
Praktyczne wprowadzenie do walidacji i regularyzacji modeli w głębokim uczeniu za pomocą TensorFlow
Opublikowany: 2020-10-28Spis treści
Wstęp
Praktyka maszyn do przyswajania informacji poprzez paradygmat nadzorowanych algorytmów uczenia się zrewolucjonizowała kilka zadań, takich jak generowanie sekwencji, przetwarzanie języka naturalnego, a nawet widzenie komputerowe. To podejście opiera się na wykorzystaniu zestawu danych, który ma zestaw funkcji wejściowych i odpowiadający mu zestaw etykiet. Następnie maszyna wykorzystuje te informacje w postaci cech i etykiet, aby poznać rozkład i wzorce danych, aby dokonać statystycznych prognoz na niewidocznych danych wejściowych.
Najważniejszym krokiem w projektowaniu modeli uczenia głębokiego jest ocena wydajności modelu, zwłaszcza w przypadku nowych i niewidocznych punktów danych. Głównym celem jest opracowanie modeli, które uogólniają poza dane, na których zostały przeszkolone. Potrzebujemy modeli, które mogą dokonywać dobrych i wiarygodnych prognoz w rzeczywistym świecie. Ważną koncepcją, która nam w tym pomaga, jest walidacja i regularyzacja modelu, którą omówimy dzisiaj.
Walidacja modelu
Budowanie modelu uczenia maszynowego zawsze sprowadza się do podzielenia dostępnych danych na trzy zestawy: uczący, walidacyjny i testowy. Dane uczące są używane przez model do uczenia się dziwactw i cech dystrybucji.
Kluczowym punktem, o którym należy wiedzieć, jest to, że zadowalająca wydajność modelu w zestawie uczącym nie oznacza, że model będzie również uogólniał nowe dane o podobnej wydajności, ponieważ model stał się stronniczy w stosunku do zestawu uczącego. Koncepcja walidacji i zestawu testowego jest zatem wykorzystywana do raportowania, jak dobrze model generalizuje się na nowych punktach danych.
Standardowa procedura polega na wykorzystaniu danych uczących w celu dopasowania modelu, ocenie wydajności modelu przy użyciu danych walidacyjnych, a na końcu danych testowych używa się do oceny, jak dobrze model będzie działał na zupełnie nowych przykładach.
Zestaw walidacyjny służy do dostrajania hiperparametrów (liczby ukrytych warstw, szybkości uczenia się, szybkości porzucania itd.) , tak aby model mógł dobrze uogólniać. Powszechną zagadką, z którą borykają się nowicjusze w dziedzinie uczenia maszynowego, jest zrozumienie potrzeby oddzielnych zestawów walidacji i testów.

