如何在 Spark 並行處理中進行並行化? [使用 RDD]
已發表: 2020-09-03在過去的幾年裡,數據的產生和消費增加了 n 倍。 隨著這麼多平台的出現,仔細處理和管理數據變得至關重要。 AI(人工智能)和 ML(機器學習)通過為我們的問題找到更好的解決方案,使我們的數字體驗更加順暢。 因此,公司現在正朝著處理數據的方向發展,並從中尋找洞察力。
同時,公司、網絡玩家和移動巨頭產生的數據是巨大的。 因此,引入了大數據的概念。 自從大數據出現以來,管理和操作大數據的工具也開始受到歡迎和重視。
Apache Spark 是操縱和處理大量數據集以從這些數據中獲得洞察力的工具之一。 由於所需的計算能力太強,這些大數據集無法一次性處理或管理。
這就是並行處理出現的地方。 我們將從簡要了解並行處理開始,然後繼續了解如何在 Spark 中進行並行化。
閱讀:Apache Spark 架構
目錄
什麼是並行處理?
並行處理是大數據系統的基本操作之一。 當您的任務很重要時,您會碰巧分成較小的任務,然後獨立解決每個任務。 大數據的並行處理涉及相同的過程。

從技術上講,並行處理是一種在不同處理器中運行單個大問題的兩個或多個部分的方法。 這減少了處理時間並提高了性能。
由於您無法在一台機器上對大型數據集執行操作,因此您需要一些非常可靠的東西。 這正是 Spark 中的並行化發揮作用的地方。 我們現在將帶您了解 Spark 並行處理以及如何在 spark 中進行並行化以從大數據集中獲得正確的輸出。
火花並行處理
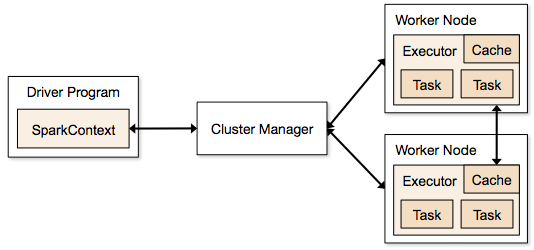
Spark 應用程序以獨立進程的形式運行,這些進程駐留在集群上,並由主程序中的 SparkContext 協調。
運行 Spark 程序的第一步是使用 Spark-submit 提交作業。 spark-submit 腳本用於在集群上啟動程序。
使用 spark-submit 腳本提交作業後,該作業將轉發到 sparkcontext 驅動程序。 Sparkcontext 驅動程序是 Spark 的入口點。 Sparkcontext 將程序路由到 Cluster Master Node 等模塊,RDD 也由這些 Sparkcontext 驅動程序創建。
然後將該程序提供給集群主節點。 每個集群都有一個主節點來執行所有必要的處理。 它將程序進一步轉發到工作節點。
工作節點是解決問題的節點。 主節點包含使用 Sparkcontext 驅動程序執行的執行程序。
 資源
資源
什麼是彈性分佈式數據集 (RDD)?
RDD 是 Apache Spark 的基礎數據結構。 此數據結構是在集群的不同節點上計算的不可變對象集合。 Spark RDD 中的每個數據集都在不同的服務器上進行了邏輯分區,因此計算可以在每個節點上順利運行。

讓我們更詳細地了解 RDD,因為它構成了 Spark 中並行化的基礎。 我們可以把名字分成三部分,就知道數據結構為什麼這麼命名了。
- 彈性:這意味著數據結構在 RDD 沿襲圖的幫助下具有容錯性,因此它可以重新計算由於節點故障而導致的丟失分區或損壞分區。
- 分佈式:這適用於所有使用分佈式環境的系統。 它被稱為分佈式,因為數據在不同/多個節點上可用。
- 數據集:數據集表示您使用它的數據。 您可以導入任何格式的可用數據集,例如 .csv、.json、文本文件或數據庫。 您可以通過使用沒有特定結構的 JDBC 來做到這一點。
導入或加載數據集後,RDD 會在邏輯上將您的數據劃分為跨多個服務器的多個節點,以保持操作運行。
另請閱讀:Apache Spark 功能
既然您了解了 RDD,那麼您將更容易理解 Spark 並行處理。
在 Spark 中使用 RDD 進行並行化
並行處理在 Apache Spark 中分 4 個重要步驟執行。 RDD 主要用於在 spark 中並行化以執行並行處理。
第1步
RDD 通常是從外部數據源創建的。 它可以是 CSV 文件、JSON 文件,或者只是一個數據庫。 在大多數情況下,它是 HDFS 或本地文件。
第2步
在第一步之後,RDD 會經歷一些並行的轉換,比如 filter、map、groupBy 和 join。 這些轉換中的每一個都提供了一個不同的 RDD,用於下一個轉換。
獲得世界頂尖大學的數據科學認證。 加入我們的行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
第 3 步
最後一個階段是關於行動; 它總是如此。 在這個階段,RDD 作為外部輸出導出到外部數據源。

查看: Apache Spark 初學者教程
結論
並行處理在數據愛好者中越來越受歡迎,因為這些見解正在幫助公司和 OTT 賺大錢。 另一方面,Spark 是通過對大數據和更大數據執行並行處理來幫助大巨頭做出決策的工具之一。
如果您希望更快地處理大數據,Apache spark 是您的不二之選。 而且,Spark 中的 RDD 提供了有史以來最好的性能。
如果您有興趣了解有關大數據的更多信息,請查看我們的 PG 大數據軟件開發專業文憑課程,該課程專為在職專業人士設計,提供 7 多個案例研究和項目,涵蓋 14 種編程語言和工具,實用的動手操作研討會,超過 400 小時的嚴格學習和頂級公司的就業幫助。
從世界頂級大學在線學習軟件開發課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。