Cum să paralelizezi în procesarea paralelă Spark? [Folosind RDD]
Publicat: 2020-09-03Generarea și consumul de date au crescut de n ori în ultimii ani. Cu atât de multe platforme care prind viață, gestionarea și gestionarea datelor cu atenție au devenit cruciale. AI (Inteligenta Artificiala) si ML (Machine Learning) fac experientele noastre digitale si mai fluide, gasind solutii mai bune la problemele noastre. Prin urmare, companiile se îndreaptă acum către tratarea datelor și găsirea de informații din acestea.
Simultan, datele generate de companii, jucători de rețea și giganți de telefonie mobilă sunt enorme. Datorită faptului că a fost introdus conceptul de date mari. De când datele mari au apărut în imagine, instrumentele de gestionare și manipulare a datelor mari au început, de asemenea, să câștige popularitate și importanță.
Apache Spark este unul dintre acele instrumente care manipulează și procesează seturi de date masive pentru a obține informații din aceste date. Aceste seturi mari de date nu pot fi procesate sau gestionate într-o singură trecere, deoarece puterea de calcul necesară este prea intensă.
Aici intervine procesarea paralelă. Vom începe prin a înțelege procesarea paralelă pe scurt și apoi vom continua să înțelegem cum să paralelizăm în scânteie.
Citiți: Apache Spark Architecture
Cuprins
Ce este procesarea paralelă?
Procesarea în paralel este una dintre operațiunile esențiale ale unui sistem de date mari. Când sarcina dvs. este semnificativă, se întâmplă să vă împărțiți în sarcini mai mici și apoi să le rezolvați pe fiecare independent. Prelucrarea paralelă a datelor mari implică același proces.

Tehnic vorbind, procesarea paralelă este o metodă de a rula două sau mai multe părți ale unei singure probleme mari în procesoare diferite. Acest lucru reduce timpul de procesare și crește performanța.
Deoarece nu puteți efectua operațiuni pe seturi mari de date pe o singură mașină, aveți nevoie de ceva foarte solid. Tocmai aici apare paralelizarea în Spark. Vă vom ghida acum prin procesarea paralelă Spark și cum să paralelizați în spark pentru a obține rezultatul potrivit din seturi mari de date.
Procesare paralelă Spark
Aplicațiile Spark rulează sub formă de procese independente care rezidă pe clustere și sunt coordonate de SparkContext în programul principal.
Primul pas în rularea unui program Spark este trimiterea jobului folosind Spark-submit. Scriptul spark-submit este folosit pentru a lansa programul pe un cluster.
Odată ce ați trimis jobul utilizând un script spark-submit, jobul este redirecționat către driverele sparkcontext. Programul driver Sparkcontext este punctul de intrare în Spark. Sparkcontext direcționează programul către module precum Cluster Master Node și RDD-urile sunt, de asemenea, create de aceste programe driver Sparkcontext.
Programul este apoi dat Nodului Master Cluster. Fiecare cluster are un nod master care efectuează toate procesările necesare. Redirecționează programul în continuare către nodurile de lucru.
Nodul lucrător este cel care rezolvă problemele. Nodurile master conțin executanți care se execută cu driverul Sparkcontext.
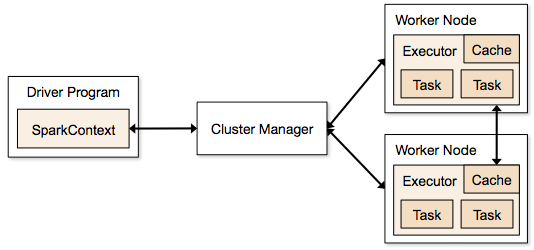 Sursă
Sursă
Ce este Resilient Distributed Dataset (RDD)?
RDD este structura fundamentală de date a Apache Spark. Această structură de date este o colecție imuabilă de obiecte care calculează pe diferite noduri ale unui cluster. Fiecare set de date din Spark RDD este partiționat logic pe diverse servere, astfel încât calculele să poată fi rulate fără probleme pe fiecare nod.

Să înțelegem RDD puțin mai detaliat, deoarece formează baza paralelizării în scânteie. Putem împărți numele în trei părți și știm de ce structura de date este numită așa.
- Rezistent : înseamnă că structura de date este tolerantă la erori cu ajutorul graficului de descendență RDD și, prin urmare, poate recalcula partițiile lipsă sau partițiile deteriorate cauzate de defecțiunile nodurilor.
- Distribuit: Acest lucru este valabil pentru toate sistemele care utilizează un mediu distribuit. Se numește distribuit deoarece datele sunt disponibile pe noduri diferite/mai multe.
- Setul de date: Setul de date reprezintă datele cu care lucrați. Puteți importa oricare dintre seturile de date disponibile în orice format, cum ar fi .csv, .json, un fișier text sau o bază de date. Puteți face asta folosind JDBC fără o structură specifică.
Odată ce importați sau încărcați setul de date, RDD-urile vă vor partiționa în mod logic datele în mai multe noduri pe mai multe servere, pentru a menține operația în funcțiune.
Citiți și: Caracteristici Apache Spark
Acum că cunoașteți RDD, vă va fi mai ușor să înțelegeți Spark Parallel Processing.
Paraleliză în Spark folosind RDD
Procesarea paralelă se realizează în 4 pași semnificativi în Apache Spark. RDD este folosit la un nivel major pentru a paraleliza în scânteie pentru a efectua procesarea paralelă.
Pasul 1
RDD este de obicei creat dintr-o sursă de date externă. Ar putea fi un fișier CSV, un fișier JSON sau pur și simplu o bază de date. În cele mai multe cazuri, este un HDFS sau un fișier local.
Pasul 2
După primul pas, RDD va trece prin câteva transformări paralele, cum ar fi filtru, hartă, grupare și alăturare. Fiecare dintre aceste transformări oferă un RDD diferit care merge înainte la următoarea transformare.
Obțineți certificare în știința datelor de la cele mai bune universități din lume. Alăturați-vă programelor noastre Executive PG, Programelor de certificate avansate sau Programelor de master pentru a vă accelera cariera.
Pasul 3
Ultima etapă este despre acțiune; este întotdeauna. RDD, în această etapă, este exportat ca o ieșire externă către surse de date externe.

Consultați: Tutorial Apache Spark pentru începători
Concluzie
Procesarea paralelă câștigă popularitate în rândul pasionaților de date, deoarece informațiile ajută companiile și OTT-urile să câștige mare. Spark, pe de altă parte, este unul dintre instrumentele care îi ajută pe marii giganți să ia decizii prin procesarea paralelă a datelor mari și mai mari.
Dacă așteptați cu nerăbdare să faceți procesarea datelor mari mai rapidă, Apache spark este calea de urmat. Și RDD-urile din Spark oferă cea mai bună performanță de când este cunoscută.
Dacă sunteți interesat să aflați mai multe despre Big Data, consultați programul nostru PG Diploma în Dezvoltare Software Specializare în Big Data, care este conceput pentru profesioniști care lucrează și oferă peste 7 studii de caz și proiecte, acoperă 14 limbaje și instrumente de programare, practică practică. ateliere de lucru, peste 400 de ore de învățare riguroasă și asistență pentru plasarea unui loc de muncă cu firme de top.
Învață cursuri de dezvoltare software online de la cele mai bune universități din lume. Câștigați programe Executive PG, programe avansate de certificat sau programe de master pentru a vă accelera cariera.