Potrzebę dwóch odrębnych zestawów można zrozumieć dzięki następującej intuicji: dla każdej głębokiej sieci neuronowej, którą należy zaprojektować, istnieje wiele hiperparametrów, które należy dostosować w celu uzyskania zadowalającej wydajności.
Wiele modeli można trenować przy użyciu jednego z hiperparametrów, a następnie model z najlepszą metryką wydajności można wybrać na podstawie wydajności tego modelu w zestawie walidacji. Teraz za każdym razem, gdy hiperparametry są modyfikowane w celu uzyskania lepszej wydajności w zestawie walidacyjnym, niektóre informacje wyciekają/wprowadzane są do modelu, w związku z czym końcowe wagi sieci neuronowej mogą być przesunięte w kierunku zestawu walidacyjnego.
Po każdym dostosowaniu hiperparametru nasz model nadal działa dobrze w zestawie walidacyjnym, ponieważ do tego właśnie go zoptymalizowaliśmy. Jest to powód, dla którego test walidacyjny nie może dokładnie określić zdolności modelu do uogólniania. Aby przezwyciężyć tę wadę, do gry wchodzi zestaw testowy.
Najdokładniejszą reprezentacją zdolności modelu do uogólniania jest wydajność w zestawie testowym, ponieważ nie optymalizowaliśmy modelu pod kątem lepszej wydajności w tym zestawie, a zatem wskaże to najbardziej pragmatyczne oszacowanie zdolności modelu.
Musisz przeczytać: najlepsze techniki głębokiego uczenia się, o których powinieneś wiedzieć
Wdrażanie strategii walidacji przy użyciu TensorFlow 2.0
TensorFlow 2.0 zapewnia niezwykle łatwe rozwiązanie do śledzenia wydajności naszego modelu w osobnym trwającym teście walidacyjnym. Argument słowa kluczowego validation_split możemy przekazać w metodzie model.fit() .
Słowo kluczowe validation_split przyjmuje dane wejściowe jako liczbę zmiennoprzecinkową z zakresu od 0 do 1 , która reprezentuje część danych uczących, które mają być użyte jako dane walidacyjne. Tak więc przekazanie wartości 0,1 w słowie kluczowym oznacza zarezerwowanie 10% danych treningowych do walidacji.
Praktyczną implementację podziału walidacji można łatwo zademonstrować za pomocą zestawu danych dotyczących cukrzycy firmy sklearn. Zestaw danych zawiera 442 instancje z 10 zmiennymi podstawowymi (wiek, płeć, BMI itp.) jako cechy treningowe i miarą postępu choroby po roku jako etykietą.
Importujemy zbiór danych za pomocą TensorFlow i sklearn:

Podstawowym krokiem po wstępnym przetworzeniu danych jest zbudowanie sekwencyjnej sieci neuronowej ze sprzężeniem do przodu z gęstymi warstwami:

Tutaj mamy sieć neuronową z sześcioma warstwami ukrytymi z aktywacją relu i jedną warstwą wyjściową z aktywacją liniową .

Następnie kompilujemy model z optymalizatorem Adama i funkcją utraty błędu średniokwadratowego .

Metoda model.fit() jest następnie używana do trenowania modelu dla 100 epok z walidacją_podziału równą 15%.

Możemy również wykreślić utratę modelu obserwowaną zarówno dla danych uczących, jak i danych walidacyjnych:
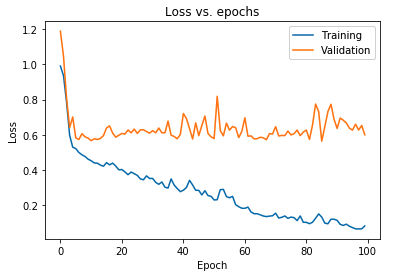
Wykres pokazany powyżej pokazuje, że utrata walidacji stale rośnie po 10 epokach, podczas gdy utrata treningu nadal maleje. Trend ten jest podręcznikowym przykładem niezwykle istotnego problemu w uczeniu maszynowym, jakim jest overfitting .
Przeprowadzono wiele przełomowych badań w celu przezwyciężenia tego problemu i łącznie te rozwiązania nazywane są technikami regularyzacyjnymi . W tej sekcji omówimy aspekt regularyzacji i procedurę regulowania dowolnego modelu głębokiego uczenia się.
Uregulowanie naszego modelu
W poprzedniej części zaobserwowaliśmy odwrotną tendencję na wykresach strat zestawów uczących i walidacyjnych, gdzie wykres funkcji kosztów drugiego zestawu wydaje się rosnąć, a wykres pierwszego zestawu nadal maleje, tworząc w ten sposób lukę ( lukę uogólniającą ). Dowiedz się więcej o regularyzacji w uczeniu maszynowym.
Fakt, że istnieje taka luka między dwoma wykresami strat, symbolizuje, że model nie może dobrze uogólniać zestawu walidacyjnego ( dane niewidoczne) , a zatem wartość kosztów/strat poniesionych na tym zestawie danych również byłaby nieuchronnie wysoka.
Ta osobliwość wynika z tego, że wagi i błędy systematyczne trenowanego modelu są wspólnie dostosowywane do uczenia się dystrybucji danych szkoleniowych tak dobrze, że nie można przewidzieć etykiet nowych i niewidocznych funkcji, co prowadzi do zwiększonej utraty walidacji.
Uzasadnienie jest takie, że skonfigurowanie złożonego modelu spowoduje takie anomalie, ponieważ parametry modeli rosną, stając się wysoce odporne na dane szkoleniowe. W związku z tym uproszczenie lub zmniejszenie pojemności/złożoności modeli zmniejszy efekt nadmiernego dopasowania. Jednym ze sposobów, aby to osiągnąć, jest wykorzystanie rezygnacji w naszym modelu głębokiego uczenia, który omówimy w następnej sekcji.
Zrozumienie i implementacja przerw w pracy w TensorFlow
Kluczową percepcją stojącą za używaniem przerw jest losowe porzucanie ukrytych i widocznych jednostek w celu uzyskania mniej złożonego modelu, który ogranicza wzrost parametrów modelu, a tym samym czyni model bardziej wytrzymałym pod względem wydajności na uogólnionym zbiorze danych.
Ta ostatnio przyjęta praktyka jest potężnym podejściem stosowanym przez praktyków uczenia maszynowego do wywoływania efektu regularyzacji w dowolnym modelu uczenia głębokiego. Porzucenia można bezproblemowo zaimplementować za pomocą interfejsu API Keras przez TensorFlow, importując warstwę porzucania i przekazując w niej argument rate , aby określić ułamek jednostek, które należy porzucić.
Te warstwy odpadające są zwykle układane w stos zaraz po każdej gęstej warstwie, aby wytworzyć naprzemienną falę architektury gęstej warstwy odpadającej.
Możemy zmodyfikować naszą wcześniej zdefiniowaną sieć neuronową feedforward, aby zawierała sześć warstw , po jednej dla każdej warstwy ukrytej:


