
Analiza danych za pomocą Pythona [Wszystko, co musisz wiedzieć]
Opublikowany: 2020-09-02Dla każdego, kto chce rozpocząć pracę z analizą danych, pierwszym językiem, który przychodzi na myśl, jest R lub Python. A powodem, dla którego programiści są teraz bardziej skłonni do Pythona, jest jego szerokie możliwości adaptacyjne w ogólnej dziedzinie tworzenia oprogramowania. Dlatego analiza danych za pomocą Pythona jest jednym z najczęściej słyszanych terminów dla osób rozpoczynających swoją podróż do Data Science.
Spis treści
Dlaczego analiza danych?
A teraz po pierwsze, dlaczego analiza danych? Cóż, to pierwszy krok do poznania, z jakim typem danych pracujesz. Jest to krok, w którym znajdujesz wartościowe wzorce w danych, których możesz nie zobaczyć w inny sposób. Ogólnie rzecz biorąc, zapewnia intuicyjne zrozumienie posiadanego zestawu danych.
Tutaj musimy wytyczyć granicę między analizą danych a wstępnym przetwarzaniem danych. Wstępne przetwarzanie danych zajmuje się modelowaniem zestawu danych, aby upewnić się, że jest gotowy do szkolenia. Analiza danych polega na zrozumieniu zestawu danych, co jest wstępnym etapem wstępnego przetwarzania danych. W analizie danych staramy się modelować dane, aby lepiej je zobaczyć, a tym samym poznać wgląd w posiadany zbiór danych.
Dlaczego Python?
Drugie pytanie brzmi: dlaczego Python? Cóż, już stwierdziliśmy, że Python jest szeroko zaadaptowanym językiem. Tak, nie jest to jedyny wybór, jeśli chodzi o analizę danych, ale jest całkiem niezły. Innym powodem jest to, że jest częściej używany! Python jest łatwy i ma dużą społeczność programistów, którzy pomogą Ci w analizie danych przy użyciu Pythona . Co więcej, analiza danych przy użyciu Pythona jest całkiem przyjemna ze względu na dużą liczbę kreatywnych bibliotek, które oferuje do analizy i wizualizacji danych.
W Pythonie podstawową biblioteką do analizy danych jest Pandas. Jest to biblioteka wysokiego poziomu, zbudowana na bibliotece NumPy, która służy do obliczeń naukowych i analiz numerycznych. Pandas ułatwiają pracę z danymi, oferując strukturę danych, znaną jako DataFrame. DataFrame pomaga w odczytywaniu i przechowywaniu zestawu danych. Zapewnia podstawowe funkcje do odczytywania i zapisywania zestawu danych, a także przeglądania metadanych i funkcji zapytań w celu wyodrębnienia wszystkich informacji z zestawu danych.
Należy zauważyć, że wizualizacja danych stanowi znaczną część ogólnej analizy danych. Ponieważ pomaga to nie tylko w lepszym zrozumieniu danych, ale także tym, którym dostarczasz spostrzeżenia. Omówilibyśmy dwie najczęściej używane biblioteki do wizualizacji: Matplotlib i Seaborn. Matplotlib to podstawowa biblioteka dla wszelkich wizualizacji w Pythonie. Seaborn jest również oparty na Matplotlib, który oferuje jedne z najbardziej kreatywnych funkcji wizualizacji danych.
Skonfiguruj środowisko
Pierwszym krokiem jest skonfigurowanie środowiska. Podczas wykonywania analizy danych za pomocą Pythona ważne jest, aby mieć odpowiednie środowisko do przechowywania całej swojej pracy. Analiza danych za pomocą Pythona nie będzie tylko skryptem, ale będzie interakcją Ciebie z zestawem danych, a do tego potrzebujesz odpowiedniego miejsca do pracy.
W Pythonie usługa ta jest świadczona przez dystrybucję Anaconda. Wiodącym miejscem pracy Anacondy jest notatnik Jupyter. Więc teraz dlaczego Jupyter? Cóż, pozwala mieć wizualizacje bezpośrednio w notatniku. Ma również kilka magicznych funkcji, które pozwalają zobaczyć dane wyjściowe bezpośrednio, bez wyraźnego określania, gdzie chcesz.
