Jak zrównoleglić w Spark Parallel Processing? [Korzystanie z RDD]
Opublikowany: 2020-09-03Generowanie i konsumpcja danych wzrosło n-krotnie w ciągu ostatnich kilku lat. Przy tak wielu platformach, które ożywają, ostrożna obsługa danych i zarządzanie nimi stały się kluczowe. AI (sztuczna inteligencja) i ML (uczenie maszynowe) sprawiają, że nasze cyfrowe doświadczenia są jeszcze płynniejsze, znajdując lepsze rozwiązania naszych problemów. Dlatego firmy zmierzają obecnie w kierunku przetwarzania danych i znajdowania z nich wglądu.
Jednocześnie dane generowane przez firmy, graczy sieciowych i mobilnych gigantów są ogromne. Dzięki temu wprowadzono pojęcie big data. Odkąd pojawiły się big data, narzędzia do zarządzania i manipulowania big data również zaczęły zyskiwać popularność i znaczenie.
Apache Spark to jedno z tych narzędzi, które manipulują i przetwarzają ogromne zbiory danych w celu uzyskania wglądu w te dane. Te duże zbiory danych nie mogą być przetwarzane ani zarządzane w jednym przebiegu, ponieważ wymagana moc obliczeniowa jest zbyt duża.
I tu pojawia się przetwarzanie równoległe. Zaczniemy od zrozumienia przetwarzania równoległego w skrócie, a następnie przejdziemy do zrozumienia, jak zrównoleglać w iskry.
Przeczytaj: Architektura Apache Spark
Spis treści
Co to jest przetwarzanie równoległe?
Przetwarzanie równoległe jest jedną z podstawowych operacji systemu Big Data. Kiedy twoje zadanie jest znaczące, zdarza ci się podzielić na mniejsze zadania, a następnie rozwiązujesz każde z nich niezależnie. Równoległe przetwarzanie dużych zbiorów danych obejmuje ten sam proces.

Z technicznego punktu widzenia przetwarzanie równoległe to metoda uruchamiania dwóch lub więcej części jednego dużego problemu w różnych procesorach. Skraca to czas przetwarzania i poprawia wydajność.
Ponieważ nie możesz wykonywać operacji na dużych zbiorach danych na jednym komputerze, potrzebujesz czegoś bardzo solidnego. Właśnie tam pojawia się paralelizacja w Sparku. Przeprowadzimy Cię teraz przez Spark Parallel Processing i jak zrównoleglać w Spark, aby uzyskać właściwe dane wyjściowe z dużych zestawów danych.
Przetwarzanie równoległe iskry
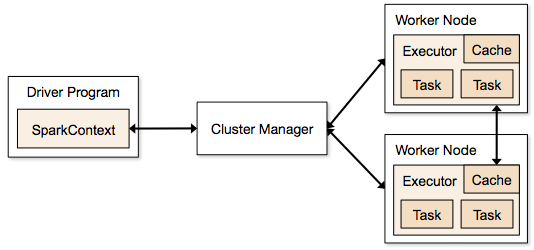
Aplikacje Spark działają w formie niezależnych procesów, które rezydują w klastrach i są koordynowane przez SparkContext w głównym programie.
Pierwszym krokiem w uruchomieniu programu Spark jest przesłanie zadania za pomocą Spark-submit. Skrypt spark-submit służy do uruchamiania programu w klastrze.
Po przesłaniu zadania za pomocą skryptu spark-submit, zadanie jest przekazywane do sterowników sparkcontext. Program sterownika Sparkcontext jest punktem wejścia do platformy Spark. Sparkcontext kieruje program do modułów, takich jak Cluster Master Node i RDD są również tworzone przez te programy sterowników Sparkcontext.
Program jest następnie przekazywany do węzła Cluster Master Node. Każdy klaster ma jeden węzeł główny, który wykonuje wszystkie niezbędne przetwarzanie. Przekazuje program dalej do węzłów roboczych.
Węzeł roboczy to ten, który rozwiązuje problemy. Węzły główne zawierają executory, które są wykonywane ze sterownikiem Sparkcontext.
 Źródło
Źródło
Co to jest elastyczny rozproszony zestaw danych (RDD)?
RDD to podstawowa struktura danych Apache Spark. Ta struktura danych jest niezmienną kolekcją obiektów, które są obliczane w różnych węzłach klastra. Każdy zestaw danych w Spark RDD jest logicznie podzielony na różne serwery, dzięki czemu obliczenia mogą przebiegać płynnie na każdym węźle.

Przyjrzyjmy się RDD nieco bardziej szczegółowo, ponieważ stanowi on podstawę paralelizacji w iskrze. Możemy podzielić nazwę na trzy części i wiedzieć, dlaczego struktura danych została tak nazwana.
- Odporny : oznacza, że struktura danych jest odporna na uszkodzenia dzięki grafowi linii RDD, a zatem może ponownie obliczyć brakujące partycje lub uszkodzone partycje spowodowane awariami węzłów.
- Rozproszony: dotyczy to wszystkich systemów korzystających ze środowiska rozproszonego. Nazywa się to rozproszonym, ponieważ dane są dostępne w różnych/wielu węzłach.
- Zestaw danych: Zestaw danych reprezentuje dane, z którymi pracujesz. Możesz importować dowolne zestawy danych dostępne w dowolnym formacie, takim jak .csv, .json, plik tekstowy lub baza danych. Możesz to zrobić za pomocą JDBC bez określonej struktury.
Po zaimportowaniu lub załadowaniu zestawu danych, RDD logicznie podzielą dane na wiele węzłów na wielu serwerach, aby zapewnić ciągłość działania.
Przeczytaj także: Funkcje Apache Spark
Teraz, gdy znasz RDD, łatwiej będzie Ci zrozumieć przetwarzanie równoległe Spark.
Równolegle w Spark za pomocą RDD
Przetwarzanie równoległe odbywa się w 4 istotnych krokach w Apache Spark. RDD jest używany na głównym poziomie do równoległości w iskry w celu wykonania przetwarzania równoległego.
Krok 1
RDD jest zwykle tworzony z zewnętrznego źródła danych. Może to być plik CSV, plik JSON lub po prostu baza danych. W większości przypadków jest to plik HDFS lub plik lokalny.
Krok 2
Po pierwszym kroku RDD przejdzie przez kilka równoległych przekształceń, takich jak filtr, mapa, groupBy i join. Każda z tych transformacji zapewnia inny RDD, który przechodzi do następnej transformacji.
Zdobądź certyfikat nauk o danych z najlepszych światowych uniwersytetów. Dołącz do naszych programów Executive PG, Advanced Certificate Programs lub Masters, aby przyspieszyć swoją karierę.
Krok 3
Ostatni etap dotyczy działania; zawsze tak jest. Na tym etapie RDD jest eksportowany jako wyjście zewnętrzne do zewnętrznych źródeł danych.

Sprawdź: samouczek Apache Spark dla początkujących
Wniosek
Przetwarzanie równoległe zyskuje popularność wśród entuzjastów danych, ponieważ spostrzeżenia pomagają firmom i OTT zarabiać dużo. Z drugiej strony Spark jest jednym z narzędzi pomagających wielkim gigantom w podejmowaniu decyzji poprzez przetwarzanie równoległe na coraz większych ilościach danych.
Jeśli nie możesz się doczekać przyspieszenia przetwarzania dużych zbiorów danych, Apache Spark to Twoja droga. A RDD w Spark zapewniają najlepszą wydajność, odkąd jest znana.
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.
Ucz się kursów rozwoju oprogramowania online z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.