați fiecare minibatch separat, după cum și când este necesar, codul GPU va încetini și nu va fi mult mai rapid decât codul CPU. Dacă aveți datele dvs. în variabilele partajate Theano, există șanse mari de a copia toate datele pe GPU dintr-o dată când variabilele partajate sunt create.
Ulterior, GPU-ul poate folosi minibatch-ul accesând aceste variabile partajate fără a fi nevoie să copieze informații din memoria CPU. De asemenea, deoarece punctele de date sunt de obicei numere reale și numere întregi etichetate, ar fi bine să folosiți diferite variabile pentru acestea, precum și pentru setul de validare, un set de antrenament și un set de testare, pentru a face codul mai ușor de citit.
Codul de mai jos vă arată cum să stocați date și să accesați un minibatch:
Sursă
2. Setul de date CIFAR-10
CIFAR înseamnă Institutul Canadian pentru Cercetare Avansată, iar setul de date CIFAR-10 a fost dezvoltat de cercetătorii de la institutul CIFAR, împreună cu setul de date CIFAR-100. Setul de date CIFAR-10 constă din 60.000 de imagini color de 32×32 pixeli ale obiectelor aparținând la zece clase precum pisici, nave, păsări, broaște etc. Aceste imagini sunt mult mai mici decât o fotografie medie și sunt destinate vizualizării computerizate.
CIFAR este un set de date bine înțeles, simplu, care este 80% precis în clasificarea imaginilor folosind procesul CNN și 90% în setul de date de testare. De asemenea, până la 1.000 de imagini răspândite într-un lot de testare și cinci loturi de antrenament.
Setul de date CIFAR-10 constă din 1.000 de imagini selectate aleatoriu din fiecare clasă, dar unele loturi pot conține mai multe imagini dintr-o clasă decât alta. Cu toate acestea, loturile de antrenament conțin exact 5.000 de imagini din fiecare clasă. Setul de date CIFAR-10 este preferat pentru ușurința sa de utilizare ca punct de plecare pentru rezolvarea problemelor de clasificare a imaginilor CNN .
Designul cablajului său de testare este modular și poate fi dezvoltat cu cinci elemente care includ încărcarea setului de date, definirea modelului, pregătirea setului de date și evaluarea și prezentarea rezultatelor. Exemplul de mai jos arată setul de date CIFAR-10 folosind API-ul Keras cu primele nouă imagini din setul de date de antrenament:
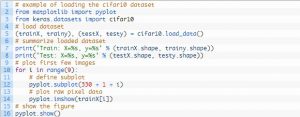
Sursă
Rularea exemplului încarcă setul de date CIFAR-10 și tipărește forma acestora.
3. ImageNet
ImageNet își propune să clasifice și să eticheteze imaginile în aproape 22.000 de categorii bazate pe cuvinte și expresii predefinite. Pentru a face acest lucru, urmează ierarhia WordNet, unde fiecare cuvânt sau expresie este un sinonim sau un synset (pe scurt). În ImageNet, toate imaginile sunt organizate în funcție de aceste synsets, pentru a avea peste o mie de imagini per synset.
Cu toate acestea, când se face referire la ImageNet în viziunea computerizată și învățarea profundă, ceea ce înseamnă de fapt este provocarea de recunoaștere la scară largă ImageNet sau ILSVRC. Scopul aici este de a clasifica o imagine în 1.000 de categorii diferite utilizând peste 100.000 de imagini de testare, deoarece setul de date de antrenament conține aproximativ 1,2 milioane de imagini.
Poate cea mai mare provocare aici este că imaginile din ImageNet măsoară 224×224, astfel încât procesarea unei cantități atât de mari de date necesită o capacitate masivă a CPU, GPU și RAM. Acest lucru s-ar putea dovedi imposibil pentru un laptop obișnuit, așa că cum depășim această problemă?
O modalitate de a face acest lucru este să utilizați Imagenette, un set de date extras din ImageNet care nu necesită prea multe resurse. Acest set de date are două foldere numite „train” (antrenament) și „Val” (validare) cu dosare individuale pentru fiecare clasă. Toate aceste clase au același ID ca și setul de date original, fiecare dintre clase având aproximativ 1.000 de imagini, astfel încât întreaga configurație este destul de echilibrată.
O altă opțiune este folosirea învățării prin transfer, o metodă care utilizează greutăți pre-antrenate pe seturi mari de date. Aceasta este o modalitate foarte eficientă de clasificare a imaginilor folosind CNN , deoarece o putem folosi pentru a produce modele care funcționează bine pentru noi. Singurul aspect pe care ar trebui să-l facă o clasificare a imaginilor folosind modelul CNN este să clasifice imaginile aparținând aceleiași clase și să facă distincția între cele care sunt diferite. Aici putem folosi greutățile pre-antrenate. Avantajul aici este că putem folosi diferite metode în funcție de tipul de set de date cu care lucrăm.
Citește și: Cele 7 tipuri de rețele neuronale artificiale pe care inginerii ML trebuie să le cunoască
Rezumând
Pentru a rezuma, clasificarea imaginilor folosind CNN a făcut procesul mai ușor, mai precis și mai puțin greoi. Dacă doriți să aprofundați în învățarea automată, upGrad are o gamă de cursuri care vă ajută să o stăpâniți ca un profesionist!
upGrad oferă diverse cursuri online cu o gamă largă de subcategorii; vizitați site-ul oficial pentru mai multe informații.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Ce sunt rețelele neuronale convoluționale?
Rețelele neuronale convoluționale (CNN) sau convnet-urile sunt o categorie de rețele neuronale artificiale profunde, cu feed-forward, cel mai frecvent aplicate la analiza imaginilor vizuale. Designul CNN-urilor este vag inspirat de organizarea cortexului vizual al mamiferelor, deși acestea au fost aplicate și la audio, vorbire și alte domenii. CNN-urile folosesc o variație de perceptroni multistrat conceput pentru a necesita preprocesare minimă. Acest lucru le face mai puțin predispuse la erori și mai portabile la un set divers de probleme, dar sacrifică capacitatea de a efectua transformări neliniare asupra intrărilor lor.
De ce sunt rețelele neuronale convoluționale bune pentru clasificarea imaginilor?
Marea limitare a CNN este că nu poate înțelege contextul într-o imagine. De asemenea, nu este capabil să facă fețe și să facă culoare. Mai multe limitări ale CNN: tehnicile de învățare utilizate în rețelele neuronale nu sunt suficiente pentru a reproduce funcții cognitive superioare, cum ar fi recunoașterea obiectelor, învățarea, conștientizarea spațială și capacitatea de a transfera experiența. Arhitectura rețelelor neuronale nu este suficient de flexibilă pentru a depăși aceste limitări.