Come parallelizzare in Spark Parallel Processing? [Utilizzo di RDD]
Pubblicato: 2020-09-03La generazione e il consumo di dati sono aumentati di n volte negli ultimi anni. Con così tante piattaforme che prendono vita, la gestione e la gestione attenta dei dati sono diventate cruciali. AI (Intelligenza Artificiale) e ML (Machine Learning) stanno rendendo le nostre esperienze digitali ancora più fluide trovando soluzioni migliori ai nostri problemi. Pertanto, le aziende si stanno ora muovendo verso il trattamento dei dati e la ricerca di approfondimenti da essi.
Allo stesso tempo, i dati generati da aziende, operatori di rete e giganti della telefonia mobile sono enormi. Per questo motivo è stato introdotto il concetto di big data. Da quando sono entrati in scena i big data, anche gli strumenti per gestire e manipolare i big data hanno iniziato a guadagnare popolarità e importanza.
Apache Spark è uno di quegli strumenti che manipolano ed elaborano enormi set di dati per ottenere informazioni dettagliate da questi dati. Questi grandi set di dati non possono essere elaborati o gestiti in un unico passaggio poiché la potenza di calcolo richiesta è troppo intensa.
È qui che entra in gioco l'elaborazione parallela. Inizieremo con la comprensione dell'elaborazione parallela in breve per poi passare a capire come parallelizzare in spark.
Leggi: Architettura Apache Spark
Sommario
Che cos'è l'elaborazione parallela?
L'elaborazione parallela è una delle operazioni essenziali di un sistema di big data. Quando il tuo compito è significativo, ti capita di suddividere in compiti più piccoli e poi risolverli indipendentemente. L'elaborazione parallela dei big data comporta lo stesso processo.

Tecnicamente parlando, l'elaborazione parallela è un metodo per eseguire due o più parti di un unico grande problema in diversi processori. Ciò riduce il tempo di elaborazione e migliora le prestazioni.
Dal momento che non puoi eseguire operazioni su grandi set di dati su una macchina, hai bisogno di qualcosa di molto solido. È proprio qui che entra in gioco il parallelismo in Spark. Ti illustreremo ora l'elaborazione parallela di Spark e come eseguire la parallelizzazione in spark per ottenere l'output corretto da grandi set di dati.
Spark elaborazione parallela
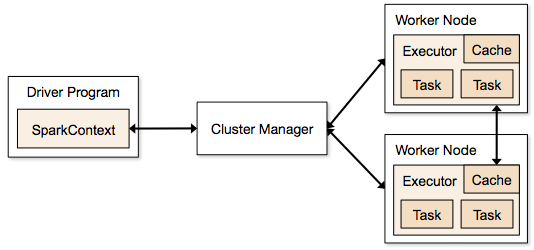
Le applicazioni Spark vengono eseguite sotto forma di processi indipendenti che risiedono su cluster e sono coordinate da SparkContext nel programma principale.
Il primo passaggio nell'esecuzione di un programma Spark consiste nell'inviare il lavoro tramite Spark-submit. Lo script spark-submit viene utilizzato per avviare il programma su un cluster.
Dopo aver inviato il lavoro utilizzando uno script spark-submit, il lavoro viene inoltrato ai driver sparkcontext. Il programma driver Sparkcontext è il punto di accesso a Spark. Sparkcontext indirizza il programma ai moduli come Cluster Master Node e anche gli RDD vengono creati da questi programmi driver Sparkcontext.
Il programma viene quindi consegnato al Cluster Master Node. Ogni cluster ha un nodo master che esegue tutte le elaborazioni necessarie. Inoltra ulteriormente il programma ai nodi di lavoro.
Il nodo di lavoro è quello che risolve i problemi. I nodi master contengono esecutori che vengono eseguiti con il driver Sparkcontext.
 Fonte
Fonte
Che cos'è il set di dati distribuito resiliente (RDD)?
RDD è la struttura dati fondamentale di Apache Spark. Questa struttura di dati è una raccolta immutabile di oggetti che calcolano su diversi nodi di un cluster. Ogni set di dati in Spark RDD è ripartito logicamente tra vari server in modo che i calcoli possano essere eseguiti senza problemi su ogni nodo.

Cerchiamo di capire RDD un po 'più in dettaglio, poiché costituisce la base per il parallelismo in spark. Possiamo suddividere il nome in tre parti e sapere perché la struttura dei dati è denominata così.
- Resiliente : significa che la struttura dei dati è a tolleranza di errore con l'aiuto del grafico del lignaggio RDD e, quindi, può ricalcolare le partizioni mancanti o danneggiate causate da guasti ai nodi.
- Distribuito: questo vale per tutti i sistemi che utilizzano un ambiente distribuito. Si chiama distribuito perché i dati sono disponibili su nodi diversi/multipli.
- Set di dati: il set di dati rappresenta i dati con cui lavori. Puoi importare qualsiasi set di dati disponibile in qualsiasi formato come .csv, .json, un file di testo o un database. Puoi farlo usando JDBC senza una struttura specifica.
Una volta importato o caricato il set di dati, gli RDD partizioniranno logicamente i dati in più nodi su molti server, per mantenere l'operazione in esecuzione.
Leggi anche: Funzionalità di Apache Spark
Ora che conosci RDD, sarà più facile per te comprendere Spark Parallel Processing.
Parallelizza in Spark usando RDD
L'elaborazione parallela viene eseguita in 4 passaggi significativi in Apache Spark. RDD viene utilizzato a un livello principale per parallelizzare in spark per eseguire l'elaborazione parallela.
Passo 1
L'RDD viene in genere creato da un'origine dati esterna. Potrebbe essere un file CSV, un file JSON o semplicemente un database per quella materia. Nella maggior parte dei casi, è un HDFS o un file locale.
Passo 2
Dopo il primo passaggio, RDD passa attraverso alcune trasformazioni parallele come filter, map, groupBy e join. Ognuna di queste trasformazioni fornisce un diverso RDD che va avanti alla trasformazione successiva.
Ottieni la certificazione di data science dalle migliori università del mondo. Unisciti ai nostri programmi Executive PG, Advanced Certificate Program o Masters per accelerare la tua carriera.
Passaggio 3
L'ultima fase riguarda l'azione; lo è sempre. L'RDD, in questa fase, viene esportato come output esterno in origini dati esterne.

Dai un'occhiata a: Tutorial Apache Spark per principianti
Conclusione
L'elaborazione parallela sta guadagnando popolarità tra gli appassionati di dati, poiché le informazioni stanno aiutando le aziende e gli OTT a guadagnare molto. Spark, d'altra parte, è uno degli strumenti che aiutano i grandi giganti a prendere decisioni eseguendo elaborazioni parallele su dati sempre più grandi.
Se non vedi l'ora di rendere più veloce l'elaborazione dei big data, Apache spark è la tua strada da percorrere. Inoltre, RDD in Spark offre le migliori prestazioni da quando è noto.
Se sei interessato a saperne di più sui Big Data, dai un'occhiata al nostro PG Diploma in Software Development Specialization nel programma Big Data, progettato per professionisti che lavorano e fornisce oltre 7 casi di studio e progetti, copre 14 linguaggi e strumenti di programmazione, pratiche pratiche workshop, oltre 400 ore di apprendimento rigoroso e assistenza all'inserimento lavorativo con le migliori aziende.
Impara i corsi di sviluppo software online dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.