Wie wird in Spark Parallel Processing parallelisiert? [Mit RDD]
Veröffentlicht: 2020-09-03Datenerzeugung und -verbrauch haben sich in den letzten Jahren vervielfacht. Da so viele Plattformen zum Leben erweckt werden, ist der sorgfältige Umgang und die Verwaltung von Daten von entscheidender Bedeutung. KI (Künstliche Intelligenz) und ML (Maschinelles Lernen) machen unsere digitalen Erfahrungen noch reibungsloser, indem sie bessere Lösungen für unsere Probleme finden. Daher gehen Unternehmen jetzt dazu über, Daten zu verarbeiten und daraus Erkenntnisse zu gewinnen.
Gleichzeitig sind die Datenmengen, die von Unternehmen, Netzwerkplayern und Mobilfunkgiganten generiert werden, enorm. Aus diesem Grund wurde das Konzept von Big Data eingeführt. Seit Big Data ins Bild kam, gewannen auch die Tools zur Verwaltung und Bearbeitung von Big Data an Popularität und Bedeutung.
Apache Spark ist eines dieser Tools, das riesige Datensätze manipuliert und verarbeitet, um Erkenntnisse aus diesen Daten zu gewinnen. Diese großen Datensätze können nicht in einem einzigen Durchgang verarbeitet oder verwaltet werden, da die erforderliche Rechenleistung zu hoch ist.
Hier kommt die Parallelverarbeitung ins Spiel. Wir beginnen damit, die Parallelverarbeitung kurz zu verstehen, und fahren dann fort, um zu verstehen, wie man in Spark parallelisiert.
Lesen Sie: Apache Spark-Architektur
Inhaltsverzeichnis
Was ist Parallelverarbeitung?
Parallelverarbeitung ist eine der wesentlichen Operationen eines Big-Data-Systems. Wenn Ihre Aufgabe wichtig ist, teilen Sie sie zufällig in kleinere Aufgaben auf und lösen sie dann unabhängig voneinander. Die parallele Verarbeitung von Big Data beinhaltet den gleichen Prozess.

Technisch gesehen ist die Parallelverarbeitung eine Methode, bei der zwei oder mehr Teile eines einzigen großen Problems in verschiedenen Prozessoren ausgeführt werden. Dies reduziert die Verarbeitungszeit und verbessert die Leistung.
Da Sie Operationen mit großen Datensätzen nicht auf einem Computer ausführen können, benötigen Sie etwas sehr Solides. Genau hier kommt die Parallelisierung in Spark ins Spiel. Wir führen Sie nun durch Spark Parallel Processing und wie Sie in Spark parallelisieren, um die richtige Ausgabe aus großen Datensätzen zu erhalten.
Spark-Parallelverarbeitung
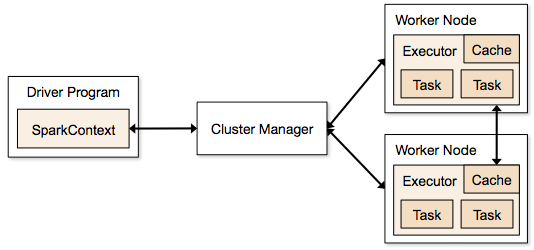
Spark-Anwendungen werden in Form von unabhängigen Prozessen ausgeführt, die sich auf Clustern befinden und von SparkContext im Hauptprogramm koordiniert werden.
Der erste Schritt beim Ausführen eines Spark-Programms besteht darin, den Job mit Spark-submit zu übermitteln. Das Spark-Submit-Skript wird verwendet, um das Programm auf einem Cluster zu starten.
Nachdem Sie den Job mit einem Spark-Submit-Skript übermittelt haben, wird der Job an die Sparkcontext-Treiber weitergeleitet. Das Sparkcontext-Treiberprogramm ist der Einstiegspunkt für Spark. Sparkcontext leitet das Programm an die Module wie Cluster Master Node und RDDs werden ebenfalls von diesen Sparkcontext-Treiberprogrammen erstellt.
Das Programm wird dann an den Cluster Master Node übergeben. Jeder Cluster hat einen Master-Knoten, der alle notwendigen Verarbeitungen durchführt. Er leitet das Programm weiter an Worker-Knoten.
Der Worker-Knoten ist derjenige, der die Probleme löst. Master-Knoten enthalten Executoren, die mit dem Sparkcontext-Treiber ausgeführt werden.
 Quelle
Quelle
Was ist Resilient Distributed Dataset (RDD)?
RDD ist die grundlegende Datenstruktur von Apache Spark. Diese Datenstruktur ist eine unveränderliche Sammlung von Objekten, die auf verschiedenen Knoten eines Clusters rechnen. Jeder Datensatz in Spark RDD ist logisch auf verschiedene Server partitioniert, sodass die Berechnungen auf jedem Knoten reibungslos ausgeführt werden können.

