Spark 병렬 처리에서 어떻게 병렬화합니까? [RDD 사용]
게시 됨: 2020-09-03데이터 생성 및 소비는 지난 몇 년 동안 n배 증가했습니다. 많은 플랫폼이 등장하면서 데이터를 신중하게 처리하고 관리하는 것이 중요해졌습니다. AI(인공 지능)와 ML(기계 학습)은 문제에 대한 더 나은 솔루션을 찾아 디지털 경험을 더욱 매끄럽게 만들고 있습니다. 따라서 기업은 이제 데이터를 처리하고 데이터에서 통찰력을 찾는 방향으로 나아가고 있습니다.
동시에 기업, 네트워크 플레이어 및 모바일 거물이 생성하는 데이터는 방대합니다. 이에 빅데이터라는 개념이 도입됐다. 빅 데이터가 등장한 이후 빅 데이터를 관리하고 조작하는 도구도 인기와 중요성을 얻기 시작했습니다.
Apache Spark는 이러한 데이터에서 통찰력을 얻기 위해 대규모 데이터 세트를 조작하고 처리하는 도구 중 하나입니다. 이러한 큰 데이터 세트는 요구되는 계산 능력이 너무 강력하기 때문에 한 번에 처리하거나 관리할 수 없습니다.
이것이 병렬 처리가 그림에 등장하는 곳입니다. 간단히 병렬 처리를 이해하는 것으로 시작한 다음 스파크에서 병렬 처리하는 방법을 이해하는 것으로 넘어갑니다.
읽기: Apache Spark 아키텍처
목차
병렬 처리란 무엇입니까?
병렬 처리는 빅 데이터 시스템의 필수 작업 중 하나입니다. 당신의 과업이 중요할 때, 당신은 우연히 더 작은 과업을 쪼개서 각각을 독립적으로 해결하게 됩니다. 빅 데이터의 병렬 처리는 동일한 프로세스를 포함합니다.

기술적으로 말하면 병렬 처리는 서로 다른 프로세서에서 하나의 큰 문제의 두 개 이상의 부분을 실행하는 방법입니다. 이렇게 하면 처리 시간이 단축되고 성능이 향상됩니다.
하나의 시스템에서 큰 데이터 세트에 대한 작업을 수행할 수 없기 때문에 매우 견고한 것이 필요합니다. 바로 이것이 Spark의 병렬화가 그림으로 등장하는 곳입니다. 이제 Spark 병렬 처리 및 Spark에서 병렬화하여 큰 데이터 세트에서 올바른 출력을 얻는 방법을 안내합니다.
스파크 병렬 처리
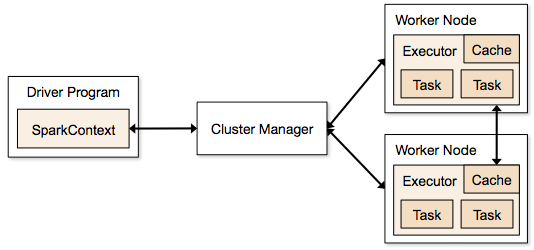
Spark 애플리케이션은 클러스터에 상주하고 주 프로그램의 SparkContext에 의해 조정되는 독립 프로세스의 형태로 실행됩니다.
Spark 프로그램을 실행하는 첫 번째 단계는 Spark-submit을 사용하여 작업을 제출하는 것입니다. spark-submit 스크립트는 클러스터에서 프로그램을 시작하는 데 사용됩니다.
spark-submit 스크립트를 사용하여 작업을 제출하면 작업이 sparkcontext 드라이버로 전달됩니다. Sparkcontext 드라이버 프로그램은 Spark의 진입점입니다. Sparkcontext는 프로그램을 클러스터 마스터 노드와 같은 모듈로 라우팅하고 이러한 Sparkcontext 드라이버 프로그램에 의해 RDD도 생성됩니다.
그런 다음 프로그램이 클러스터 마스터 노드에 제공됩니다. 모든 클러스터에는 필요한 모든 처리를 수행하는 하나의 마스터 노드가 있습니다. 프로그램을 작업자 노드로 더 전달합니다.
작업자 노드는 문제를 해결하는 노드입니다. 마스터 노드에는 Sparkcontext 드라이버로 실행되는 실행기가 포함되어 있습니다.
 원천
원천
복원력 있는 분산 데이터 세트(RDD)란 무엇입니까?
RDD는 Apache Spark의 기본 데이터 구조입니다. 이 데이터 구조는 클러스터의 다른 노드에서 계산하는 개체의 변경 불가능한 컬렉션입니다. Spark RDD의 모든 데이터 세트는 다양한 서버에 논리적으로 분할되므로 각 노드에서 계산을 원활하게 실행할 수 있습니다.