Biblioteki Pandas i Matplotlib są preinstalowane, a zatem nie jest wymagana dodatkowa konfiguracja do ich używania.
Oto streszczenie tego, jak obejść analizę danych za pomocą Pythona :
- Ładowanie zbioru danych
- Przeglądanie metadanych zbioru danych za pomocą Pandy
- Wizualizacje danych za pomocą Matplotlib
- Zbieranie spostrzeżeń na temat danych
Importuj niezbędne biblioteki
Zanim zaczniemy przyglądać się kodowi kroków, wystarczy zaimportować potrzebne biblioteki z pseudotagami, tak jak w nazwie, którą nazwalibyśmy je dla całego programu.
importuj numer jako np
importuj pandy jako PD
# do wizualizacji danych
importuj matplotlib.pyplot jako plt
importuj seaborn jako sns
Teraz przyjrzymy się każdemu krokowi i omówimy, które funkcje są dostępne i jak z nich korzystać.
Po pierwsze, czytanie zbiorów danych. Pandy zapewniają kilka podstawowych funkcji ładowania zestawu danych do jego podstawowej struktury danych: DataFrame. Możemy go użyć w następujący sposób.
data_df = pd.read_csv('serce.csv')
Wyjściem dowolnej funkcji odczytu będzie DataFrame. Oprócz czytników CSV, pandy udostępniają czytniki prawie wszystkich rodzajów danych. Od HTML do JSON i Excela.
Poza tym, jeśli nie masz żadnych danych jako takich i chcesz utworzyć swój zbiór danych, możesz łatwo użyć funkcji obiektowych Pand Series i DataFrame.
Tak więc, gdy już masz dane pod ręką, przejdźmy do przeglądania, o czym są dane. Aby uzyskać pierwszy widok danych, możesz użyć funkcji takich jak df.info lub df.describe, aby poznać strukturę swojego zbioru danych.
data_df.info()
data_df.opis()
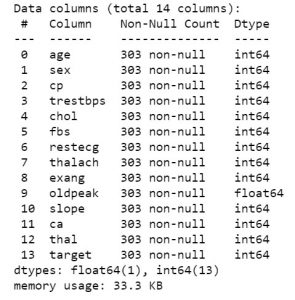
Gdy już wiesz, jakie funkcje zawiera Twój zbiór danych, możesz przyjrzeć się ich wartościom. Możesz użyć funkcji df.head(), aby pobrać pierwsze 5 próbek.
data_df.head()
#lub
data_df.head(3)
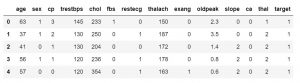
Możesz również określić liczbę próbek, aby zastąpić domyślną wartość 5. Możesz również użyć funkcji df.tail() do pobrania ostatnich 5 wartości zestawu danych.
data_df.tail()
To jest tylko ogólny przegląd tego, jak mogą wyglądać Twoje dane. Gdy będziesz gotowy, możesz rozpocząć główne zadania wizualizacji danych, używając Matplotlib. Przebij następujący kod, aby drukowanie było interaktywne i wyświetlało je w samym notatniku.
%matplotlib wbudowany
Zobaczylibyśmy funkcjonalności 5 najlepszych wizualizacji w matplotlib. Zanim przejdziemy do tego, powinniśmy poznać kilka innych funkcji, które kontrolują nasze działki. Funkcje takie jak:
- Etykiety: xlabel(), ylabel(). Są one przeznaczone dla etykiet na osi X i Y.
- Legenda: Służy do tworzenia legendy dla fabuły.
- Tytuł: Aby nadać tytuł swojej działce
- I na koniec pokaż funkcję, aby wyświetlić fabułę.
