Как распараллелить в параллельной обработке Spark? [Использование СДР]
Опубликовано: 2020-09-03Генерация и потребление данных выросли в n раз за последние несколько лет. С появлением стольких платформ тщательная обработка данных и управление ими стали критически важными. AI (искусственный интеллект) и ML (машинное обучение) делают наш цифровой опыт еще более плавным, находя лучшие решения наших проблем. Поэтому компании сейчас переходят к обработке данных и извлечению из них идей.
В то же время данные, генерируемые компаниями, сетевыми игроками и мобильными гигантами, огромны. Благодаря чему было введено понятие больших данных. С появлением больших данных инструменты для управления и обработки больших данных также начали приобретать популярность и важность.
Apache Spark — один из тех инструментов, которые манипулируют и обрабатывают массивные наборы данных, чтобы получить представление об этих данных. Эти большие наборы данных нельзя обрабатывать или управлять ими за один проход, поскольку требуемая вычислительная мощность слишком высока.
Вот где на сцену выходит параллельная обработка. Мы начнем с краткого понимания параллельной обработки, а затем перейдем к пониманию того, как распараллелить в spark.
Читайте: Архитектура Apache Spark
Оглавление
Что такое параллельная обработка?
Параллельная обработка — одна из важнейших операций системы больших данных. Когда ваша задача значительна, вы разбиваетесь на более мелкие задачи, а затем решаете каждую из них самостоятельно. Параллельная обработка больших данных включает в себя тот же процесс.

С технической точки зрения, параллельная обработка — это метод выполнения двух или более частей одной большой задачи на разных процессорах. Это сокращает время обработки и повышает производительность.
Поскольку вы не можете выполнять операции с большими наборами данных на одной машине, вам нужно что-то очень надежное. Именно здесь на сцену выходит распараллеливание в Spark. Теперь мы познакомим вас с параллельной обработкой Spark и с тем, как распараллелить в Spark, чтобы получить правильный результат из больших наборов данных.
Параллельная обработка Spark
Приложения Spark запускаются в виде независимых процессов, которые находятся в кластерах и координируются SparkContext в основной программе.
Первым шагом в запуске программы Spark является отправка задания с помощью Spark-submit. Сценарий spark-submit используется для запуска программы в кластере.
После отправки задания с помощью сценария spark-submit задание перенаправляется в драйверы sparkcontext. Программа драйвера Sparkcontext является точкой входа в Spark. Sparkcontext направляет программу к модулям, таким как главный узел кластера, и RDD также создаются этими программами-драйверами Sparkcontext.
Затем программа передается главному узлу кластера. Каждый кластер имеет один главный узел, который выполняет всю необходимую обработку. Он перенаправляет программу дальше на рабочие узлы.
Рабочий узел — это тот, который решает проблемы. Главные узлы содержат исполнители, которые выполняются с помощью драйвера Sparkcontext.
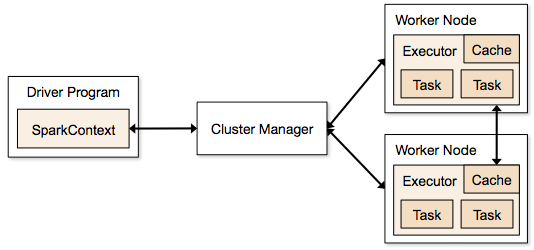 Источник
Источник
Что такое устойчивый распределенный набор данных (RDD)?
RDD — это основная структура данных Apache Spark. Эта структура данных представляет собой неизменяемую коллекцию объектов, которые вычисляются на разных узлах кластера. Каждый набор данных в Spark RDD логически разделен между различными серверами, поэтому вычисления могут выполняться гладко на каждом узле.

Давайте разберемся с RDD немного подробнее, так как он составляет основу распараллеливания в spark. Мы можем разбить имя на три части и узнать, почему структура данных названа так.
- Resilient : это означает, что структура данных является отказоустойчивой с помощью графа происхождения RDD, и, следовательно, она может повторно вычислить отсутствующие разделы или поврежденные разделы, вызванные сбоями узлов.
- Распределенная: это справедливо для всех систем, использующих распределенную среду. Он называется распределенным, потому что данные доступны на разных/нескольких узлах.
- Набор данных: Набор данных представляет данные, с которыми вы работаете. Вы можете импортировать любые доступные наборы данных в любом формате, например .csv, .json, текстовый файл или базу данных. Вы можете сделать это, используя JDBC без определенной структуры.
После того как вы импортируете или загрузите свой набор данных, RDD логически разделят ваши данные на несколько узлов на многих серверах, чтобы операция продолжалась.
Читайте также: Возможности Apache Spark
Теперь, когда вы знаете RDD, вам будет легче понять параллельную обработку Spark.
Распараллелить в Spark с помощью RDD
Параллельная обработка выполняется в Apache Spark за 4 важных этапа. RDD используется на основном уровне для распараллеливания в искре для выполнения параллельной обработки.
Шаг 1
RDD обычно создается из внешнего источника данных. Это может быть файл CSV, файл JSON или просто база данных. В большинстве случаев это HDFS или локальный файл.
Шаг 2
После первого шага RDD будет выполнять несколько параллельных преобразований, таких как filter, map, groupBy и join. Каждое из этих преобразований предоставляет другой RDD, который переходит к следующему преобразованию.
Получите сертификат по науке о данных от лучших университетов мира. Присоединяйтесь к нашим программам Executive PG, Advanced Certificate Programs или Masters Programs, чтобы ускорить свою карьеру.
Шаг 3
Последний этап посвящен действию; это всегда так. На этом этапе RDD экспортируется как внешний вывод во внешние источники данных.

Ознакомьтесь: Учебное пособие по Apache Spark для начинающих
Заключение
Параллельная обработка набирает популярность среди энтузиастов данных, поскольку полученные знания помогают компаниям и ОТТ зарабатывать большие деньги. Spark, с другой стороны, является одним из инструментов, помогающих крупным гигантам принимать решения, выполняя параллельную обработку больших и больших данных.
Если вы хотите ускорить обработку больших данных, вам подойдет Apache spark. Кроме того, RDD в Spark обеспечивают наилучшую производительность за всю историю существования.
Если вам интересно узнать больше о больших данных, ознакомьтесь с нашей программой PG Diploma в области разработки программного обеспечения со специализацией в области больших данных, которая предназначена для работающих профессионалов и включает более 7 тематических исследований и проектов, охватывает 14 языков и инструментов программирования, практические занятия. семинары, более 400 часов интенсивного обучения и помощь в трудоустройстве в ведущих фирмах.
Изучайте онлайн-курсы по разработке программного обеспечения в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.