¿Cómo paralelizar en Spark Parallel Processing? [Usando RDD]
Publicado: 2020-09-03La generación y el consumo de datos se han multiplicado por n en los últimos años. Con tantas plataformas cobrando vida, el manejo y la gestión de datos con cuidado se han vuelto cruciales. AI (inteligencia artificial) y ML (aprendizaje automático) están haciendo que nuestras experiencias digitales sean aún más fluidas al encontrar mejores soluciones a nuestros problemas. Por lo tanto, las empresas ahora se están moviendo hacia el tratamiento de datos y la búsqueda de información a partir de ellos.
Al mismo tiempo, los datos generados por las empresas, los actores de la red y los gigantes móviles son enormes. Debido a lo cual, se introdujo el concepto de big data. Desde que Big Data entró en escena, las herramientas para administrar y manipular Big Data también comenzaron a ganar popularidad e importancia.
Apache Spark es una de esas herramientas que manipulan y procesan conjuntos de datos masivos para obtener información de estos datos. Estos grandes conjuntos de datos no se pueden procesar ni administrar en un solo paso, ya que la potencia computacional requerida es demasiado intensa.
Ahí es donde el procesamiento paralelo entra en escena. Comenzaremos por comprender brevemente el procesamiento en paralelo y luego pasaremos a comprender cómo paralelizar en Spark.
Leer: Arquitectura Apache Spark
Tabla de contenido
¿Qué es el procesamiento paralelo?
El procesamiento paralelo es una de las operaciones esenciales de un sistema de big data. Cuando su tarea es importante, se divide en tareas más pequeñas y luego resuelve cada una de forma independiente. El procesamiento paralelo de big data implica el mismo proceso.

Técnicamente hablando, el procesamiento paralelo es un método para ejecutar dos o más partes de un solo gran problema en diferentes procesadores. Esto reduce el tiempo de procesamiento y mejora el rendimiento.
Dado que no puede realizar operaciones en grandes conjuntos de datos en una máquina, necesita algo muy sólido. Ahí es precisamente donde entra en escena la paralelización en Spark. Ahora lo guiaremos a través del procesamiento paralelo de Spark y cómo paralelizarlo en Spark para obtener el resultado correcto de grandes conjuntos de datos.
Procesamiento paralelo Spark
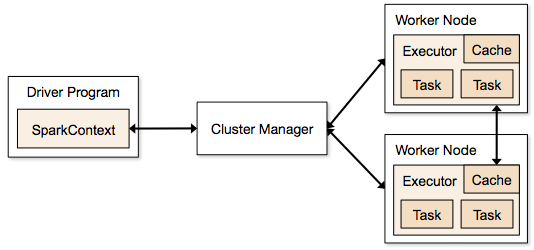
Las aplicaciones de Spark se ejecutan en forma de procesos independientes que residen en clústeres y están coordinados por SparkContext en el programa principal.
El primer paso para ejecutar un programa Spark es enviar el trabajo mediante Spark-submit. La secuencia de comandos spark-submit se utiliza para iniciar el programa en un clúster.
Una vez que haya enviado el trabajo mediante un script de envío de chispa, el trabajo se reenvía a los controladores de contexto de chispa. El programa controlador Sparkcontext es el punto de entrada a Spark. Sparkcontext enruta el programa a los módulos como Cluster Master Node y RDD también son creados por estos programas de controlador Sparkcontext.
Luego, el programa se entrega al nodo principal del clúster. Cada clúster tiene un nodo maestro que lleva a cabo todo el procesamiento necesario. Reenvía el programa a los nodos trabajadores.
El nodo trabajador es el que resuelve los problemas. Los nodos maestros contienen ejecutores que se ejecutan con el controlador Sparkcontext.
 Fuente
Fuente
¿Qué es un conjunto de datos distribuido resistente (RDD)?
RDD es la estructura de datos fundamental de Apache Spark. Esta estructura de datos es una colección inmutable de objetos que se computan en diferentes nodos de un clúster. Cada conjunto de datos en Spark RDD se divide lógicamente en varios servidores para que los cálculos se puedan ejecutar sin problemas en cada nodo.

Entendamos RDD con un poco más de detalle, ya que forma la base de la paralelización en chispa. Podemos dividir el nombre en tres partes y saber por qué la estructura de datos se llama así.
- Resiliente : significa que la estructura de datos es tolerante a fallas con la ayuda del gráfico de linaje RDD y, por lo tanto, puede volver a calcular las particiones que faltan o las particiones dañadas causadas por fallas en los nodos.
- Distribuido: Esto es válido para todos los sistemas que utilizan un entorno distribuido. Se llama distribuido porque los datos están disponibles en diferentes/múltiples nodos.
- Conjunto de datos: el conjunto de datos representa los datos con los que trabaja. Puede importar cualquiera de los conjuntos de datos disponibles en cualquier formato, como .csv, .json, un archivo de texto o una base de datos. Puede hacerlo utilizando JDBC sin una estructura específica.
Una vez que importe o cargue su conjunto de datos, los RDD dividirán lógicamente sus datos en múltiples nodos en muchos servidores, para mantener la operación en funcionamiento.
Lea también: Características de Apache Spark
Ahora que conoce RDD, le resultará más fácil comprender el procesamiento paralelo de Spark.
Paralelizar en Spark usando RDD
El procesamiento paralelo se lleva a cabo en 4 pasos significativos en Apache Spark. RDD se usa en un nivel importante para paralelizar en chispa para realizar procesamiento paralelo.
Paso 1
RDD generalmente se crea a partir de una fuente de datos externa. Podría ser un archivo CSV, un archivo JSON o simplemente una base de datos. En la mayoría de los casos, es un HDFS o un archivo local.
Paso 2
Después del primer paso, RDD pasaría por algunas transformaciones paralelas como filter, map, groupBy y join. Cada una de estas transformaciones proporciona un RDD diferente que avanza a la siguiente transformación.
Obtenga una certificación en ciencia de datos de las mejores universidades del mundo. Únase a nuestros programas Executive PG, programas de certificación avanzada o programas de maestría para acelerar su carrera.
Paso 3
La última etapa se trata de la acción; siempre lo es El RDD, en esta etapa, se exporta como una salida externa a fuentes de datos externas.

Consulte: Tutorial de Apache Spark para principiantes
Conclusión
El procesamiento paralelo está ganando popularidad entre los entusiastas de los datos, ya que los conocimientos están ayudando a las empresas y los OTT a ganar mucho. Spark, por otro lado, es una de las herramientas que ayudan a los grandes gigantes a tomar decisiones mediante el procesamiento paralelo de datos cada vez más grandes.
Si desea acelerar el procesamiento de big data, Apache Spark es su camino a seguir. Y RDD en Spark ofrece el mejor rendimiento desde que se conoce.
Si está interesado en saber más sobre Big Data, consulte nuestro programa PG Diploma in Software Development Specialization in Big Data, que está diseñado para profesionales que trabajan y proporciona más de 7 estudios de casos y proyectos, cubre 14 lenguajes y herramientas de programación, prácticas talleres, más de 400 horas de aprendizaje riguroso y asistencia para la colocación laboral con las mejores empresas.
Aprenda cursos de desarrollo de software en línea de las mejores universidades del mundo. Obtenga Programas PG Ejecutivos, Programas de Certificado Avanzado o Programas de Maestría para acelerar su carrera.