Zamówienie: wynagrodzenie analityka danych w Indiach
Wizualizacje
Zobaczmy teraz wizualizacje. Zaczęlibyśmy od podstawowej fabuły. Funkcja plt.plot() służy do generowania prostego wykresu liniowego dla danych. Funkcja wymaga przymusu dwóch parametrów, a są to dane z osi x i dane z osi y. Opcjonalnie możesz podać style, nazwę i kolor wykresu. Oto jak to wygląda w kodzie.
plt.plot(data_df['chol'])
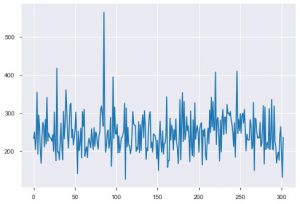
Drugi wykres to histogram. Histogram pomaga wyświetlić częstotliwość lub rozkład określonej funkcji. Pomaga ci zobaczyć, jak wielkości odnoszą się do siebie. Plt.hist() to podstawowa funkcja do tworzenia histogramu na twoich danych. Możesz wspomnieć o parametrze bins, aby kontrolować liczbę na działce. Wystarczy przekazać dane jednej osi, jeśli chcesz przeprowadzić analizę jednowymiarową.
plt.hist(data_df['wiek'])
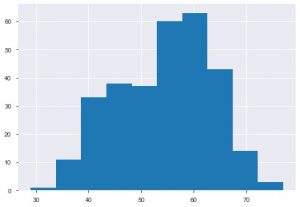

Inną fabułą, którą często byś widział, jest fabuła barowa. Pomaga w analizowaniu i porównywaniu różnych funkcji. W przeciwieństwie do histogramów wykresy słupkowe służą do pracy z danymi kategorialnymi.
Możesz bezpośrednio zastosować wykres w DataFrame lub możesz określić parametry wewnątrz funkcji plt.bar(). Oto jak go używamy.
df = pd.DataFrame(np.random.rand(15, 5), kolumny=['t1', 't2', 't3', 't4', 't5'])
df.wykres.bar()
Możesz również użyć wykresu słupkowego w poziomie, używając funkcji barh().
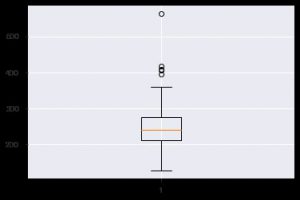
Innym wnikliwym wykresem jest wykres pudełkowy. Pomaga w zrozumieniu rozkładu wartości w ramach każdej cechy. Możesz użyć funkcji plt.boxplot(), aby określić dane, na podstawie których chcesz wygenerować wykres pudełkowy. Wykres jest szczególnie przydatny, gdy trzeba szybko wyświetlić rozproszenie w zestawie danych lub skośność. Oto jak możesz z niego korzystać.
plt.boxplot(data_df['chol'])
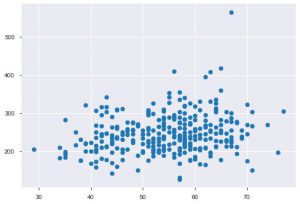
Za każdym razem, gdy pracujesz z danymi statystycznymi, na pewno zobaczysz wykres punktowy. Wykres punktowy pomaga w obserwowaniu relacji między dwiema cechami. Wykres wymaga wartości liczbowych zarówno dla danych osi x, jak i osi y. Możesz po prostu podać te dwie wartości w funkcji plt.scatter() lub zastosować bezpośrednio w DataFrame, określając nazwy kolumn w atrybutach x i y. Oto jak możesz tego użyć:
plt.scatter(dane_df['wiek'], dane_df['chol'])
Teraz jest odpowiedni moment, aby przedstawić Wam funkcje Seaborn. Wykres punktowy w seaborn jest bardziej intuicyjny niż matplotlib, ponieważ domyślnie zapewnia linię regresji na wykresie, aby lepiej zwizualizować wykres. Do wykonania tego wykresu można użyć funkcji sns.lmplot().
sns.lmplot('wiek', 'chol', data=data_df)
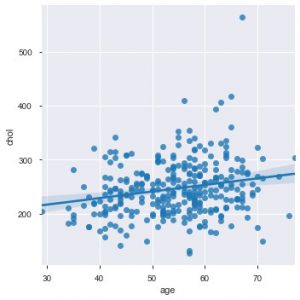
Jak widać na powyższym wykresie, linia regresji pomaga jeszcze lepiej zrozumieć rozkład.
