Spark並列処理で並列化する方法は? [RDDを使用]
公開: 2020-09-03データの生成と消費は、過去数年間でn倍に増加しています。 非常に多くのプラットフォームが実現するにつれ、データの慎重な処理と管理が重要になっています。 AI(人工知能)とML(機械学習)は、問題のより良い解決策を見つけることで、デジタル体験をさらにスムーズにします。 したがって、企業は現在、データの処理とそこからの洞察の発見に向かっています。
同時に、企業、ネットワークプレーヤー、モバイルの巨人によって生成されたデータは膨大です。 そのため、ビッグデータの概念が導入されました。 ビッグデータが登場して以来、ビッグデータを管理および操作するためのツールも人気と重要性を増し始めました。
Apache Sparkは、大量のデータセットを操作および処理して、これらのデータから洞察を得るツールの1つです。 これらの大きなデータセットは、必要な計算能力が高すぎるため、1回のパスで処理または管理することはできません。
そこで、並列処理が登場します。 簡単に並列処理を理解することから始め、次にスパークで並列化する方法を理解することに移ります。
読む:ApacheSparkアーキテクチャ
目次
並列処理とは何ですか?
並列処理は、ビッグデータシステムの重要な操作の1つです。 あなたの仕事が重要であるとき、あなたはたまたま小さな仕事に分かれて、それからそれぞれを独立して解決します。 ビッグデータの並列処理には同じプロセスが含まれます。

技術的に言えば、並列処理は、異なるプロセッサで1つの大きな問題の2つ以上の部分を実行する方法です。 これにより、処理時間が短縮され、パフォーマンスが向上します。
1台のマシンで大きなデータセットに対して操作を実行することはできないため、非常に堅固なものが必要です。 ここで、Sparkでの並列化が重要になります。 ここでは、Spark並列処理と、Sparkで並列化して大きなデータセットから適切な出力を取得する方法について説明します。
Spark並列処理
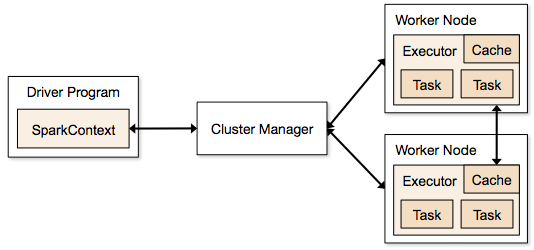
Sparkアプリケーションは、クラスター上に存在し、メインプログラムのSparkContextによって調整される独立したプロセスの形式で実行されます。
Sparkプログラムを実行する最初のステップは、Spark-submitを使用してジョブを送信することです。 spark-submitスクリプトは、クラスターでプログラムを起動するために使用されます。
spark-submitスクリプトを使用してジョブを送信すると、ジョブはsparkcontextドライバーに転送されます。 Sparkcontextドライバープログラムは、Sparkへのエントリポイントです。 Sparkcontextはプログラムをクラスターマスターノードなどのモジュールにルーティングし、RDDもこれらのSparkcontextドライバープログラムによって作成されます。
次に、プログラムはクラスターマスターノードに渡されます。 すべてのクラスターには、必要なすべての処理を実行する1つのマスターノードがあります。 プログラムをさらにワーカーノードに転送します。
ワーカーノードは、問題を解決するノードです。 マスターノードには、Sparkcontextドライバーで実行されるエグゼキューターが含まれています。
 ソース
ソース
復元力のある分散データセット(RDD)とは何ですか?
RDDは、ApacheSparkの基本的なデータ構造です。 このデータ構造は、クラスターのさまざまなノードで計算されるオブジェクトの不変のコレクションです。 Spark RDDのすべてのデータセットは、さまざまなサーバー間で論理的に分割されているため、各ノードで計算をスムーズに実行できます。

RDDは、スパークでの並列化の基礎を形成するため、もう少し詳しく理解しましょう。 名前を3つの部分に分割して、データ構造にそのように名前が付けられている理由を知ることができます。
- 復元力:RDDリネージグラフを使用してデータ構造にフォールトトレラントがあることを意味します。したがって、ノードの障害が原因で発生した欠落したパーティションまたは損傷したパーティションを再計算できます。
- 分散:これは、分散環境を使用するすべてのシステムに当てはまります。 データが異なる/複数のノードで利用できるため、分散と呼ばれます。
- データセット:データセットは、使用するデータを表します。 .csv、.json、テキストファイル、データベースなど、任意の形式で利用可能な任意のデータセットをインポートできます。 これは、特定の構造を持たないJDBCを使用して行うことができます。
データセットをインポートまたはロードすると、RDDはデータを論理的に多数のサーバー上の複数のノードに分割し、操作を実行し続けます。
また読む:ApacheSparkの機能
RDDについて理解したので、Spark並列処理を理解しやすくなります。
RDDを使用したSparkでの並列化
並列処理は、ApacheSparkの4つの重要なステップで実行されます。 RDDは、並列処理を実行するためにスパークで並列化するためにメジャーレベルで使用されます。
ステップ1
RDDは通常、外部データソースから作成されます。 それは、CSVファイル、JSONファイル、または単にデータベースである可能性があります。 ほとんどの場合、これはHDFSまたはローカルファイルです。
ステップ2
最初のステップの後、RDDは、filter、map、groupBy、joinなどのいくつかの並列変換を実行します。 これらの各変換は、次の変換に進む異なるRDDを提供します。
世界のトップ大学からデータサイエンス認定を取得します。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムに参加して、キャリアを早めに進めましょう。
ステップ3
最後の段階は行動についてです。 いつもそうです。 この段階では、RDDは外部出力として外部データソースにエクスポートされます。

チェックアウト:初心者向けのApacheSparkチュートリアル
結論
並列処理は、洞察が企業やOTTの収益に貢献しているため、データ愛好家の間で人気が高まっています。 一方、Sparkは、ビッグデータとビッグデータに対して並列処理を実行することにより、ビッグジャイアントが意思決定を行うのを支援するツールの1つです。
ビッグデータ処理を高速化することを楽しみにしている場合は、ApacheSparkが最適です。 そして、SparkのRDDは、それが知られているので、これまでで最高のパフォーマンスを提供しています。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。
世界のトップ大学からオンラインでソフトウェア開発コースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。