Tutaj współczynnik dropout _ został ustawiony na 0,2, co oznacza, że 20% węzłów zostanie porzuconych podczas trenowania modelu. Kompilujemy i trenujemy model z tym samym optymalizatorem, funkcją straty, metrykami i liczbą epok, aby dokonać rzetelnego porównania.
Główny wpływ uregulowania modelu za pomocą przerw można zinterpretować, ponownie wykreślając krzywą utraty modelu otrzymanego na zbiorach uczących i walidacyjnych:
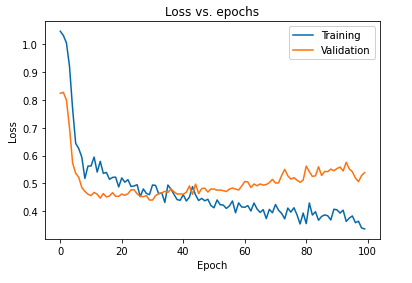
Z powyższego wykresu widać, że luka generalizacji uzyskana po uregulowaniu modelu jest znacznie mniejsza, co sprawia, że model jest mniej podatny na przeuczenie danych uczących.
Przeczytaj także: Pomysły na projekty głębokiego uczenia się
Wniosek
Aspekt walidacji i regularyzacji modelu jest istotną częścią projektowania przepływu pracy przy tworzeniu dowolnego rozwiązania uczenia maszynowego. Prowadzonych jest wiele badań w celu improwizacji nadzorowanego uczenia się, a ten praktyczny samouczek zapewnia krótki wgląd w niektóre z najbardziej akceptowanych praktyk i technik podczas tworzenia dowolnego algorytmu uczenia się.
Jeśli chcesz dowiedzieć się więcej o technikach głębokiego uczenia , uczeniu maszynowym, sprawdź certyfikat PG IIIT-B i upGrad w zakresie uczenia maszynowego i głębokiego uczenia się, który jest przeznaczony dla pracujących profesjonalistów i oferuje ponad 240 godzin rygorystycznych szkoleń, ponad 5 studiów przypadków i zadania, status absolwentów IIIT-B i pomoc w pracy z najlepszymi firmami.