
Introdução prática à validação e regularização de modelos em Deep Learning usando o TensorFlow
Publicados: 2020-10-28Índice
Introdução
A prática das máquinas de assimilar informações através do paradigma de algoritmos de aprendizagem supervisionada revolucionou diversas tarefas como geração de sequências, processamento de linguagem natural e até visão computacional. Essa abordagem é baseada na utilização de um conjunto de dados que possui um conjunto de recursos de entrada e um conjunto correspondente de rótulos. A máquina então usa essas informações presentes na forma de recursos e rótulos para aprender a distribuição e os padrões dos dados para fazer previsões estatísticas sobre entradas não vistas.
Uma etapa primordial no design de modelos de aprendizado profundo é avaliar o desempenho do modelo, especialmente em pontos de dados novos e não vistos. O objetivo principal é desenvolver modelos que generalizem além dos dados em que foram treinados. Queremos modelos que possam fazer previsões boas e confiáveis no mundo real. Um conceito importante que nos ajuda nisso é a validação e regularização do modelo que abordaremos hoje.
Validação do modelo
Construir um modelo de aprendizado de máquina sempre se resume a dividir os dados disponíveis em três conjuntos: treinamento, validação e conjunto de teste. Os dados de treinamento são usados pelo modelo para aprender as peculiaridades e características da distribuição.
Um ponto focal a saber aqui é que um desempenho satisfatório do modelo no conjunto de treinamento não significa que o modelo também generalizará em novos dados com desempenho semelhante, isso ocorre porque o modelo se tornou tendencioso ao conjunto de treinamento. O conceito de validação e conjunto de teste é, portanto, usado para relatar quão bem o modelo generaliza em novos pontos de dados.
O procedimento padrão é usar os dados de treinamento para ajustar o modelo, avaliar o desempenho do modelo usando os dados de validação e, finalmente, os dados de teste são usados para avaliar o desempenho do modelo em novos exemplos.
O conjunto de validação é usado para ajustar os hiperparâmetros (número de camadas ocultas, taxa de aprendizado, taxa de abandono, etc.) para que o modelo possa generalizar bem. Um enigma comum enfrentado por iniciantes em aprendizado de máquina é entender a necessidade de conjuntos de validação e teste separados.

A necessidade de dois conjuntos distintos pode ser entendida pela seguinte intuição: para cada rede neural profunda que precisa ser projetada, existem vários números de hiperparâmetros que precisam ser ajustados para um desempenho satisfatório.
Vários modelos podem ser treinados usando qualquer um dos hiperparâmetros e, em seguida, o modelo com a melhor métrica de desempenho pode ser selecionado com base no desempenho desse modelo no conjunto de validação. Agora, cada vez que os hiperparâmetros são ajustados para melhor desempenho no conjunto de validação, algumas informações são vazadas/alimentadas no modelo, portanto, os pesos finais da rede neural podem ser tendenciosos para o conjunto de validação.
Após cada ajuste do hiperparâmetro, nosso modelo continua a ter um bom desempenho no conjunto de validação porque foi para isso que o otimizamos. Esta é a razão pela qual o teste de validação não pode denotar com precisão a capacidade de generalização do modelo. Para superar essa desvantagem, o conjunto de teste entra em ação.
A representação mais precisa da capacidade de generalização de um modelo é dada pelo desempenho no conjunto de teste, pois não otimizamos o modelo para melhor desempenho nesse conjunto e, portanto, isso indicará a estimativa mais pragmática da capacidade do modelo.
Deve ler: Principais técnicas de aprendizado profundo que você deve conhecer
Implementando estratégias de validação usando o TensorFlow 2.0
O TensorFlow 2.0 fornece uma solução extremamente fácil para rastrear o desempenho do nosso modelo em um teste de validação separado. Podemos passar o argumento de palavra-chave validation_split no método model.fit() .
A palavra-chave validation_split recebe a entrada como um número flutuante entre 0 e 1, que representa a fração dos dados de treinamento a serem usados como dados de validação. Assim, passar o valor de 0,1 na palavra-chave significa reservar 10% dos dados de treinamento para validação.
A implementação prática da divisão de validação pode ser facilmente demonstrada usando o Diabetes Dataset do sklearn. O conjunto de dados tem 442 instâncias com 10 variáveis de linha de base (idade, sexo, IMC, etc.) como recursos de treinamento e a medida da progressão da doença após um ano como seu rótulo.
Importamos o conjunto de dados usando TensorFlow e sklearn:

O passo fundamental após o pré-processamento de dados é construir uma rede neural de feedforward sequencial com camadas densas:

Aqui, temos uma rede neural com seis camadas ocultas com ativação relu e uma camada de saída com ativação linear .
Em seguida, compilamos o modelo com o otimizador de Adam e a função de perda de erro quadrático médio .


O método model.fit() é então usado para treinar o modelo por 100 épocas com um validation_split de 15%.