Kolejnym ulepszeniem przy użyciu seaborna jest fabuła roju. Służy do rysowania kategorycznego wykresu rozrzutu. Jedną z zalet wykresu roju w porównaniu z podobnym wykresem paskowym jest to, że wykorzystuje tylko punkty, które nie nakładają się. Jest to więc czystsza fabuła, a zatem daje lepszy wgląd.
sns.swarmplot(dane_df['wiek'], dane_df['chol'])
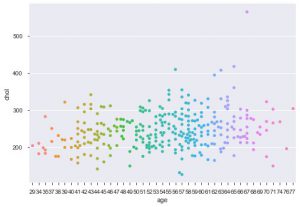
Są to więc różne rodzaje działek w Matplotlib i Seaborn. To tylko wierzchołek góry lodowej, a istnieją setki innych sposobów kreślenia danych w celu wydobycia kreatywnych spostrzeżeń na ich temat.
Teraz, gdy znasz wykresy, pozwól nam zobaczyć, jak przeprowadzić rzeczywistą analizę danych za pomocą Pythona . Przyjrzyjmy się kilku wykresom i zobaczmy, co pokazują nam na temat analizy danych za pomocą Pythona .
Zaczynajmy.
Po załadowaniu danych pierwszą rzeczą, którą robi teraz każdy analityk danych, jest utworzenie profilu pandy. Teraz można to również wyświetlić jako skrót, ale jeśli chcesz zobaczyć wszystkie relacje, liczebności i histogramy zmiennych w zestawie danych, możesz użyć profilowania pand. Jest bardzo łatwy do wygenerowania, wystarczy pobrać moduł profilowania pandy i wbić następujący kod:
importuj pandy_profiling
profil = pandas_profiling.ProfileReport(data_df)
profil
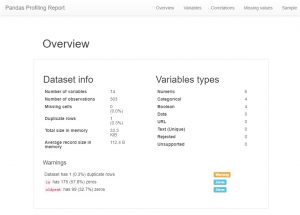
Jak widać, istnieje ogromna ilość informacji o metadanych, a także informacje o poszczególnych funkcjach. Mogłoby to doprowadzić do wielkiego zrozumienia.
Drugą rzeczą, którą możemy zrobić, to wygenerować mapę cieplną. Teraz mapa cieplna pokazuje korelację każdej funkcji z drugą. A jeśli znajdziemy wartość z wyższą korelacją, oznacza to, że te dwie cechy są bardzo do siebie podobne. Możemy więc porzucić jedną z funkcji, a mimo to model będzie działał dobrze.
sns.heatmap(data_df.corr(), annot = True , cmap='Pomarańcze')
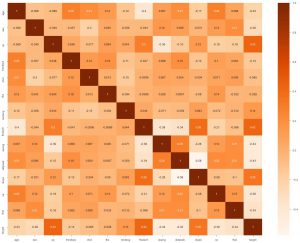
Tutaj widzimy, że żadne z nich nie są silnie powiązane, więc możemy powiedzieć inżynierowi modelu, że potrzebujemy wszystkich funkcji jako danych wejściowych.
Możemy zobaczyć, jaki jest rozkład wieku, ponieważ mamy do czynienia ze zbiorem danych dotyczących chorób serca, zobaczmy rozkład, abyśmy mogli użyć wykresu dystalnego urodzonych w morzu.
sns.distplot(data_df['wiek'], kolor = 'cyjan')
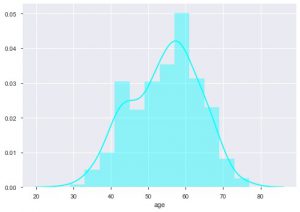
Z fabuły można powiedzieć, że większość osób cierpiących na choroby serca jest w wieku od 50 do 60 lat. W ten sam sposób możemy również zobaczyć kilka innych ważnych cech, takich jak spoczynkowe ciśnienie krwi, które jest oznaczane przez tresbps. Możemy wykonać wykres pudełkowy, aby zobaczyć rozkład w porównaniu z wartością docelową, czyli 0 i 1.
sns.boxplot(data_df['target'], data_df['trestbps'], palette = 'zmierzch')
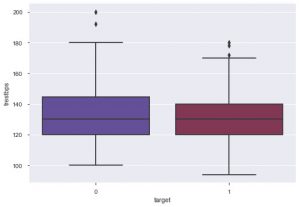
Z wykresu możemy wywnioskować, że jeśli dana osoba ma niższą wartość tres bps, to szanse na chorobę serca są mniejsze niż osoby z wyższą wartością tres bps.
