Spark Parallel Processing'de Paralelleştirme Nasıl Yapılır? [RDD kullanarak]
Yayınlanan: 2020-09-03Veri üretimi ve tüketimi son birkaç yılda n kat arttı. Bu kadar çok platformun hayata geçmesiyle, verilerin dikkatli bir şekilde ele alınması ve yönetilmesi çok önemli hale geldi. AI (Yapay Zeka) ve ML (Makine Öğrenimi), sorunlarımıza daha iyi çözümler bularak dijital deneyimlerimizi daha da sorunsuz hale getiriyor. Bu nedenle, şirketler artık verileri işlemeye ve ondan içgörüler bulmaya doğru ilerliyor.
Aynı zamanda şirketler, ağ oyuncuları ve mobil devler tarafından üretilen veriler çok büyük. Bu nedenle, büyük veri kavramı tanıtıldı. Büyük veri ortaya çıktığından, büyük veriyi yönetme ve manipüle etme araçları da popülerlik ve önem kazanmaya başladı.
Apache Spark, bu verilerden içgörü elde etmek için büyük veri kümelerini manipüle eden ve işleyen araçlardan biridir. Bu büyük veri kümeleri, gereken hesaplama gücü çok yoğun olduğu için tek geçişte işlenemez veya yönetilemez.
Paralel işlemenin resme girdiği yer burasıdır. Kısaca paralel işlemeyi anlayarak başlayacağız ve ardından kıvılcımla paralelleştirmeyi anlamaya devam edeceğiz.
Okuyun: Apache Spark Mimarisi
İçindekiler
Paralel İşleme Nedir?
Paralel işleme, büyük bir veri sisteminin temel işlemlerinden biridir. Göreviniz önemli olduğunda, daha küçük görevlere ayrılır ve ardından her birini bağımsız olarak çözersiniz. Büyük verilerin paralel işlenmesi aynı süreci içerir.

Teknik olarak paralel işleme, tek bir büyük sorunun iki veya daha fazla parçasını farklı işlemcilerde çalıştırma yöntemidir. Bu işlem süresini azaltır ve performansı artırır.
Tek bir makinede büyük veri kümeleri üzerinde işlem yapamayacağınız için çok sağlam bir şeye ihtiyacınız var. İşte tam da bu noktada Spark'ta paralelleştirme devreye giriyor. Şimdi sizi Spark Paralel İşleme ve büyük veri kümelerinden doğru çıktıyı elde etmek için kıvılcım içinde nasıl paralel hale getirileceğine götüreceğiz.
Kıvılcım Paralel İşleme
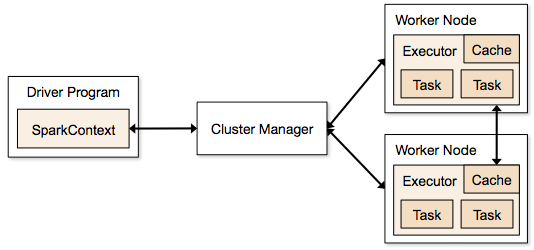
Spark uygulamaları, kümelerde bulunan ve ana programdaki SparkContext tarafından koordine edilen bağımsız süreçler şeklinde çalışır.
Bir Spark programını çalıştırmanın ilk adımı, işi Spark-gönder'i kullanarak göndermektir. Spark-gönder komut dosyası, programı bir kümede başlatmak için kullanılır.
Spark-gönder komut dosyası kullanarak işi gönderdikten sonra, iş, sparkcontext sürücülerine iletilir. Sparkcontext sürücü programı, Spark'a giriş noktasıdır. Sparkcontext, programı Küme Ana Düğümü gibi modüllere yönlendirir ve RDD'ler de bu Sparkcontext sürücü programları tarafından oluşturulur.
Program daha sonra Cluster Master Node'a verilir. Her küme, gerekli tüm işlemleri gerçekleştiren bir ana düğüme sahiptir. Programı daha fazla çalışan düğümlere iletir.
Çalışan düğüm, sorunları çözen düğümdür. Ana düğümler, Sparkcontext sürücüsü ile yürütülen yürütücüler içerir.
 Kaynak
Kaynak
Esnek Dağıtılmış Veri Kümesi (RDD) nedir?
RDD, Apache Spark'ın temel veri yapısıdır. Bu veri yapısı, bir kümenin farklı düğümlerinde hesaplanan değişmez bir nesneler topluluğudur. Spark RDD'deki her veri kümesi, çeşitli sunucular arasında mantıksal olarak bölümlenir, böylece hesaplamalar her düğümde sorunsuz bir şekilde çalıştırılabilir.