Também podemos plotar a perda do modelo conforme observado para os dados de treinamento e os dados de validação:
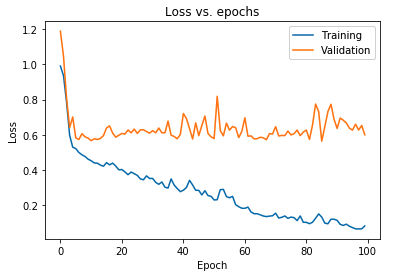
O gráfico exibido acima mostra que a perda de validação aumenta continuamente após 10 épocas, enquanto a perda de treinamento continua a diminuir. Essa tendência é um exemplo clássico de um problema incrivelmente significativo no aprendizado de máquina que é chamado de overfitting .
Muitas pesquisas seminais foram conduzidas para superar esse problema e coletivamente essas soluções são chamadas de técnicas de regularização . A seção a seguir abordará o aspecto da regularização e o procedimento para regularizar qualquer modelo de aprendizado profundo.
Regularizando nosso Modelo
Na seção anterior observamos uma tendência inversa nos gráficos de perda dos conjuntos de treinamento e validação, onde o gráfico da função de custo do último conjunto parece aumentar e o do primeiro conjunto continua diminuindo e, portanto, criando um gap ( gap de generalização ). Saiba mais sobre regularização no aprendizado de máquina.
O fato de existir uma lacuna entre os dois gráficos de perda simboliza que o modelo não pode generalizar bem no conjunto de validação ( dados não vistos) e, portanto, o valor de custo/perda incorrido nesse conjunto de dados também seria inevitavelmente alto.
Essa peculiaridade ocorre porque os pesos e vieses do modelo treinado são co-adaptados para aprender a distribuição dos dados de treinamento tão bem que ele não consegue prever os rótulos de recursos novos e não vistos, levando a uma maior perda de validação.
A lógica é que configurar um modelo complexo produzirá tais anomalias, uma vez que os parâmetros dos modelos crescem e se tornam altamente robustos para os dados de treinamento. Assim, simplificar ou reduzir a capacidade/complexidade dos modelos reduzirá o efeito de overfitting. Uma maneira de conseguir isso é usando dropouts em nosso modelo de aprendizado profundo, que abordaremos na próxima seção.
Entendendo e implementando desistências no TensorFlow
A principal percepção por trás do uso de dropouts é descartar aleatoriamente unidades ocultas e visíveis para obter um modelo menos complexo que restringe o aumento dos parâmetros do modelo e, portanto, torna o modelo mais robusto para desempenho em um conjunto de dados generalizado.
Essa prática recentemente aceita é uma abordagem poderosa usada por praticantes de aprendizado de máquina para induzir um efeito de regularização em qualquer modelo de aprendizado profundo. Os dropouts podem ser implementados sem esforço usando a API Keras sobre o TensorFlow importando a camada dropout e passando o argumento rate nela para especificar a fração de unidades que precisam ser descartadas.
Essas camadas de dropout são geralmente empilhadas logo após cada camada densa para produzir uma maré alternada de uma arquitetura de camada de dropout densa .
Podemos modificar nossa rede neural feedforward definida anteriormente para incluir seis camadas de dropout , uma para cada camada oculta:


Aqui, a taxa de dropout _ foi definida como 0,2, o que significa que 20% dos nós serão descartados durante o treinamento do modelo. Compilamos e treinamos o modelo com o mesmo otimizador, função de perda, métricas e o número de épocas para fazer uma comparação justa.
O impacto primário de regularizar o modelo usando dropouts pode ser interpretado novamente traçando a curva de perda do modelo obtido nos conjuntos de treinamento e validação:
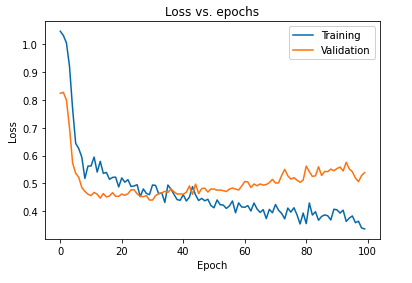
É evidente a partir do gráfico acima que a lacuna de generalização obtida após a regularização do modelo é muito menor, o que torna o modelo menos suscetível a sobreajustar os dados de treinamento.
Leia também: Ideias de projetos de aprendizagem profunda
Conclusão
O aspecto de validação e regularização do modelo é uma parte essencial do design do fluxo de trabalho de construção de qualquer solução de aprendizado de máquina. Muitas pesquisas estão sendo conduzidas para improvisar o aprendizado supervisionado e este tutorial prático fornece uma breve visão de algumas das práticas e técnicas mais aceitas ao montar qualquer algoritmo de aprendizado.
Se você estiver interessado em aprender mais sobre técnicas de aprendizado profundo , aprendizado de máquina, confira a Certificação PG do IIIT-B e do upGrad em aprendizado de máquina e aprendizado profundo, projetada para profissionais que trabalham e oferece mais de 240 horas de treinamento rigoroso, mais de 5 estudos de caso e atribuições, status de ex-alunos do IIIT-B e assistência de trabalho com as principais empresas.