스파크에서 병렬화의 기초를 형성하는 RDD를 조금 더 자세히 이해합시다. 우리는 이름을 세 부분으로 나눌 수 있으며 데이터 구조의 이름이 그렇게 지정된 이유를 알 수 있습니다.
- Resilient : 데이터 구조가 RDD 계보 그래프의 도움으로 내결함성이 있으므로 노드 오류로 인해 누락된 파티션이나 손상된 파티션을 다시 계산할 수 있음을 의미합니다.
- 분산: 분산 환경을 사용하는 모든 시스템에 적용됩니다. 데이터가 서로 다른/여러 노드에서 사용 가능하기 때문에 분산이라고 합니다.
- 데이터 세트: 데이터 세트는 작업하는 데이터를 나타냅니다. .csv, .json, 텍스트 파일 또는 데이터베이스와 같은 형식으로 사용 가능한 모든 데이터 세트를 가져올 수 있습니다. 특정 구조 없이 JDBC를 사용하여 이를 수행할 수 있습니다.
데이터 세트를 가져오거나 로드하면 RDD가 데이터를 여러 서버에 걸쳐 여러 노드로 논리적으로 분할하여 작업을 계속 실행합니다.
또한 읽기: Apache Spark 기능
이제 RDD를 알았으니 Spark 병렬 처리를 이해하는 것이 더 쉬울 것입니다.
RDD를 사용하여 Spark에서 병렬화
병렬 처리는 Apache Spark에서 중요한 4단계로 수행됩니다. RDD는 병렬 처리를 수행하기 위해 스파크에서 병렬화하기 위해 주요 수준에서 사용됩니다.
1 단계
RDD는 일반적으로 외부 데이터 소스에서 생성됩니다. CSV 파일, JSON 파일 또는 해당 문제에 대한 단순한 데이터베이스가 될 수 있습니다. 대부분의 경우 HDFS 또는 로컬 파일입니다.
2 단계
첫 번째 단계 후에 RDD는 필터, 맵, groupBy 및 조인과 같은 몇 가지 병렬 변환을 거칩니다. 이러한 각 변환은 다음 변환으로 넘어가는 다른 RDD를 제공합니다.
세계 최고의 대학에서 데이터 과학 인증 을 획득 하십시오. 귀하의 경력을 빠르게 추적하려면 Executive PG 프로그램, 고급 인증 프로그램 또는 석사 프로그램에 가입하십시오.
3단계
마지막 단계는 행동에 관한 것입니다. 항상 그렇습니다. 이 단계에서 RDD는 외부 데이터 소스에 외부 출력으로 내보내집니다.

확인: 초보자를 위한 Apache Spark 자습서
결론
병렬 처리는 통찰력이 기업과 OTT가 큰 수익을 올리는 데 도움이 되면서 데이터 애호가들 사이에서 인기를 얻고 있습니다. 반면에 Spark는 크고 큰 데이터에 대해 병렬 처리를 수행하여 거대 기업이 의사 결정을 내리는 데 도움이 되는 도구 중 하나입니다.
빅 데이터 처리 속도를 높이고 싶다면 Apache Spark를 선택하십시오. 그리고 Spark의 RDD는 알려진 이후로 최고의 성능을 제공하고 있습니다.
빅 데이터에 대해 더 알고 싶다면 PG 디플로마 빅 데이터 소프트웨어 개발 전문화 프로그램을 확인하십시오. 이 프로그램은 실무 전문가를 위해 설계되었으며 7개 이상의 사례 연구 및 프로젝트를 제공하고 14개 프로그래밍 언어 및 도구, 실용적인 실습을 다룹니다. 워크샵, 400시간 이상의 엄격한 학습 및 최고의 기업과의 취업 지원.
세계 최고의 대학에서 온라인으로 소프트웨어 개발 과정 을 배우십시오 . 이그 제 큐 티브 PG 프로그램, 고급 인증 프로그램 또는 석사 프로그램을 획득하여 경력을 빠르게 추적하십시오.