Spark'ta paralelleştirmenin temelini oluşturduğu için RDD'yi biraz daha ayrıntılı olarak anlayalım. Adı üç parçaya ayırabilir ve veri yapısının neden böyle adlandırıldığını anlayabiliriz.
- Esnek : Veri yapısının RDD köken grafiği yardımıyla hataya dayanıklı olduğu anlamına gelir ve bu nedenle düğüm arızalarından kaynaklanan eksik bölümleri veya hasarlı bölümleri yeniden hesaplayabilir.
- Dağıtılmış: Bu, dağıtılmış bir ortam kullanan tüm sistemler için geçerlidir. Veriler farklı/birden çok düğümde mevcut olduğu için dağıtılmış olarak adlandırılır.
- Veri Kümesi: Veri Kümesi, üzerinde çalıştığınız verileri temsil eder. .csv, .json, metin dosyası veya veritabanı gibi herhangi bir biçimde mevcut olan veri kümelerinden herhangi birini içe aktarabilirsiniz. Bunu, belirli bir yapısı olmayan JDBC kullanarak yapabilirsiniz.
Veri kümenizi içe aktardığınızda veya yüklediğinizde, RDD'ler işlemin devam etmesini sağlamak için verilerinizi mantıksal olarak birçok sunucuda birden çok düğüme böler.
Ayrıca Okuyun: Apache Spark Özellikleri
Artık RDD'yi bildiğinize göre, Spark Paralel İşleme'yi anlamanız daha kolay olacaktır.
RDD Kullanarak Spark'ta Paralelleştirme
Paralel işleme Apache Spark'ta 4 önemli adımda gerçekleştirilir. RDD, paralel işleme gerçekleştirmek için kıvılcım içinde paralel hale getirmek için büyük bir düzeyde kullanılır.
Aşama 1
RDD genellikle harici bir veri kaynağından oluşturulur. Bu bir CSV dosyası, JSON dosyası veya bu konuda bir veritabanı olabilir. Çoğu durumda, bir HDFS veya yerel bir dosyadır.
Adım 2
İlk adımdan sonra RDD, filtre, harita, groupBy ve birleştirme gibi birkaç paralel dönüşümden geçer. Bu dönüşümlerin her biri, bir sonraki dönüşüme ilerleyen farklı bir RDD sağlar.
Dünyanın en iyi Üniversitelerinden veri bilimi sertifikası kazanın . Kariyerinizi hızlandırmak için Yönetici PG Programlarımıza, İleri Düzey Sertifika Programlarımıza veya Yüksek Lisans Programlarımıza katılın.
Aşama 3
Son aşama eylemle ilgilidir; her zaman öyledir. Bu aşamada RDD, harici veri kaynaklarına harici bir çıktı olarak dışa aktarılır.

Kontrol edin: Yeni Başlayanlar için Apache Spark Eğitimi
Çözüm
İçgörüler şirketlerin ve OTT'lerin büyük kazanç elde etmesine yardımcı olduğundan paralel işleme, veri meraklıları arasında popülerlik kazanıyor. Spark ise büyük ve daha büyük veriler üzerinde paralel işleme yaparak büyük devlerin karar vermelerine yardımcı olan araçlardan biridir.
Büyük veri işlemeyi daha hızlı hale getirmeyi dört gözle bekliyorsanız, Apache Spark gitmeniz gereken yoldur. Ve Spark'taki RDD'ler, bilindiğinden beri en iyi performansı sunuyor.
Büyük Veri hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 7+ vaka çalışması ve proje sağlayan, 14 programlama dili ve aracını kapsayan, pratik uygulamalı Büyük Veride Yazılım Geliştirme Uzmanlığı programında PG Diplomamıza göz atın çalıştaylar, en iyi firmalarla 400 saatten fazla titiz öğrenim ve işe yerleştirme yardımı.
Dünyanın En İyi Üniversitelerinden Online Yazılım Geliştirme Kursları öğrenin . Kariyerinizi hızlandırmak için Yönetici PG Programları, Gelişmiş Sertifika Programları veya Yüksek Lisans Programları kazanın.