Lassen Sie uns RDD etwas genauer verstehen, da es die Grundlage der Parallelisierung in Spark bildet. Wir können den Namen in drei Teile aufteilen und wissen, warum die Datenstruktur so heißt.
- Belastbar : Dies bedeutet, dass die Datenstruktur mit Hilfe des RDD-Herkunftsdiagramms fehlertolerant ist und daher die fehlenden Partitionen oder beschädigten Partitionen, die aufgrund von Knotenausfällen verursacht wurden, neu berechnen kann.
- Verteilt: Dies gilt für alle Systeme, die eine verteilte Umgebung verwenden. Es wird als verteilt bezeichnet, weil Daten auf verschiedenen/mehreren Knoten verfügbar sind.
- Dataset: Dataset stellt die Daten dar, mit denen Sie arbeiten. Sie können alle Datensätze importieren, die in jedem Format wie .csv, .json, einer Textdatei oder einer Datenbank verfügbar sind. Sie können dies tun, indem Sie JDBC ohne spezifische Struktur verwenden.
Nachdem Sie Ihren Datensatz importiert oder geladen haben, partitionieren die RDDs Ihre Daten logisch in mehrere Knoten auf vielen Servern, um den Vorgang am Laufen zu halten.
Lesen Sie auch: Apache Spark-Funktionen
Jetzt, da Sie RDD kennen, wird es Ihnen leichter fallen, Spark Parallel Processing zu verstehen.
Parallelisieren in Spark mit RDD
Die Parallelverarbeitung erfolgt in Apache Spark in 4 wesentlichen Schritten. RDD wird auf einer großen Ebene verwendet, um in Spark zu parallelisieren, um eine parallele Verarbeitung durchzuführen.
Schritt 1
RDD wird normalerweise aus einer externen Datenquelle erstellt. Dabei kann es sich um eine CSV-Datei, eine JSON-Datei oder einfach um eine Datenbank handeln. In den meisten Fällen handelt es sich um ein HDFS oder eine lokale Datei.
Schritt 2
Nach dem ersten Schritt durchläuft RDD einige parallele Transformationen wie filter, map, groupBy und join. Jede dieser Transformationen stellt eine andere RDD bereit, die zur nächsten Transformation übergeht.
Erwerben Sie eine Data-Science-Zertifizierung von den besten Universitäten der Welt. Nehmen Sie an unseren Executive PG-Programmen, Advanced Certificate Programs oder Masters-Programmen teil, um Ihre Karriere zu beschleunigen.
Schritt 3
In der letzten Phase geht es um Aktion; es ist immer. Das RDD wird in dieser Phase als externe Ausgabe an externe Datenquellen exportiert.

Schauen Sie sich das an: Apache Spark-Tutorial für Anfänger
Fazit
Die parallele Verarbeitung wird bei Datenbegeisterten immer beliebter, da die Erkenntnisse Unternehmen und OTTs dabei helfen, große Gewinne zu erzielen. Spark hingegen ist eines der Tools, das großen Giganten hilft, Entscheidungen zu treffen, indem es eine parallele Verarbeitung von immer größeren Datenmengen durchführt.
Wenn Sie sich darauf freuen, die Verarbeitung großer Datenmengen zu beschleunigen, ist Apache Spark genau das Richtige für Sie. Und RDDs in Spark liefern die beste Leistung, seit es bekannt ist.
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.
Lernen Sie Softwareentwicklungskurse online von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.