Como paralelizar no processamento paralelo do Spark? [Usando RDD]
Publicados: 2020-09-03A geração e o consumo de dados aumentaram n vezes nos últimos anos. Com tantas plataformas ganhando vida, o manuseio e gerenciamento de dados cuidadosamente se tornaram cruciais. AI (Inteligência Artificial) e ML (Machine Learning) estão tornando nossas experiências digitais ainda mais suaves ao encontrar melhores soluções para nossos problemas. Portanto, as empresas estão agora se movendo no sentido de tratar dados e encontrar insights a partir deles.
Simultaneamente, os dados gerados por empresas, players de rede e gigantes móveis são enormes. Devido a isso, o conceito de big data foi introduzido. Desde que big data entrou em cena, as ferramentas para gerenciar e manipular big data também começaram a ganhar popularidade e importância.
O Apache Spark é uma daquelas ferramentas que manipulam e processam grandes conjuntos de dados para obter insights desses dados. Esses grandes conjuntos de dados não podem ser processados ou gerenciados em uma única passagem, pois o poder computacional necessário é muito intenso.
É aí que o processamento paralelo entra em cena. Começaremos entendendo o processamento paralelo em resumo e, em seguida, avançaremos para entender como paralelizar no spark.
Leia: Arquitetura Apache Spark
Índice
O que é processamento paralelo?
O processamento paralelo é uma das operações essenciais de um sistema de big data. Quando sua tarefa é significativa, você divide em tarefas menores e depois resolve cada uma de forma independente. O processamento paralelo de big data envolve o mesmo processo.

Tecnicamente falando, o processamento paralelo é um método de executar duas ou mais partes de um único grande problema em diferentes processadores. Isso reduz o tempo de processamento e melhora o desempenho.
Como você não pode executar operações em grandes conjuntos de dados em uma máquina, você precisa de algo muito sólido. É exatamente aí que o paralelismo no Spark entra em cena. Agora, vamos guiá-lo pelo processamento paralelo do Spark e como paralelizar no Spark para obter a saída certa de grandes conjuntos de dados.
Processamento paralelo de faísca
Os aplicativos Spark são executados na forma de processos independentes que residem em clusters e são coordenados pelo SparkContext no programa principal.
A primeira etapa na execução de um programa Spark é enviar o trabalho usando o Spark-submit. O script spark-submit é usado para iniciar o programa em um cluster.
Depois de enviar o trabalho usando um script spark-submit, o trabalho é encaminhado para os drivers sparkcontext. O programa de driver Sparkcontext é o ponto de entrada para o Spark. O Sparkcontext roteia o programa para os módulos como Cluster Master Node e RDDs também são criados por esses programas de driver Sparkcontext.
O programa é então entregue ao Cluster Master Node. Cada cluster possui um nó mestre que realiza todo o processamento necessário. Ele encaminha o programa ainda mais para nós de trabalho.
O nó trabalhador é aquele que resolve os problemas. Os nós mestres contêm executores que executam com o driver Sparkcontext.
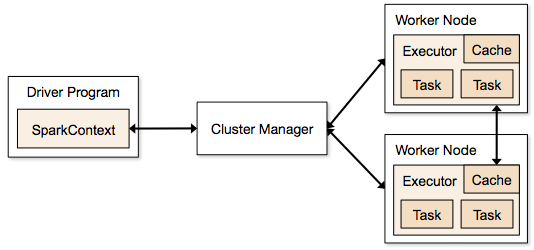 Fonte
Fonte
O que é um conjunto de dados distribuído resiliente (RDD)?
RDD é a estrutura de dados fundamental do Apache Spark. Essa estrutura de dados é uma coleção imutável de objetos que computam em diferentes nós de um cluster. Cada conjunto de dados no Spark RDD é particionado logicamente em vários servidores para que os cálculos possam ser executados sem problemas em cada nó.

Vamos entender o RDD com um pouco mais de detalhes, pois ele forma a base do paralelismo no spark. Podemos dividir o nome em três partes e saber por que a estrutura de dados recebe esse nome.
- Resiliente : significa que a estrutura de dados é tolerante a falhas com a ajuda do gráfico de linhagem RDD e, portanto, pode recalcular as partições ausentes ou danificadas causadas por falhas de nó.
- Distribuído: Isso vale para todos os sistemas que usam um ambiente distribuído. É chamado de distribuído porque os dados estão disponíveis em nós diferentes/múltiplos.
- Conjunto de dados: o conjunto de dados representa os dados com os quais você trabalha. Você pode importar qualquer um dos conjuntos de dados disponíveis em qualquer formato, como .csv, .json, um arquivo de texto ou um banco de dados. Você pode fazer isso usando JDBC sem estrutura específica.
Depois de importar ou carregar seu conjunto de dados, os RDDs particionarão logicamente seus dados em vários nós em vários servidores, para manter a operação em execução.
Leia também: Recursos do Apache Spark
Agora que você conhece o RDD, será mais fácil entender o processamento paralelo do Spark.
Paralelizar no Spark usando RDD
O processamento paralelo é realizado em 4 etapas significativas no Apache Spark. O RDD é usado em um nível principal para paralelizar no Spark para executar o processamento paralelo.
Passo 1
O RDD geralmente é criado a partir de uma fonte de dados externa. Pode ser um arquivo CSV, arquivo JSON ou simplesmente um banco de dados. Na maioria dos casos, é um HDFS ou um arquivo local.
Passo 2
Após a primeira etapa, o RDD passaria por algumas transformações paralelas, como filtro, mapa, groupBy e join. Cada uma dessas transformações fornece um RDD diferente que avança para a próxima transformação.
Obtenha a certificação em ciência de dados das melhores universidades do mundo. Junte-se aos nossos Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
etapa 3
A última etapa é sobre ação; sempre é. O RDD, neste estágio, é exportado como uma saída externa para fontes de dados externas.

Confira: Tutorial do Apache Spark para iniciantes
Conclusão
O processamento paralelo está ganhando popularidade entre os entusiastas de dados, pois os insights estão ajudando empresas e OTTs a ganhar muito. O Spark, por outro lado, é uma das ferramentas que ajudam os grandes gigantes a tomar decisões, realizando processamento paralelo em dados cada vez maiores.
Se você está ansioso para tornar o processamento de big data mais rápido, o Apache Spark é o caminho a seguir. E os RDDs no Spark estão oferecendo o melhor desempenho desde que são conhecidos.
Se você estiver interessado em saber mais sobre Big Data, confira nosso programa PG Diploma in Software Development Specialization in Big Data, projetado para profissionais que trabalham e fornece mais de 7 estudos de caso e projetos, abrange 14 linguagens e ferramentas de programação, práticas práticas workshops, mais de 400 horas de aprendizado rigoroso e assistência para colocação de emprego com as principais empresas.
Aprenda cursos de desenvolvimento de software online das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.