W ten sam sposób możemy również zobaczyć związek z poziomem cholesterolu. Widzimy, że ludzie z niższym poziomem cholesterolu mają mniejsze ryzyko zachorowania na choroby serca.
Możesz udokumentować wszystkie te spostrzeżenia i przekazać je inżynierowi uczenia maszynowego, który może wykorzystać je do stworzenia wydajnego modelu.
Wniosek
W ten sposób możesz przeprowadzić analizę danych za pomocą Pythona . To dopiero pierwszy krok na drodze do nauki o danych. Aby dowiedzieć się więcej o wydobywaniu kreatywnych spostrzeżeń z danych i ogólnej analizy danych, przejdź do kursów oferowanych przez upGrad tutaj . Znajdziesz szereg pomocnych kursów, które skutecznie poprowadzą analizę danych za pomocą Pythona.
Ucz się kursów nauki o danych z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Jak mam zacząć uczyć się Pythona do analizy danych?
Jeśli jesteś na ścieżce do nauki Pythona do analizy danych, to jesteś we właściwym miejscu. Aby uprościć proces uczenia się, musisz postępować krok po kroku. Oto jak wygląda proces:
1. Wyjaśnij cel nauki Pythona i sposób, w jaki będziesz mógł go używać w swojej dziedzinie.
2. Pobierz wymagany terminal Pythona i zainstaluj go w swoim systemie.
3. Rozpocznij naukę podstaw Pythona, biorąc udział w różnych kursach i zapoznając się z różnymi bibliotekami Pythona.
4.Zapoznaj się z wyrażeniami regularnymi używanymi w Pythonie.
5. Przejdź do zdobycia dogłębnej wiedzy na temat różnych bibliotek Pythona, takich jak Pandas, NumPy, Matplotlib i SciPy.
6. Zacznij uczyć się koncepcji analizy danych i tego, jak zintegrować z nim Pythona.
7. Teraz musisz tylko ćwiczyć różne narzędzia i techniki, aby stać się lepszym w Pythonie do analizy danych. Przechodząc przez to podejście krok po kroku, łatwo nauczysz się Pythona i staniesz się lepszy w pracy z analizą danych.
W jaki sposób Python jest używany do analizy danych?
Wiadomo, że Python jest bardzo ważnym źródłem analizy danych. Python pomaga na różne sposoby w przeprowadzaniu analizy danych. Ale wcześniej musisz przygotować dane do analizy, przeprowadzić analizę statystyczną, stworzyć wizualizacje danych, które mogą zapewnić pewien wgląd, przewidzieć przyszłe trendy na podstawie dostępnych danych i wiele więcej.
Stwierdzono, że Python jest kluczowym elementem analizy danych, ponieważ pomaga w:
1. Importowanie zbiorów danych
2. Oczyszczanie i przygotowywanie danych do analizy
3. Manipulowanie ramką danych Pandas
4. Podsumowanie zbiorów danych
5. Opracowanie modelu uczenia maszynowego do analizy danych w Pythonie
Czy mogę nauczyć się Pythona w miesiąc?
Tak, na pewno możesz to osiągnąć, jeśli jesteś biegły w innych językach programowania, takich jak Java, C, C++ itp. Jeśli Twoja podstawa jest jasna, nauczenie się Pythona będzie całkiem łatwe nawet w ciągu jednego miesiąca. Poza tym, jeśli włożysz wysiłek i zastosujesz podejście krok po kroku w zdyscyplinowany sposób, możesz nauczyć się Pythona w miesiąc, nawet jeśli nie masz wcześniejszej znajomości innych języków programowania. Wystarczy ustalić harmonogram i poświęcić się nauce Pythona w ciągu miesiąca.