Bagaimana Memparalelkan dalam Pemrosesan Paralel Spark? [Menggunakan RDD]
Diterbitkan: 2020-09-03Pembuatan dan konsumsi data telah meningkat n kali lipat selama beberapa tahun terakhir. Dengan begitu banyak platform menjadi hidup, penanganan dan pengelolaan data dengan hati-hati menjadi sangat penting. AI (Kecerdasan Buatan) dan ML (Pembelajaran Mesin) membuat pengalaman digital kami lebih lancar dengan menemukan solusi yang lebih baik untuk masalah kami. Oleh karena itu, perusahaan sekarang bergerak ke arah mengolah data dan menemukan wawasan darinya.
Secara bersamaan, data yang dihasilkan oleh perusahaan, pemain jaringan, dan raksasa seluler sangat besar. Karena itu, konsep big data diperkenalkan. Sejak data besar muncul, alat untuk mengelola dan memanipulasi data besar juga mulai mendapatkan popularitas dan kepentingan.
Apache Spark adalah salah satu alat yang memanipulasi dan memproses kumpulan data besar untuk mendapatkan wawasan dari data ini. Kumpulan data besar ini tidak dapat diproses atau dikelola dalam satu lintasan karena daya komputasi yang dibutuhkan terlalu kuat.
Di situlah pemrosesan paralel muncul. Kami akan mulai dengan memahami pemrosesan paralel secara singkat dan kemudian melanjutkan untuk memahami bagaimana memparalelkan dalam percikan.
Baca: Arsitektur Apache Spark
Daftar isi
Apa itu Pemrosesan Paralel?
Pemrosesan paralel adalah salah satu operasi penting dari sistem data besar. Ketika tugas Anda penting, Anda memecahkan tugas-tugas yang lebih kecil dan kemudian menyelesaikannya secara mandiri. Pemrosesan paralel data besar melibatkan proses yang sama.

Secara teknis, pemrosesan paralel adalah metode menjalankan dua atau lebih bagian dari satu masalah besar di prosesor yang berbeda. Ini mengurangi waktu pemrosesan dan meningkatkan kinerja.
Karena Anda tidak dapat melakukan operasi pada kumpulan data besar pada satu mesin, Anda memerlukan sesuatu yang sangat solid. Di situlah tepatnya paralelisasi di Spark muncul. Kami sekarang akan membawa Anda melalui Pemrosesan Paralel Spark dan cara memparalelkan dalam percikan untuk mendapatkan output yang tepat dari kumpulan data besar.
Pemrosesan Paralel Percikan
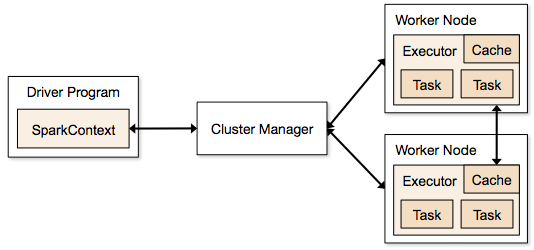
Aplikasi Spark berjalan dalam bentuk proses independen yang berada di cluster dan dikoordinasikan oleh SparkContext di program utama.
Langkah pertama dalam menjalankan program Spark adalah dengan mengirimkan pekerjaan menggunakan Spark-submit. Skrip spark-submit digunakan untuk meluncurkan program pada sebuah cluster.
Setelah Anda mengirimkan pekerjaan menggunakan skrip spark-submit, pekerjaan diteruskan ke driver sparkcontext. Program driver Sparkcontext adalah titik masuk ke Spark. Sparkcontext merutekan program ke modul seperti Cluster Master Node dan RDD juga dibuat oleh program driver Sparkcontext ini.
Program tersebut kemudian diberikan ke Cluster Master Node. Setiap cluster memiliki satu node master yang melakukan semua pemrosesan yang diperlukan. Ini meneruskan program lebih jauh ke node pekerja.
Simpul pekerja adalah simpul yang memecahkan masalah. Node master berisi eksekutor yang mengeksekusi dengan driver Sparkcontext.
 Sumber
Sumber
Apa itu Resilient Distributed Dataset (RDD)?
RDD adalah struktur data dasar Apache Spark. Struktur data ini adalah kumpulan objek yang tidak dapat diubah yang menghitung pada node yang berbeda dari sebuah cluster. Setiap dataset di Spark RDD dipartisi secara logis di berbagai server sehingga komputasi dapat berjalan dengan lancar di setiap node.

Mari kita memahami RDD sedikit lebih detail, karena ini membentuk dasar paralelisasi dalam percikan. Kita dapat memecah nama menjadi tiga bagian dan mengetahui mengapa struktur data dinamai demikian.
- Resilient : Ini berarti struktur data toleran terhadap kesalahan dengan bantuan grafik garis keturunan RDD, dan karenanya, dapat menghitung ulang partisi yang hilang atau partisi yang rusak yang disebabkan karena kegagalan node.
- Terdistribusi: Ini berlaku untuk semua sistem yang menggunakan lingkungan terdistribusi. Disebut terdistribusi karena data tersedia pada node yang berbeda/banyak.
- Dataset: Dataset mewakili data yang Anda gunakan. Anda dapat mengimpor kumpulan data apa pun yang tersedia dalam format apa pun seperti .csv, .json, file teks, atau database. Anda dapat melakukannya dengan menggunakan JDBC tanpa struktur khusus.
Setelah Anda mengimpor atau memuat dataset Anda, RDD secara logis akan mempartisi data Anda menjadi beberapa node di banyak server, untuk menjaga operasi tetap berjalan.
Baca Juga: Fitur Apache Spark
Setelah mengetahui RDD, Anda akan lebih mudah memahami Spark Parallel Processing.
Paralel dalam Spark Menggunakan RDD
Pemrosesan paralel dilakukan dalam 4 langkah signifikan di Apache Spark. RDD digunakan pada tingkat utama untuk memparalelkan dalam percikan untuk melakukan pemrosesan paralel.
Langkah 1
RDD biasanya dibuat dari sumber data eksternal. Itu bisa berupa file CSV, file JSON, atau hanya database dalam hal ini. Dalam kebanyakan kasus, ini adalah HDFS atau file lokal.
Langkah 2
Setelah langkah pertama, RDD akan melalui beberapa transformasi paralel seperti filter, map, groupBy, dan join. Masing-masing transformasi ini memberikan RDD berbeda yang maju ke transformasi berikutnya.
Dapatkan sertifikasi ilmu data dari Universitas top dunia. Bergabunglah dengan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister kami untuk mempercepat karir Anda.
Langkah 3
Tahap terakhir adalah tentang tindakan; itu selalu. RDD, dalam tahap ini, diekspor sebagai output eksternal ke sumber data eksternal.

Lihat: Tutorial Apache Spark untuk Pemula
Kesimpulan
Pemrosesan paralel semakin populer di kalangan penggemar data, karena wawasan membantu perusahaan dan OTT menghasilkan banyak uang. Spark, di sisi lain, adalah salah satu alat yang membantu raksasa besar untuk membuat keputusan dengan melakukan pemrosesan paralel pada data yang besar dan lebih besar.
Jika Anda ingin mempercepat pemrosesan data besar, Apache spark adalah pilihan Anda. Dan, RDD di Spark, memberikan kinerja terbaik sejak dikenal.
Jika Anda tertarik untuk mengetahui lebih banyak tentang Big Data, lihat Diploma PG kami dalam Spesialisasi Pengembangan Perangkat Lunak dalam program Big Data yang dirancang untuk para profesional yang bekerja dan menyediakan 7+ studi kasus & proyek, mencakup 14 bahasa & alat pemrograman, praktik langsung lokakarya, lebih dari 400 jam pembelajaran yang ketat & bantuan penempatan kerja dengan perusahaan-perusahaan top.
Pelajari Kursus Pengembangan Perangkat Lunak online dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Lanjutan, atau Program Magister untuk mempercepat karier Anda.